基于遗传算法的BP神经网络优化算法(附代码)
BP网络是前向网络的核心部分,是神经网络中的最精华、最完美的部分,由于其简单的结构,可调整的参数多,训练算法也多,而且可操作性好,BP神经网络获得了非常广泛的应用,但是也存在着一些缺陷,例如学习收敛速度太慢、不能保证收敛到全局最小点、网络结构不易确定。另外,网络结构、初始连接权值和阈值的选择对网络训练的影响很大,但是又无法准确获得,针对这些特点可以采用遗传算法对神经网络进行优化。
案例问题描述
这里以某型拖拉机的齿轮箱为工程背景,介绍使用基于遗传算法的BP神经网络进行齿轮箱故障的诊断。统计表明,齿轮箱故障中60%左右都是由齿轮故障导致的,所以这里只研究齿轮故障的诊断。对于齿轮的故障,这里选取了频域中的几个特征量。频域中齿轮故障比较明显的是在啮合频率处的边缘带上。所以在频域特征信号的提取中选取了在2、4、6挡时,在1、2、3轴的边频带族f(s)士nf(z)处的幅值A(i,j1)、A(i,j2)和A(i,j3),其中f(s)为齿轮的啮合频率,f(z)为轴的转频,n = 1, 2, 3, i=2,4,6表示挡位,j=1,2,3表示轴的序号。由于在2轴和3轴上有两对齿轮啮合,所以1、2分别表示两个啮合频率。这样,网络的输入就是一个15维的向量。因为这些数据具有不同的量纲和量级,所以在输人神经网络之前首先进行归一化处理。表3-1和表3-2列出了归一化后的齿轮箱状态样本数据。
从表中可以看出齿轮状态有三种故障模式,因此可以采用如下的形式来表示输出。
无故障:(1,0,0)。
齿根裂纹:(0,1,0)。
断齿:(0,0,1)。
为了对训练好的网络进行测试,另外再给出三组新的数据作为网络的测试数据,如表3-2所列。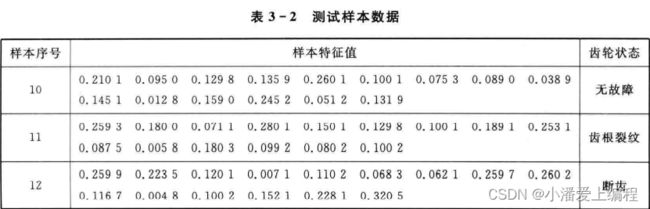
数据集以及代码放在文末!!!
解题思路及步骤
1.算法流程
遗传算法优化BP神经网络算法流程如下图所示
遗传算法优化BP神经网络主要分为:BP神经网络结构确定、遗传算法优化权值和阈值、BP神经网络训练及预测。其中,BP神经网络的拓扑结构是根据样本的输入/输出参数个数确定的,这样就可以确定遗传算法优化参数的个数,从而确定种群个体的编码长度。因为遗传算法优化参数是BP神经网络的初始权值和阈值,只要网络结构已知,权值和阈值的个数就已知了。神经网络的权值和阈值一般是通过随机初始化为[-0.5,0.5]区间的随机数,网络的训练结果是一样的,引入遗传算法就是为了优化出最佳的初始权值和阈值。
2.神经网络算法实现
-
网络创建
BP神经网络的确定有以下两条重要的指导原则。
1.对于一般的模式识别问题,三层网络可以很好地解决问题。
2.在三层网络中,隐含层神经网络个数n2和输入层神经元个数n1之间有近似关系:
n2 = n1 x 2 + 1
在本案例中,由于样本有15个输入参数,3个输出参数,所以这里n2取值为31,设置的BP神经网络结构为15 - 31 - 3,即输入层有15个节点,隐含层有31个节点,输出层有3个节点,共有15 x 31 + 31 x 3 = 558个权值,31 + 3 = 34个阈值,所以遗传算法优化参数的个数558 + 34 = 592。使用表3 - 1中的9个样本作为训练数据,用于网络训练,表3 - 2中的3个样本作为测试数据。把参数样本的测试误差的范数作为衡量网络的一个泛化能力(网络的优劣),再通过误差范数计算个体的适应度值,个体的误差范数越小,个体适应度值越大,个体越优。
神经网络的隐含层神经元的传递函数采用S型正切函数tansig(),输出层神经元的传递函数采用S型对数函数logsig(),这是由于输出模式为0 - 1,正好满足网络的输出要求。创建网络使用一下代码:net = feedforwardnet(31) net.layers{2}.transferFcn = 'logsig'; -
网络训练和测试
网络训练是一个不断修正权值和阈值的过程,通过训练,是的网络的输出误差越来越小。再默认情况下,BP神经网络的训练函数为trainln(),即是利用Levenberg - Marquardt算法对网络进行训练的,具体的网络测试设置及训练代码如下:%% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1 net.trainParam.epochs = 1000; net.trainParam.goal = 0.01; net.trainParam.lr = 0.1; net.trainParam.show = NaN; net.trainParam.showwindow = false; % 使用高版本MATLAB不显示图形框 %% 训练网络 net = train(net, P, T);网络训练之后,需要对网络进行测试。例如测试样本数据矩阵为P_test,则测试代码如下:
Y = sim(net, P_test); -
遗传算法实现
遗传算法优化BP神经网络是用遗传算法来优化BP神经网络的初始权重值和阈值,使优化后的BP神经网络能够更好地进行样本预测。遗传算法优化BP神经网络的要素包括种群初始化、适应度函数,选择算子、交叉算子和变异算子。
(1)种群初始化
个体编码使用二进制编码,每个个体均为一个二进制串,由输人层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值、输出层阈值四部分组成,每个权值和阈值使用M位的二进制编码,将所有权值和阈值的编码连接起来即为一个个体的编码。例如,本例的网络结构是15 - 31 - 3,所以权值和阈值的个数如表3 - 3所列。
(2)适应度函数
本案例是为了使BP网络在预测时,预测值与期望值的残差尽可能小,所以选择预测样本的预测值与期望值的误差矩阵的范数作为目标函数的输出。适应度函数采用排序的适应度分配函数:FitnV = ranking(obj),其中obj为目标函数的输出。
(3)选择算子
选择算子采用随机遍历抽样(sus)。
(4)交叉算子
交叉算子采用最简单的单点交叉算子。
(5)变异算子
变异以一定概率产生变异基因数,用随机方法选出发生变异的基因。如果所选的基因的编码为1,则变为0;反之,则变为1。
本案例的遗传算法运行参数设定如表3 - 4所列。
3.MATLAB程序实现
- 神经网络算法
本案例是将神经网络算法部分作为遗传算法的一个目标函数,函数的输出是预测样本的预测误差的范数。误差越小表示网络的预测精度越高,在遗传算法部分得到的该个体的适应度值也越大。function err = Bpfun(x, P, T, hiddennum, P_test, T_test) %% 训练与测试BP网络 %% 输入 % x:一个个体的初始权值和阈值 % P:训练样本输入 % T:训练样本输出 % hiddennum:隐含层神经元数 % P_test:测试样本输入 % T_test:测试样本期望输出 %% 输出 % err:预测样本的预测误差的范数 inputnum = size(P, 1); % 输入层神经元个数 outputnum = size(T, 1); % 输出层神经元个数 %% 新建BP网络 net = feedforwardnet(hiddennum); net = configure(net, P, T); net.layers{2}.transferFcn = 'logsig'; %% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1 net.trainParam.epochs = 1000; net.trainParam.goal = 0.01; net.trainParam.lr = 0.1; net.trainParam.show = NaN; net.trainParam.showwindow = false; % 使用高版本MATLAB不显示图形框 %% 神经网络初始权值和阈值 w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数 w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数 w1 = x(1 : w1num); % 初始输入层到隐含层的权值 B1 = x(w1num + 1 : w1num + hiddennum); % 隐含层神经元阈值 w2 = x(w1num + hiddennum + 1 : w1num + hiddennum + w2num); % 初始隐含层到输出层的权值 B2 = x(w1num + hiddennum + w2num + 1 : w1num + hiddennum + w2num + outputnum); % 输出层阈值 net.iw{1, 1} = reshape(w1, hiddennum, inputnum); % 输入层到隐含层的权值 net.lw{2, 1} = reshape(w2, outputnum, hiddennum); % 隐含层到输出层的权值 net.b{1} = reshape(B1, hiddennum, 1); net.b{2} = reshape(B2, outputnum, 1); %% 训练网络 net = train(net, P, T); %% 测试网络 Y = sim(net, P_test); err = norm(Y - T_test); end -
遗传算法主函数
遗传算法主函数流程为:
(1)随机初始化种群。
(2)计算种群适应度值,从中找出最优个体。
(3)选择操作。
(4)交叉操作。
(5)变异操作。
(6)判断进化是否结束;若否,则返回步骤(2)。
主函数名为GABP_Main。主函数的MATLAB代码如下:clc; clear close all %% 加载神经网络的训练样本,测试样本每列一个样本,输入P,输出T % 样本数据就是前面问题描述中列出的数据 load data % 初始隐含层神经元个数 hiddennum = 31; % 输入层个数*2 + 1 % 输入向量的最大值和最小值 threshold = [0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1]; inputnum = size(P, 1); % 输入层神经元个数 outputnum = size(T, 1); % 输出层神经元个数 w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数 w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数 N = w1num + hiddennum + w2num + outputnum; % 待优化的变量个数 %% 定义遗传算法参数 NIND = 40; % 种群大小 MAXGEN = 50; % 最大遗传代数 PRECI = 10; % 个体长度 GGAP = 0.95; % 代沟 px = 0.7; % 交叉概率 pm = 0.01; % 变异概率 trace = zeros(N + 1, MAXGEN); % 寻优结果的初始值 FieldD = [repmat(PRECI, 1, N); repmat([-0.5; 0.5], 1, N); repmat([1;0;1;1], 1, N)]; % 区域描述器 Chrom = crtbp(NIND, PRECI * N); % 创建任意离散随机种群 %% 优化 gen = 0; % 代计数器 X = bs2rv(Chrom, FieldD); % 计算初始种群的十进制转换 ObjV = Objfun(X, P, T, hiddennum, P_test, T_test); % 计算目标函数值 while gen < MAXGEN fprintf('%d\n', gen) FitnV = ranking(ObjV); % 分配适应度值 SelCh = select('sus', Chrom, FitnV, GGAP); % 选择 SelCh = recombin('xovsp', SelCh, px); % 重组 SelCh = mut(SelCh, pm); % 变异 X = bs2rv(SelCh, FieldD); % 子代个体的二进制到十进制转换 ObjVSel = Objfun(X, P, T, hiddennum, P_test, T_test); % 计算子代的目标函数值 [Chrom, ObjV] = reins(Chrom, SelCh, 1, 1, ObjV, ObjVSel); % 将子代重插入到父代,得到新种群 X = bs2rv(Chrom, FieldD); gen = gen + 1; % 代计数器增加 % 获取每代的最优解及其序号,Y为最优解,I为个体的序号 [Y, I] = min(ObjV); trace(1: N, gen) = X(I, :); % 记下每代的最优值 trace(end, gen) = Y; % 记下每代的最优值 end %% 画进化图 figure(1); plot(1: MAXGEN, trace(end, :)); grid on xlabel('遗传代数') ylabel('误差的变化') title('进化过程') bestX = trace(1: end - 1, end); bestErr = trace(end, end); fprintf(['最优初始权值和阈值:\nX=', num2str(bestX'), '\n最小误差 err = ', num2str(bestErr), '\n'])其中,函数Objfun的代码如下:
function Obj = Objfun(X, P, T, hiddennum, P_test, T_test) %% 用来分别求解种群中各个个体的目标值 %% 输入 % X:所有个体的初始权值和阈值 % P:训练样本输入 % T:训练样本输出 % hiddennum:隐含层神经元数 % P_test:测试样本输入 % T_test:测试样本期望输出 %% 输出 % Obj:所有个体预测样本预测误差的范数 [M, ~] = size(X); Obj = zeros(M, 1); for i = 1 : M Obj(i) = Bpfun(X(i, :), P, T, hiddennum, P_test, T_test); end -
比较使用遗传算法前后的差别
经过遗传算法优化之后得到最佳的初始权值与阈值矩阵,可以将该初始权值和阈值回代入网络画出训练误差曲线、预测值、预测误差、训练误差等。使用以下代码可以比较优化前后的差别,其中bestX参数为前面优化得到的最优初始权重值和阈值矩阵。函数名为callbackfun。其MATLAB代码如下:clc %% 使用随机权值 inputnum = size(P, 1); % 输入层神经元个数 outputnum = size(T, 1); % 输出层神经元个数 %% 新建BP网络 net = feedforwardnet(hiddennum); net = configure(net, P, T); net.layers{2}.transferFcn = 'logsig'; %% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1 net.trainParam.epochs = 1000; net.trainParam.goal = 0.01; net.trainParam.lr = 0.1; %% 训练网络 net = train(net, P, T); %% 测试网络 disp('1.使用随机权值和阈值') disp('测试样本预测结果:') Y1 = sim(net, P_test) err1 = norm(Y1 - T_test); % 测试样本的仿真误差 err11 = norm(sim(net, P) - T); % 训练样本的仿真误差 disp(['测试样本的仿真误差:', num2str(err1)]) disp(['训练样本的仿真误差:', num2str(err11)]) %% 使用优化后的权值和阈值 inputnum = size(P, 1); % 输入层神经元个数 outputnum = size(T, 1); % 输出层神经元个数 %% 新建BP网络 net = feedforwardnet(hiddennum); net = configure(net, P, T); net.layers{2}.transferFcn = 'logsig'; %% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1 net.trainParam.epochs = 1000; net.trainParam.goal = 0.01; net.trainParam.lr = 0.1; %% BP神经网络初始化权值和阈值 w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数 w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数 w1 = bestX(1 : w1num); % 初始输入层到隐含层的权值 B1 = bestX(w1num + 1 : w1num + hiddennum); % 隐含层神经元阈值 w2 = bestX(w1num + hiddennum + 1 : w1num + hiddennum + w2num); % 初始隐含层到输出层的权值 B2 = bestX(w1num + hiddennum + w2num + 1 : w1num + hiddennum + w2num + outputnum); % 输出层阈值 net.iw{1, 1} = reshape(w1, hiddennum, inputnum); % 输入层到隐含层的权值 net.lw{2, 1} = reshape(w2, outputnum, hiddennum); %隐 含层到输出层的权值 net.b{1} = reshape(B1, hiddennum, 1); net.b{2} = reshape(B2, outputnum, 1); %% 训练网络 net = train(net, P, T); %% 测试网络 disp('2.使用优化后的权值和阈值') disp('测试样本预测结果:') Y2 = sim(net, P_test) err2 = norm(Y2 - T_test); err21 = norm(sim(net, P) - T); disp(['测试样本的仿真误差:', num2str(err2)]) disp(['训练样本的仿真误差:', num2str(err21)]) -
结果分析
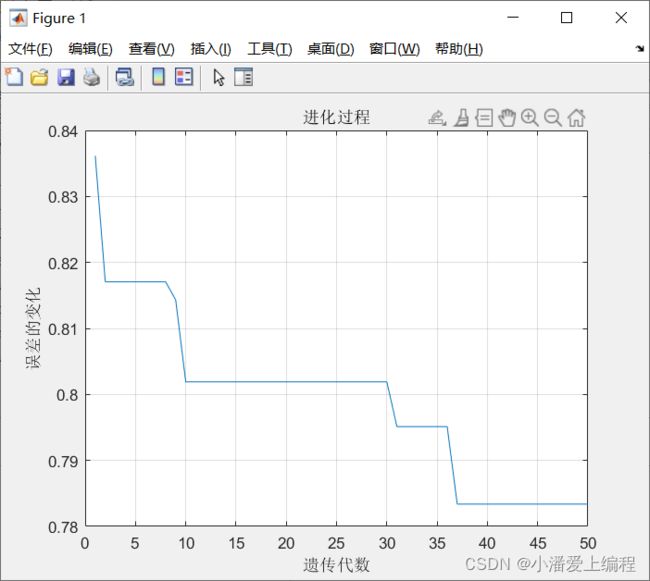


(每次运行结果不一样)
4.小结
遗传算法优化BP神经网络的目的是通过遗传算法得到更好的网络初始权值和阈值,其基本思想就是用个体代表网络的初始权值和阈值,把预测样本的BP神经网络的测试误差的范数作为目标函数的输出,进而计算该个体的适应度值,通过选择、交叉、变异操作寻找最优个体,即最优的BP神经网络初始权值和阈值。除了遗传算法之外,还可以采用粒子群算法、蚁群算法等优化BP神经网络初始权值和阈值。
链接:https://pan.baidu.com/s/1A3t8NF8qN5EZGQQog97-Sw
提取码:6ix3
--来自百度网盘超级会员V3的分享