Hadoop集群搭建(一)----伪分布式集群与eclipse的安装
Haoop集群搭建【一】--伪分布式集群与eclipse的安装
- Ⅰ 前言
- Ⅱ 搭建虚拟机准备(附带下载链接)
-
- 一.VMware
- 二.终端模拟器及文件传输软件
- 三.虚拟机镜像
- 四.相关组件
- Ⅲ.集群安装与配置教程
-
- 一,创建虚拟机
- 二,安装Centos7
-
- 常见问题
- 三,虚拟机网络配置(通过环回适配器)
-
- 本地物理机网络配置
- 虚拟机网络配置
- 虚拟机网卡配置
- 克隆虚拟机
- 配置主机名及hosts列表
- 设置免密钥登录
- 关闭防火墙(所有机器)
- 验证网络
- Ⅳ,安装hadoop
-
- 安装jdk
- 安装hadoop
-
- 配置环境变量 hadoop-env.sh
- 配置环境变量 yarn-env.sh
- 配置环境变量 mapred-env.sh
- 配置核心组件core-site.xml
- 配置文件系统 hdfs-site.xml
- 配置文件系统 yarn-site.xml
- 配置计算框架 mapred-site.xml
- 配置slaves文件
- 配置hadoop启动系统环境变量
- 复制hadoop传给虚拟机
- 启动Hadoop集群
- Ⅴ,安装eclipse
- Ⅵ,小结
Ⅰ 前言
最近由于硬盘垃圾文件太多,图方便直接恢复出厂清空了所有盘文件,想着重装一次虚拟机可以顺便写一个安装心得还有教程,于是写了包括本文的接下来几个博客,该系列博客将会手把手搭建hadoop集群及其常用组件,记录全过程并指出部分常见错误
Ⅱ 搭建虚拟机准备(附带下载链接)
我们首先需要准备一些基本的软件用于搭建集群
一.VMware
VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统.我们需要下载这个平台用于搭建虚拟机,在下面链接中下载完成后自行安装好。
(以下给出下载链接)
VMware Station pro 16.0.0 下载链接
密码:zccy
至于激活码,搜索一下,网上一大把都可以随便用(我的链接中的虚拟机版本是16.0,激活版本别搞错了)
二.终端模拟器及文件传输软件
我们还需要一个终端模拟器和文件传输软件来进行对虚拟机的控制和文件传输,这里我们使用Xmanager,他包含一组工具,其中含有Xshell(模拟器)和Xftp(传输软件),此处要是有自己习惯的软件的话也可以使用自己喜欢的,安装即可,一样的,下面给出链接,
Xmanager下载链接
密码:zccy
1,解压压缩包
2、注册码.txt中获取序列号。双击运行Xme5.exe,进行安装
三.虚拟机镜像
我们还需要为虚拟机准备系统镜像,这里选用适合初学者的centos7(linux)
Centos7镜像下载地址
密码:zccy
四.相关组件
hadoop生态圈还有很多的组件。例如Spark,Hbase,hive等等,因为篇幅问题,这些软件在此处不介绍,给出下载链接,具体的安装教程将会在之后的博客给出,(本文需要使用链接中的hadoop,jdk,eclipse,hadoop-eclipse-plugin-2.7.7.jar (eclipse插件))
集群组件下载链接
密码:zccy
Ⅲ.集群安装与配置教程
一,创建虚拟机

创建虚拟机—>选择典型—>下一步

选择稍后安装—>点击下一步

选择Linux—>版本选择Centos(7) 64位—>点击下一步

修改名称—>选择存储路径—>下一步

默认配置即可

完成虚拟机创建,此步可以自定义硬件(虚拟机的内存可根据自身计算机的配置自行分配,一般使用默认即可)
二,安装Centos7
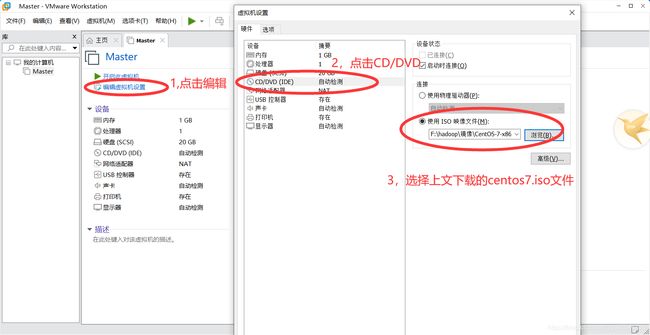
先挂载镜像

开启虚拟机
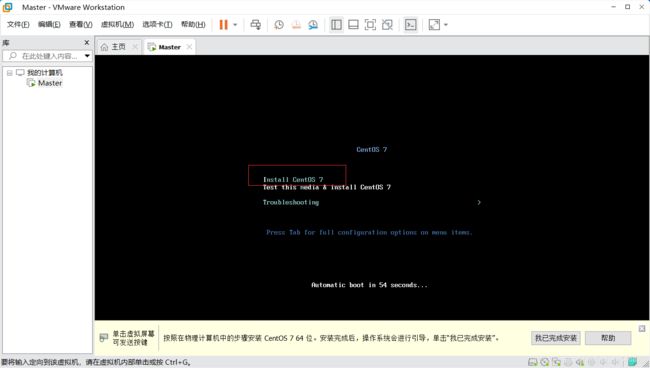
选择Install Centos7

一段时间的加载后,进入语言选择界面,选择自己喜欢的语言,再点击继续

选择安装软件

选择KDE可视化界面(推荐,要是喜欢在命令行敲代码也可以选其他的)

选择自动分区—>开始安装

可以在等待时间里设置一下root密码和hadoop账户,完成后点击重启即可

常见问题

三,虚拟机网络配置(通过环回适配器)
如图,使用root用户登陆虚拟机
本地物理机网络配置
特别提醒,这里操作的是你自己的电脑,不是虚拟机,打开自己电脑的计算机管理,如图所示点击,

选择添加过时硬件

下一步



选择网络适配器

选择厂商为Microsoft,选择型号为KM-TEST环回适配器
没有的话也可能这个
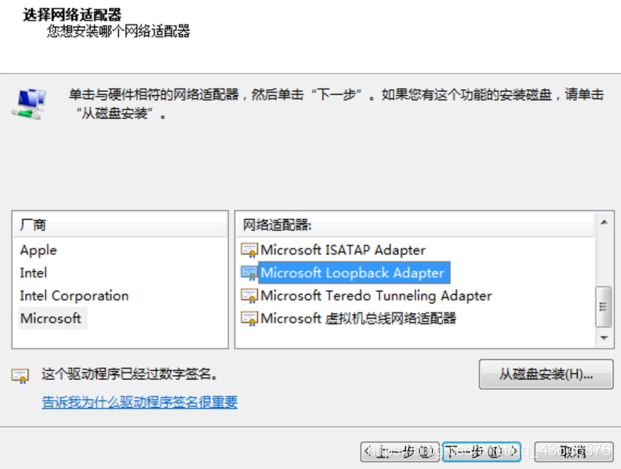
连续点击几个下一步,然后完成。
接下来打开“控制面板\网络和 Internet\网络连接”
找到刚刚添加的环回适配器,然后进行如下操作
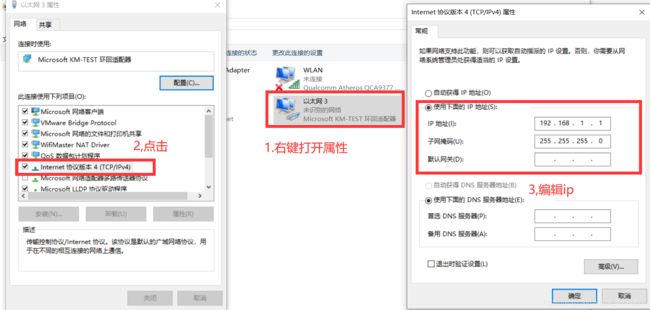
虚拟机网络配置
如图,在VMware中打开虚拟网络编辑器

选择更改设置

添加一个VMnet2(没有的话)

将新建的VMnet2连接到KM回环适配器上

然后修改一下虚拟机的网络属性

修改网络链接,确认保存后重启虚拟机

虚拟机网卡配置
重启完成后,再次登入root用户
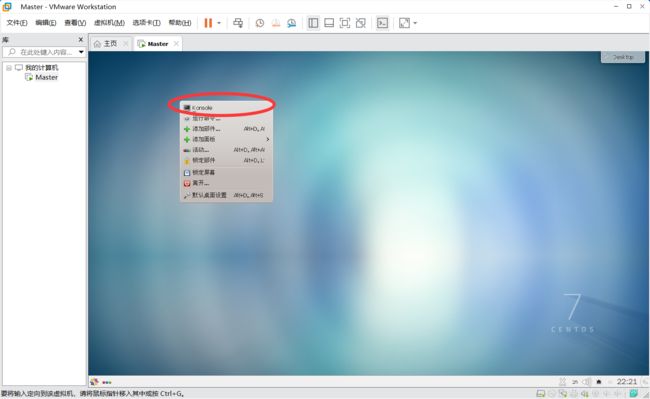
在虚拟机中点击右键,再点击console
输入两个命令:
cd /etc/sysconfig/network-scripts/
ls
我们看到了如下的界面

输入编辑网卡的指令,并进行如下修改:
vi ifcfg-ens33

修改后结果如下

输入命令:
service network restart
如果结果和下图一样,则运行成功

成功了就关机就是简单粗暴
克隆虚拟机
其实除了通过VMware克隆,还可以在本地文件系统找到虚拟机根目录,直接复制粘贴虚拟机,但这种方法不做推荐(能按两下解决的事,整那么复杂干嘛)
如下图,依次点击

复制当前状态

创建完整克隆
修改名称和存储路径
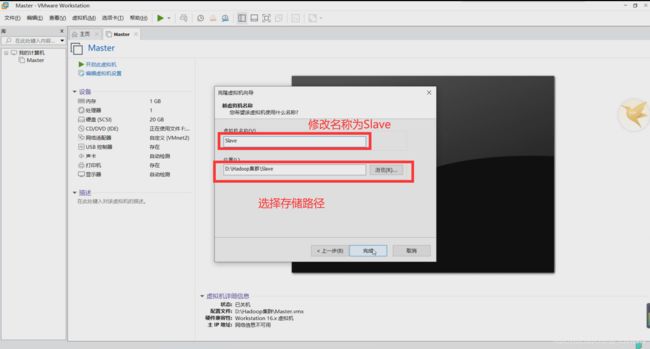
克隆完成,关闭

按箭头顺序依次点击,记住一定要重新生成,不然会没网(老版本克隆不会自动重新生成)

之后打开slave,修改他的网卡配置(IP),方法上面讲过

重启网卡

相同方法再克隆一个Slave2
配置主机名及hosts列表
在Master中输入指令
hostnamectl set-hostname master

在slave中输入指令
hostnamectl set-hostname slave
在所有虚拟机上配置hosts列表(否则会导致连接错误)
vi /etc/hosts
删除其余的配置,向其中添加主节点以及从节点信息(如图)

设置免密钥登录
首先在三个虚拟机都输入指令
ssh-keygen –t rsa
连续点击几个回车
然后回到master上,继续输入指令
cd .ssh
cp id_rsa.pub authorized_keys
scp -p id_rsa.pub root@slave:/root/.ssh/authorized_keys
scp -p id_rsa.pub root@slave2:/root/.ssh/authorized_keys
注意,最后两步需要输入密码,请一步一步执行,不要直接复制全部
最后回到两个slave上输入指令
cd .ssh
chmod 600 authorized_keys

如图,即成功
关闭防火墙(所有机器)
关闭虚拟机防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
关闭物理机防火墙(ping不通物理机再关)
验证网络
将下面几行填入/etc/hosts文件中(根据自己配的IP地址)
192.168.1.2 master
192.168.1.3 slave
192.168.1.4 slave2
使用ping命令查看网络

我们可以看到三个虚拟机之间是可以互ping的,接着我们试一试ping 192.168.1.1(物理机ip)
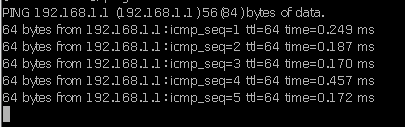
那我们再试试外网,如果Ping通,结果如下
(
注:仅使用本教程的回环适配器是无法联网的,需要再连接一个新的网卡连接外网,方法在我的另一个博客(里面还有常见的几种网络配置错误的解决方法)
传送门:虚拟机ping不通的几种常见解决方法
)

如图,也是可以的,
Ⅳ,安装hadoop
做好了准备,我们开始正式进入hadoop集群安装
首先打开Xmanager中的Xshell
 如图,创建一个新会话
如图,创建一个新会话
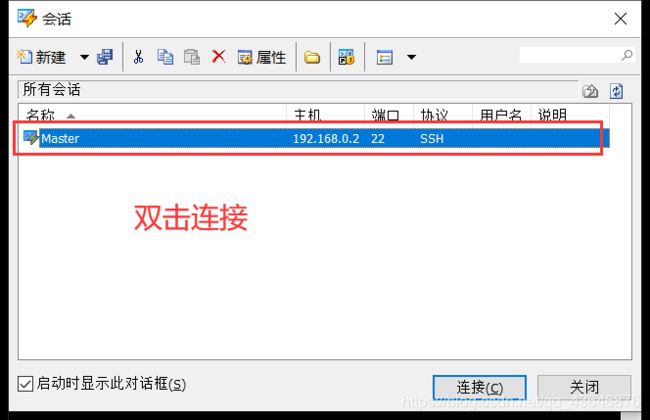
 接受并保存
接受并保存
 输入root用户名(勾选记住用户名)(之后输入自己的密码)
输入root用户名(勾选记住用户名)(之后输入自己的密码)

出现这样的画面就说明连接成功
同样地,再设两个虚拟机会话

一样连接上
打开Xftp


安装jdk
将jdk传给虚拟机(几个虚拟机都传)
(确定在根目录下)创建一个jdk目录(三个虚拟机同步),并解压jdk到这个文件夹
mkdir jdk
tar -xvf jdk-8u144-linux-x64.tar.gz -C /root/jdk

然后我们会看到命令行窗口开始duang duang duang地弹东西,等解压完了。我们看一看目录
ls /root/jdk
解压完成,我们配置一下jdk路径(保证在root目录下)
vi ./.bash_profile
编辑内容如下
export JAVA_HOME=/root/jdk/jdk1.8.0_144/
export PATH=$JAVA_HOME/bin:$PATH

编辑完成后,重新加载,输入下列指令
source .bash_profile
再查看jdk版本
java -version

这里我们说一下.bash_profile文件,这是一个配置路径的文件,还有一个效果相同的文件(在/etc)profile,这里我们之所以使用.bash_profile的原因是/etc/profile是默认配置文件,我们可以把我们的路径信息放在.bash_profile中,就可以与系统配置文件错开
提示:JAVAHOME是自己设置的jdk路径(跟着我做的文件跟我一样就行)
安装hadoop
将准备好的hadoop下载到master的root目录下,
解压
tar -xvf hadoop-2.7.7.tar.gz
创建几个新文件夹
mkdir /root/hadoop-2.7.7/hdfs
mkdir /root/hadoop-2.7.7/hdfs/tmp
mkdir /root/hadoop-2.7.7/hdfs/name
mkdir /root/hadoop-2.7.7/hdfs/data
配置环境变量 hadoop-env.sh
输入指令
vi ./hadoop-2.7.7/etc/hadoop/hadoop-env.sh
找到配置文件中的JAVA_HOME,添加自己的jdk路径

配置环境变量 yarn-env.sh
输入指令
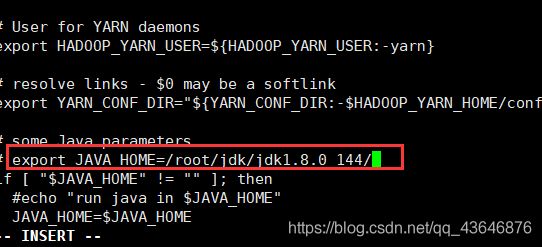
vi ./hadoop-2.7.7/etc/hadoop/yarn-env.sh
同样的,修改其中的JAVA_HOME
配置环境变量 mapred-env.sh
输入指令
vi ./hadoop-2.7.7/etc/hadoop/mapred-env.sh
同样的,修改其中的JAVA_HOME

配置核心组件core-site.xml
输入指令
vi ./hadoop-2.7.7/etc/hadoop/core-site.xml
在文件末尾的 configuration 之间添加下列内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.7.7/hdfs/tmp</value>
</property>
结果如下

配置文件系统 hdfs-site.xml
输入指令
vi ./hadoop-2.7.7/etc/hadoop/hdfs-site.xml
在文件末尾的 configuration 之间添加下列内容
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop-2.7.7hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop-2.7.7/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>

配置文件系统 yarn-site.xml
输入指令
vi ./hadoop-2.7.7/etc/hadoop/yarn-site.xml
在文件末尾的 configuration 之间添加下列内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
结果如下

配置计算框架 mapred-site.xml
输入指令
cp ./hadoop-2.7.7/etc/hadoop/mapred-site.xml.template ./hadoop-2.7.7/etc/hadoop/mapred-site.xml
vi ./hadoop-2.7.7/etc/hadoop/mapred-site.xml
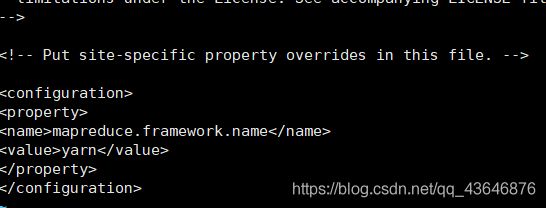
在文件末尾的 configuration 之间添加下列内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
结果如下:
配置slaves文件
vi ./hadoop-2.7.7/etc/hadoop/slaves
把localhost改成slave,slave2

配置hadoop启动系统环境变量
向.bash_profile 添加hadoop配置信息
vi .bash_profile
export HADOOP_HOME=/root/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
结果如下

编辑完成后,重新加载,输入下列指令
source .bash_profile
复制hadoop传给虚拟机
根目录下
scp -r hadoop-2.7.7 root@slave:~/
scp -r hadoop-2.7.7 root@slave2:~/
启动Hadoop集群
格式化文件系统
hdfs namenode -format
启动Hadoop
cd hadoop-2.7.7/sbin
./start-dfs.sh
./start-yarn.sh
jps查看运行情况,如图所示,即成功(namenode启动)

打开浏览器,在地址栏中输入 http://master:50070/查看节点情况,若如图,则配置成功
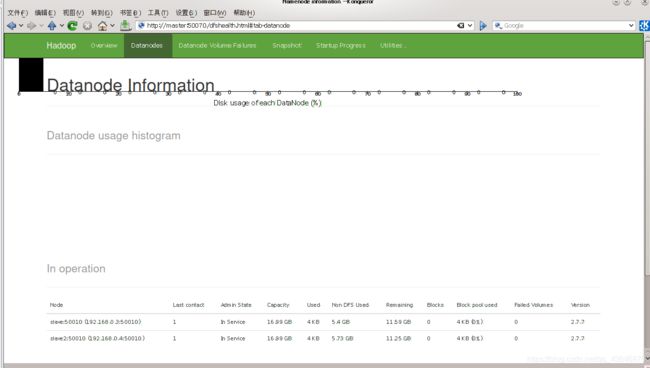
好了,到这伪分布式集群就搭建完成了
集群(节点)无法启动,可以参考我的另一篇博客
这是传送门:虚拟机节点启动异常的解决方法
web页面无法显示datanode节点信息,可以参考我的另一篇博客
这是传送门:hadoop集群web页面无法显示节点信息的解决方法
Ⅴ,安装eclipse
将准备好的eclipse压缩包和hadoop-eclipse-plugin-2.7.7.jar 放入root目录下,(hadoop-eclipse-plugin-2.7.7.jar在上面链接下载,这个资源不好找,直接下就好,我是自己用ant编译的)
解压eclipse
tar -xvf eclipse-jee-oxygen-3-linux-gtk-x86_64.tar.gz
将hadoop-eclipse-plugin-2.7.7.jar拷贝至eclipse的plugins目录下
cp /root/hadoop-eclipse-plugin-2.7.7.jar /root/eclipse/plugins
打开eclipse
eclipse/eclipse
打开菜单Window–Preference–Hadoop Map/Reduce进行配置,如下图所示:(路径为hadoop路径)

显示Hadoop连接配置窗口:Window–Perspective–OpenPerspective–Other-MapReduce,如下图所示
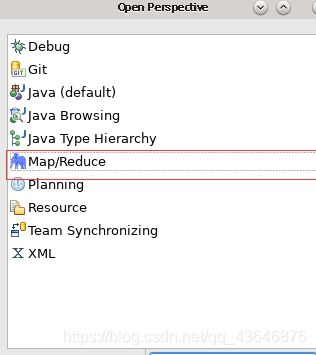
按顺序点击图标

配置连接Hadoop,如下图所示:
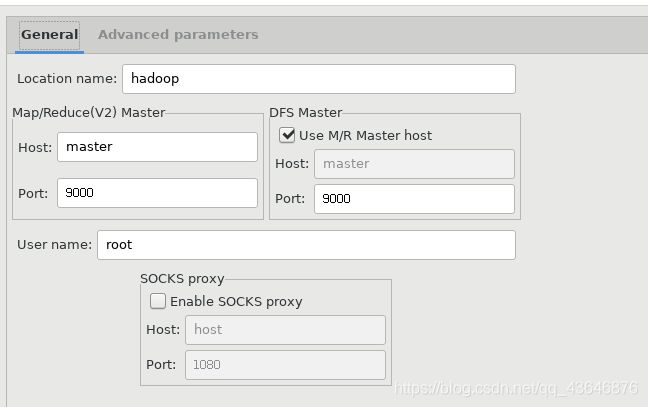
如下图,即配置成功

Ⅵ,小结
安装hadoop集群是学习是学习haoop集群的第一步,如果出现了什么问题欢迎在评论区留言,互相讨论,下一篇将会介绍hadoop集群上spark环境的安装,如果这篇博有帮到你,请在下文点个赞呦!