【Transformers】第 2 章:主题的实践介绍
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
使用 Anaconda 安装Transformer
在 Linux 上安装
在 Windows 上安装
在 macOS 上安装
安装 TensorFlow、PyTorch 和 Transformer
使用 Google Colab 安装
使用语言模型和分词器
使用社区提供的模型
使用基准和数据集
重要基准
GLUE基准
SuperGLUE 基准测试
XTREME基准
XGLUE 基准测试
SQuAD 基准测试
使用应用程序编程接口访问数据集
使用数据集库进行数据操作
速度和内存的基准测试
概括
到目前为止,我们已经全面了解了使用基于深度学习( DL ) 的方法的自然语言处理( NLP )的演变。我们已经了解了有关 Transformer 及其各自架构的一些基本信息。在本章中,我们将更深入地了解如何使用变压器模型。标记器和模型,例如来自 Transformer ( BERT ) 的双向编码器表示),本章将通过动手示例更详细地描述技术细节,包括如何加载标记器/模型和使用社区提供的预训练模型。但在使用任何特定模型之前,我们将了解使用 Anaconda 提供必要环境所需的安装步骤。在安装步骤中,将介绍在 Linux、Windows 和 macOS 等各种操作系统上安装库和程序。还展示了在中央处理单元( CPU ) 和图形处理单元( GPU )的两个版本中安装PyTorch和TensorFlow。快速跳转到Google Colaboratory (Google Colab ) 提供了 Transformer 库的安装。还有一个部分专门介绍在 PyTorch 和 TensorFlow 框架中使用模型。
HuggingFace 模型存储库也是本章的另一个重要部分,其中讨论了寻找不同模型和使用各种管道的步骤——例如,双向和自回归转换器( BART )、BERT 和表解析( TAPAS ) 等模型) 很详细,一目了然Generative Pre-trained Transformer 2 ( GPT-2 ) 文本生成。然而,这纯粹是一个概述,本章的这一部分涉及准备好环境和使用预训练模型。这里没有讨论模型训练,因为这在接下来的章节中会变得更加重要。
在一切准备就绪并且我们了解了如何使用Transformer库通过社区提供的模型进行推理之后,将描述数据集库。在这里,我们着眼于加载各种数据集、基准测试和使用指标。加载特定的数据集并从中获取数据是我们在这里研究的主要领域之一。此处还考虑了跨语言数据集以及如何将本地文件与数据集库一起使用。map和filter函数是数据集库在模型训练方面的重要功能,本章也将对其进行研究。
本章是本书的重要组成部分,因为这里更详细地描述了数据集库。了解如何使用社区提供的模型并使系统为本书的其余部分做好准备对您来说也非常重要。
总而言之,我们将在本章中涵盖以下主题:
- 使用 Anaconda 安装变压器
- 使用语言模型和分词器
- 使用社区提供的模型
- 使用基准和数据集
- 速度和内存的基准测试
技术要求
您将需要安装下面列出的库和软件。尽管拥有最新版本是一个加分项,但必须安装彼此兼容的版本。有关 HuggingFace Transformer 最新版本安装的更多信息,请查看他们的官方网页https://huggingface.co/Transformer/installation.html:
- Anaconda
- Transformer 4.0.0
- PyTorch 1.1.0
- TensorFlow 2.4.0
- Datasets 1.4.1
最后,本章中显示的所有代码都可以在本书的 GitHub 存储库中找到,地址为 https://github.com/PacktPublishing/Mastering-Transformer/tree/main/CH02。
查看以下链接以查看代码在行动视频:https ://bit.ly/372ek48
使用 Anaconda 安装Transformer
Anaconda是Python 和 R 编程语言的分发,使包分发和部署易于科学计算。在本章,我们将描述安装Transformer库。但是,也可以在没有 Anaconda 帮助的情况下安装这个库。使用 Anaconda 的主要动机是更容易地解释过程并调整使用的包。
要开始安装相关库,Anaconda 的安装是必须的步骤。Anaconda 文档提供的官方指南提供了为常见操作系统(macOS、Windows 和 Linux)安装它的简单步骤。
在 Linux 上安装
许多发行版Linux 是可供用户享受,但在他们,Ubuntu是首选之一。在本节中,将介绍 Linux 上安装 Anaconda 的步骤。进行如下操作:
- 下载来自 https://www.anaconda.com/products/individual#Downloads 的适用于 Linux 的 Anaconda 安装程序并转到 Linux 部分,如以下屏幕截图所示:

图 2.1 – Anaconda Linux 下载链接
- 运行bash命令进行安装并完成以下步骤:
- 打开终端并运行以下命令:
bash Terminal./FilePath/For/Anaconda.sh - 按Enter 键查看许可协议,如果您不想全部阅读,请按Q ,然后执行以下操作:
- 单击是同意。
- 单击是,安装程序始终初始化conda根环境。
- 后从终端运行python命令,你在 Python 版本信息之后应该会看到 Anaconda 提示。
- 您可以通过从终端运行anaconda-navigator命令来访问 Anaconda Navigator。结果,您将看到 Anaconda图形用户界面( GUI ) 开始加载相关模块,如以下屏幕截图所示:

图 2.2 – Anaconda 导航器
让我们继续下一节吧!
在 Windows 上安装
以下步骤描述如何安装 AnacondaWindows 操作系统:
- 下载从 https://www.anaconda.com/products/individual#Downloads 安装程序并转到 Windows 部分,如以下屏幕截图所示:

图 2.3 – 适用于 Windows 的 Anaconda 下载链接
- 打开安装程序并按照指南单击我同意按钮。
- 选择安装位置,如下图所示:
 图 2.4 – 适用于 Windows 的 Anaconda 安装程序
图 2.4 – 适用于 Windows 的 Anaconda 安装程序 - 不要忘记选中Add anaconda3 to my PATH environment variable复选框,如下图所示截屏。如果不选中此框,Anaconda 版本的 Python 将不会添加到 Windows 环境变量中,并且您将无法从 Windows shell 或 Windows 命令行直接使用python命令运行它:

图 2.5 – Anaconda 安装程序高级选项
- 跟着其余的安装说明和完成安装。
您现在应该能够从“开始”菜单启动 Anaconda Navigator。
在 macOS 上安装
以下必须按照步骤安装 Anaconda苹果系统:
- 下载从 https://www.anaconda.com/products/individual#Downloads 安装安装程序并转到 macOS 部分,如以下屏幕截图所示:

图 2.6 – macOS 的 Anaconda 下载链接
- 打开安装程序。
- 跟着说明并单击安装按钮将 macOS 安装在预定义的位置,如以下屏幕截图所示。您可以更改默认目录,但不建议这样做:

2.7 – macOS 的 Anaconda 安装程序
一旦你完成安装,你应该可以访问蟒蛇领航员。
安装 TensorFlow、PyTorch 和 Transformer
的安装TensorFlow 和 PyTorch 作为用于 DL 的两个主要库可以通过pip或conda本身制作。conda提供了一个命令行界面( CLI ) 以便于安装这些图书馆。
为了干净安装并避免中断其他环境,最好为huggingface库创建一个conda环境。您可以通过运行以下代码来执行此操作:
conda create -n Transformer此命令将为安装其他库创建一个空环境。创建后,我们需要激活它,如下所示:
conda activate Transformer通过运行以下命令可以轻松完成Transformer库的安装:
conda install -c conda-forge tensorflow
conda install -c conda-forge pytorch
conda install -c conda-forge Transformerconda install命令中的-c参数允许 Anaconda 使用其他通道来搜索库。
请注意,它是一个要求有安装了 TensorFlow 和 PyTorch,因为Transformer库同时使用了这两个库。另一个注意事项是 Conda 轻松处理 CPU 和 GPU 版本的 TensorFlow。如果你只是在tensorflow后面加上 –gpu,它会安装 GPU 版本自动地。要通过cuda库(GPU 版本)安装 PyTorch ,您需要有cuda等相关库,但conda会自动处理,无需进一步手动设置或安装。以下屏幕截图显示了 conda 如何通过安装相关的cudatoolkit和cudnn库来自动安装 PyTorch GPU 版本:

图 2.8 – Conda 安装 PyTorch 和相关的 cuda 库
请注意,所有这些安装也可以在没有conda的情况下完成,但使用 Anaconda 的原因是它易于使用。在使用环境或安装 TensorFlow 或 PyTorch 的 GPU 版本方面,Anaconda 就像魔术一样,是一个很好的节省时间的方法。
使用 Google Colab 安装
即使使用 Anaconda 可以节省时间并且是有用,在大多数情况下,并不是每个人都有这么好的和合理的可用计算资源。在这种情况下,Google Colab 是一个不错的选择。在 Colab 中安装Transformer库是使用以下命令进行的:
!pip install Transformer语句前的感叹号使代码在 Colab shell 中运行,相当于在终端中运行代码而不是使用 Python 解释器运行它。这将自动安装Transformer库。
使用语言模型和分词器
在本节中,我们将了解如何将Transformer库与语言模型以及它们相关的标记器一起使用。在为了使用任何指定语言模型,我们首先需要导入它。我们将从 Google 提供的 BERT 模型开始,使用它的预训练版本,如下:
from Transformer import BERTTokenizer
tokenizer = BERTTokenizer.from_pretrained('BERT-base-uncased')上述代码片段的第一行导入了 BERT 分词器,第二行为 BERT 基础版本下载了预训练的分词器。请注意,不加大小写的版本是用不加大小写的字母训练的,所以字母是大写还是小写都没有关系。要测试并查看输出,您必须运行以下代码行:
text = "Using Transformer is easy!"
tokenizer(text)这将是输出:
{'input_ids': [101, 2478, 19081, 2003, 3733, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1、1、1、1、1]}
input_ids显示每个标记的标记 ID,而token_type_ids显示分隔第一和第二序列的每个标记的类型,如下面的屏幕截图所示:
![]()
图 2.9 – BERT 的序列分离
attention_mask是 0 和 1 的掩码,用于显示 Transformer 模型序列的开始和结束,以防止不必要的计算。每个标记器都有自己的方式将特殊标记添加到原始序列中。在 BERT 的情况下分词器,它在序列的开头添加一个[CLS]令牌,在序列的末尾添加一个[SEP]令牌,可以通过 101 和 102 看到。这些数字来自预训练的分词器的令牌 ID。
标记器可用于基于 PyTorch 和 TensorFlow 的Transformer模型。为了每个都有输出,必须在return_tensors中使用pt和tf关键字。例如,您可以通过简单地运行以下命令来使用分词器:
encoded_input = tokenizer(text, return_tensors="pt")encoded_input具有 PyTorch 模型要使用的标记化文本。为了运行模型(例如,BERT 基础模型),可以使用以下代码从huggingface模型库下载模型:
from Transformer import BERTModel
model = BERTModel.from_pretrained("BERT-base-uncased")分词器的输出可以使用以下代码行传递给下载的模型:
output = model(**encoded_input)这将以嵌入和交叉注意力输出的形式为您提供模型的输出。
加载和导入模型时,您可以指定您尝试使用的模型版本。如果您只是将TF放在模型名称之前,Transformer库将加载它的 TensorFlow 版本。以下代码展示了如何加载和使用 TensorFlow 版本的 BERT base:
from Transformer import BERTTokenizer, TFBERTModel
tokenizer = BERTTokenizer.from_pretrained('BERT-base-uncased')
model = TFBERTModel.from_pretrained("BERT-base-uncased")
text = " Using Transformer is easy!"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(**encoded_input)对于特定任务,例如使用填充掩码语言模型,有由huggingface设计的管道可以使用。例如,填充掩码的任务可以在以下代码片段中看到:
from Transformer import pipeline
unmasker = pipeline('fill-mask', model='BERT-base-uncased')
unmasker("The man worked as a [MASK].")此代码将产生以下输出显示了分数和可能放置在[MASK]标记中的标记:
[{'score': 0.09747539460659027, 'sequence': 'the man worked as a carpenter.', 'token': 10533, 'token_str': 'carpenter'}, {'score': 0.052383217960596085, 'sequence': 'the man worked as a waiter.', 'token': 15610, 'token_str': 'waiter'}, {'score': 0.049627091735601425, 'sequence': 'the man worked as a barber.', 'token': 13362, 'token_str': 'barber'}, {'score': 0.03788605332374573, 'sequence': 'the man worked as a mechanic.', 'token': 15893, 'token_str': 'mechanic'}, {'score': 0.03768084570765495, 'sequence': 'the man worked as a salesman.', 'token': 18968, 'token_str': 'salesman'}]
要使用 pandas 获得整洁的视图,请运行以下代码:
pd.DataFrame(unmasker("The man worked as a [MASK]."))结果可以在以下屏幕截图中看到:

图 2.10 – BERT 掩码填充的输出
到目前为止,我们已经学习了如何加载和使用预训练的 BERT 模型,并了解了标记器的基础知识,以及模型的 PyTorch 和 TensorFlow 版本之间的区别。在下一节中,我们将通过加载不同的模型、阅读模型作者提供的相关信息以及使用不同的管道(例如文本生成或问答( QA ) 管道)来学习使用社区提供的模型。
使用社区提供的模型
拥抱脸有很多由Google 和 Facebook 等大型人工智能( AI ) 和信息技术( IT ) 公司的合作者提供的社区模型。个人和大学也提供了许多有趣的模型。访问和使用它们也很容易。首先,您应该访问其可用的 Transformer 模型目录网站(https://huggingface.co/models),如下图所示:
图 2.11 – Hugging Face 模型库
除了在这些模型中,还有许多可用于 NLP 任务的优秀且有用的数据集。要开始使用其中一些模型,您可以通过关键字搜索来探索它们,或者只指定您的主要 NLP 任务和管道。
例如,我们正在寻找一个表 QA 模型。找到我们感兴趣的模型后,可以从 Hugging Face 网站 ( google/tapas-base-finetuned-wtq · Hugging Face ) 获得如下页面:
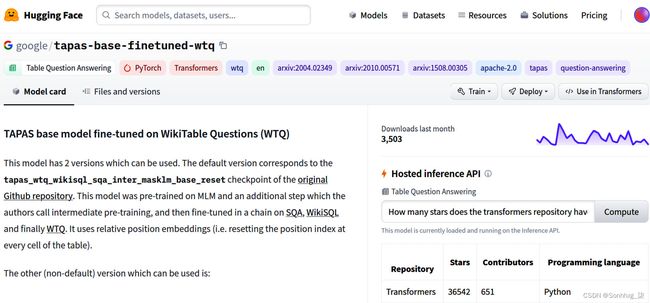
图 2.12 – TAPAS 模型页面
在右侧,有一个面板,您可以在其中测试此模型。请注意,这是一个表格 QA 模型,可以回答有关提供给模型的表格的问题。如果您提出问题,它将通过突出显示答案来回答。以下屏幕截图显示了它如何获取输入并为特定表提供答案:

图 2.13 – 使用 TAPAS 的表 QA
每个模型都有一个模型作者提供的页面也是已知的作为样板卡。您可以通过模型页面中提供的示例来使用模型。例如,您可以访问 GPT-2 huggingface存储库页面并查看作者提供的示例 ( gpt2 · Hugging Face ),如下图所示:
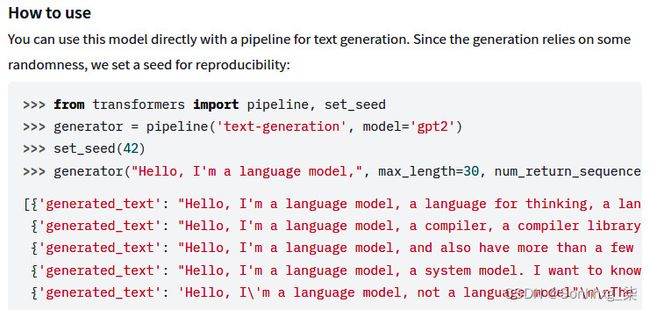
图 2.14 – Hugging Face GPT-2 页面的文本生成代码示例
建议使用管道,因为所有脏活都由Transformer库处理。作为另一个示例,假设您需要一个开箱即用的零样本分类器。以下代码片段显示了实现和使用这种预训练模型是多么容易:
from Transformer import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
sequence_to_classify = "I am going to france."
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(sequence_to_classify, candidate_labels)上述代码将提供以下结果:
{'labels': ['travel', 'dancing', 'cooking'], 'scores': [0.9866883158683777, 0.007197578903287649, 0.006114077754318714], 'sequence': 'I am going to france.'}
我们完了安装和hello-world应用程序部分。至此,我们已经介绍了安装流程,完成了环境设置,体验了第一个变压器管道。在下一部分中,我们将介绍数据集库,这将是我们在接下来的实验章节中必不可少的实用工具。
使用基准和数据集
在介绍datasets库之前,我们最好先谈谈重要的基准,例如通用语言理解评估( GLUE )、多语言编码器的跨语言传输评估( XTREME ) 和斯坦福问答数据集( SquaAD )。基准测试是对内迁移学习多任务和多语言环境。在 NLP 中,我们大多专注于特定指标,即特定任务或数据集的性能得分。多亏了Transformer库,我们能够将我们从特定任务中学到的知识转移到相关任务中,这称为转移学习( TL )。经过在相关问题之间转移表示,我们能够训练共享通用语言的通用模型跨任务的知识,也称为多任务学习( MTL )。TL 的另一个方面是跨自然语言(多语言模型)传递知识。
重要基准
在这一部分中,我们将介绍基于变压器的架构广泛使用的重要基准。这些基准专门为 MTL 以及多语言和零样本学习做出了很大贡献,包括许多具有挑战性的任务。我们将查看以下基准:
- GLUE
- SuperGLUE
- XTREME
- XGLUE
- SQuAD
为了使用更少的页面,我们只给出了 GLUE benchmark 的任务细节,所以让我们先看一下这个 benchmark。
GLUE基准
最近的研究解决了多任务训练方法可以实现的事实比单任务学习作为任务的特定模型更好的结果。在这个方向上,已经为 MTL 引入了GLUE基准,它是用于评估 MTL 模型在一系列任务中的性能的工具和数据集的集合。它提供了一个公共排行榜来监控基准上的提交性能,以及一个总结 11 个任务的单一数字指标。该基准包括许多句子理解任务,这些任务基于现有任务,涵盖不同大小、文本类型和难度级别的各种数据集。这些任务分为三种类型,概述如下:
- 单句任务
- CoLA:语言可接受性数据集的语料库。该任务包括英语从语言理论文章中得出的可接受性判断。
- SST-2:斯坦福情绪树库数据集。这个任务包括来自的句子电影评论和带有pos / neg标签的情感注释。
- 相似性和释义任务
- MRPC:Microsoft Research 释义语料库数据集。这个任务看成对的句子是否是语义等价。
- QQP:Quora 问题对数据集。这个任务决定一对问题是否语义等价。
- STS-B:语义文本相似性基准数据集。这个任务是一个集合从新闻中提取的句子对标题,相似度得分在 1 到 5 之间。
- 推理任务
- MNLI:多类型自然语言推理语料库。这是一个集合带有文本蕴涵的句子对。这任务是预测文本是否包含假设(蕴含)、与假设相矛盾(矛盾)或两者都不存在(中性)。
- QNLI:问题自然语言推理数据集。这是一个转换版本队。任务是检查一个句子是否包含问题的答案。
- RTE:识别文本内涵数据集。这是文本的任务蕴涵合并来自不同来源的数据的挑战。该数据集类似于之前的 QNLI 数据集,其任务是检查第一个文本是否包含第二个文本。
- WNLI:Winograd 自然语言推理模式挑战。这是起初将句子中的代词和短语联系起来的代词解析任务。GLUE 将问题转换为句子对分类,如下所述。
SuperGLUE 基准测试
与 Glue 一样,SuperGLUE是一种新的基准风格与一套新的更难语言理解任务,并利用现有数据提供当前大约八种语言任务的公共排行榜,并与 GLUE 等单一数字性能指标相关联。其背后的动机是,在撰写本书时,当前最先进的 GLUE 分数 (90.8) 超过了人类的表现 (87.1)。因此,SuperGLUE 为通用语言理解技术提供了更具挑战性和多样化的任务。
您可以同时访问gluebenchmark.com上的 GLUE 和 SuperGLUE 基准测试。
XTREME基准
近年来,NLP研究人员越来越关注学习通用表示,而不是可以应用于许多相关任务的单个任务。构建通用语言模型的另一种方法是使用多语言任务。已经观察到最近的多语言模型,例如多语言 BERT ( mBERT ) 和对大量多语言语料库进行预训练的 XLM-R 在将它们转移到其他语言时表现更好。因此,这里的主要优势是跨语言泛化使我们能够通过零样本跨语言迁移在资源匮乏的语言中构建成功的 NLP 应用程序。
在这个方向上,已经设计了XTREME基准。它目前包括属于 12 个语言家族的大约 40 种不同语言,并包括 9 个不同的任务,需要对不同级别的语法或语义进行推理。但是,将模型扩展到覆盖 7,000 多种世界语言仍然具有挑战性,并且在语言覆盖率和模型能力之间存在权衡。请查看以下链接有关此的更多详细信息:https ://sites.research.google/xtreme 。
XGLUE 基准测试
XGLUE是另一种跨语言基准评估和改进跨语言预训练的表现自然语言理解( NLU ) 和自然语言生成( NLG ) 的模型。它最初由 11 个任务组成,超过 19 个语言。与 XTREME 的主要区别在于每个任务的训练数据仅提供英文版本。这迫使语言模型仅从英语的文本数据中学习并将这些知识转移到其他语言,这称为零样本跨语言转移能力。第二个不同是它同时有 NLU 和 NLG 的任务。请查看有关此内容的更多详细信息,请访问以下链接:https ://microsoft.github.io/XGLUE/ 。
SQuAD 基准测试
SQuAD是一种广泛使用的NLP 领域的 QA 数据集。它提供了一组 QA 对对 NLP 模型的阅读理解能力进行基准测试。它由问题列表、阅读文章和由众包工作人员在一组 Wikipedia 文章中注释的答案组成。问题的答案是阅读文章中的一段文本。初始版本 SQuAD1.1 在收集数据集时没有无法回答的选项,因此每个问题都可以在阅读文章的某处找到答案。NLP 模型被迫回答这个问题,即使这看起来不可能。SQuAD2.0 是一个改进版本,NLP 模型不仅要在可能的情况下回答问题,而且在无法回答的情况下也应该放弃回答。SQuAD2.0 包含 50,000 个无法回答的问题,这些问题由众包工作者以对抗方式编写,看起来与可回答的问题相似。此外,它还有 100 个,
使用应用程序编程接口访问数据集
数据集库通过 Hugging Face 集线器提供了一个非常有效的实用程序来加载、处理和与社区共享数据集。与 TensorFlow 数据集一样,它可以更轻松地直接从原始数据集主机根据要求。该库还提供评估指标以及数据。实际上,集线器不保存或分发数据集。相反,它保留了有关数据集的所有信息,包括所有者、预处理脚本、描述和下载链接。我们需要检查我们是否有权使用相应许可下的数据集。要查看其他功能,请查看GitHub 存储库下相应数据集的dataset_infos.json和DataSet-Name.py文件,位于https://github.com/huggingface/datasets/tree/master/datasets
让我们从安装数据集库开始,如下:
pip install datasets以下代码使用 Hugging Face 集线器自动加载可乐数据集。如果数据尚未缓存,则 datasets.load_dataset() 函数会从实际路径下载加载脚本:
from datasets import load_dataset
cola = load_dataset('glue', 'cola')
cola['train'][25:28]重要的提示
数据集的可重用性:当您重新运行代码几次时,数据集库开始缓存您的加载和操作请求。它首先存储数据集并开始缓存您对数据集的操作,例如拆分、选择和排序。您将看到一条警告消息,例如重用数据集 xtreme (/home/savas/.cache/huggingface/dataset...)或加载缓存排序...。
在前面的示例中,我们从 GLUE 基准测试中下载了cola数据集,并从它的train split 中选择了一些示例。
目前,有 661 个 NLP 数据集和 21 个指标用于各种任务,如以下代码片段所示:
from pprint import pprint
from datasets import list_datasets, list_metrics
all_d = list_datasets()
metrics = list_metrics()
print(f"{len(all_d)} datasets and {len(metrics)} metrics exist in the hub\n")
pprint(all_d[:20], compact=True)
pprint(metrics, compact=True)这是这输出:
661 datasets and 21 metrics exist in the hub.
['acronym_identification', 'ade_corpus_v2', 'adversarial_qa', 'aeslc', 'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue', 'ajgt_twitter_ar', 'allegro_reviews', 'allocine', 'alt', 'amazon_polarity', 'amazon_reviews_multi', 'amazon_us_reviews', 'ambig_qa', 'amttl', 'anli', 'app_reviews', 'aqua_rat']
['accuracy', 'BERTscore', 'bleu', 'bleurt', 'comet', 'coval', 'f1', 'gleu', 'glue', 'indic_glue', 'meteor', 'precision', 'recall', 'rouge', 'sacrebleu', 'sari', 'seqeval', 'squad', 'squad_v2', 'wer', 'xnli']
一个数据集可能有多种配置。例如,正如我们之前提到的,作为聚合基准的 GLUE 有许多子集,例如 CoLA、SST-2 和 MRPC。要访问每个 GLUE 基准数据集,我们传递两个参数,其中第一个是glue,第二个是可以选择的示例数据集( cola或sst2 )的特定数据集。同样,Wikipedia 数据集为多种语言提供了多种配置。
数据集带有DatasetDict对象,包括几个Dataset实例。当使用拆分选择(split='...')时,我们得到Dataset实例。例如,CoLA数据集带有DatasetDict,其中我们有三个拆分:train、validation和test。虽然训练和验证数据集包含两个标签(1表示可接受,0表示不可接受),但测试拆分的标签值为-1,表示无标签。
让我们看看CoLA数据集的结构对象,如下:
>>> cola = load_dataset('glue', 'cola')
>>> cola
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551 })
validation: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1043 })
test: Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 1063 })
})
cola['train'][12]
{'idx': 12, 'label':1,'sentence':'Bill rolled out of the room.'}
>>> cola['validation'][68]
{'idx': 68, 'label': 0, 'sentence': 'Which report that John was incompetent did he submit?'}
>>> cola['test'][20]
{'idx': 20, 'label': -1, 'sentence': 'Has John seen Mary?'}数据集对象有一些额外的可能对我们有用的元数据信息:split、description、citation、homepage、license和info。让我们运行以下代码:
>>> print("1#",cola["train"].description)
>>> print("2#",cola["train"].citation)
>>> print("3#",cola["train"].homepage)
1# GLUE, the General Language Understanding Evaluation benchmark(https://gluebenchmark.com/) is a collection of resources for training,evaluating, and analyzing natural language understanding systems.
2# @article{warstadt2018neural, title={Neural Network Acceptability Judgments}, author={Warstadt, Alex and Singh, Amanpreet and Bowman, Samuel R}, journal={arXiv preprint arXiv:1805.12471}, year={2018}}@inproceedings{wang2019glue, title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding}, author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.}, note={In the Proceedings of ICLR.}, year={2019}}
3# https://nyu-mll.github.io/CoLA/如前所述,GLUE 基准测试提供了许多数据集。让我们下载 MRPC 数据集,如下:
mrpc = load_dataset('glue', 'mrpc')同样,要访问其他 GLUE 任务,我们将更改第二个参数,如下所示:
load_dataset('glue', 'XYZ')为了应用数据可用性的健全性检查,运行以下代码:
glue=['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli',
'mnli_mismatched', 'mnli_matched', 'qnli', 'rte',
'wnli', 'ax']
for g in glue:
_=load_dataset('glue', g)XTREME(使用跨语言数据集)是我们已经讨论过的另一个流行的跨语言数据集。让我们从 XTREME 集中挑选MLQA示例。MLQA 是 XTREME 基准测试的子集,旨在评估跨语言的性能质量保证模型。它包括大约 5,000 个 SQuAD 格式的抽取式 QA 实例,涵盖七种语言,其中是英语、德语、阿拉伯语、印地语、越南语、西班牙语和简体中文。
例如,MLQA.en.de是一个英德 QA 示例数据集,可以按如下方式加载:
en_de = load_dataset('xtreme', 'MLQA.en.de')
en_deDatasetDict({
test: Dataset({features: ['id', 'title', 'context', 'question', 'answers'], num_rows: 4517
}) validation: Dataset({ features: ['id', 'title', 'context', 'question', 'answers'], num_rows: 512})})
在 pandas DataFrame 中查看它可能更方便,如下所示:
import pandas as pd
pd.DataFrame(en_de['test'][0:4])这是前面代码的输出:

图 2.15 – 英德跨语言 QA 数据集
使用数据集库进行数据操作
数据集有很多子集的字典,其中split参数用于决定要加载哪个子集或子集的一部分。如果默认情况下为none,它将返回所有子集(训练、测试、验证或任何其他组合)的数据集字典。如果指定了split参数,它将返回单个数据集而不是字典。对于以下示例,我们仅检索可乐数据集的火车拆分:
cola_train = load_dataset('glue', 'cola', split ='train')我们可以获得训练和验证子集的混合,如下所示:
cola_sel = load_dataset('glue', 'cola', split = 'train[:300]+validation[-30:]')拆分表达式意味着前 300 个训练示例和后30 个验证示例作为cola_sel获得。
我们可以应用不同的组合,如以下拆分示例所示:
- 来自train和validation的前 100 个示例,如下所示:
split='train[:100]+validation[:100]' - 训练的50%和验证的最后 30% ,如下所示:
split='train[:50%]+validation[-30%:]' - 前 20% 的train和来自validation的切片 [30:50] 中的示例,如下所示:
split='train[:20%]+validation[30:50]'
排序、索引和改组
以下执行调用cola_sel对象的sort()函数。我们看到前 15 个和后 15 个标签:
cola_sel.sort('label')['label'][:15][0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
cola_sel.sort('label')['label'][-15:][1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
我们已经熟悉Python 切片符号。同样,我们也可以使用类似的切片符号或索引列表访问多行,如下所示:
cola_sel[6,19,44]{'idx': [6, 19, 44],
'label': [1, 1, 1],
'sentence':['Fred watered the plants flat.',
'The professor talked us into a stupor.',
'The trolley rumbled through the tunnel.']}我们洗牌数据集如下:
cola_sel.shuffle(seed=42)[2:5]{'idx': [159, 1022, 46],
'label': [1, 0, 1],
'sentence': ['Mary gets depressed if she listens to the Grateful Dead.',
'It was believed to be illegal by them to do that.',
'The bullets whistled past the house.']}重要的提示
种子值:在洗牌的时候,我们需要传递一个种子值来控制随机性,实现作者和读者输出一致。
缓存和可重用性
使用缓存文件允许我们使用快速后端通过内存映射(如果数据集适合驱动器)加载大型数据集。这种智能缓存有助于保存和重用在驱动器上执行的操作。要查看有关数据集的缓存日志,请运行以下代码:
cola_sel.cache_files[{'filename': '/home/savas/.cache/huggingface...,'skip': 0, 'take': 300}, {'filename': '/home/savas/.cache/huggingface...','skip': 1013, 'take': 30}]
数据集过滤器和地图功能
我们可能想要使用特定的数据集选择。例如,我们只能检索句子,包括可乐数据集中的术语kick,如以下执行所示。datasets.Dataset.filter ()函数返回句子包括应用匿名函数和lambda关键字的kick :
cola_sel = load_dataset('glue', 'cola', split='train[:100%]+validation[-30%:]')
cola_sel.filter(lambda s: "kick" in s['sentence'])["sentence"][:3]['Jill kicked the ball from home plate to third base.', 'Fred kicked the ball under the porch.', 'Fred kicked the ball behind the tree.']
以下过滤用于从集合中获取正面(可接受的)示例:
cola_sel.filter(lambda s: s['label']== 1 )["sentence"][:3]["Our friends won't buy this analysis, let alone the next one we propose.",
"One more pseudo generalization and I'm giving up.",
"One more pseudo generalization or I'm giving up."]
在某些情况下,我们可能不知道类标签的整数代码。假设我们有很多类,文化类的代码在 10 个类中很难记住。我们可以将一个可接受的标签传递给str2int()函数,而不是在前面的示例中给出整数代码1 ,即可接受的代码,如下所示:
cola_sel.filter(lambda s: s['label']== cola_sel.features['label'].str2int('acceptable'))["sentence"][:3]这将产生与先前执行相同的输出。
使用 map 函数处理数据
datasets.Dataset.map()函数迭代数据集,将处理函数应用于集合中的每个示例,并修改例子的内容。以下执行显示了一个新的 'len'特征被添加来表示句子的长度:
cola_new=cola_sel.map(lambda e:{'len': len(e['sentence'])})
pd.DataFrame(cola_new[0:3])这是前面代码片段的输出:

图 2.16 – 带有附加列的可乐数据集
再举一个例子,下面的一段代码在 20 个字符后截断了句子。我们不创建新的特征,而是更新句子特征的内容,如下:
cola_cut=cola_new.map(lambda e: {'sentence': e['sentence'][:20]+ '_'})这输出是此处显示:

图 2.17 – 带有更新的可乐数据集
使用本地文件
加载一个从逗号分隔值( CSV )、文本( TXT ) 或JavaScript 对象表示法( JSON ) 格式的本地文件中获取数据集,我们将文件类型(csv、文本或json)传递给通用load_dataset()加载脚本,作为如下图所示代码片段。在../data/文件夹下,有 3 个 CSV 文件(a.csv、b.csv和c.csv),它们是随机的从 SST-2 数据集中选择玩具示例。我们可以加载单个文件,如data1对象所示,合并多个文件,如data2对象,或进行数据集拆分,如data3:
from datasets import load_dataset
data1 = load_dataset('csv', data_files='../data/a.csv', delimiter="\t")
data2 = load_dataset('csv', data_files=['../data/a.csv','../data/b.csv', '../data/c.csv'], delimiter="\t")
data3 = load_dataset('csv', data_files={'train':['../data/a.csv','../data/b.csv'], 'test':['../data/c.csv']}, delimiter="\t")为了获取其他格式的文件,我们传递json或text代替csv,如下:
data_json = load_dataset('json', data_files='a.json')
data_text = load_dataset('text', data_files='a.txt')到目前为止,我们有讨论了如何加载、处理和操作已经托管在集线器中或本地驱动器上的数据集。现在,我们将研究如何为 Transformer 模型训练准备数据集。
为模型训练准备数据集
让我们从标记化过程。每个模型都有它的在实际语言模型之前训练的自己的标记化模型。我们将在下一章详细讨论这一点。要使用分词器,我们应该已经安装了Transformer库。以下示例从预训练的 distilBERT-base-uncased模型加载标记器模型。我们使用map和带有lambda的匿名函数来对data3中的每个拆分应用标记器。如果在map函数中选择了批处理,则它会向tokenizer函数提供一批示例。batch_size值为1000 _默认情况下,这是传递给函数的每批示例的数量。如果未选中,则整个数据集将作为单个批次传递。代码可以在这里看到:
from Transformer import DistilBERTTokenizer
tokenizer = DistilBERTTokenizer.from_pretrained('distilBERT-base-uncased')
encoded_data3 = data3.map(lambda e: tokenizer( e['sentence'], padding=True, truncation=True, max_length=12), batched=True, batch_size=1000)如以下输出所示,我们看到了data3和encoded_data3之间的区别,其中两个额外的特征—— attention_mask和input_ids ——被相应地添加到数据集中。我们已经在本章的前面部分介绍了这两个特性。简而言之,input_ids是句子中每个标记对应的索引。它们是 Transformer 的Trainer类所需的预期功能,我们将在接下来的微调章节中讨论。
我们大多通过一次几个句子(称为批处理)到标记器并进一步将标记化的批次传递给模型。为此,我们将每个句子填充到批处理中的最大句子长度或由max_length参数指定的特定最大长度——在这个玩具示例中为12 。我们还截断较长的句子以适应最大长度。该代码可以在以下代码段中看到:
data3DatasetDict({
train: Dataset({
features: ['sentence','label'], num_rows: 199 })
test: Dataset({
features: ['sentence','label'], num_rows: 100 })})
encoded_data3DatasetDict({
train: Dataset({
features: ['attention_mask', 'input_ids', 'label', 'sentence'],
num_rows: 199 })
test: Dataset({
features: ['attention_mask', 'input_ids', 'label', 'sentence'],
num_rows: 100 })})
pprint(encoded_data3['test'][12]){'attention_mask': [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], 'input_ids': [101, 2019, 5186, 16010, 2143, 1012, 102, 0, 0, 0, 0, 0], 'label': 0, 'sentence': 'an extremely unpleasant film . '}
我们是使用数据集库完成。至此,我们评估了数据集的所有方面。我们已经介绍了类似 GLUE 的基准测试,其中考虑了分类指标。在下一节中,我们将重点关注如何对速度和内存而不是分类的计算性能进行基准测试。
速度和内存的基准测试
只是比较分类大型模型在特定任务或基准证明不再足够。我们现在必须考虑给定环境(随机存取内存( RAM )、CPU、GPU)在内存使用和速度方面的特定模型的计算成本。训练和部署到生产以进行推理的计算成本是要衡量的两个主要值。Transformer库的两个类PyTorchBenchmark和TensorFlowBenchmark使得对 TensorFlow 和 PyTorch 的模型进行基准测试成为可能。
在我们开始实验之前,我们需要通过以下执行检查我们的 GPU 能力:
import torch
print(f"The GPU total memory is {torch.cuda.get_device_properties(0).total_memory /(1024**3)} GB")The GPU total memory is 2.94921875 GB
输出来自 NVIDIA GeForce GTX 1050 ( 3 GB )。我们需要更强大的资源来进行高级实施。Transformer库目前仅支持单设备基准测试。当我们在 GPU 上进行基准测试时,我们需要指出 Python 代码将在哪个 GPU 设备上运行,这是通过设置CUDA_VISIBLE_DEVICES环境变量来完成的。例如,导出 CUDA_VISIBLE_DEVICES=0。O表示将使用第一个cuda设备。
在下面的代码示例中,探索了两个网格。我们比较了模型数组中列出的四个随机选择的预训练 BERT 模型。要观察的第二个参数是sequence_lengths。我们将批量大小保持为4。如果你有一个更好的GPU容量,可以扩展参数搜索批处理值在 4-64 范围内的空间和其他参数:
from Transformer import PyTorchBenchmark, PyTorchBenchmarkArguments
models= ["BERT-base-uncased","distilBERT-base-uncased","distilroBERTa-base", "distilBERT-base-german-cased"]
batch_sizes=[4]
sequence_lengths=[32,64, 128, 256,512]
args = PyTorchBenchmarkArguments(models=models, batch_sizes=batch_sizes, sequence_lengths=sequence_lengths, multi_process=False)
benchmark = PyTorchBenchmark(args)重要的提示
TensorFlow 基准测试:代码示例用于这部分的 PyTorch 基准测试。对于 TensorFlow 基准测试,我们只需使用TensorFlowBenchmarkArguments和TensorFlowBenchmark对应类。
我们准备通过运行以下代码来进行基准测试:
results = benchmark.run()这可能需要一些时间,具体取决于您的 CPU/GPU 容量和参数选择。如果您遇到内存不足的问题,您应该采取以下措施来克服这个问题:
- 重启你的内核或您的操作系统。
- 删除所有启动前内存中不必要的对象。
- 设置较低的批量大小,例如 2,甚至 1。
以下输出指示推理速度性能。由于我们的搜索空间有四种不同的模型和五种不同的序列长度,我们在结果中看到 20 行:

图 2.18 – 推理速度表现
同样,我们看到了 20 种不同场景的推理内存使用情况,如下所示:

图 2.19 – 推理内存使用
观察记忆跨参数的使用,我们将使用存储统计信息的结果对象。以下执行将绘制跨模型和序列长度的时间推理性能:
import matplotlib.pyplot as plt
plt.figure(figsize=(8,8))
t=sequence_lengths
models_perf=[list(results.time_inference_result[m]['result'][batch_sizes[0]].values()) for m in models]
plt.xlabel('Seq Length')
plt.ylabel('Time in Second')
plt.title('Inference Speed Result')
plt.plot(t, models_perf[0], 'rs--', t, models_perf[1], 'g--.', t, models_perf[2], 'b--^', t, models_perf[3], 'c--o')
plt.legend(models)
plt.show()如图所示以下截图,两个 DistillBERT 模型显示接近结果和表现优于其他两个模型。与其他模型相比,基于 BERT 的未封装模型表现不佳,尤其是在序列长度增加时:
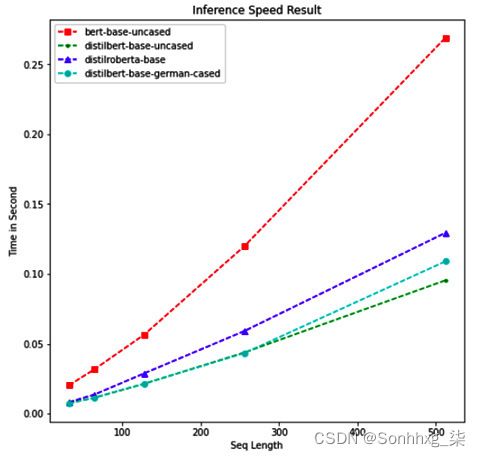
图 2.20 – 推理速度结果
要绘制内存性能,您需要使用结果对象的memory_inference_result结果而不是time_inference_result,如前面的代码所示。
更多有趣的基准测试示例,请查看以下链接:
- Benchmarks
- https://github.com/huggingface/transformers/tree/master/notebooks
现在我们已经完成了这一节,我们成功地完成了这一章。恭喜您完成安装、运行您的第一个hello-world转换器程序、使用数据集库和基准测试!
概括
在本章中,我们介绍了各种介绍性主题,还亲身体验了hello-world转换器应用程序。另一方面,本章在将目前学到的知识应用到即将到来的章节方面发挥着至关重要的作用。那么,到目前为止学到了什么?我们通过设置环境和系统安装迈出了第一步。在这种情况下,anaconda包管理器帮助我们安装了主要操作系统的必要模块。我们还研究了语言模型、社区提供的模型和标记化过程。此外,我们引入了多任务 (GLUE) 和跨语言基准测试 (XTREME),使这些语言模型变得更强大、更准确。数据集引入了库,有助于高效访问社区提供的 NLP 数据集。最后,我们学习了如何根据内存使用和速度来评估特定模型的计算成本。Transformer 框架可以对 TensorFlow 和 PyTorch 的模型进行基准测试。
本节中使用的模型已经被社区训练并与我们分享。现在,轮到我们训练语言模型并将其传播给社区了。
在下一章中,我们将学习如何训练 BERT 语言模型和分词器,并了解如何与社区分享它们。