HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
引言
如何设计更高效的网络架构是进一步提高CNNs性能的关键。然而,随着超参数 (规模、宽度、基数等) 的增加,设计高效的体系结构变得越来越复杂,尤其是在网络深入发展的时候。在本文中,我们重新考虑了网络设计的瓶颈结构的尺寸。我们特别考虑以下三个基本问题。(i) 如何避免产生特征图中包含的丰富甚至冗余信息。(ii) 如何在没有任何计算复杂性的情况下促进网络学习更强大的特征表示。(iii) 如何实现更好的性能并保持推理速度。
在本文中,我们介绍了一种新颖的分层分割块来生成多尺度特征表示。具体来说,深度神经网络中的一个普通特征图将被拆分为s组,每个组具有w个通道。如图2所示,只有第一组过滤器可以直接连接到下一层。首先将第二组特征图发送到3 × 3滤波器的卷积以提取特征,然后将输出特征图在通道维度上分为两个子组。特征映射的一个子组直接连接到下一层,而另一个子组与通道维度中的下一组输入特征映射串联。串联特征图由一组3 × 3卷积滤波器操作。此过程重复几次,直到处理了其余的输入特征图。最后,将所有输入组中的特征映射级联并发送到另一层1 × 1过滤器以重建特征。同时,我们提出了一个名为HS-ResNet的网络,该网络由几个分层分割的块组成。与Res2Net[9] 不同,我们避免产生特征图中包含的丰富甚至冗余信息,并且网络可以学习更丰富的特征表示。

主要贡献:
- 我们提出了一种新颖的分层分割块,其中包含多尺度特征。分层分割块非常有效,并且可以保持与标准卷积相似的参数数量和计算成本。分层分割块非常灵活且可扩展,为计算机视觉的众多任务打开了各种网络体系结构的大门。
- 我们提出了一种用于图像分类任务的网络体系结构,该体系结构的性能明显优于基线模型。此外,它们在参数数量和计算成本方面是有效的,并且平均优于其他更复杂的体系结构。
- 我们发现,利用HS-ResNet主干的模型能够在几个任务上实现最先进的性能,即: 图像分类 [17],对象检测 [26],实例分割 [11] 和语义分割 [3]。
相关工作
为了提升模型的功能,当前的工作通常遵循两种类型的方法。一种是基于人类设计的CNN架构,另一种是基于神经架构搜索 (NAS)
人工设计的CNN架构
VGG[30] 展示了一种简单而有效的构建非常深的网络的策略: 堆叠具有相同维度的构建块。GoogLeNet[31] 构造了一个初始块,它包括四个并行操作: 1 × 1卷积,3 × 3卷积,5 × 5卷积和最大池。然后将这四个操作的输出串联并馈送到下一层。ResNeXt[36] 提出了名为基数的新维度,该维度由组卷积操作,并认为增加基数比增加网络容量时更深或更宽更有效。SE-Net[15] 通过自适应地重新校准通道特征响应,引入了通道注意机制。SK-Net[20] 在两个网络分支中引起了特征图的关注。Res2Net[9] 在更粒度的水平上提高了多尺度表示能力。ResNeSt[39] 在各个网络块中合并了特征图拆分注意力。PyConvResNet[8] 使用金字塔形卷积,其中包括四个级别的不同内核大小: 9 × 9、7 × 7、5 × 5、3 × 3,以捕获多个尺度特征。
神经架构搜索
随着GPU硬件的发展,主要问题已从手动设计的体系结构转变为对特定任务进行自适应系统搜索的体系结构。大多数NAS生成的网络使用与MobileNetV2相同或相似的设计空间 [27],包括EfficientNet [444],MobileNetV3[14],FBNet[35],DNANet[18],OFANet[2] 等。MixNet[34] 提出在一层中混合不同内核大小的深度卷积。但是,NAS生成的网络依赖于人为生成的块,例如瓶颈 [12],反向块 [27]。我们的方法还可以增加神经体系结构搜索的搜索空间,并有可能提高整体性能,这可以在将来的工作中进行研究。
方法
分层分割块
分层分割块的结构如图2所示。在1 × 1卷积之后,我们将特征图分成s组,用xi表示,并且每个组具有相同w,作为通道宽度。每个xi将输入3 × 3卷积,用Fi () 表示。Fi () 的输出特征图用yi表示。最有创意的想法是将yi分为两个子组,分别表示为yi,1和yi,2。然后yi2与下一个组xi 1连接,然后馈入Fi 1 (), 表示两个特征图在通道维度上连接。完成所有输入特征组的操作后,将通过连接所有yi,1来恢复通道维度,每个yi,1具有不同的通道。更多的通道yi,1包含,更大的感受野。具有较小感受野的输出特征图可以关注细节,这对于识别小对象或对象的关键部分很重要,而将来自前组的更多特征串联起来将捕获更多较大的对象。在这项工作中,我们控制w和s以限制hs-resnet的参数或计算复杂度。较大的s对应更强的多尺度能力,而较大的w对应更丰富的特征图。
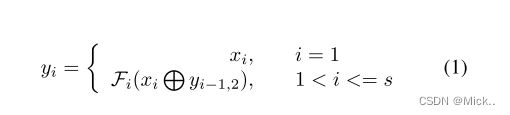
拆分和连接操作
分层分割块包括两个阶段的分割和连接操作。第一个分割操作将集成的特征图x变成单独的组xi,并且每个组具有公共宽度。第二次拆分操作将备用特征图yi转换为两个子组,分别为yi,1和yi,2。值得注意的是,当yi的宽度不均匀时,yi,1和yi,2的宽度会不同。该设计的灵感来自GhostNet[10],yi,1的身份映射是为了保留固有特征图,而yi,2用于捕获更精细的特征
第一串联用于通过串联yi-1,2和xi来加宽信道,增强不同组之间的信息流。第二个串联只是将所有的yi,1合并,并将输出输入到1 × 1卷积中。我们认为串联比在Res2Net中使用的求和更有效 [9]。求和操作可能会改变,甚至会破坏特征表示,而串联将整体保持特征表示。
复杂性分析
作者这里进行模型复杂度分析,主要是比较参数量的大小。但是和谁进行比较,没有看懂。
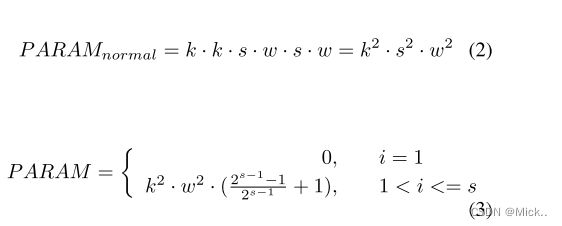
import torch
import torch.nn as nn
class HSBlock(nn.Module):
'''
替代3x3卷积
'''
def __init__(self, in_ch, s=8):
'''
特征大小不改变
:param in_ch: 输入通道
:param s: 分组数
'''
super(HSBlock, self).__init__()
self.s = s
self.module_list = nn.ModuleList()
in_ch_range=torch.Tensor(in_ch)
in_ch_list = list(in_ch_range.chunk(chunks=self.s, dim=0))
self.module_list.append(nn.Sequential())
channel_nums = []
for i in range(1,len(in_ch_list)):
if i == 1:
channels = len(in_ch_list[i])
else:
random_tensor = torch.Tensor(channel_nums[i-2])
_, pre_ch = random_tensor.chunk(chunks=2, dim=0)
channels= len(pre_ch)+len(in_ch_list[i])
channel_nums.append(channels)
self.module_list.append(self.conv_bn_relu(in_ch=channels, out_ch=channels))
self.initialize_weights()
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, stride=1, padding=1):
conv_bn_relu = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
return conv_bn_relu
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = list(x.chunk(chunks=self.s, dim=1))
for i in range(1, len(self.module_list)):
y = self.module_list[i](x[i])
if i == len(self.module_list) - 1:
x[0] = torch.cat((x[0], y), 1)
else:
y1, y2 = y.chunk(chunks=2, dim=1)
x[0] = torch.cat((x[0], y1), 1)
x[i + 1] = torch.cat((x[i + 1], y2), 1)
return x[0]参考文献:
HS-Resnet - 知乎 (zhihu.com)
论文阅读分享(特征提取网络HS-ResNet) - 知乎 (zhihu.com)
HS-ResNet/hs_block.py at main · bobo0810/HS-ResNet (github.com)