论文总结-交通预测(未完成)
通过找文献、下载文献、精读文献,向好的文章学习,具体化、实例化的总结归纳每一篇文章!不要浪费时间在劣质文章和试读文章,要多多花费时间在精读文章上~~学会使用《中国计算机学会推荐国际学术会议和期刊目录》
Sci论文期刊检索|文献检索求助互助 - Sci-Hub|Scidown
dblp: computer science bibliography
Sci-Hub:SciHub科研学术网址导航
目录
0.概况
一、研究背景
1.1目前方法的局限
1.2研究的意义
1.3本文主要贡献
二、本文方法
2.1两类方法
具体化
model
2.2具体实现
A参数回归和非参数回归
参数回归:
非参数回归:
B深度学习
C集成学习方法
2.3方法论
A问题描述
B使用CNN进行时空表示
C对交通预测的集成学习
算法:
三、实验分析
A数据集和实验设置
(1)数据集描述和数据预处理
(2)模型架构
B评价指标
C结果和讨论
实验对比
成功项目展示
四、文献拓展
0.概况
文献名称:Acting as a Decision Maker:Traffic-Condition-Aware Ensemble Learning for Traffic Flow Prediction
本地位置:/Users/yueying/Desktop/others/ml
期刊:IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS
发表时间:2020
关键词:Traffic flow prediction,ensemble learning,deep learning
数据集:Caltrans Performance Measurement System 网址:http://pems.dot.ca.gov/
权威数据:交通领域科研常用数据集总结与分享
真正意义上读懂一篇文献,是深入浅出,用最简单的语言讲述复杂的问题,具体的模型和方法远远没有弄懂这篇论文“在干什么”重要。
一、研究背景
由于交通流时间序列中复杂的不稳定的时间动态化&公路网络的空间依赖性(就是指当地理空间中某一点的值依赖于和它相邻的另一点的值时,就产生了空间依赖性,于是在这一个地理空间中各个点的值都会影响相邻的其他点的值。)目前没有很有优势的方法
1.1目前方法的局限
没有假设一个交通流量模型去描述交通系统的动态性;
没有一个交通模型可以一直优于其他模型,在任意交通状况,对于任意数据集;原因:(1)由于交通流时间序列中复杂的不稳定的时间动态化&公路网络的空间依赖性难以建模(2)一个单独模型难以概括不同的交通状况
1.2研究的意义
有重要意义:for both proactive traffic control and traveler information service
1.3本文主要贡献
(1)设计出了一个集成学习框架:TCAE——Traffic-Condition-Aware-Ensemble 改善了交通预测的性能;
(2)构造了CNN模型,通过提取时空特征,卷积操作提取时间特征,池化操作提取空间特征;
(3)作者实验证明了TCAE的性能优于SVR,LSTM,HA,WR,GBRT
二、本文方法
2.1两类方法
(1)基于模型的[例如macroscopic model, mesoscopic model, microscopic model]
(2)大数据驱动的[建立一个mapping] 【作者集中讲述】
具体化
集成学习vs GBRT SVR LSTM HA
公式:

 是一个集成模型,
是一个集成模型, 是基模型,
是基模型, 是基模型的权重;
是基模型的权重;

上图展示:不同(SVR和LSTM)基模型的性能;
(a)LSTM预测在目标值的上面,SVR预测在目标值的下面;
(b)LSTM和SVR均在目标值的下面;
(c)LSTM和SVR均在目标值的上面;
model
本文使用CNN获取交通流中的spatiotemporal时空特征,提取高水平的特征,生成权重。
2.2具体实现
本文提出了一个集成学习框架:两个必不可少的模型分别是交通状况识别和动态权重生成
A参数回归和非参数回归
参数回归:
ARIMA(Autoregressive Integrated Moving Average 时间序列自回归整合移动模型):预测交通容量 1980's 首先识别出3个模型参数,![]() ,
, 代表自回归项的数量,
代表自回归项的数量,  代表差分阶数,
代表差分阶数,  代表移动平均项的数量。
代表移动平均项的数量。
很多研究者提出了它的变体:Kohonen ARIMA, subsetARIMA, ARIMA with explanatory variables, and Seasonal ARIMA;
vs ARIMA:卡尔曼滤波也是一种参数回归的方法;
ARIMA(p,d,q)模型原理及其实现 --------python_English Chan的博客-CSDN博客_arima模型表达式怎么写
参数回归不适合预测快速变化的样本 => 非参数回归。
非参数回归:
非参数回归的方法例如:SVR(support vector regression支持向量机回归),KNN(k-nearest neighbors最邻近分类)
机器学习笔记 - 什么是支持向量回归(SVR)?_坐望云起的博客-CSDN博客_支持向量机回归
机器学习之KNN最邻近分类算法_pengjunlee的博客-CSDN博客_knn分类算法
KNN算法(一) KNN算法原理_~风凌天下~的博客-CSDN博客_knn
B深度学习
DNN深度神经网络算法比传统的参数回归和非参数回归方法性能更高,主要使用的体系结构有:DFN深度前反馈网络,RNN循环神经网络,CNN卷积神经网络...
C集成学习方法
同质弱学习器:bagging(基础模型根据不同的训练实例集进行训练,然后对其输出直接取平均值进行回归或多数投票进行分类) & boosting(训练一系列基模型在同一时间计算出权重);
异质弱学习器:stacking(先训练基模型,然后再训练一个高水平的模型或元模型,把基类模型的输出当作输入);
集成学习方法可以减少模型种类,提高预测精度;
列举最近的研究...
2.3方法论
A问题描述
把观测到的交通数据(交通容量、行程时间)和外部信息(例如极端天气)映射到目标交通流量预测,定义一个交通流矩阵:

![]() 代表探测器
代表探测器  在时间
在时间  的交通流,矩阵里面存放的是历史探测数据;
的交通流,矩阵里面存放的是历史探测数据;![]() 代表探测器
代表探测器  在时间
在时间 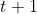 的交通流估计值;映射函数可以表示为
的交通流估计值;映射函数可以表示为 ![]()
B使用CNN进行时空表示


把式(5)代入式(4)得到式(6) ![]() ;
;
我们重复迭代式(6)从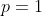 至
至 ![]() ,我们得到卷积操作在特征向量
,我们得到卷积操作在特征向量 ![]() 基础上的特征向量
基础上的特征向量![]() ;如果有
;如果有 个探测器,输出特征的维度是:
个探测器,输出特征的维度是:![]() ,写作
,写作![]() .
.
一层filter卷积输出一个feature map,池化输出的 ![]() 元素 在特征向量
元素 在特征向量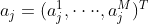 是
是 ![o_{j}^{q}=f(\beta max[a_{j}^{q},\cdot \cdot \cdot ,a_{j}^{q+m-1}]+b)](http://img.e-com-net.com/image/info8/3c6e332147a34691ac004f472fad04f5.gif) ,
, 是乘法的偏置,
是乘法的偏置, 是加法的偏置,
是加法的偏置, 是池化窗口的尺寸。是激活函数,池化的输出可以写作:
是池化窗口的尺寸。是激活函数,池化的输出可以写作:

卷积操作和池化操作之后,最新的输出map传递到全连接神经网络层,输出权重向量:![]() .
.
C对交通预测的集成学习
(1)增强精度;
(2)减少误差;
一个相加模型:
![]()
![]() 是使用CNN学习到的权重,
是使用CNN学习到的权重,![]() 是
是![]() 交通预测器的输出;
交通预测器的输出;
定义损失函数:
![]()
 算法:
算法:

三、实验分析
实验证明了作者预测的高性能:
A数据集和实验设置
(1)数据集描述和数据预处理
作者使用交通领域科研常用数据集:Caltrans PeMS,是California的交通大数据系统,地图上显示的交通数据是从39000多个单独的探测器中实时收集的,这些传感器跨越了California所有主要都会区的高速公路,数据量非常之大、之全。
147个机动车探测器,数据时间跨度:一年中363天,从上午6点到下午十点;
用箱形图表示数据集,表示出最小值、上四分位数、中位数、下四分位数和最大值:

对数据集进行z- score标准化处理,公式如下:![]()
前50个数据用来计算,147分数据用来当作输入,前80%用作训练集,后20%用作测试集。
上图绘出了工作日和周末高速公路交通流;
为充分利用时空特征,时间序列特征向量  :由连续的6个交通流点组成,命名为
:由连续的6个交通流点组成,命名为![]() ,显示地显示出了机动车探测点位置的时间依赖性,数据集包含了147个机动车探测点位置(VDS ),交通矩阵
,显示地显示出了机动车探测点位置的时间依赖性,数据集包含了147个机动车探测点位置(VDS ),交通矩阵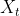 包含了所有机动车探测点位置的特征向量,表示为:
包含了所有机动车探测点位置的特征向量,表示为:
![]()
(2)模型架构
Pytorch & scikit-learn
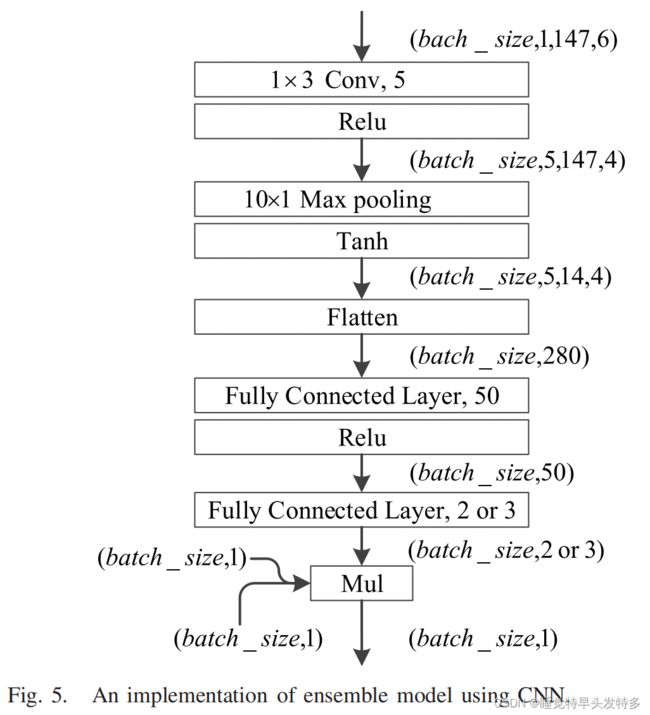
WRegression的预测值  写作
写作 ![]() ,
,![]() 是基模型的预测值,
是基模型的预测值,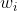 是它的权重。
是它的权重。
B评价指标
MAE
RMASE
MRE
C结果和讨论
实验对比
成功项目展示
四、文献拓展
文献总结模版参考:文献Review:基于端元可变光谱分解的多时相遥感影像变化检测方法_harden1013的博客-CSDN博客
机器学习 - Ensemble Model - 知乎
自动回归移动模型 - 小司 - 博客园
移动平均线研判(Moving average) - 道客巴巴
Bagging与Boosting的区别与联系_我对算法一无所知的博客-CSDN博客_bagging和boosting的区别
常用的模型集成方法介绍:bagging、boosting、stacking
集成学习方法之Bagging,Boosting,Stacking_天才厨师1号的博客-CSDN博客_bagging、boosting、stacking
ImportError: cannot import name 'tqdm' from partially initialized module 'tqdm' (most likely due to a circular import) (/Users/yueying/coding2022/tqdm.py)
解绝:ImportError: cannot import name XXX from partially initialized module XXX (most likely_沫小希的博客-CSDN博客
python3中,socket使用send函数时出现的错误:TypeError: a bytes-like object is required, not 'str'_code的魅力的博客-CSDN博客