论文精读:Axial-DeepLab: Stand-Alone Axial-Attention forPanoptic Segmentation
论文地址:https://arxiv.org/abs/2003.07853
Abstract
卷积利用局部性来提高效率,但代价是缺少长期上下文。自我注意已经被用来通过非局部的交互作用来增强cnn。最近的研究证明,通过将注意力限制在一个局部区域,可以通过叠加自注意层来获得一个完全的注意网络。本文试图通过将二维自注意分解为两个一维自注意来消除这一约束。这降低了计算的复杂度,并允许在一个更大的、甚至是全局的区域内执行注意力。与此,我们还提出了一种位置敏感的自我注意设计。结合这两者,我们可以得到位置敏感轴向注意层,这是一种新的构建块,可以堆叠形成轴向注意模型,用于图像分类和密集预测的预测。结合这两者,我们可以得到位置敏感轴向注意层,这是一种新的构建块,可以堆叠形成轴向注意模型,用于图像分类和密集预测的预测。我们在四个大规模数据集上证明了我们的模型的有效性。
1 Introduction
卷积具有就局部性,缺少上下文特征交互,而全局注意力机制计算规模大,局部注意力机制限制了图像的接受域。
在这项工作中,我们建议采用轴向注意[32,39],它不仅允许有效的计算,而且在独立的注意模型中恢复了较大的接受域。其核心思想是将二维注意沿高度轴和宽度轴顺序分解为两个一维注意。它的效率使我们能够关注大的区域,并建立模型来学习长期甚至全局的交互。此外,之前的大多数注意力模块都没有利用位置信息,这降低了注意力在建模与位置相关的交互作用时的能力,比如在多个尺度上的形状或物体。最近的研究工作引入了位置编码的注意力机制,但以一种与上下文无关的方式。在本文中,我们将位置项增强为与上下文相关的,使我们的注意力对位置敏感,并具有边际成本。
我们的贡献如下:
该方法是首次尝试建立具有大的或全局接受域的独立注意模型。
我们提出了位置敏感注意层,它可以更好地利用位置信息,而不增加太多的计算成本。
我们表明,轴向注意工作得很好,不仅作为一个独立的图像分类模型,而且作为panoptic segmentation、instance segmentation和segmantic segmentation的骨干。
3 Method
3.1 Position-Sensitive Self-Attention
Position-Sensitivity: 之前的位置偏置项仅仅包含query,作者提出在keys、values也加入位置偏置项,公式如下:


3.2 Axial-Attention
局部注意力机制显著降低了视觉任务中的计算成本,并使建立完全的自注意模型成为可能。然而,这种约束牺牲了全局连接,使注意力的接受域不大于具有相同核大小的深度卷积。此外,在局部平方区域中进行的局部自注意仍然具有区域长度的二次复杂性,引入了另一个超参数来进行性能和计算复杂度之间的权衡。在这项工作中,我们建议在独立的自注意中采用轴向注意,以确保全局连接和高效的计算。具体来说,我们首先将图像的宽轴上的轴向注意层简单地定义为一维位置敏感的自注意,并对高度轴使用类似的定义。具体来说,沿宽轴的轴向注意层定义如下:

一个轴向注意层沿着一个特定的轴传播信息。为了获取全局信息,我们分别对高度轴和宽度轴分别使用两个轴向注意层。这两个轴向注意层都采用了多头注意机制。
轴向注意可将复杂性降低到O(hwm)。这使得全局接受域成为可能,这是通过将跨度m直接设置为整个输入特征来实现的。另外,还可以使用固定的m值,以减少巨大特性映射上的内存占用。
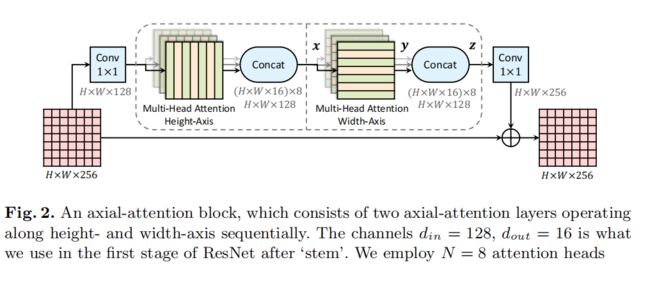
Axial-ResNet: 为了将ResNet [31]转换为Axial-ResNet,我们将residual bottleneck中的3×3卷积替换为两个多头轴向注意层(一个用于高度轴,另一个用于宽轴)。在相应的轴向注意层之后的每个轴上执行可选的stride操作。这两个1×1的卷积被保留进行特征整合。这形成了我们的(residual) axial-attention block,如图2所示,它被多次堆叠以获得Axial-ResNets.。请注意,我们没有在两个轴向注意层之间使用1×1的卷积,因为矩阵乘法(WQ,WK,WV)立即跟随。此外,保留原始ResNet中的stem(即第一个串的7×7卷积和3×3最大池),从而形成一个conv-stem模型,其中第一层使用卷积,注意层在其他地方使用。在conv-stem模型中,我们将跨度m设置为来自第一个块的整个输入,其中特征图大小为56×56。
在我们的实验中,我们还建立了一个full axial-attention模型,称为全轴向resnet,它进一步将轴向注意应用于Full Axial-ResNet。我们没有设计一个特殊的spatially-varying attention stem,而是简单地堆叠了三个axial-attention bottleneck blocks.。此外,为了降低Full Axial-ResNets的计算量,我们在前几个块中采用局部注意力(即局部m*m区域)。
Axial-DeepLab: 为了进一步将轴向resnet转换为轴向deeplab用于分割任务,我们做了几个更改,如下所述。
首先,为了提取密集的特征图,DeepLab [12]改变了ResNet [31]中最后一个或两个阶段的步幅和空洞率。类似地,我们删除了最后一阶段的步幅,但我们没有实现“空洞”的注意力模块,因为我们的轴向注意力已经捕获了整个输入的全局信息。在这项工作中,我们提取了具有输出步幅(即输入分辨率与最终主干特征分辨率的比率)的特征映射16。我们不追求输出步幅8,因为它的计算成本很高。
其次,我们不采用空间空间金字塔池模块(ASPP),因为我们的轴向注意块也可以有效地编码多尺度或全局信息。我们在实验中表明,我们的没有ASPP的Axial-DeepLab的性能优于全光学-Panoptic-DeepLab。
最后,参考Panoptic-DeepLab,我们采用了完全相同的三个卷积、双解码器和预测头。头部产生语义分割和类不可知的实例分割,并通过多数投票的[89]进行合并,形成最终的panoptic segmentation。
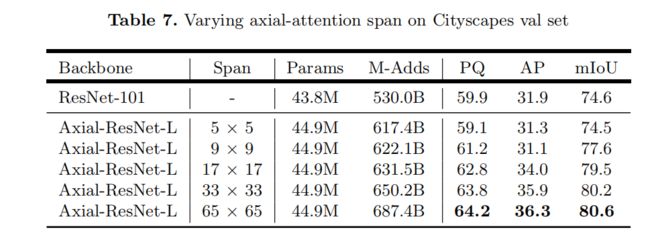
在输入非常大(例如,2177×2177)和内存受限的情况下,我们在所有轴向注意块中采用大跨度(m = 65)。请注意,我们不将轴向跨度视为超参数,因为它已经足以覆盖多个数据集的长范围甚至全局上下文,并且设置较小的跨度不会显著减少m-add。
4 Experimental Results
4.1 ImageNet


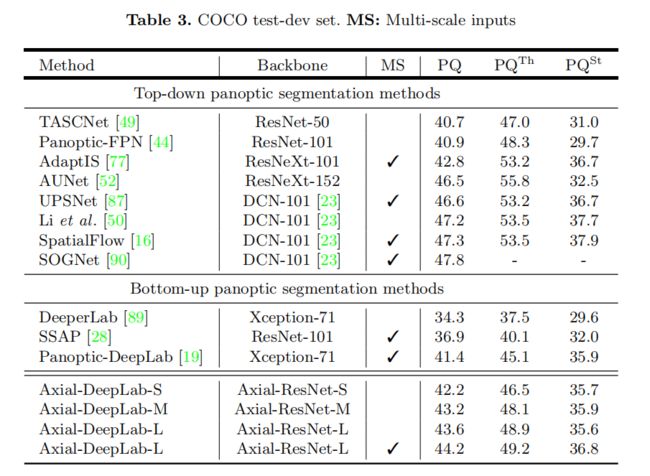
4.2 COCO

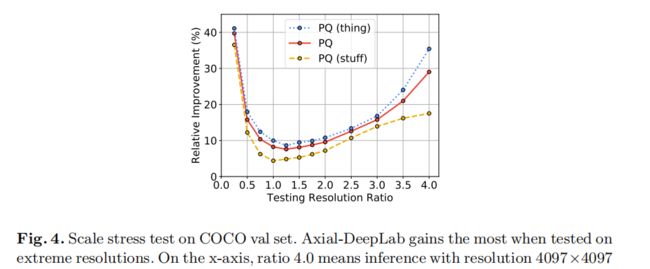
4.3 Mapillary Vistas

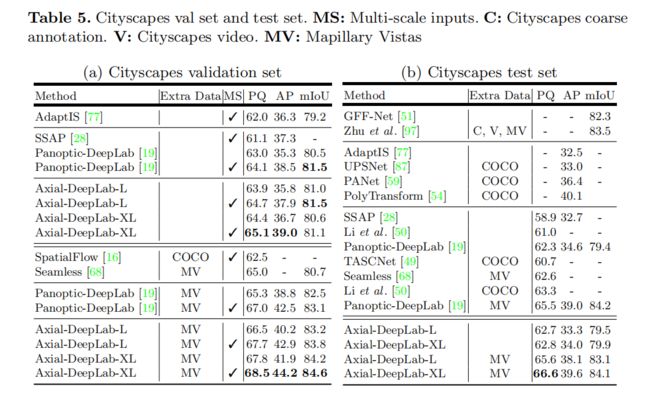
4.4 Cityscapes
4.5 Ablation Studies
Importance of Position-Sensitivity and Axial-Attention: 位置敏感注意比之前的自注意力机制表现得更好,轴向注意力显著提高性能和大型输入图像分割任务编码能力。

Importance of Axial-Attention Span: 较大的跨度能够持续提高性能,同时也需要额外的计算成本。