机器学习笔记(2)-决策树
决策树
一.问题概述
决策树(decision tree)希望从给定的数据集学得一个模型用以对新示例来进行分类,把这个样本分类的任务看作对“当前样本属于正类吗?”这个问题的“决策”或者“判定”的过程。决策树是基于树的结构进行决策的,如下图:
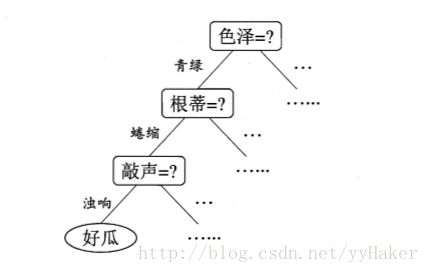
二.决策树学习的基本算法

三.实现算法
决策树最核心的问题就是如何选择出最优的划分属性,即上述算法中的第8行,一般而言,我们希望决策树的分支节点所包含的样本尽可能的属于同一个类别,即样本的“纯度”越来越高。
- ID3决策树算法
1.1.以信息增益为准则来选择划分属性
1.2 基本定义
信息熵(information entropy),是度量样本集合纯度最常用的一种指标,假定样本集合D中第k类样本所占的比例为Pk(k=1,2,…,|y|),则D的信息熵定义为:
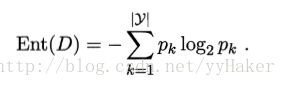
假定离散属性a有V个可能的取值{a1 , a2 , … , aV},若使用a来对样本进行划分,则会产生V个节点,其中第v个分支节点包含了D中所有在属性a上取值为aV的样本,记为Dv。于是可以计算用属性a划分的“信息增益(information gain)”为:
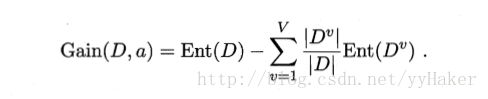
一般而言,信息增益越大,则意味着用属性a进行划分所得的”纯度提升“越大,因此我们可以使用信息增益为准则来划分属性,即选择属性
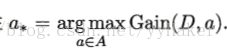
1.3 缺点:信息增益为准则对可取值数目较多的属性有所偏好 - C4.5决策树算法
2.1增益率(gain ratio)的定义:
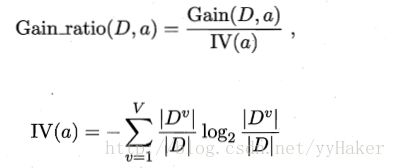
其中IV(a)称为属性a的固有值,属性a的可能取值的数目越多,则IV(a)的值通常会越大。
2.2 由于增益率对可取值数目较多的属性有所偏好,C4.5采用启发式方法:先从候选的划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。 - CART决策树算法
3.1使用“基尼指数(Gini index)”来选择划分属性。一个数据集的纯度可以使用基尼值来度量:

基尼指数Gini(D)反应了从数据集中随机抽取两个样本不一致的概率。因此,Gini(D)越小,则数据集的纯度越高。
相应的,属性a的基尼指数定义为:
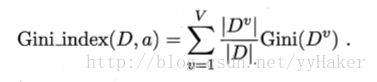
4.实现的python代码如下,我这里实现了上述三个算法,根据方法chooseBestFeatureToSplit(dataSet, modelType =’ID3’)的modelType参数来选择相应的算法。
# -*- coding: utf-8 -*-
"""
Decision Tree Source Code for Machine Learning
algorithm: ID3,C4.5,CART 以信息增益、增益率为准则来选择最优的划分属性
@author leyuan
"""
from math import log
import operator
import treePlotter
def createDataSet():
"""
产生测试数据
"""
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
def calcShannonEnt(dataSet):
"""
计算给定数据集的信息熵(information entropy),
:param dataSet:
:return:
"""
numEntries = len(dataSet)
labelCounts = {}
# 统计每个类别出现的次数,保存在字典labelCounts中
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): # 如果当前键值不存在,则扩展字典并将当前键值加入字典
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
# 使用所有类标签的发生频率计算类别出现的概率
prob = float(labelCounts[key])/numEntries
# 用这个概率计算信息熵
shannonEnt -= prob * log(prob, 2) # 取2为底的对数
return shannonEnt
def calcGini(dataSet):
"""
计算给定数据集的基尼指数
:param dataSet:
:return:
"""
numExample = len(dataSet)
lableCounts = {}
# 统计每个类别出现的次数,保存在字典lableCounts中
for featVect in dataSet:
currentLable = featVect[-1]
# 如果当前键值不存在,则扩展字典将当前键值加入到字典中
if currentLable not in lableCounts.keys():
lableCounts[currentLable] = 0
lableCounts[currentLable] += 1
gini = 1.0
for key in lableCounts:
# 使用所有类标签的频率来计算概率
prob = float(lableCounts[key])/numExample
# 计算基尼指数
gini -= prob**2
return gini
def splitDataSet(dataSet, axis, value):
"""
按照给定特征划分数据集
dataSet:待划分的数据集
axis: 划分数据集的第axis个特征
value: 特征的返回值(比较值)
"""
retDataSet = []
# 遍历数据集中的每个元素,一旦发现符合要求的值,则将其添加到新创建的列表中
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
# extend()和append()方法功能相似,但在处理列表时,处理结果完全不同
# a=[1,2,3] b=[4,5,6]
# a.append(b) = [1,2,3,[4,5,6]]
# a.extend(b) = [1,2,3,4,5,6]
return retDataSet
def chooseBestFeatureToSplit(dataSet, modelType ='ID3'):
"""
选择最好的数据集划分方式,支持ID3,C4.5,CART
:param dataSet: 数据集
:param modelType: 决定选择最优划分属性的方式
:return: 最优分类的特征的index
"""
# 计算特征数量
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
infoGainList = []
gain_ratioList = []
gini_index_list = []
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
# 计算用某种属性划分的信息熵和信息增益
newEntropy = 0.0
instrinsicValue = 0.0
# 基尼指数
gini_index = 0.0
for value in uniqueVals:
# 计算属性的每个取值的信息熵x权重
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
# 计算固有值(instrinsic value)
instrinsicValue -= prob * log(prob, 2)
# 计算基尼指数
gini_index += prob * calcGini(subDataSet)
# 计算信息增益
infoGain = baseEntropy - newEntropy
infoGainList.append(infoGain)
# 计算增益率
if instrinsicValue == 0:
gain_ratio = 0
else:
gain_ratio = infoGain/instrinsicValue
gain_ratioList.append(gain_ratio)
# 保存基尼指数
gini_index_list.append(gini_index)
# C4.5实现两个步骤:1.找出信息增益高于平均水平的属性组成集合A 2.从A中选择增益率最高的
# 求infoGain平均值
avgInfoGain = sum(infoGainList)/len(infoGainList)
infoGainSublist = [gain for gain in infoGainList if gain >= avgInfoGain]
# ID3信息增益越大能得到最优化分
if modelType == 'ID3':
bestInfoGain = max(infoGainList)
bestFeature = infoGainList.index(bestInfoGain)
# C4.5得到最优化分属性
elif modelType == 'C4.5':
# 选择增益率最高的
maxGainRatio = 0.0
for i in [infoGainList.index(infor) for infor in infoGainSublist]:
if gain_ratioList[i] > maxGainRatio:
maxGainRatio = gain_ratioList[i]
bestFeature = i
elif modelType == 'CART':
# 选择划分后基尼指数最小的
minGini = 1
for i in range(len(gini_index_list)):
if gini_index_list[i] < minGini:
minGini = gini_index_list[i]
bestFeature = i
return bestFeature
def majorityCnt(classList):
"""
投票表决函数
输入classList:标签集合,本例为:['yes', 'yes', 'no', 'no', 'no']
输出:得票数最多的分类名称
:param classList:
:return:
"""
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
# 把分类结果进行排序,然后返回得票数最多的分类结果
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels, featDict):
"""
创建树
:param dataSet: 数据集
:param labels: 标签列表(属性集合)
:return:
"""
# classList为数据集的所有类标签
classList = [example[-1] for example in dataSet]
# 停止条件1:所有类标签完全相同,直接返回该类标签
if classList.count(classList[0]) == len(classList):
return classList[0]
# 停止条件2:遍历完所有特征时仍不能将数据集划分成仅包含唯一类别的分组,则返回出现次数最多的
# 此处还存在一种情况数据集dataSet在属性集上取值相同???
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 选择最优分类特征
bestFeat = chooseBestFeatureToSplit(dataSet, modelType='ID3')
bestFeatLabel = labels[bestFeat]
# myTree存储树的所有信息
myTree = {bestFeatLabel: {}}
# 以下得到列表包含的所有属性值
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
# 遍历当前选择特征包含的所有属性值(怎么保证该属性能取到属性的所有值?我这里在外面写了一个getFeatAllVals)
for value in featDict[bestFeatLabel]:
resDataSet = splitDataSet(dataSet, bestFeat, value)
if len(resDataSet) == 0:
myTree[bestFeatLabel][value] = majorityCnt(classList)
else:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(resDataSet, subLabels, featDict)
return myTree
def getFeatAllVals(dataSet, lables):
"""
获得给定数据集的指定标签的所有属性取值
:param dataSet:
:param lables:
:return:
"""
featDict = {}
for i in range(len(lables)):
featValues = [example[i] for example in dataSet]
uniqueVals = set(featValues)
featDict[lables[i]] = uniqueVals
return featDict
def classify(inputTree, featLabels, testVec):
"""
决策树的分类函数
:param inputTree: 训练好的树信息
:param featLabels: 标签列表
:param testVec: 测试向量
:return:
"""
# 在2.7中,找到key所对应的第一个元素为:firstStr = myTree.keys()[0],
# 这在3.4中运行会报错:‘dict_keys‘ object does not support indexing,这是因为python3改变了dict.keys,
# 返回的是dict_keys对象,支持iterable 但不支持indexable,
# 我们可以将其明确的转化成list,则此项功能在3中应这样实现:
firstSides = list(inputTree.keys())
firstStr = firstSides[0]
secondDict = inputTree[firstStr]
# 将标签字符串转换成索引
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
# 递归遍历整棵树,比较testVec变量中的值与树节点的值,如果到达叶子节点,则返回当前节点的分类标签
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else:
classLabel = valueOfFeat
return classLabel
def storeTree(inputTree, filename):
"""
使用pickle模块存储决策树
:param inputTree: 训练好的树信息
:param filename:
:return:
"""
import pickle
fw = open(filename, 'wb+')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
"""
导入决策树模型
:param filename:
:return:
"""
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)
if __name__ == "__main__":
fr = open('watermellon2')
lenses = [inst.strip().split('-') for inst in fr.readlines()]
lensesLabels = ['color', 'root', 'stroke', 'grain', 'navel', 'touch']
featDict = getFeatAllVals(lenses, lensesLabels)
lensesTree = createTree(lenses, lensesLabels, featDict)
treePlotter.createPlot(lensesTree)
5.我使用的数据训练集合为:
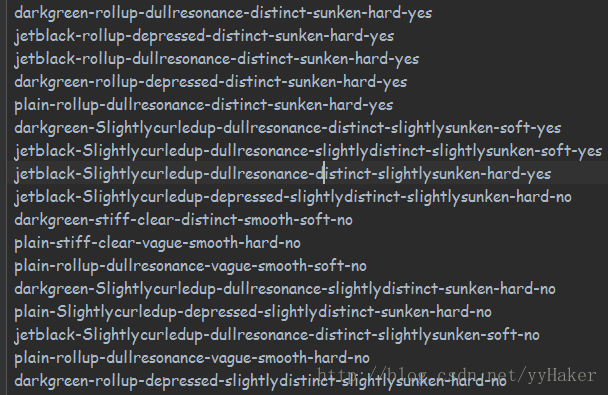
下面是采用ID3的运行结果:
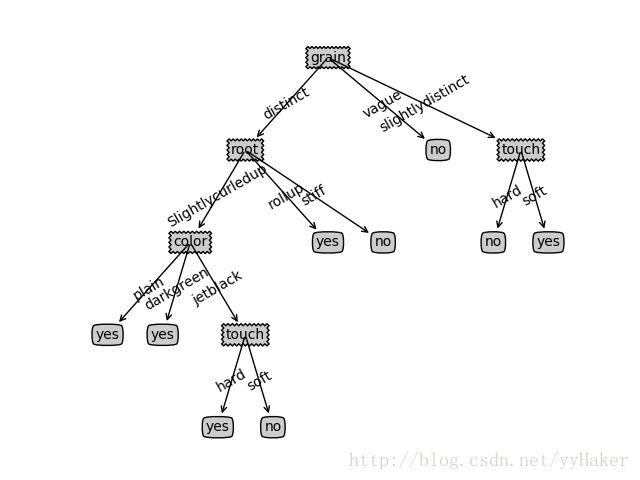
详细代码请参考我的gihub地址:https://github.com/yyHaker/MachineLearning/tree/master/MLaction-master/Ch03_DT
四.剪枝、连续值处理
- 预剪枝
在决策树生成过程中,对每个节点在划分前进行估计,若当前节点的划分不能带来决策树泛化性能(指处理未见实例的能力)的提升,则停止划分,并将当前结点标记为叶子节点。 - 后剪枝
先从训练集生成一颗完整的决策树,然后自底向上地对非叶子结点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能的提升,则将该叶子结点替换为叶子结点。
两种剪枝方法的比较:
预剪枝使得很多的决策树分支没有申展,这不仅降低了过拟合的风险,还显著的减少了决策树的训练时间开销和测试时间开销;另一方面有些分支的当前划分虽然不能提升泛化性能,甚至可能导致泛化性能暂时下降,但是在其基础上进行的后续划分却有可能导致性能显著的提高;预剪枝基于“贪心”本质禁止这些分支展开,给决策树带来了欠拟合的风险。
后剪枝通常比预剪枝保留了更多的保留了分支。一般情况下,后剪枝决策树的欠拟合的风险很小,泛化性能往往优于预剪枝的决策树,但是后剪枝的决策树是在生成的完全的决策树之后的,并且要自底向上的对树种的所有非叶子节点进行注意考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大的多。 连续值的处理
采用二分法对连续属性进行处理,给定属性集D和连续属性a,a在D上出现了n个不同的取值,将这些值从小到大排序,记为{a1,a2,a3,…,an}.
对连续属性a我们考察n-1个元素的候选划分点集合:
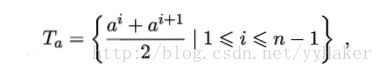
找出使得信息增益最大的候选划分点:

区间[ai , a(i+1)]的中位点作为候选划分点t.需要注意与离散属性不同,若当前属性为连续属性,改属性还可以作为其后代节点的划分属性。
代码实现,我这里实现了以基尼指数为最优的划分策略、连续值的处理和离散值的处理,不剪枝策略、预剪枝策略以及后剪枝策略,代码如下:
# coding: utf-8
from numpy import *
import pandas as pd
import codecs
import operator
import copy
import json
import treePlotter
def calcGini(dataSet):
"""
计算给定数据集的基尼指数
:param dataSet: 数据集 list
:return:
"""
numEntries = len(dataSet)
labelCounts = {}
# 给所有可能的分类创建字典
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
Gini = 1.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
Gini -= prob * prob
return Gini
def splitDataSet(dataSet,axis,value):
"""
对离散变量划分数据集,取出该特征值为value的所有样本
:param dataSet: 数据集list
:param axis: 属性下标
:param value: 属性取值
:return:retDataSet
"""
returnMat = []
for data in dataSet:
if data[axis] == value:
returnMat.append(data[:axis]+data[axis+1:])
return returnMat
"""
注意到连续属性和离散属性不同,对离散属性划分数据集时会删除对应属性的数据,若当前节点划分属性为连续属性,
该属性还可作为其后代节点的划分属性,因此对连续变量划分数据集时并没有删除对应属性的数据
"""
def splitContinuousDataSet(dataSet, axis, value, direction):
"""
对连续变量划分数据集
:param dataSet: 数据集
:param axis: 属性下标
:param value: 属性值
:param direction: 划分的方向,决定划分是小于value的数据样本还是大于value 的数据样本
direction=0得到大于value的数据集
:return: retDataSet
"""
retDataSet = []
for featVec in dataSet:
if direction == 0:
if featVec[axis] > value:
retDataSet.append(featVec)
else:
if featVec[axis] <= value:
retDataSet.append(featVec)
return retDataSet
'''
决策树算法中比较核心的地方,究竟是用何种方式来决定最佳划分?
使用信息增益作为划分标准的决策树称为ID3
使用信息增益比作为划分标准的决策树称为C4.5,甚至综合信息增益和信息增益比
本题为CART基于基尼指数
从输入的训练样本集中,计算划分之前的熵,找到当前有多少个特征,遍历每一个特征计算信息增益,找到这些特征中能带来信息增益最大的那一个特征。
这里用分了两种情况,离散属性和连续属性
1、离散属性,在遍历特征时,遍历训练样本中该特征所出现过的所有离散值,假设有n种取值,那么对这n种我们分别计算每一种的熵,最后将这些熵加起来
就是划分之后的信息熵
2、连续属性,对于连续值就稍微麻烦一点,首先需要确定划分点,用二分的方法确定(连续值取值数-1)个切分点。遍历每种切分情况,对于每种切分,
计算新的信息熵,从而计算增益,找到最大的增益。
假设从所有离散和连续属性中已经找到了能带来最大增益的属性划分,这个时候是离散属性很好办,直接用原有训练集中的属性值作为划分的值就行,但是连续
属性我们只是得到了一个切分点,这是不够的,我们还需要对数据进行二值处理。
'''
def chooseBestFeatureToSplit(dataSet, labels):
"""
选择最优的划分属性
:param dataSet: 数据集list
:param labels: 属性集合
:return: 最优划分属性的下标
"""
numFeatures = len(dataSet[0]) - 1
bestGini = 10000.0
bestFeature = -1
bestSplitDict = {}
for i in range(numFeatures):
# 对连续型特征进行处理 ,i代表第i个特征,featList是每次选取一个特征之后这个特征的所有样本对应的数据
featList = [example[i] for example in dataSet]
# 对连续型值处理
if type(featList[0]).__name__ == 'float' or type(featList[0]).__name__ == 'int':
# 产生n-1个候选划分点
sortfeatList = sorted(featList)
splitList = []
for j in range(len(sortfeatList) - 1):
splitList.append((sortfeatList[j] + sortfeatList[j + 1]) / 2.0)
bestSplitGini = 10000
# 求用第j个候选划分点划分时,得到的信息熵,并记录最佳划分点
for value in splitList:
newGini = 0.0
subDataSet0 = splitContinuousDataSet(dataSet, i, value, 0)
subDataSet1 = splitContinuousDataSet(dataSet, i, value, 1)
prob0 = len(subDataSet0) / float(len(dataSet))
newGini += prob0 * calcGini(subDataSet0)
prob1 = len(subDataSet1) / float(len(dataSet))
newGini += prob1 * calcGini(subDataSet1)
if newGini < bestSplitGini:
bestSplitGini = newGini
bestSplit = value
# 用字典记录当前特征的最佳划分点,记录对应的基尼指数
bestSplitDict[labels[i]] = bestSplit
newGini = bestSplitGini
# 对离散型特征进行处理
else:
uniqueVals = set(featList)
newGini = 0.0
# 计算该特征下划分的信息熵,选取第i个特征的值为value的子集
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newGini += prob * calcGini(subDataSet)
# 得到最优的划分属性
if newGini < bestGini:
bestGini = newGini
bestFeature = i
# 若当前节点的最佳划分特征为连续特征,则将其以之前记录的划分点为界进行二值化处理即是否小于等于bestSplitValue
# 问题:为什么要进行二值化处理,怎么保证如果选择的当前划分属性为连续属性,该属性还可以作为后代的划分属性
# 思路:能不能在选择的划分属性为连续属性时除了返回属性下标外,还返回划分数值,后面再递归求解构造树
if type(dataSet[0][bestFeature]).__name__ == 'float' or type(dataSet[0][bestFeature]).__name__ == 'int':
bestSplitValue = round(bestSplitDict[labels[bestFeature]], 3)
newlable = lables[bestFeature]
if '<=' in newlable:
newlable = newlable[:newlable.index('<=')]
lables[bestFeature] = newlable
labels[bestFeature] = labels[bestFeature] + '<=' + str(bestSplitValue)
return bestFeature
def majorityCnt(classList):
"""
特征已经划分完成,节点下的样本还没有统一取值,则需要进行投票
:param classList:
:return:
"""
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 由于在Tree中,连续值特征的名称以及改为了feature <= value的形式
# 因此对于这类特征,需要利用正则表达式进行分割,获得特征名以及分割阈值
def classify(inputTree, featLabels, testVec):
"""
对给定的数据集合进行分类
:param inputTree:训练好i的决策树
:param featLabels:属性集合
:param testVec: 测试样本
:return:
"""
firstStr = list(inputTree.keys())[0]
if u'<=' in firstStr:
featvalue = float(firstStr.split(u"<=")[1])
featkey = firstStr.split(u"<=")[0]
secondDict = inputTree[firstStr]
# 对于连续属性,我们遍历列表得到属性下标
featIndex = 0
for i in range(len(featLabels)):
if featkey in featLabels[i]:
featIndex = i
if testVec[featIndex] <= featvalue:
judge = 1
else:
judge = 0
for key in secondDict.keys():
if judge == int(key):
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
else: # 离散属性的情况
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def testing(myTree, data_test, labels):
"""
后剪枝
:param myTree: 已经训练成的树
:param data_test: 测试泛化能力的数据
:param labels: 属性集
:return:
"""
error = 0.0
for i in range(len(data_test)):
if classify(myTree, labels, data_test[i]) != data_test[i][-1]:
error += 1
return float(error)
def caclAccuracyRate(mtTree, data_test, lables):
"""
计算决策树模型预测的准确率
:param mtTree:
:param data_test:
:param lables:
:return:
"""
return 1 - testing(myTree, data_test, lables)/float(len(data_test))
def testing_feat(feat, train_data, test_data, labels):
"""
评测若选择当前最优的划分属性进行划分所产生决策树的泛化能力
:param feat: 当前最优的划分属性
:param train_data: 数据集
:param test_data: 测试泛化能力的数据集
:param labels: 属性集
:return:
"""
# 训练数据的类别集合
class_list = [example[-1] for example in train_data]
bestFeatIndex = lables.index(feat)
# 当前最优化分属性下标在测试数据中对应的turple(属性取值,所属类别)
test_data = [(example[bestFeatIndex], example[-1]) for example in test_data]
error = 0.0
# 判断是离散属性还是连续属性
if "<=" in feat: # 连续属性
featvalue = float(feat.split("<=")[1]) # 连续属性的划分取值
featkey = feat.split("<=")[0] # 连续属性的名字,下标为 bestFeatIndex
# value > featvalue majority(classList0)
subDataSet0 = splitContinuousDataSet(train_data, bestFeatIndex, featvalue, 0)
classList0 =[example[-1] for example in subDataSet0]
# value <= featvalue majority(classList1)
subDataSet1 = splitContinuousDataSet(train_data, bestFeatIndex, featvalue, 1)
classList1 = [example[-1] for example in subDataSet1]
twoLables = [majorityCnt(classList0), majorityCnt(classList1)]
# 计算error
for data in test_data:
if data[0] <= featvalue and data[1] != twoLables[1]:
error += 1.0
elif data[0] > featvalue and data[1] != twoLables[0]:
error +=1.0
else: # 离散属性
# 当前最优划分属性的取值集合
train_data = [example[bestFeatIndex] for example in train_data]
all_feat = set(train_data)
for value in all_feat:
class_feat = [class_list[i] for i in range(len(class_list)) if train_data[i] == value]
major = majorityCnt(class_feat)
for data in test_data:
if data[0] == value and data[1] != major:
error += 1.0
# print 'myTree %d' % error
return error
def testingMajor(major, data_test):
"""
评测若不选择当前最优的划分属性进行划分所产生决策树的泛化能力
:param major: 当前训练集合最多的类别
:param data_test: 测试泛化能力的数据集
:return:
"""
error = 0.0
for i in range(len(data_test)):
if major != data_test[i][-1]:
error += 1
# print 'major %d' % error
return float(error)
'''
主程序,递归产生决策树。
params:
dataSet:用于构建树的数据集,最开始就是data_full,然后随着划分的进行越来越小,第一次划分之前是17个瓜的数据在根节点,然后选择第一个bestFeat是纹理
纹理的取值有清晰、模糊、稍糊三种,将瓜分成了清晰(9个),稍糊(5个),模糊(3个),这个时候应该将划分的类别减少1以便于下次划分
labels:还剩下的用于划分的类别
data_full:全部的数据
label_full:全部的类别
既然是递归的构造树,当然就需要终止条件,终止条件有三个:
1、当前节点包含的样本全部属于同一类别;-----------------注释1就是这种情形
2、当前属性集为空,即所有可以用来划分的属性全部用完了,这个时候当前节点还存在不同的类别没有分开,这个时候我们需要将当前节点作为叶子节点,
同时根据此时剩下的样本中的多数类(无论几类取数量最多的类)-------------------------注释2就是这种情形
3、当前节点所包含的样本集合为空。比如在某个节点,我们还有10个西瓜,用大小作为特征来划分,分为大中小三类,10个西瓜8大2小,因为训练集生成
树的时候不包含大小为中的样本,那么划分出来的决策树在碰到大小为中的西瓜(视为未登录的样本)就会将父节点的8大2小作为先验同时将该中西瓜的
大小属性视作大来处理。
'''
def createTree(dataSet, labels, data_full, labels_full, test_data, mode="unpro"):
"""
递归的产生决策树
:param dataSet: 数据集
:param labels: 属性集
:param data_full: 全部的数据
:param labels_full: 全部的属性
:param test_data: 测试数据,用来评测泛化能力
:param mode:剪枝策略,不剪枝,预剪枝,后剪枝
:return:
"""
classList=[example[-1] for example in dataSet]
# 数据集中的样本全部属于同一类别,将该节点标记为叶节点,并标记为该类别(注释1)
if classList.count(classList[0]) == len(classList):
return classList[0]
# 属性集为空或者样本数据在属性集上完全相同,将该节点标记为叶子结点,类别标记为样本中类别最多的一个类(注释2)
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 平凡情况,每次找到最佳划分的特征
labels_copy = copy.deepcopy(labels) # 浅拷贝只得到引用,深拷贝得到具体的值
bestFeat=chooseBestFeatureToSplit(dataSet, labels)
bestFeatLabel = labels[bestFeat]
# 相应的剪枝操作
if mode == "unpro" or mode == "post":
myTree = {bestFeatLabel: {}}
elif mode == "prev":
if testing_feat(bestFeatLabel, dataSet, test_data, labels_copy) < testingMajor(majorityCnt(classList), test_data):
myTree = {bestFeatLabel: {}}
else:
return majorityCnt(classList)
# 判断选择的最优的划分属性是连续属性还是离散属性
if '<=' in bestFeatLabel: # 连续属性
featvalue = float(bestFeatLabel.split("<=")[1]) # 连续属性的划分取值
featkey = bestFeatLabel.split("<=")[0] # 连续属性的名字,下标为 bestFeat
for i in range(2):
subDataSet = splitContinuousDataSet(dataSet, bestFeat, featvalue, i)
subClassList = [example[-1] for example in subDataSet]
if len(subDataSet) == 0 or len(set(subClassList)) == 1:
myTree[bestFeatLabel][i] = majorityCnt(subClassList)
else:
myTree[bestFeatLabel][i] = createTree(subDataSet, lables, data_full, lables_full, test_data, mode=mode)
else: # 离散属性
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
'''
刚开始很奇怪为什么要加一个uniqueValFull,后来思考下觉得应该是在某次划分,比如在根节点划分纹理的时候,将数据分成了清晰、模糊、稍糊三块
,假设之后在模糊这一子数据集中,下一划分属性是触感,而这个数据集中只有软粘属性的西瓜,这样建立的决策树在当前节点划分时就只有软粘这一属性了,
事实上训练样本中还有硬滑这一属性,这样就造成了树的缺失,因此用到uniqueValFull之后就能将训练样本中有的属性值都囊括。
如果在某个分支每找到一个属性,就在其中去掉一个,最后如果还有剩余的根据父节点投票决定。
但是即便这样,如果训练集中没有出现触感属性值为“一般”的西瓜,但是分类时候遇到这样的测试样本,那么应该用父节点的多数类作为预测结果输出。
'''
if type(dataSet[0][bestFeat]).__name__ == 'unicode' or type(dataSet[0][bestFeat]).__name__ == 'str':
currentlabel = labels_full.index(labels[bestFeat])
featValuesFull = [example[currentlabel] for example in data_full]
uniqueValsFull = set(featValuesFull)
del(labels[bestFeat])
'''
针对bestFeat的每个取值,划分出一个子树。对于纹理,树应该是{"纹理":{?}},显然?处是纹理的不同取值,有清晰模糊和稍糊三种,对于每一种情况,
都去建立一个自己的树,大概长这样{"纹理":{"模糊":{0},"稍糊":{1},"清晰":{2}}},对于0\1\2这三棵树,每次建树的训练样本都是值为value特征数减少1
的子集。
'''
for value in uniqueVals:
subLabels = labels[:]
# print(type(dataSet[0][bestFeat]+" "+dataSet[0][bestFeat]).__name__)
if type(dataSet[0][bestFeat]).__name__ == 'unicode' or type(dataSet[0][bestFeat]).__name__ == 'str':
uniqueValsFull.remove(value)
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels, data_full, labels_full, splitDataSet(test_data, bestFeat, value), mode=mode)
if type(dataSet[0][bestFeat]).__name__ == 'unicode' or type(dataSet[0][bestFeat]).__name__ == 'str':
for value in uniqueValsFull:
myTree[bestFeatLabel][value] = majorityCnt(classList)
# 后剪枝
if mode == "post":
if testing(myTree, test_data, labels_copy) > testingMajor(majorityCnt(classList), test_data):
return majorityCnt(classList)
return myTree
# 读入csv文件数据
def load_data(file_name):
file = codecs.open(file_name, "r", 'utf-8')
filedata = [line.strip('\n').split(',') for line in file]
filedata = [[float(i) if '.' in i else i for i in row] for row in filedata] # change decimal from string to float
train_data = [row[1:] for row in filedata[1:12]]
test_data = [row[1:] for row in filedata[11:]]
labels = []
for label in filedata[0][1:-1]:
labels.append(unicode(label))
return train_data,test_data,labels
if __name__ == "__main__":
"""
train_data,test_data,labels = load_data("data/西瓜数据集2.0.csv")
data_full = train_data[:]
labels_full = labels[:]
"""
# 数据测试
df = pd.read_csv('watermellon4.2.1.csv')
data = df.values[:11, 1:].tolist()
test_data = df.values[11:, 1:].tolist()
data_full = data[:]
lables = df.columns.values[1:-1].tolist()
lables_full = lables[:]
"""
为了代码的简洁,将预剪枝,后剪枝和未剪枝三种模式用一个参数mode传入建树的过程
post代表后剪枝,prev代表预剪枝,unpro代表不剪枝
"""
# mode = "unpro"
# mode = "prev"
# mode = "post"
mode = "unpro"
myTree = createTree(data, lables, data_full, lables_full, test_data, mode=mode)
# myTree = postPruningTree(myTree,train_data,test_data,labels_full)
print(myTree)
print(json.dumps(myTree, ensure_ascii=False, indent=4))
print("accuracyRate:", caclAccuracyRate(myTree, test_data, lables_full))
treePlotter.createPlot(myTree)
测试
5.1我使用的数据集如下:
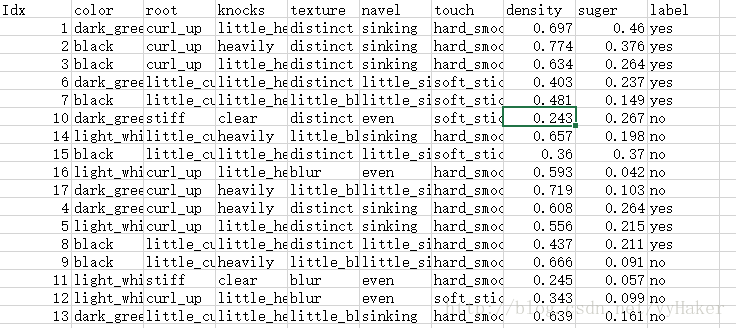
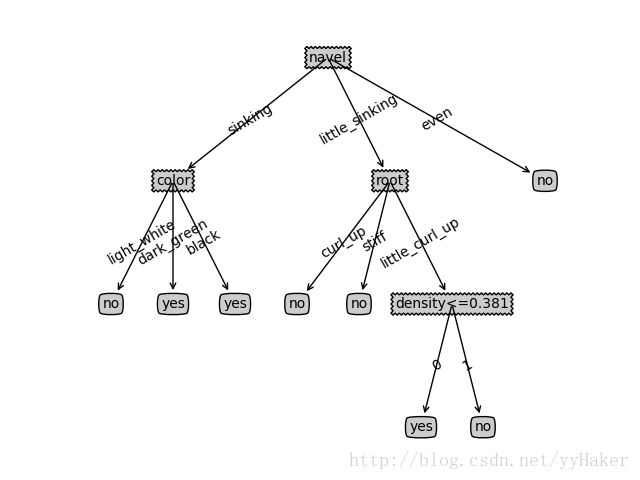
5.2使用前面11个数据训练决策是,后面7个数据测试,结果如下5.2.1 不剪枝,预测准确率:0.5 得到决策树如下:
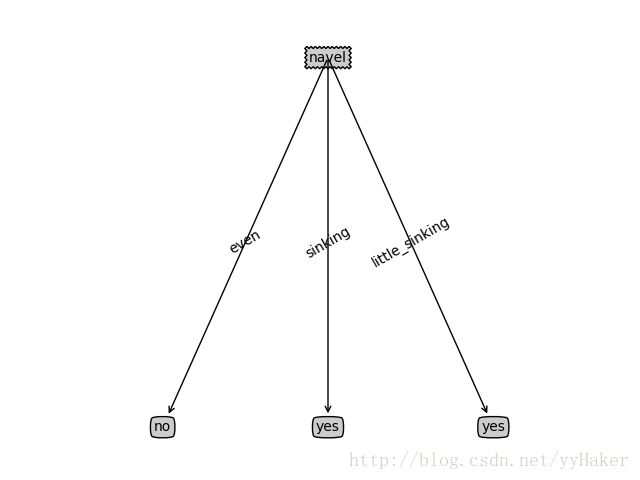
5.2.2 预剪枝,预测准确率:0.6667 得到决策树如下:
5.2.3 后剪枝,预测准确率:0.6667 得到决策树如下:
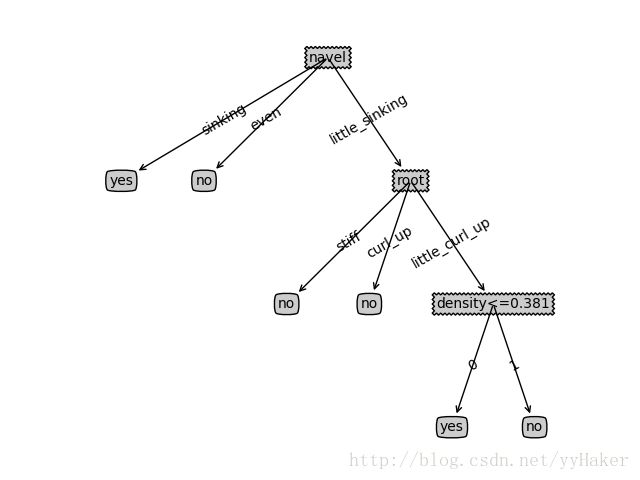
5.2.4 只选取数据集合中连续属性:
a.不剪枝 准确率0.8333 得到决策树
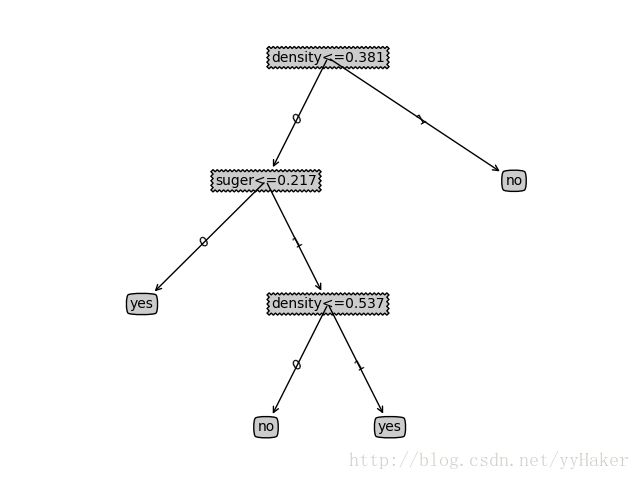
b.预剪枝 准确率 0.6667 得到决策树
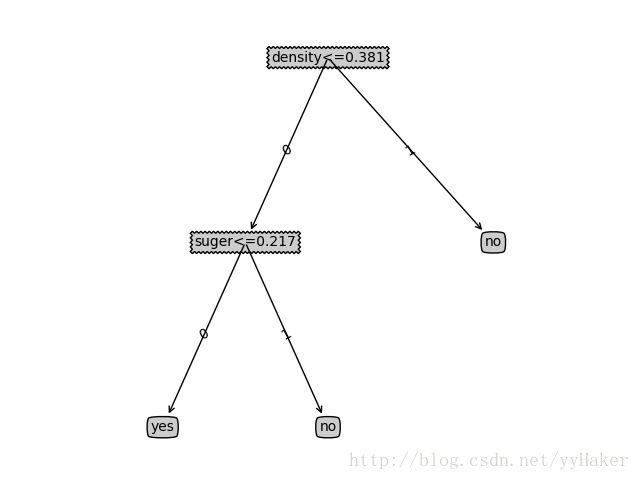
c.后剪枝 准确率 0.6667 得到决策树
详细代码请参考我的github:https://github.com/yyHaker/MachineLearning/tree/master/MLaction-master/Ch03_DT/treeCART
如有问题,请指正,一起学习,谢谢!
参考网址以及书籍:
1.周志华《机器学习》
2.使用CART实现预剪枝、后剪枝:http://blog.csdn.net/sysu_cis/article/details/51874229