基于Bert语言模型的中文短文本分类
基于Bert语言模型的中文短文本分类
一、前言
本次的任务是基于谷歌开源的Bert语言模型,进行微调,完成中文短文本分类任务。利用爬虫从微博客户端中获取热门评论,做为训练语料。
二、添加自定义类MyDataProcessor
添加自定义类MyDataProcessor,完成训练和测试语料的文件读取和预处理工作。
class MyDataProcessor(DataProcessor):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
# 读入训练文本数据
file_path = os.path.join(data_dir,'train_sentiment.txt')
f = open(file_path,'r',encoding='utf-8')
train_data = []
index = 0
# 以行的方式读入
for line in f.readlines() :
# guid用来区分每一个example
guid = "train-%d" % (index)
line = line.replace('\n','').split('\t')
# text_a 要分类的文本
text_a = tokenization.convert_to_unicode(str(line[1]))
# 文本对应的分类类别
label = str(line[2])
train_data.append(
InputExample(guid=guid,text_a=text_a,text_b=None,label=label))
index += 1
return train_data
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
# 读入测试文本数据
file_path = os.path.join(data_dir, 'test_sentiment.txt')
f = open(file_path, 'r', encoding='utf-8')
dev_data = []
index = 0
# 以行的方式读入
for line in f.readlines():
# guid用来区分每一个example
guid = "dev-%d" % index
line = line.replace('\n', '').split('\t')
# text_a 要分类的文本
text_a = tokenization.convert_to_unicode(str(line[1]))
# 文本对应的分类类别
label = str(line[2])
dev_data.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
index += 1
return dev_data
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
# 读入文本数据
file_path = os.path.join(data_dir, 'test.csv')
test_df = pd.read_csv(file_path,encoding='utf-8')
test_data = []
# 以行的方式读入
for index,test in enumerate(test_df.values) :
# guid用来区分每一个example
guid = "test-%d" % index
# text_a 要分类的文本
text_a = tokenization.convert_to_unicode(str(test[0]))
# 文本对应的分类类别
label = str(test[1])
test_data.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
index += 1
return test_data
def get_labels(self):
"""Gets the list of labels for this data set."""
return ['0','1','2']
MydataProcessor类中包含三个方法:get_train_examples(),get_dev_examples(),get_test_examples。其实逻辑思路按照开源程序中英文文本分类任务的进行修改即可。需要注意的是,英文文本分类任务中包含text_a 和 text_b,而在本次任务中只有text_a因此可以将text_b = None.最终 get_labels()方法返回三个标签[“0”,“1”,“2”],分别对应[“中立”,“正向”,“负向”] .
三、修改主类
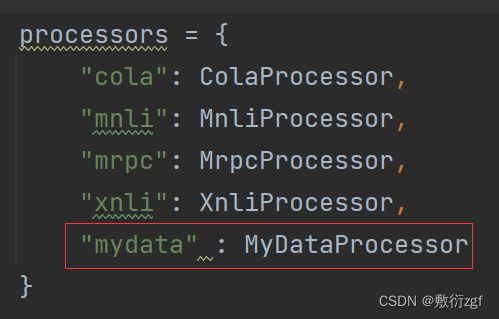
在主类中添加自定义类的类名。
四、修改运行参数
–task_name=mydata # 修改为自定义类类名
–do_train=true # 是否训练
–do_eval=true # 是否验证
–data_dir=…/GLUE/glue_data/mydata
–vocab_file=…/GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/vocab.txt
–bert_config_file=…/GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_config.json
–init_checkpoint=…/GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_model.ckpt
–max_seq_length=128 # 文本最大长度
–train_batch_size=6
–learning_rate=2e-5 # 学习率
–num_train_epochs=1.0
–output_dir=…/GLUE/chineseoutput # 模型的最终保存位置
中文文本分类任务:
--task_name=mydata
--do_train=true
--do_eval=true
--data_dir=../GLUE/glue_data/mydata
--vocab_file=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/vocab.txt
--bert_config_file=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_config.json
--init_checkpoint=../GLUE/BERT_BASE_DIR/chinese_L-12_H-768_A-12/bert_model.ckpt
--max_seq_length=128
--train_batch_size=6
--learning_rate=2e-5
--num_train_epochs=1.0
--output_dir=../GLUE/chineseoutput
英文文本分类任务:
--task_name=MRPC
--do_train=true
--do_eval=true
--data_dir=../GLUE/glue_data/MRPC
--vocab_file=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/vocab.txt
--bert_config_file=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/bert_config.json
--init_checkpoint=../GLUE/BERT_BASE_DIR/uncased_L-12_H-768_A-12/bert_model.ckpt
--max_seq_length=128
--train_batch_size=6
--learning_rate=2e-5
--num_train_epochs=3.0
--output_dir=../GLUE/output
五、运行
配置完参数后直接运行
报错:tensorflow.python.framework.errors_impl.DataLossError: Checksum does not match: stored 4283821441 vs. calculated on the restored bytes 2653108158
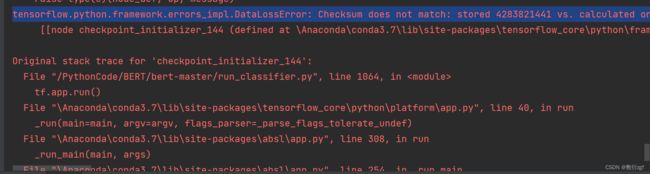
经过查阅资料,发现可能是由于ckpt文件有问题,下载的Bert预训练模型中的中文ckpt文件出错;
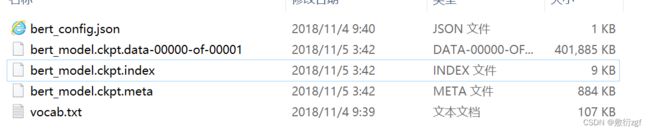
解决方法: 重新换一个ckpt文件
更换过后
报错:tensorflow.python.framework.errors_impl.OutOfRangeError: Read fewer bytes than requested

解决方案: 重新换回原来的文件
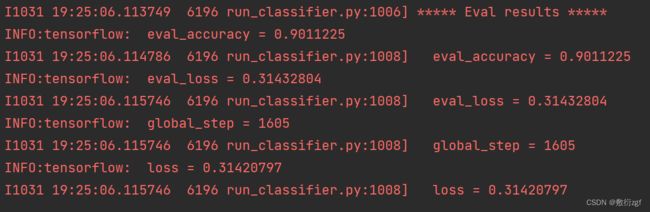
模型可以跑起来了!!!
等待若干小时