【翻译】Coordinate Attention for Efficient Mobile Network Design
Coordinate Attention for Efficient Mobile Network Design
高效移动网络设计的坐标关注力
Qibin Hou, Daquan Zhou, Jiashi Feng
论文:Coordinate Attention for Efficient Mobile Network Design
项目:https://github.com/Andrew-Qibin/CoordAttention
如有侵权,请联系删除。
文章目录
- Abstract(摘要)
- 1. Introduction(介绍)
- 2. Related Work(相关工作)
-
- 2.1. Mobile Network Architectures(移动网络架构)
- 2.2. Attention Mechanisms(注意力机制)
- 3. Coordinate Attention(坐标注意力)
-
- 3.1. Revisit Squeeze-and-Excitation Attention(重新审视SE注意力)
- 3.2. Coordinate Attention Blocks(坐标注意力块)
-
- 3.2.1 Coordinate Information Embedding(坐标信息嵌入)
- 3.2.2 Coordinate Attention Generation(坐标注意力的产生)
- 3.3. Implementation(实施)
- 4. Experiments(实验)
-
- 4.1. Experiment Setup(实验设置)
- 4.2. Ablation Studies(消融实验)
- 4.3. Comparison with Other Methods(与其他模型的对比)
- 4.4. Applications(应用)
-
- 4.4.1 Object Detection(目标检测)
- 4.4.2 Semantic Segmentation(语义分割)
- 5. Conclusions(结论)
Abstract(摘要)
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a novel attention mechanism for mobile networks by embedding positional information into channel attention, which we call “coordinate attention”. Unlike channel attention that transforms a feature tensor to a single feature vector via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively. In this way, long-range dependencies can be captured along one spatial direction and meanwhile precise positional information can be preserved along the other spatial direction. The resulting feature maps are then encoded separately into a pair of direction-aware and position-sensitive attention maps that can be complementarily applied to the input feature map to augment the representations of the objects of interest. Our coordinate attention is simple and can be flexibly plugged into classic mobile networks, such as MobileNetV2, MobileNeXt, and EfficientNet with nearly no computational overhead. Extensive experiments demonstrate that our coordinate attention is not only beneficial to ImageNet classification but more interestingly, behaves better in down-stream tasks, such as object detection and semantic segmentation. Code is available at https://github.com/Andrew-Qibin/CoordAttention.
最近关于移动网络设计的研究表明,通道注意力(如压缩和激励注意力(SE注意力))对提高模型性能有显著的效果,但它们通常忽略了位置信息,而位置信息对产生空间选择性注意力图很重要。在本文中,我们提出了一种新的移动网络注意力机制,这种注意力机制将位置信息嵌入到通道注意力中,我们称之为 “坐标注意力”。与通过二维全局池化将特征张量转化为单一特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向汇集特征。通过这种方式,可以沿一个空间方向捕获长距离的依赖性,同时可以沿另一个空间方向保留精确的位置信息。然后,产生的特征图被分别编码为一对方向感知和位置敏感的注意力图,它们可以互补地应用于输入特征图,以增强对感兴趣的目标的表征。我们的坐标注意力很简单,可以灵活地插入到经典的移动网络中,如MobileNetV2、MobileNeXt和EfficientNet,几乎没有计算开销。大量的实验表明,我们的坐标注意力不仅有利于ImageNet的分类,而且更有趣的是,在下游任务中表现得更好,如目标检测和语义分割。代码可在https://github.com/Andrew-Qibin/CoordAttention获得。
1. Introduction(介绍)
Attention mechanisms, used to tell a model “what” and “where” to attend, have been extensively studied [47, 29] and widely deployed for boosting the performance of modern deep neural networks [18, 44, 3, 25, 10, 14]. However, their application for mobile networks (with limited model size) significantly lags behind that for large networks [36, 13, 46]. This is mainly because the computational overhead brought by most attention mechanisms is not affordable for mobile networks.
用于告诉模型"什么"和"哪里"需要注意的注意力机制已被广泛研究[47, 29],并被广泛的应用来提高现代深度神经网络的性能[18, 44, 3, 25, 10, 14]。然而,它们在移动网络中的应用(模型大小有限)明显落后于大型网络的应用[36, 13, 46]。这主要是因为大多数注意力机制所带来的计算开销是移动网络所不能承受的。
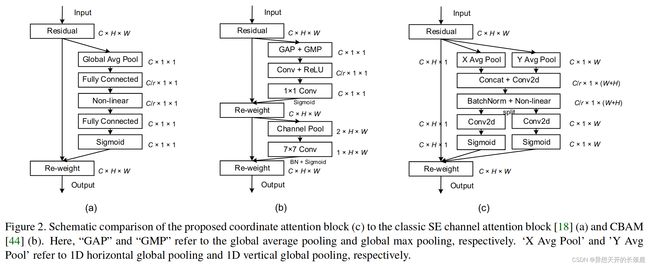
Considering the restricted computation capacity of mobile networks, to date, the most popular attention mechanism for mobile networks is still the Squeeze-and-Excitation (SE) attention [18]. It computes channel attention with the help of 2D global pooling and provides notable performance gains at considerably low computational cost. However, the SE attention only considers encoding inter-channel information but neglects the importance of positional information, which is critical to capturing object structures in vision tasks [42]. Later works, such as BAM [30] and CBAM [44], attempt to exploit positional information by reducing the channel dimension of the input tensor and then computing spatial attention using convolutions as shown in Figure 2(b). However, convolutions can only capture local relations but fail in modeling long-range dependencies that are essential for vision tasks [48, 14].
考虑到移动网络的计算能力有限,到目前为止,最流行的移动网络注意力机制仍然是Squeeze-and-Excitation(SE)注意力[18]。它在二维全局池化的帮助下计算通道注意力,并以相当低的计算成本提供明显的性能提升。然而,SE注意力只考虑了通道间信息的编码,而忽略了位置信息的重要性,而位置信息对于捕捉视觉任务中的目标结构至关重要[42]。后来的工作,如BAM[30]和CBAM[44],试图通过减少输入张量的通道维度来利用位置信息,然后使用卷积计算空间注意力,如图2(b)所示。然而,卷积只能捕捉到局部关系,而不能模拟长距离的依赖关系,而这种依赖关系对于视觉任务是至关重要的[48, 14]。
In this paper, beyond the first works, we propose a novel and efficient attention mechanism by embedding positional information into channel attention to enable mobile networks to attend over large regions while avoiding incurring significant computation overhead. To alleviate the positional information loss caused by the 2D global pooling, we factorize channel attention into two parallel 1D feature encoding processes to effectively integrate spatial coordinate information into the generated attention maps. Specifically, our method exploits two 1D global pooling operations to respectively aggregate the input features along the vertical and horizontal directions into two separate directionaware feature maps. These two feature maps with embedded direction-specific information are then separately encoded into two attention maps, each of which captures longrange dependencies of the input feature map along one spatial direction. The positional information can thus be preserved in the generated attention maps. Both attention maps are then applied to the input feature map via multiplication to emphasize the representations of interest. We name the proposed attention method as coordinate attention as its operation distinguishes spatial direction (i.e., coordinate) and generates coordinate-aware attention maps.
在本文中,在第一个工作之外,我们通过将位置信息嵌入到通道注意力中,提出了一种新颖、高效的注意力机制,使移动网络能够在大区域内进行关注,同时避免产生大量的计算开销。为了缓解二维全局池化所造成的位置信息损失,我们将通道注意力分解为两个平行的一维特征编码过程,以有效地将空间坐标信息整合到生成的注意力图中。具体来说,我们的方法利用两个一维全局池化操作,将沿垂直和水平方向的输入特征分别汇总为两个独立的方向感知特征图。然后,这两个具有嵌入式方向特定信息的特征图被分别编码为两个注意力图,每个注意力图都能捕捉到沿一个空间方向的输入特征图的远距离依赖关系。因此,位置信息可以在生成的注意图中得到保留。然后,两个注意图都通过乘法应用于输入特征图,以强调感兴趣的表征。我们将提出的注意力方法命名为坐标注意,因为它的操作区分了空间方向(即坐标),并产生了坐标意识的注意图。
Our coordinate attention offers the following advantages. First of all, it captures not only cross-channel but also direction-aware and position-sensitive information, which helps models to more accurately locate and recognize the objects of interest. Secondly, our method is flexible and light-weight, and can be easily plugged into classic building blocks of mobile networks, such as the inverted residual block proposed in MobileNetV2 [34] and the sandglass block proposed in MobileNeXt [49], to augment the features by emphasizing informative representations. Thirdly, as a pretrained model, our coordinate attention can bring significant performance gains to down-stream tasks with mobile networks, especially for those with dense predictions (e.g., semantic segmentation), which we will show in our experiment section.
我们的坐标注意力具有以下优势。首先,它不仅能捕捉到跨通道的信息,还能捕捉到方向感知和位置敏感的信息,这有助于模型更准确地定位和识别感兴趣的目标。其次,我们的方法灵活而轻便,可以很容易地插入移动网络的经典构建模块,如MobileNetV2[34]中提出的倒置残差块和MobileNeXt[49]中提出的sandglass块,通过强调信息表征来增强特征。第三,作为一个预训练的模型,我们的坐标注意力可以为移动网络的下游任务带来显著的性能提升,特别是对于那些有密集预测的任务(如语义分割),我们将在实验部分展示。
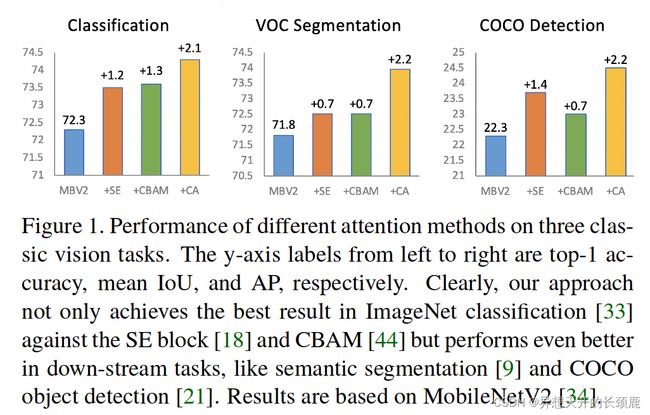
To demonstrate the advantages of the proposed approach over previous attention methods for mobile networks, we conduct extensive experiments in both ImageNet classification [33] and popular down-stream tasks, including object detection and semantic segmentation. With a comparable amount of learnable parameters and computation, our network achieves 0.8% performance gain in top-1 classification accuracy on ImageNet. In object detection and semantic segmentation, we also observe significant improvements compared to models with other attention mechanisms as shown in Figure 1. We hope our simple and efficient design could facilitate the development of attention mechanisms for mobile networks in the future.
为了证明所提出的方法相对于以前的移动网络注意力方法的优势,我们在ImageNet分类[33]和流行的下游任务中进行了广泛的实验,包括目标检测和语义分割。在可学习的参数和计算量相当的情况下,我们的网络在ImageNet上实现了0.8%的top-1分类精度的性能提升。在目标检测和语义分割方面,我们也观察到与其他注意力机制的模型相比有明显的改进,如图1所示。我们希望我们简单而高效的设计能够促进未来移动网络注意力机制的发展。
2. Related Work(相关工作)
In this section, we give a brief literature review of this paper, including prior works on efficient network architecture design and attention or non-local models.
在这一节中,我们对本文进行了简要的文献回顾,包括之前关于高效网络架构设计和注意力或非局部模型的工作。
2.1. Mobile Network Architectures(移动网络架构)
Recent state-of-the-art mobile networks are mostly based on the depthwise separable convolutions [16] and the inverted residual block [34]. HBONet [20] introduces down-sampling operations inside each inverted residual block for modeling the representative spatial information. ShuffleNetV2 [27] uses a channel split module and a channel shuffle module before and after the inverted residual block. Later, MobileNetV3 [15] combines with neural architecture search algorithms [50] to search for optimal activation functions and the expansion ratio of inverted residual blocks at different depths. Moreover, MixNet [39], EfficientNet [38] and ProxylessNAS [2] also adopt different searching strategies to search for either the optimal kernel sizes of the depthwise separable convolutions or scalars to control the network weight in terms of expansion ratio, input resolution, network depth and width. More recently, Zhou et al. [49] rethought the way of exploiting depthwise separable convolutions and proposed MobileNeXt that adopts a classic bottleneck structure for mobile networks.
最近最先进的移动网络大多是基于深度可分离卷积[16]和倒置残差块[34]。HBONet[20]在每个倒置的残差块内引入了下采样操作,用于对代表性的空间信息进行建模。ShuffleNetV2[27]在倒置的残差块前后使用了一个通道分割模块和一个通道shuffle模块。后来,MobileNetV3[15]与神经结构搜索算法[50]相结合,搜索最佳激活函数和不同深度的倒置残差块的扩展率。此外,MixNet[39]、EfficientNet[38]和ProxylessNAS[2]也采用了不同的搜索策略,在扩展率、输入分辨率、网络深度和宽度方面搜索深度可分离卷积的最优核大小或控制网络权重的标量。最近,Zhou等人[49]重新思考了利用纵深可分离卷积的方式,并提出了MobileNeXt,它采用了移动网络的经典瓶颈结构。
2.2. Attention Mechanisms(注意力机制)
Attention mechanisms [41, 40] have been proven helpful in a variety of computer vision tasks, such as image classification [18, 17, 44, 1] and image segmentation [14, 19, 10]. One of the successful examples is SENet [18], which simply squeezes each 2D feature map to efficiently build interdependencies among channels. CBAM [44] further advances this idea by introducing spatial information encoding via convolutions with large-size kernels. Later works, like GENet [17], GALA [22], AA [1], and TA [28], extend this idea by adopting different spatial attention mechanisms or designing advanced attention blocks.
注意力机制[41, 40]已被证明有助于各种计算机视觉任务,如图像分类[18, 17, 44, 1]和图像分割[14, 19, 10]。其中一个成功的例子是SENet[18],它简单地压缩每个二维特征图以有效地建立通道之间的相互依赖关系。CBAM[44]通过引入大尺寸核的卷积进行空间信息编码,进一步推进了这一想法。后来的工作,如GENET[17]、GALA[22]、AA[1]和TA[28],通过采用不同的空间注意力机制或设计先进的注意块来扩展这个想法。
Non-local/self-attention networks are recently very popular due to their capability of building spatial or channelwise attention. Typical examples include NLNet [43], GCNet [3], A2Net [7], SCNet [25], GSoP-Net [11], or CCNet [19], all of which exploit non-local mechanisms to capture different types of spatial information. However, because of the large amount of computation inside the selfattention modules, they are often adopted in large models [13, 46] but not suitable for mobile networks.
非局部/自注意力网络最近非常流行,因为它们有能力建立空间或通道上的注意力。典型的例子包括NLNet[43]、GCNNet[3]、A2Net[7]、SCNet[25]、GSoP-Net[11]或CCNNet[19],它们都利用非局部机制来捕捉不同类型的空间信息。然而,由于自注意力模块内部有大量的计算,它们通常在大型模型中被采用[13, 46],但不适合移动网络。
Different from these approaches that leverage expensive and heavy non-local or self-attention blocks, our approach considers a more efficient way of capturing positional information and channel-wise relationships to augment the feature representations for mobile networks. By factorizing the 2D global pooling operations into two one-dimensional encoding processes, our approach performs much better than other attention methods with the lightweight property (e.g., SENet [18], CBAM [44], and TA [28]).
与这些利用昂贵和沉重的非局部或自注意力块的方法不同,我们的方法考虑了一种更有效的捕捉位置信息和通道关系的方式,以增强移动网络的特征表示。通过将二维全局池化操作分解为两个一维编码过程,我们的方法比其他具有轻量级特性的注意力方法(如SENet[18]、CBAM[44]和TA[28])表现得更好。
3. Coordinate Attention(坐标注意力)
A coordinate attention block can be viewed as a computational unit that aims to enhance the expressive power of the learned features for mobile networks. It can take any intermediate feature tensor X = [ x 1 , x 2 , . . . , x C ] ∈ R C × H × W X = [x_1, x_2, . . . , x_C ] ∈\mathbb{R}^{C×H×W} X=[x1,x2,...,xC]∈RC×H×W as input and outputs a transformed tensor with augmented representations Y = [ y 1 , y 2 , . . . , y C ] Y = [y_1, y_2, . . . , y_C ] Y=[y1,y2,...,yC] of the same size to X X X. To provide a clear description of the proposed coordinate attention, we first revisit the SE attention, which is widely used in mobile networks.
一个坐标注意块可以被看作是一个计算单元,其目的是提高移动网络学习特征的表达能力。它可以将任何中间特征张量 X = [ x 1 , x 2 , . . , x C ] ∈ R C × H × W X = [x_1, x_2, . . , x_C ] ∈\mathbb{R}^{C×H×W} X=[x1,x2,..,xC]∈RC×H×W作为输入,并输出一个与 X X X相同大小的具有增强表示的变换张量 Y = [ y 1 , y 2 , . . , y C ] Y = [y_1, y_2, . . , y_C ] Y=[y1,y2,..,yC]。为了清楚地描述所提出的坐标注意力,我们首先重新审视SE注意力,它被广泛用于移动网络中。
3.1. Revisit Squeeze-and-Excitation Attention(重新审视SE注意力)
As demonstrated in [18], the standard convolution itself is difficult to model the channel relationships. Explicitly building channel inter-dependencies can increase the model sensitivity to the informative channels that contribute more to the final classification decision. Moreover, using global average pooling can also assist the model in capturing global information, which is a lack for convolutions.
如[18]所示,标准卷积本身很难对通道关系进行建模。明确建立通道间的依赖关系可以提高模型对信息通道的敏感性,这些通道对最终的分类决策贡献更大。此外,使用全局平均池化也可以帮助模型捕捉全局信息,这也是卷积的不足。
Structurally, the SE block can be decomposed into two steps: squeeze and excitation, which are designed for global information embedding and adaptive recalibration of channel relationships, respectively. Given the input X X X , the squeeze step for the c c c-th channel can be formulated as follows:
从结构上看,SE块可以分解为两个步骤:压缩和激励,它们分别用于全局信息嵌入和通道关系的适应性再校准。给定输入 X X X,第 c c c个通道的挤压步骤可以表述为:。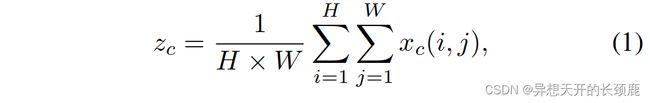
where z c z_c zc is the output associated with the c c c-th channel. The input X X X is directly from a convolutional layer with a fixed kernel size and hence can be viewed as a collection of local descriptors. The squeeze operation makes collecting global information possible.
其中 z c z_c zc是与第 c c c个通道相关的输出。输入的 X X X直接来自具有固定核大小的卷积层,因此可以被看作是局部描述符的集合。压缩操作使得收集全局信息成为可能。
The second step, excitation, aims to fully capture channel-wise dependencies, which can be formulated as
第二步,激励,目的是充分捕捉通道的依赖性,可以表述为
where ⋅ · ⋅ refers to channel-wise multiplication, σ σ σ is the sigmoid function, and z ^ \hat{z} z^ is the result generated by a transformation function, which is formulated as follows:
其中, ⋅ · ⋅指的是通道级的乘法, σ σ σ是sigmoid函数, z ^ \hat{z} z^是由转换函数产生的结果,其表述如下。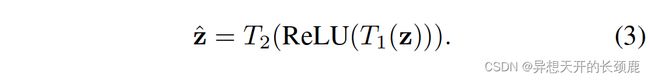
Here, T 1 T_1 T1 and T 2 T_2 T2 are two linear transformations that can be learned to capture the importance of each channel.
这里, T 1 T_1 T1和 T 2 T_2 T2是两个线性变换,可以通过学习来捕捉每个通道的重要性。
The SE block has been widely used in recent mobile networks [18, 4, 38] and proven to be a key component for achieving state-of-the-art performance. However, it only considers reweighing the importance of each channel by modeling channel relationships but neglects positional information, which as we will prove experimentally in Section 4 to be important for generating spatially selective attention maps. In the following, we introduce a novel attention block, which takes into account both inter-channel relationships and positional information.
SE块已被广泛用于最近的移动网络中[18, 4, 38],并被证明是实现最先进性能的一个关键组成部分。然而,它只考虑了通过对通道关系的建模来重新权衡每个通道的重要性,但忽略了位置信息,正如我们将在第4节中通过实验证明的那样,位置信息对于生成空间选择性注意力图是很重要的。在下文中,我们将介绍一个新的注意块,它同时考虑到通道间的关系和位置信息。
3.2. Coordinate Attention Blocks(坐标注意力块)
Our coordinate attention encodes both channel relationships and long-range dependencies with precise positional information in two steps: coordinate information embedding and coordinate attention generation. The diagram of the proposed coordinate attention block can be found in the right part of Figure 2. In the following, we will describe it in detail.
我们的坐标注意在两个步骤中对通道关系和长距离依赖的精确位置信息进行编码:坐标信息嵌入和坐标注意力生成。图2的右边部分是所提出的坐标注意模块的示意图。在下文中,我们将详细描述它。
3.2.1 Coordinate Information Embedding(坐标信息嵌入)
The global pooling is often used in channel attention to encode spatial information globally, but it squeezes global spatial information into a channel descriptor and hence is difficult to preserve positional information, which is essential for capturing spatial structures in vision tasks. To encourage attention blocks to capture long-range interactions spatially with precise positional information, we factorize the global pooling as formulated in Eqn. (1) into a pair of 1D feature encoding operations. Specifically, given the input X X X, we use two spatial extents of pooling kernels ( H , 1 ) (H, 1) (H,1) or ( 1 , W ) (1, W ) (1,W) to encode each channel along the horizontal coordinate and the vertical coordinate, respectively. Thus, the output of the c c c-th channel at height h h h can be formulated as
全局池化在通道注意力中经常被用来对空间信息进行全局编码,但它将全局空间信息挤压到通道描述符中,因此很难保留位置信息,而位置信息对捕捉视觉任务中的空间结构至关重要。为了鼓励注意力区块以精确的位置信息来捕捉长距离的空间互动,我们将公式(1)中表述的全局集合分解为一对一维特征编码操作。具体来说,给定输入 X X X,我们使用两个空间范围的集合核 ( H , 1 ) (H, 1) (H,1)或 ( 1 , W ) (1, W ) (1,W)分别沿横坐标和纵坐标对每个通道进行编码。因此,高度为 h h h的第 c c c个通道的输出可以被表述为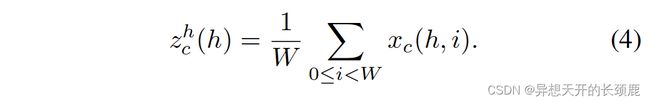
Similarly, the output of the c c c-th channel at width w w w can be written as
类似地,宽度为 w w w的第 c c c通道的输出可以写成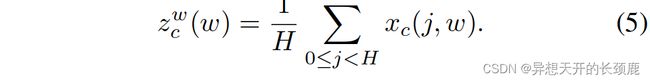
The above two transformations aggregate features along the two spatial directions respectively, yielding a pair of direction-aware feature maps. This is rather different from the squeeze operation (Eqn. (1)) in channel attention methods that produce a single feature vector. These two transformations also allow our attention block to capture long-range dependencies along one spatial direction and preserve precise positional information along the other spatial direction, which helps the networks more accurately locate the objects of interest.
上述两种变换分别沿两个空间方向聚集特征,产生一对方向感知的特征图。这与通道注意方法中产生单一特征向量的挤压操作(公式(1))相当不同。这两个转换还允许我们的注意力块沿一个空间方向捕捉长距离的依赖性,并沿另一个空间方向保留精确的位置信息,这有助于网络更准确地定位感兴趣的物体。
3.2.2 Coordinate Attention Generation(坐标注意力的产生)
As described above, Eqn. (4) and Eqn. (5) enable a global receptive field and encode precise positional information. To take advantage of the resulting expressive representations, we present the second transformation, termed coordinate attention generation. Our design refers to the following three criteria. First of all, the new transformation should be as simple and cheap as possible regarding the applications in mobile environments. Second, it can make full use of the captured positional information so that the regions of interest can be accurately highlighted. Last but not the least, it should also be able to effectively capture inter-channel relationships, which has been demonstrated essential in existing studies [18, 44].
如上所述,公式(4)和公式(5)实现了全局感受野,并编码了精确的位置信息。为了利用由此产生的表达性表征,我们提出了第二个转换,称为坐标注意力生成。我们的设计指的是以下三个标准。首先,就移动环境中的应用而言,新的转换应该尽可能的简单和低成本。其次,它可以充分利用捕捉到的位置信息,从而使感兴趣的区域能够被准确地突出。最后但最重要的是,它还应该能够有效地捕捉通道间的关系,这在现有的研究中已经被证明是至关重要的[18, 44]。
Specifically, given the aggregated feature maps produced by Eqn. 4 and Eqn. 5, we first concatenate them and then send them to a shared 1 × 1 1 × 1 1×1 convolutional transformation function F 1 F_1 F1, yielding
具体来说,给定由公式4和公式5产生的聚合特征图,我们首先将它们连接起来,然后将它们发送到一个共享的 1 × 1 1×1 1×1卷积变换函数 F 1 F_1 F1,得到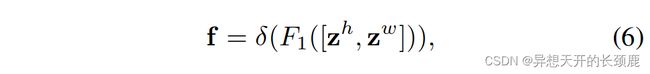
where [·, ·] denotes the concatenation operation along the spatial dimension, δ δ δ is a non-linear activation function and f ∈ R C / r × ( H + W ) \mathbf{f} ∈ \mathbb{R}^{C/r×(H+W)} f∈RC/r×(H+W) is the intermediate feature map that encodes spatial information in both the horizontal direction and the vertical direction. Here, r r r is the reduction ratio for controlling the block size as in the SE block. We then split f \mathbf{f} f along the spatial dimension into two separate tensors f h ∈ R C / r × H \mathbf{f}^h ∈ \mathbb{R}^{C/r×H} fh∈RC/r×H and f w ∈ R C / r × W \mathbf{f}^w ∈ \mathbb{R}^{C/r×W} fw∈RC/r×W . Another two 1 × 1 1 × 1 1×1 convolutional transformations F h F^h Fh and F w F_w Fw are utilized to separately transform f h \mathbf{f}^h fh and f w \mathbf{f}^w fw to tensors with the same channel number to the input X X X, yielding
其中[·, ·]表示沿空间维度的连接操作, δ δ δ是一个非线性激活函数, f ∈ R C / r × ( H + W ) \mathbf{f}∈\mathbb{R}^{C/r×(H+W)} f∈RC/r×(H+W)是中间特征图,在水平方向和垂直方向都编码空间信息。这里, r r r是控制块大小的还原率,与SE块一样。然后我们将 f \mathbf{f} f沿空间维度分割成两个独立的张量 f h ∈ R C / r × H \mathbf{f}^h∈ \mathbb{R}^{C/r×H} fh∈RC/r×H和 f w ∈ R C / r × W \mathbf{f}^w∈ \mathbb{R}^{C/r×W} fw∈RC/r×W 。另有两个 1 × 1 1×1 1×1卷积变换 F h F_h Fh和 F w F_w Fw被利用来分别变换 f h \mathbf{f}^h fh和 f w \mathbf{f}^w fw为输入 X X X的相同通道数的张量,得到
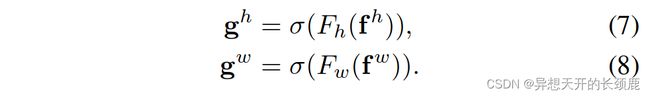
Recall that σ σ σ is the sigmoid function. To reduce the overhead model complexity, we often reduce the channel number of f \mathbf{f} f with an appropriate reduction ratio r r r (e.g., 32). We will discuss the impact of different reduction ratios on the performance in our experiment section. The outputs g h \mathbf{g}^h gh and g w \mathbf{g}^w gw are then expanded and used as attention weights, respectively. Finally, the output of our coordinate attention block Y Y Y can be written as
回顾一下, σ σ σ是sigmoid函数。为了降低开销模型的复杂性,我们经常用一个适当的减少比 r r r(例如32)来减少 f \mathbf{f} f的通道数。我们将在实验部分讨论不同还原比对性能的影响。然后,输出的 g h \mathbf{g}^h gh和 g w \mathbf{g}^w gw分别被展开并作为注意力权重。最后,我们的坐标注意块 Y Y Y的输出可以写为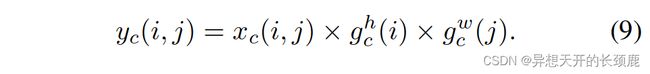
Discussion. Unlike channel attention that only focuses on reweighing the importance of different channels, our coordinate attention block also considers encoding the spatial information. As described above, the attention along both the horizontal and vertical directions is simultaneously applied to the input tensor. Each element in the two attention maps reflects whether the object of interest exists in the corresponding row and column. This encoding process allows our coordinate attention to more accurately locate the exact position of the object of interest and hence helps the whole model to recognize better. We will demonstrate this exhaustively in our experiment section.
讨论。与只注重重新权衡不同通道的重要性的通道注意力不同,我们的坐标注意力块还考虑了空间信息的编码。如上所述,沿水平和垂直方向的注意同时应用于输入张量。两个注意图中的每个元素都反映了感兴趣的目标是否存在于相应的行和列中。这个编码过程使我们的坐标注意能够更准确地定位感兴趣的目标的确切位置,从而帮助整个模型更好地识别。我们将在实验部分详尽地证明这一点。
3.3. Implementation(实施)
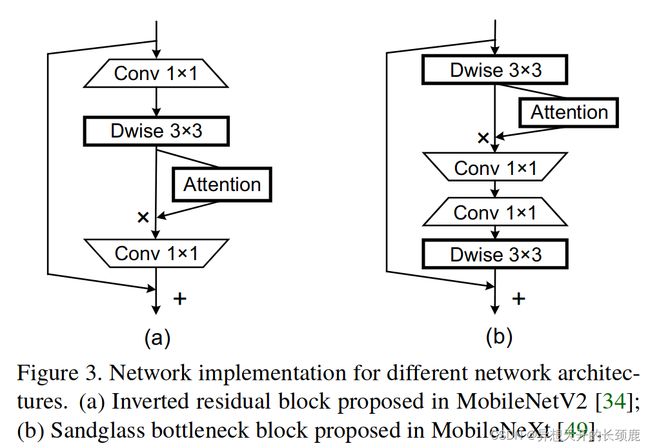
As the goal of this paper is to investigate a better way to augment the convolutional features for mobile networks, here we take two classic light-weight architectures with different types of residual blocks (i.e., MobileNetV2 [34] and MobileNeXt [49]) as examples to demonstrate the advantages of the proposed coordinate attention block over other famous light-weight attention blocks. Figure 3 shows how we plug attention blocks into the inverted residual block in MobileNetV2 and the sandglass block in MobileNeXt.
由于本文的目标是研究一种更好的方法来增强移动网络的卷积特征,这里我们以两个具有不同类型的残差块的经典轻量级架构(即MobileNetV2[34]和MobileNeXt[49])为例来证明所提出的坐标注意力块相对于其他著名的轻量级注意力块的优势。图3显示了我们如何将注意力块插入MobileNetV2的倒残差块和MobileNeXt的沙漏块。
4. Experiments(实验)
In this section, we first describe our experiment settings and then conduct a series of ablation experiments to demonstrate the contribution of each component in the proposed coordinate attention to the performance. Next, we compare our approach with some attention based methods. Finally, we report the results of the proposed approach compared to other attention based methods on object detection and semantic segmentation.
在这一节中,我们首先描述了我们的实验设置,然后进行了一系列的消融实验,以证明所提出的坐标注意力中的每个组成部分对性能的贡献。接下来,我们将我们的方法与一些基于注意力的方法进行比较。最后,我们报告了所提出的方法与其他基于注意力的方法在目标检测和语义分割方面的比较结果。
4.1. Experiment Setup(实验设置)
We use the PyTorch toolbox [31] to implement all our experiments. During training, we use the standard SGD optimizer with decay and momentum of 0.9 to train all the models. The weight decay is set to 4 × 1 0 − 5 4×10^{−5} 4×10−5 always. The cosine learning schedule with an initial learning rate of 0.05 is adopted. We use four NVIDIA GPUs for training and the batch size is set to 256. Without extra declaration, we take MobileNetV2 as our baseline and train all the models for 200 epochs. For data augmentation, we use the same methods as in MobileNetV2. We report results on the ImageNet dataset [33] in classification.
我们使用PyTorch工具箱[31]来实现我们所有的实验。在训练过程中,我们使用标准的带衰减的SGD优化器和动量为0.9来训练所有的模型。权重衰减始终设置为 4 × 1 0 − 5 4×10^{-5} 4×10−5。采用初始学习率为0.05的余弦学习计划。我们使用四个NVIDIA GPU进行训练,批次大小被设置为256。在没有额外声明的情况下,我们将MobileNetV2作为基线,对所有的模型进行200次的训练。对于数据增强,我们使用与MobileNetV2相同的方法。我们报告了在ImageNet数据集[33]上的分类结果。
4.2. Ablation Studies(消融实验)
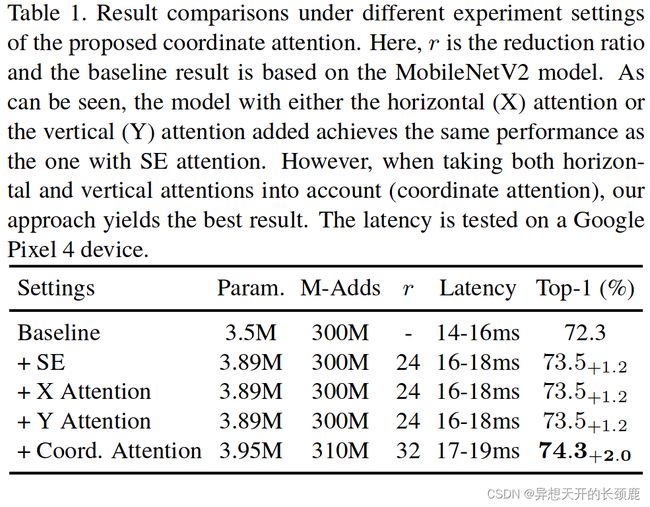
Importance of coordinate attention. To demonstrate the performance of the proposed coordinate attention, we perform a series of ablation experiments, the corresponding results of which are all listed in Table 1. We remove either the horizontal attention or the vertical attention from the coordinate attention to see the importance of encoding coordinate information. As shown in Table 1, the model with attention along either direction has comparable performance to the one with the SE attention. However, when both the horizontal attention and the vertical attention are incorporated, we obtain the best result as highlighted in Table 1. These experiments reflect that with comparable learnable parameters and computational cost, coordinate information embedding is more helpful for image classification.
坐标注意力的重要性。为了证明所提出的坐标注意力的性能,我们进行了一系列的消融实验,其相应的结果都列于表1。我们从坐标注意力中去除水平注意力或垂直注意力,以观察编码坐标信息的重要性。如表1所示,沿任何一个方向的注意力的模型都具有与SE注意力的模型相当的性能。然而,当水平注意力和垂直注意力都被纳入时,我们得到了表1中强调的最佳结果。这些实验反映出,在可学习的参数和计算成本相当的情况下,坐标信息嵌入对图像分类更有帮助。
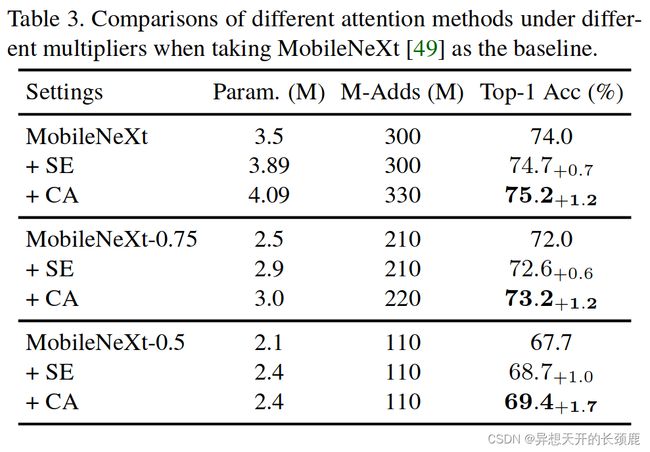
Different weight multipliers. Here, we take two classic mobile networks (including MobileNetV2 [34] with inverted residual blocks and MobileNeXt [49] with sandglass bottleneck block) as baselines to see the performance of the proposed approach compared to the SE attention [18] and CBAM [44] under different weight multipliers. In this experiment, we adopt three typical weight multipliers, including {1.0, 0.75, 0.5}. As shown in Table 2, when taking the MobileNetV2 network as baseline, models with CBAM have similar results to those with the SE attention. However, models with the proposed coordinate attention yield the best results under each setting. Similar phenomenon can also be observed when the MobileNeXt network is used as listed in Table 3. This indicates that no matter which of the sandglass bottleneck block or the inverted residual block is considered and no matter which weight multiplier is selected, our coordinate attention performs the best because of the advanced way to encode positional and inter-channel information simultaneously.
不同的权重乘数。这里,我们以两个经典的移动网络(包括带有倒置残差块的MobileNetV2[34]和带有沙漏瓶颈块的MobileNeXt[49])为基线,来看看在不同的权重乘数下,所提出的方法与SE注意力[18]和CBAM[44]的性能对比。在这个实验中,我们采用了三种典型的权重乘数,包括{1.0, 0.75, 0.5}。如表2所示,当以MobileNetV2网络为基线时,采用CBAM的模型与采用SE注意力的模型有类似的结果。然而,在每一种设置下,采用提出的坐标注意力的模型都能产生最好的结果。当使用MobileNeXt网络时,也可以观察到类似的现象,如表3中所列。这表明,不管是考虑沙漏瓶颈区块还是倒置的残余区块,也不管选择哪一个权重乘数,我们的坐标注意都表现得最好,因为它是同时编码位置和通道间信息的先进方法。

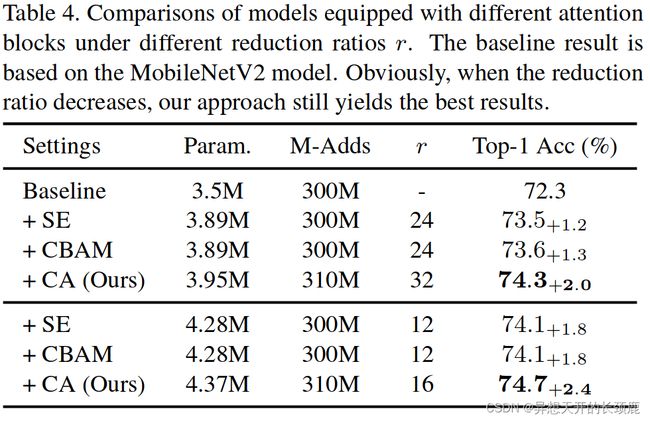
The impact of reduction ratio r r r. To investigate the impact of different reduction ratios of attention blocks on the model performance, we attempt to decrease the size of the reduction ratio and see the performance change. As shown in Table 4, when we reduce r r r to half of the original size, the model size increases but better performance can be yielded. This demonstrates that adding more parameters by reducing the reduction ratio matters for improving the model performance. More importantly, our coordinate attention still performs better than the SE attention and CBAM in this experiment, reflecting the robustness of the proposed coordinate attention to the reduction ratio.
减少 r r r比率的影响。为了研究不同的注意力块的减少比率对模型性能的影响,我们尝试减少减少比率的大小,看看性能的变化。如表4所示,当我们把 r r r减少到原始大小的一半时,模型的大小会增加,但可以产生更好的性能。这表明,通过减少缩减率来增加参数对提高模型性能很重要。更重要的是,在这个实验中,我们的坐标注意力仍然比SE注意力和CBAM表现得更好,反映了所提出的坐标注意力对减少比例的鲁棒性。
4.3. Comparison with Other Methods(与其他模型的对比)
Attention for Mobile Networks. We compare our coordinate attention with other light-weight attention methods for mobile networks, including the widely adopted SE attention [18] and CBAM [44] in Table 2. As can be seen, adding the SE attention has already raised the classification performance by more than 1%. For CBAM, it seems that its spatial attention module shown in Figure 2(b) does not contribute in mobile networks compared to the SE attention. However, when the proposed coordinate attention is considered, we achieve the best results. We also visualize the feature maps produced by models with different attention methods in Figure 4. Obviously, our coordinate attention can help better in locating the objects of interest than the SE attention and CBAM.
移动网络的注意力。我们将我们的坐标注意力与其他用于移动网络的轻量级注意力方法进行比较,包括表2中广泛采用的SE注意力[18]和CBAM[44]。可以看出,加入SE注意力后,分类性能已经提高了1%以上。对于CBAM,与SE注意相比,其图2(b)所示的空间注意力模块似乎在移动网络中没有贡献。然而,当考虑到提出的坐标注意力时,我们取得了最好的结果。我们还在图4中可视化了不同注意力方法的模型所产生的特征图。很明显,我们的坐标注意力比SE注意力和CBAM更能帮助定位感兴趣的目标。
We argue that the advantages of the proposed positional information encoding manner over CBAM are two-fold. First, the spatial attention module in CBAM squeezes the channel dimension to 1, leading to information loss. However, our coordinate attention uses an appropriate reduction ratio to reduce the channel dimension in the bottleneck, avoiding too much information loss. Second, CBAM utilizes a convolutional layer with kernel size 7 × 7 to encode local spatial information while our coordinate attention encodes global information by using two complementary 1D global pooling operations. This enables our coordinate attention to capture long-range dependencies among spatial locations that are essential for vision tasks.
我们认为,与CBAM相比,所提出的位置信息编码方式有两方面的优势。首先,CBAM中的空间注意力模块将通道维度压缩到1,导致信息损失。然而,我们的坐标注意力使用一个适当的减少率来减少瓶颈处的通道维度,避免了过多的信息损失。其次,CBAM利用内核大小为7×7的卷积层来编码局部空间信息,而我们的坐标注意通过使用两个互补的1维全局池化操作来编码全局信息。这使我们的坐标注意能够捕捉到空间位置之间的长距离依赖关系,这对视觉任务是至关重要的。
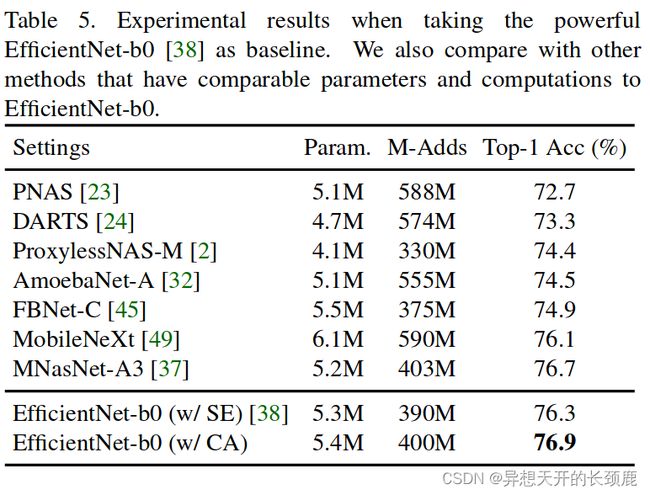
Stronger Baseline. To further demonstrate the advantages of the proposed coordinate attention over the SE attention in more powerful mobile networks, we take EfficientNet-b0 [38] as our baseline here. EfficientNet is based on architecture search algorithms. and contains SE attention. To investigate the performance of the proposed coordinate attention on EfficientNet, we simply replace the SE attention with our proposed coordinate attention. For other settings, we follow the original paper. The results have been listed in Table 5. Compared to the original EfficientNet-b0 with SE attention included and other methods that have comparable parameters and computations to EfficientNet-b0, our network with coordinate attention achieves the best result. This demonstrates that the proposed coordinate attention can still performance well in powerful mobile networks.
更强大的基线。为了进一步证明所提出的坐标注意力在更强大的移动网络中相对于SE注意力的优势,我们在此将EfficientNet-b0[38]作为我们的基线。EfficientNet是基于架构搜索算法的,并包含SE注意力。为了研究EfficientNet上所提出的坐标注意力的性能,我们只是用我们所提出的坐标注意力来代替SE注意力。对于其他的设置,我们遵循原论文的规定。结果已列于表5。与包含SE注意力的原始EfficientNet-b0以及其他与EfficientNet-b0具有可比性的参数和计算方法相比,我们的网络在坐标注意力方面取得了最好的结果。这表明所提出的坐标注意力在强大的移动网络中仍能有良好的表现。
4.4. Applications(应用)
In this subsection, we conduct experiments on both the object detection task and the semantic segmentation task to explore the transferable capability of the proposed coordinate attention against other attention methods.
在本小节中,我们对目标检测任务和语义分割任务进行了实验,以探索所提出的坐标注意力对其他注意力方法的可转移能力。
4.4.1 Object Detection(目标检测)
Implementation Details. Our code is based on PyTorch and SSDLite [34, 26]. Following [34], we connect the first and second layers of SSDLite to the last pointwise convolutions with output stride of 16 and 32, respectively and add the rest SSDLite layers on top of the last convolutional layer. When training on COCO, we set the batch size to 256 and use the synchronized batch normalization. The cosine learning schedule is used with an initial learning rate of 0.01. We train the models for totally 1,600,000 iterations. When training on Pascal VOC, the batch size is set to 24 and all the models are trained for 240,000 iterations. The weight decay is set to 0.9. The initial learning rate is 0.001, which is then divided by 10 at 160,000 and again at 200,000 iterations. For other settings, readers can refer to [34, 26].
实施细节。我们的代码是基于PyTorch和SSDLite[34, 26]。按照[34],我们将SSDLite的第一层和第二层分别连接到输出跨度为16和32的最后一个点阵卷积层,并在最后一个卷积层之上添加其余的SSDLite层。在COCO上训练时,我们将批次大小设置为256,并使用同步的批次归一化。使用余弦学习计划,初始学习率为0.01。我们对模型进行了1,600,000次迭代训练。当在Pascal VOC上训练时,批次大小被设置为24,所有的模型被训练了24万次迭代。权重衰减被设置为0.9。初始学习率为0.001,然后在160,000次和200,000次迭代时除以10。对于其他设置,读者可以参考[34,26]。
Results on COCO. In this experiment, we follow most previous work and report results in terms of AP, AP50, AP75, APS, APM , and APL, respectively. In Table 6, we show the results produced by different network settings on the COCO 2017 validation set. It is obvious that adding coordinate attention into MobileNetV2 substantially improve the detection results (24.5 v.s. 22.3) with only 0.5M parameters overhead and nearly the same computational cost. Compared to other light-weight attention methods, such as the SE attention and CBAM, our version of SSDLite320 achieves the best results in all metrics with nearly the same number of parameters and computations.
关于COCO的结果。在这个实验中,我们遵循大多数以前的工作,分别以AP、AP 50 _{50} 50、AP 75 _{75} 75、AP S _{S} S、AP M _{M} M和AP L _{L} L的方式报告结果。在表6中,我们显示了COCO 2017验证集上不同网络设置产生的结果。很明显,在MobileNetV2中加入坐标关注,在只有0.5M的参数开销和几乎相同的计算成本的情况下,大幅提高了检测结果(24.5 v.s. 22.3)。与其他轻量级的注意力方法,如SE注意力和CBAM相比,我们的SSDLite320版本在所有指标上都取得了最好的结果,而参数和计算的数量几乎相同。
Moreover, we also show results produced by previous state-of-the-art models based on SSDLite320 as listed in Table 6. Note that some methods (e.g., MobileNetV3 [15] and MnasNet-A1 [37]) are based on neural architecture search methods but our model does not. Obviously, our detection model achieves the best results in terms of AP compared to other approaches with close parameters and computations.
此外,我们还展示了以前基于SSDLite320的最先进模型产生的结果,如表6所列。请注意,一些方法(例如MobileNetV3 [15]和MnasNet-A1 [37])是基于神经结构搜索方法的,但我们的模型没有。显然,与其他参数和计算接近的方法相比,我们的检测模型在AP方面取得了最佳结果。

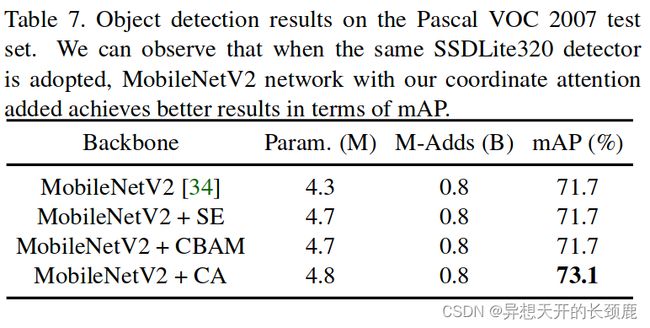
Results on Pascal VOC. In Table 7, we show the detection results on Pascal VOC 2007 test set when different attention methods are adopted. We observe that the SE attention and CBAM cannot improve the baseline results. However, adding the proposed coordinate attention can largely raise the mean AP from 71.7 to 73.1. Both detection experiments on COCO and Pascal VOC datasets demonstrate that classification models with the proposed coordinate attention have better transferable capability compared to those with other attention methods.
Pascal VOC的结果。在表7中,我们显示了采用不同注意力方法时对Pascal VOC 2007测试集的检测结果。我们观察到,SE注意力和CBAM不能改善基线结果。然而,加入提出的坐标注意力可以将平均AP从71.7提高到73.1。在COCO和Pascal VOC数据集上的两个检测实验都表明,与其他注意力方法相比,采用提出的坐标注意力的分类模型具有更好的可转移能力。
4.4.2 Semantic Segmentation(语义分割)
We also conduct experiments on semantic segmentation. Following MobileNetV2 [34], we utilize the classic DeepLabV3 [6] as an example and compare the proposed approach with other models to demonstrate the transferable capability of the proposed coordinate attention in semantic segmentation. Specifically, we discard the last linear operator and connect the ASPP to the last convolutional operator. We replace the standard 3 × 3 convolutional operators with the depthwise separable convolutions in the ASPP to reduce the model size considering mobile applications. The output channels for each branch in ASPP are set to 256 and other components in the ASPP are kept unchanged (including the 1×1 convolution branch and the image-level feature encoding branch). We report results on two widely used semantic segmentation benchmarks, including Pascal VOC 2012 [9] and Cityscapes [8]. For experiment settings, we strictly follow the DeeplabV3 paper except for the weight decay that is set to 4e-5. When the output stride is set to 16, the dilation rates in the ASPP are {6, 12, 18} while {12, 24, 36} when the output stride is set to 8.
我们还对语义分割进行了实验。继MobileNetV2[34]之后,我们利用经典的DeepLabV3[6]作为例子,将所提出的方法与其他模型进行比较,以证明所提出的坐标注意力在语义分割中的可转移能力。具体来说,我们抛弃了最后一个线性算子,将ASPP连接到最后一个卷积算子。我们用ASPP中的深度可分离卷积算子取代标准的3×3卷积算子,以减少考虑到移动应用的模型大小。ASPP中每个分支的输出通道被设置为256,ASPP中的其他组件保持不变(包括1×1卷积分支和图像级特征编码分支)。我们报告了两个广泛使用的语义分割基准的结果,包括Pascal VOC 2012 [9] 和Cityscapes [8]。对于实验设置,我们严格遵循DeeplabV3的论文,除了权重衰减被设置为4e-5。当输出跨度设置为16时,ASPP中的扩张率为{6, 12, 18},而当输出跨度设置为8时,扩张率为{12, 24, 36}。
Results on Pascal VOC 2012. The Pascal VOC 2012 segmentation benchmark has totally 21 classes including one background class. As suggested by the original paper, we use the split with 1,464 images for training and the split with 1,449 images for validation. Also, as done in most previous work [6, 5], we augment the training set by adding extra images from [12], resulting in totally 10,582 images for training.
Pascal VOC 2012的结果。Pascal VOC 2012的分割基准共有21个类,包括一个背景类。根据原论文的建议,我们使用1,464张图像的分割进行训练,使用1,449张图像的分割进行验证。此外,正如大多数以前的工作[6,5]所做的,我们通过添加来自[12]的额外图像来增加训练集,导致总共10,582张图像用于训练。
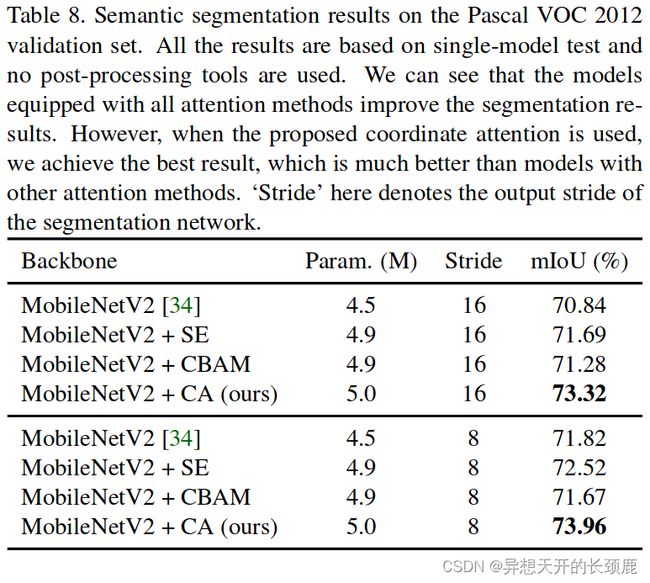
We show the segmentation results when taking different models as backbones in Table 8. We report results under two different output strides, i.e., 16 and 8. Note that all the results reported here are not based on COCO pretraining. According to Table 8, models equipped with our coordinate attention performs much better than the vanilla MobileNetV2 and other attention methods.
我们在表8中显示了以不同模型为骨干网络的分割结果。我们报告了两种不同输出步长下的结果,即16和8。请注意,这里报告的所有结果都不是基于COCO预训练的。根据表8,配备了我们的坐标注意力的模型比原始的MobileNetV2和其他注意力方法表现得更好。
Results on Cityscapes. Cityscapes [8] is one of the most popular urban street scene segmentation datasets, containing totally 19 different categories. Following the official suggestion, we use the split with 2,975 images for training and 500 images for validation. Only the fine-annotated images are used for training. In training, we randomly crop the original images to 768 × 768. During testing, all images are kept the original size (1024 × 2048).
Cityscapes的结果。Cityscapes[8]是最流行的城市街道场景分割数据集之一,共包含19个不同的类别。按照官方的建议,我们使用了2,975张图片进行训练,500张图片进行验证的分割。只有精细注释的图像被用于训练。在训练中,我们将原始图像随机裁剪为768×768。在测试过程中,所有图像都保持原始尺寸(1024×2048)。
In Table 9, we show the segmentation results produced by models with different attention methods on the Cityscapes dataset. Compared to the vanilla MobileNetV2 and other attention methods, our coordinate attention can improve the segmentation results by a large margin with comparable number of learnable parameters.
在表9中,我们显示了采用不同注意力方法的模型在Cityscapes数据集上产生的分割结果。与原始的MobileNetV2和其他注意力方法相比,我们的坐标注意力可以在可学习参数数量相当的情况下大幅提高分割结果。
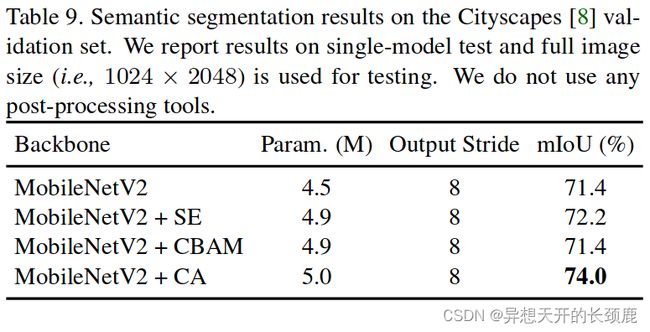
Discussion. We observe that our coordinate attention yields larger improvement on semantic segmentation than ImageNet classification and object detection. We argue that this is because our coordinate attention is able to capture long-range dependencies with precise postional information, which is more beneficial to vision tasks with dense predictions, such as semantic segmentation.
讨论。我们观察到,与ImageNet分类和目标检测相比,我们的坐标注意力在语义分割上产生了更大的改进。我们认为,这是因为我们的坐标注意力能够以精确的姿势信息来捕捉长距离的依赖关系,这对具有密集预测的视觉任务更有利,如语义分割。
5. Conclusions(结论)
In this paper, we present a novel light-weight attention mechanism for mobile networks, named coordinate attention. Our coordinate attention inherits the advantage of channel attention methods (e.g., the Squeeze-andExcitation attention) that model inter-channel relationships and meanwhile captures long-range dependencies with precise positional information. Experiments in ImageNet classification, object detection and semantic segmentation demonstrate the effectiveness of our coordination attention.
在本文中,我们为移动网络提出了一种新的轻量级的注意力机制,名为坐标注意力。我们的坐标注意力继承了通道注意力方法(如压缩和激发注意力)的优点,这些方法对通道间的关系进行建模,同时用精确的位置信息捕捉长距离的依赖关系。在ImageNet分类、目标检测和语义分割中的实验证明了我们的坐标注意力的有效性。