目标检测新方法(DETR)
TOC
DETR — End-to-End Object Detection with Transformers
outline
摘要:
我们提出了一种将对象检测视为直接集预测问题的新方法。 我们的方法简化了检测流程,有效地消除了对许多手工设计的组件的需求,例如非最大抑制程序或锚点生成,这些组件明确编码了我们对任务的先验知识。 新框架的主要成分称为DEtection TRANSformer或DETR,是基于集合的全局损耗,它通过二分匹配和变压器编码器-解码器体系结构来强制进行唯一的预测。 给定固定的学习对象查询集,则DETR会考虑对象与全局图像上下文之间的关系,以直接并行并行输出最终的预测集。 与许多其他现代检测器不同,新模型在概念上很简单,并且不需要专门的库。 DETR与具有挑战性的COCO对象检测数据集上成熟且高度优化的Faster RCNN基线具有同等的准确性和运行时性能。 此外,可以很容易地将DETR概括为以统一的方式产生全景分割。 我们证明它明显优于竞争基准。 培训代码和预训练模型可在https://github.com/facebookresearch/detr中获得。
DETR 将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。
传统的目标检测(以faster-rcnn为代表)的流程:backbone提取特征->利用RPN枚举所有的框并筛选regeion proposal->在regeion proposal上得到每个框的类别和置信度。
存在的问题:
- 枚举了每个特征图上的像素点;在每个像素点上枚举预定义的anchor;造成大多数的候选框是坏的,无效的,缓慢的。
- RPN输出了太多冗余的框需要NMS来删除;
- 手工涉及的元素只有很少的超参数可以调节
- 模型tuning比较复杂
DETR提出一个比较简洁的pipeline,去除先验性操作和手工操作。
pipeline
论文所示的主要流程如下图所示:
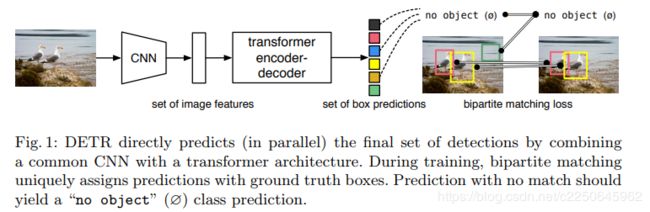
输入图片->backbone提取特征->构造一组图像特征集->经过transformer的编解码模块->直接预测…
about transformer
为了更好的理解当中的关键点,这里对transformer相关的内容做一个笔记,真的是万事开头难,然后更难…
transformer outline
Transformer是2017年NIPS上的文章,题目为Attention is All You Need。它使用attention组成了encoder-decoder的框架,并将其用于机器翻译。它的大致结构如下:

编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起——数字6没有什么神奇之处,你也可以尝试其他数字)。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
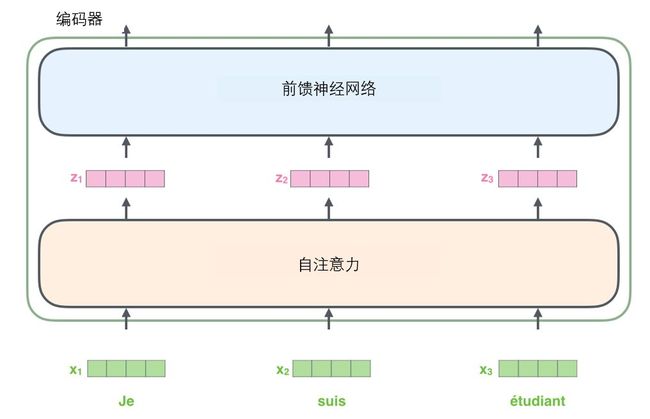
编码器和解码器在结构上都是相同的,但没有共享参数。每个而解码器都可以分解成两个子层。


self-attention
(单头)自注意力机制。
自注意力机制原本关注的就是当前的这个单词与句子当中其余单词的关联。
为了解释自注意力机制的原理,首先引入一张图来介绍几个概念:

-
词嵌入向量:在NLP的应用中,一般句子当中的每个单词都会通过词嵌入算法将单词转换为词向量(无论多长的单词,一般都会转换为统一长度的向量,比如512)。

-
查询向量:将每个词嵌入向量与 W Q W^Q WQ 向量相乘得到。用于与所有的键向量相乘直接得到分数。
-
键向量:同样的,将每个词嵌入向量与 W K W^K WK 得到。
-
值向量:同上。用于对每个单词的分数的加权。
具体的计算不步骤如下图所示:

-
将查询向量与每个键向量相乘,得到打分,比如112,96,此打分评估Thinking与Machines这两个单词与自身以及其余单词的相关性。
-
将打分除以键向量维数的平方根( 64 = 8 \sqrt{64}=8 64=8),据说这样有利于梯度稳定。
-
进行softmax进行归一化,每个单词都得到一个权重。
-
将每个值向量按照每个单词的权重进行加权求和。得到 Z i Z_i Zi
以上过程都可用矩阵实现
多头注意力机制
所谓多头注意力机制,就是对每个单词,都有多个查询/键/值向量。其余过程与单头相同:
 quanzhong
quanzhong
Z 0 . . . Z 7 Z_0...Z_7 Z0...Z7的拼接与转换如下所示:

positional encoding
在NLP中,句子中的单词也需要一个位置编码,用于建立单词之间的距离。encoder 为每个输入 embedding 添加了一个向量,这些向量符合一种特定模式,可以确定每个单词的位置,或者序列中不同单词之间的距离。例如,input embedding 的维度为4,那么实际的positional encodings如下所示:
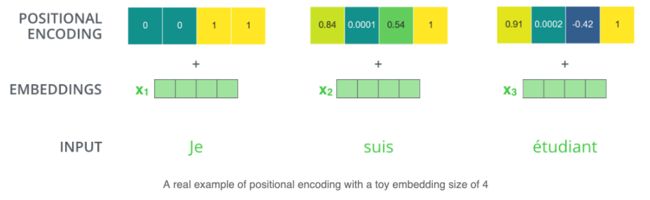
位置编码的方式:
- 构造一个跟输入embedding维度一样的矩阵。行表示词语,列表示词向量,也就是每个词的embedding向量。
- 利用如下公式进行编码,编码公式如下:
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d model ) P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{2 i / d_{\text {model}}}\right) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\text {model}}}\right) PE(pos,2i+1)=cos(pos/100002i/dmodel)
PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;$ d_{model}$表示词向量的维度;i表示词向量的位置。因此,上述公式表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此来填满整个PE矩阵,然后加到input embedding中去,这样便完成位置编码的引入了。
这么做的好处是什么:
根据
{ sin ( α + β ) = sin α cos β + con α sin β cos ( α + β ) = cos α cos β − sin α sin β \left\{\begin{array}{c} \sin (\alpha+\beta)=\sin \alpha \cos \beta+\operatorname{con} \alpha \sin \beta \\ \cos (\alpha+\beta)=\cos \alpha \cos \beta-\sin \alpha \sin \beta \end{array}\right. {sin(α+β)=sinαcosβ+conαsinβcos(α+β)=cosαcosβ−sinαsinβ
如果我们要求 P E ( p o s + k , 2 i ) PE(pos+k,2i) PE(pos+k,2i)的向量的时候,可表示为对 P E ( p o s , 2 i ) PE(pos,2i) PE(pos,2i)上的线性表示:
{ P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) × P E ( k , 2 i + 1 ) + P E ( p o s , 2 i + 1 ) × P E ( k , 2 i ) P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + 1 ) × P E ( k , 2 i + 1 ) − P E ( p o s , 2 i ) × P E ( k , 2 i ) \left\{\begin{aligned} P E(p o s+k, 2 i) &=P E(p o s, 2 i) \times P E(k, 2 i+1)+P E(p o s, 2 i+1) \times P E(k, 2 i) \\ P E(p o s+k, 2 i+1) &=P E(p o s, 2 i+1) \times P E(k, 2 i+1)-P E(p o s, 2 i) \times P E(k, 2 i) \end{aligned}\right. {PE(pos+k,2i)PE(pos+k,2i+1)=PE(pos,2i)×PE(k,2i+1)+PE(pos,2i+1)×PE(k,2i)=PE(pos,2i+1)×PE(k,2i+1)−PE(pos,2i)×PE(k,2i)
在下图中,是20个单词的 positional encoding,每行代表一个单词的位置编码,即第一行是加在输入序列中第一个词嵌入的,每行包含 512 个值, 每个值介于 -1 和 1 之间,用颜色表示出来。

可以看到在中心位置分成了两半,因为左半部分的值由一个正弦函数生成,右半部分由余弦函数生成,然后将它们连接起来形成了每个位置的编码向量。
当然这并不是位置编码的唯一方法,只是这个方法能够扩展到看不见的序列长度处,例如当我们要翻译一个句子,这个句子的长度比我们训练集中的任何一个句子都长时。
作者:不会停的蜗牛
链接:https://www.jianshu.com/p/e7d8caa13b21
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在原本的transormer中positional encoding向量与词嵌入向量是直接相加得到的。但是在DETR中有了略微的改变。
transformer of DETR
介绍了关于transformer的一些关键点,再来看DETR,就不会那么难理解了。
对比这两张图,左图为原本的transformer的结构,右图为DETR修改后的transformer的结构。

-
从结构上看,在输出的分支上,DETR利用FFN引出了两个分支,一个做分类,一个做BBox的回归。
-
从Encoder和Decoder输入来看,positional encoding在原本的transformer中是直接与input embeding相加,但是在DETR中,
Encoder
介绍完了一些基本的概念,以及多头自注意力机制和位置编码,这里需要提一下的就是decoder中的前向传播和归一化操作以及残差连接。回顾一下上面这张图,可以清晰的看出整个Encoder的每一层EncoderLayer由四个部分组成:多头注意力机制模块、Add & Norm模块、前向传播模块,一共有6层。
每一层的操作完全一致,每一层的具体细节为:
-
进入Encoder的参数有三个:
- backbone最后一层输出的特征图src(维度映射到了hidden_dim,所以也可以叫做特征向量了,因为不再是二维的了),shape=(HW,batch,hidden_dim);
- 最后一层的特征图的位置编码pos,shape=(HW,batch,hidden_dim);
- 以及对应最后一层输出的特征图对应的mask,shape=(batch,HW)。
-
EncoderLayer的前向过程分为两种情况:
- 一种是在输入多头自注意力层和前向反馈层前先进行归一化;
- 另一种则是在这两个层输出后再进行归一化操作。
-
这里一般默认选择在多头自注意力层和前向反馈层后进行归一化,将"1"中的特征图进行LayerNormlize(与batchNormlize不同,LayerNormlize是在Channel这个维度去做归一化。)

看图片不一定能看得很清楚,举个例子,对于一个(Batch,C,H,W)的张量:
- BN:会在batch size这个维度,对不同样本的同一个通道直接做归一化,得到C个均值和方差,以及C个 γ , β \gamma ,\beta γ,β ,注意:BN在做归一化的时候,是对整个Batch size张同一通道的特征图也就是Batch*H*W个值求一个均值而不是对Batch size个值求一个均值。关于为什么要将一层特征图全部都做归一化呢?梁博:是因为,BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。而对于同一张特征图而言,共用了同一个卷积,所以需要整张图分布趋同。
- LN:会在Channel这个维度进行归一化处理,也就是,对同一个样本的不同Channel之间做均值LN,最后求得Batch Size个均值。
-
将特征图分成三份,一份直接作为V值向量,其余两份与位置编码向量直接相加,分别作为K(键向量),Q(查询向量)。
-
将KVQ输入多头注意力模块,输出一个src1,shape=(HW,batch,hidden_dim);
-
与原src直接相加短接;
-
进行第一次LN;
-
linear,Relu激活,dropout,linear还原维度,dropout,再与8的输入短接。
-
第二次LN。
-
输入下一个EncoderLayer;
-
经过6个EncoderLayer后,encoder结束;
Obeject Query
在进入decoder之前,必须要了解Obeject Query的意义。positional encodings是对feature的编码,那么Obeject Query是对anchor的编码,并且这个anchor是一个全参数可学习的。
Obeject Query的具体表现形式是query embeding,在源代码中,这是一个torch.nn.Embedding的对象,官方介绍:一个保存了固定字典和大小的简单查找表。这个模块常用来保存词嵌入和用下标检索它们。模块的输入是一个下标的列表,输出是对应的词嵌入。
个人理解:这是一个矩阵类,里面初始化了一个随机矩阵,矩阵的长是字典的大小,宽是用来表示字典中每个元素的属性向量,向量的维度根据你想要表示的元素的复杂度而定。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。实际上query embeding当中就一个tensor,就是一个(num_queries,hidden_dim)的矩阵,num_queries指的是预设的最大bbox的个数,通常设为100。
同样的,query embeding也有一个位置编码query pos,这个编码没有用sin 与 cos的编码形式,而是一个与query embeding相同shape的向量,并且参与到网络的学习当中。
decoder
decoder的结构与encoder的机构非常相似,decode的输入包括了几个部分:
- query embeding ,shape=(num_queries,batch,hidden_dim)
- query pos,shape=(num_queries,batch,hidden_dim)
- encoder的输出,shape=(HW,batch,hidden_dim)
- pos
decoder在结构上相比encoder每层多了一个多头注意力机制和Add & Norm,目的是对query embeding与query pos进行学习,注意:和Encoder相同,DecoderLayer也是6层,每一层输入都是除了上一层的输出以外,还要单独重新加入query pos与encoder中的positional encoding。
decoder流程:
- query embeding(第一次输入是query embeding,第二次是上一层的输出out)与query pos相加得到q,k;
- 将q与k输入以及out(作为值向量)输入第一个多头注意力模块,得到输出shape=(num_queries,batch,hidden_dim);
- 将上层输出进行dropout与out相加输出;
- 将out+query pos相加作为q,将encoder的输出与词嵌入向量pos想加作为k,encoder的输出作为v作为输入,进入第二个多头注意力模块
- LN+drop…
- 经过6个DecoderLayer后输出:[num_queries, batch,hidden_dim ]的向量
- 将output堆叠成一个(6,num_queries, batch,hidden_dim)的向量后输出
FFN
最后是接了一个FFN,就是两个全连接层,分别进行分类和bbox坐标的回归。
分类分支输出一个outputs_class,shape=(6,batch,100,num_classs)的tensor。(outputs_class原本输出为(batch,100,hidden),经stack6层)
bbox坐标回归分支输出一个outputs_coord,shape=(6,batch,100,4)的tensor
Loss
损失一共分为:loss_labels,loss_cardinality,loss_boxes,loss_masks(如果要做分割任务)。
在源码中,专门用了一个SetCriterion(nn.Modlue)类来进行loss的计算。
- 分类loss:CEloss(交叉熵损失);
- 回归loss的计算包括预测框与GT的中心点和宽高的L1 loss以及GIoU loss
- loss_cardinality,后面再说。
匈牙利算法
集合到集合的预测看起来非常直接,但是在训练的过程就会遇到一个问题,就是如何把预测出来的100个框与ground truth做匹配,然后得到损失。DETR就非常暴力,直接利用pd(predicttion)与gt(ground truth)按照最小权重做一对一匹配,剩余的框全部当做背景处理。
此权重的构成:
- 分类损失:这里分类损失是由直接-softmax的值取出来的。举个例子:预测100个目标框,每个目标框有92个候选类别,经softmax输出后有out,shape=(100,92)。根据groundtruth的target标签假设(有20个),根据这些类别值直接作为索引值筛选出每个年预测目标框的类别以及概率,最后剩下了=(100,20)的softmax的值。也就是说只把图片内存在的类别作为交叉熵损失的选择,然后用1-softmax来作为损失,由于1是常数,直接进行了一个省略。
- 目标框的损失是将预测的目标框,与gt中每个目标框做L1损失,假设gt有20个目标框,就会产生200*20个损失值。
- 同上,求IOU并取负做损失
损失加权求和作为总损失。
然后利用匈牙利匹配出目标框,将预测框的索引值和对应位置的gt目标狂的索引配对输出。其余的就直接抛弃。
简单demo分析
这里直接从源码中进行分析(官方提供了一个非常丝滑的前向推断的demo,backbone用的resnet50,然后最重要的就是,position encoding选择的方式是x与y方向可学习的(50,128)的位置编码。代码真的非常简单,整体结构一目了然):detr_demo
首先解析一下主要的网络结构的代码:
class DETRdemo(nn.Module):
"""
Demo DETR implementation.
Demo implementation of DETR in minimal number of lines, with the
following differences wrt DETR in the paper:
* learned positional encoding (instead of sine)
* positional encoding is passed at input (instead of attention)
* fc bbox predictor (instead of MLP)
The model achieves ~40 AP on COCO val5k and runs at ~28 FPS on Tesla V100.
Only batch size 1 supported.
"""
def __init__(self, num_classes, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# create ResNet-50 backbone
self.backbone = resnet50() #backbone选择的是resnet50
del self.backbone.fc #去掉resnet50的全连接层
# create conversion layer
self.conv = nn.Conv2d(2048, hidden_dim, 1) #1*1卷积进行降维,形成hidden_dim个channel的特征向量
# create a default PyTorch transformer
self.transformer = nn.Transformer(
hidden_dim, nheads, num_encoder_layers, num_decoder_layers) #transformer模块
# prediction heads, one extra class for predicting non-empty slots
# note that in baseline DETR linear_bbox layer is 3-layer MLP
self.linear_class = nn.Linear(hidden_dim, num_classes + 1) #分为两个分支,一个分支预测类别(为什么加1呢,因为对与背景,实际上给了一个$的类别)
self.linear_bbox = nn.Linear(hidden_dim, 4) #预测bbox
# output positional encodings (object queries)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# spatial positional encodings
# note that in baseline DETR we use sine positional encodings
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
# propagate inputs through ResNet-50 up to avg-pool layer
x = self.backbone.conv1(inputs)
x = self.backbone.bn1(x)
x = self.backbone.relu(x)
x = self.backbone.maxpool(x)
x = self.backbone.layer1(x)
x = self.backbone.layer2(x)
x = self.backbone.layer3(x)
x = self.backbone.layer4(x)
# convert from 2048 to 256 feature planes for the transformer
h = self.conv(x)
# construct positional encodings
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# propagate through the transformer
h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1)).transpose(0, 1)
# finally project transformer outputs to class labels and bounding boxes
return {'pred_logits': self.linear_class(h),
'pred_boxes': self.linear_bbox(h).sigmoid()}
-
输入图片,经过预处理:(1,3,800,1066)
-
输入resnet50(去掉全连接层):(1,2048,25,34)
-
经过1*1卷积进行降维,获得transformer的词嵌入向量维度256,此时的特征图为(256,25,34)
-
利用学习到的row_embed与col_embed两个position embeding向量维度均为(50,128),128为0.5*dim,行列编码的第一个维度都是50,代表这里默认backbone的输出的特征图尺寸不超过50*50根据1*1卷积的输出H与W,切分row_embed与col_embed。
-
获得row_embed:(25,128) col_embed(34,128),分别复制相应维度到(25,34,128),concat得到position_embed (25,34,256)。
-
展开position_embed,得到 (850,256)维,把position_embed的850个地址编码向量按顺序平展,相当于850个单词的位置编码,每个单词的词嵌入向量维度或者说地址编码维度为256维,前128维是x方向的,后128维是y方向的。
-
将1*1卷积的特征图原本C*H*W的编码改为H*W*C的编码,再将二维特征图展开,得到850个像素点的平展,如上所说,850个像素点相当于850个单词,每个单词都用256维的向量表示为词嵌入向量。
-
将词嵌入向量与position_embed相加(这里实际上给了词嵌入向量0.1的权重),得到包含了位置信息的词嵌入向量。
-
在本网络中给定的输出框的个数为100个:query_pos==100,每个框的编码向量维数为256与词嵌入向量维数相同。
-
将‘8’中得到了词嵌入向量与训练好的object queries直接输入到pytorch的nn.transformer网络中。
-
transformer的输出(100,1,256),转置为(1,100,256)。
-
将transformer的输出分别输入到FFN,这里的FFN就是两个一维卷积,分别进行类别的回归和边界框。
-
通过以下两个函数,进行边界框编码的调整:
# for output bounding box post-processing def box_cxcywh_to_xyxy(x): x_c, y_c, w, h = x.unbind(1) b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)] return torch.stack(b, dim=1) def rescale_bboxes(out_bbox, size): img_w, img_h = size b = box_cxcywh_to_xyxy(out_bbox) b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32) return b
细节补充
FFNSs
最终预测是由具有ReLU激活功能且具有隐藏层的3层感知器和线性层计算的。 FFN预测框的标准化中心坐标,高度和宽度, 输入图像,然后线性层使用softmax函数预测类标签。 由于我们预测了一组固定大小的N个边界框,其中N通常比图像中感兴趣的对象的实际数量大得多,因此使用了一个额外的特殊类标签∅来表示在未检测到任何对象。 此类在标准对象检测方法中与“背景”类具有相似的作用。