PyTorch实现MNIST手写数字识别/LeNet/tensorboard绘制loss曲线
文章目录
- 0 MNIST是什么?
- 1 环境搭建与超参数设置
- 2 下载数据集
- 3 装载数据集并可视化
-
- 3.1 查看训练数据的构成
- 3.2 可视化部分训练数据
- 4 构建LeNet网络
-
- 4.1 什么是LeNet?
- 4.2 使用torch.nn搭建LeNet
- 5 初始化网络参数并选择优化器
- 6 开始训练并保存模型
- 7 开始测试并加载权重预测
- 8 使用Tensorboard绘制loss曲线
- 完整代码见下方链接
0 MNIST是什么?
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集

MNIST可以算是深度学习中的Hello World了,几乎每个初学者都会先从MNIST数据集入手,来训练自己的第一个基于CNN的分类器
1 环境搭建与超参数设置
本文将使用PyTorch1.7来训练LeNet网络来对手写数字进行分类
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader as dataloader
# 超参数
path_model = "./model/model.pkl"
batch_size = 64
epochs = 50
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
sampler = torch.utils.data.SubsetRandomSampler(indices=list(range(500)))
2 下载数据集
torchvision中的datasets模块中已经包含了MNIST数据集,调用即可
# 下载MNIST数据集
data_train = torchvision.datasets.MNIST(root='./data/',train=True,download=True,transform=transform)
data_test = torchvision.datasets.MNIST(root='./data/',train=False,download=True,transform=transform)
![]()
参数说明:
- root(string):MNIST数据存放的位置’./data/’
- train(bool,optional):如果为True则作为训练集,否则作为测试集
- download(bool,optional):如果为True,从网上把这个数据集下载下来并放到root指定的位置,如果下过了就不会重复下载
- transform(callable,oprtional):接受一个PIL图像并返回转换后的版本,对数据集中的图片进行相应的操作
需要注意的是,我们下载下来的MNIST数据集的格式是PIL文件,而送入CNN中进行训练的都是Tensor格式的数据,所以先要对数据集中的图片进行transform成Tensor类型的数据
# 没有对数据集进行Transform,可以发现dataset是PIL格式的文件
In:data_train[0]
Out: (<PIL.Image.Image image mode=L size=28x28 at 0x124B4EAD0>, 5)
# 设置Transform之后,返回的是一个元组形式的数据,其中
# [0]是tensor格式的图片,[1]是图片的真实值,即Label
In: data_train[0]
Out: (tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
....
0.0000, 0.0000, 0.0000, 0.0000]]]),
5)
3 装载数据集并可视化
torch.utils.data中的Dataloader(注意这个D是大写)模块可以很方便的将dataset装载起来,相当于一个数据读取器,方便对数据集进行处理
# 装载数据集
data_train = dataloader(dataset=data_train,batch_size=batch_size,shuffle=True)
data_test = dataloader(dataset=data_test,batch_size=batch_size,shuffle=True)
参数说明:
-
dataset :准备放进去的数据集
-
batch_size (int, optional) : 每一批装载多少个样本 (default: 1).根据内存和显存大小来定
-
shuffle (bool, optional) :set to True to have the data reshuffled at every epoch (default: False). 是否打乱
-
sample(Sampler or Iterable, optional) : defines the strategy to draw samples from the dataset. Can be any Iterable with len implemented. If specified, shuffle must not be specified. 与shuffle相冲突
我们可以设置sample参数,在一个epoch中仅对指定的样本量进行处理
sampler = torch.utils.data.SubsetRandomSampler(indices=list(range(100)))
3.1 查看训练数据的构成
使用enumerate函数将data_train转换成iterable的数据,方便对数据的读取
examples = enumerate(data_train)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape)
tensor([4, 7, 0, 8]) # 每一个batch中的样本label值
torch.Size([4, 1, 28, 28])# 每一次iter读取到的数据size,第一维为batch_size。
3.2 可视化部分训练数据
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()

4 构建LeNet网络
4.1 什么是LeNet?
LeNet-5是Yann LeCun等人在多次研究后提出的最终卷积神经网络结构,一般LeNet即指代LeNet-5,诞生于1994年
1989年,Yann LeCun等人在美国邮政服务提供的手写邮政编码数字数据集上,首次采用BP算法训练他们提出的LeNet网络,并且分类精度达到到了99%
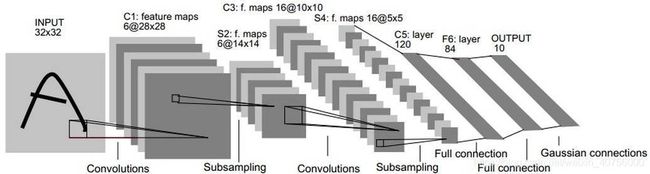
[图片及描述来源:LeCun, Y.; Bottou, L.; Bengio, Y. & Haffner, P. (1998). Gradient-based learning applied to document recognition.Proceedings of the IEEE. 86(11): 2278 - 2324.]
4.2 使用torch.nn搭建LeNet
因为论文中提出的手写数字数据集的图片size为32*32,而MNIST中的图片size为28*28,所以在原LeNet的基础上,我们需要先对图片进行padding。
在Conv1中设置padding=2,即可对输入图片进行扩充,在kernel_size=5的情况下匹配上维度
# 构建网络
class LeNet(nn.Module): # 继承于nn.Module这个父类
def __init__(self): # 初始化网络结构
super(LeNet, self).__init__() # 多继承需用到super函数
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2), # 输出为6*28*28
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出为6*14*14
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1), # 输出为16*10*10
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出为16*5*5
)
self.block_2 = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10),
)
def forward(self, x): # 正向传播过程
x = self.block_1(x)
x = x.view(-1,16*5*5)
x = self.block_2(x)
return x
对LeNet实例化后,再次输入对象可打印出net的层参数信息
net = LeNet()
net
Out:
LeNet(
(block_1): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block_2): Sequential(
(0): Linear(in_features=400, out_features=120, bias=True)
(1): Linear(in_features=120, out_features=84, bias=True)
(2): Linear(in_features=84, out_features=10, bias=True)
)
5 初始化网络参数并选择优化器
model = LeNet() # 实例化LeNet
data_input = Variable(torch.randn(16,1,28,28)) # 随机初始化网络参数
print(data_input.size())
net(data_input)
print(summary(net,(1,28,28)))
cost_fun = nn.CrossEntropyLoss() # 选择交叉熵作为损失函数
optimizer = torch.optim.SGD(net.parameters(),lr=1e-3) # 选择SGD作为优化器
OUT:
torch.Size([16, 1, 28, 28])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 156
ReLU-2 [-1, 6, 28, 28] 0
MaxPool2d-3 [-1, 6, 14, 14] 0
Conv2d-4 [-1, 16, 10, 10] 2,416
ReLU-5 [-1, 16, 10, 10] 0
MaxPool2d-6 [-1, 16, 5, 5] 0
Linear-7 [-1, 120] 48,120
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 10] 850
================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
----------------------------------------------------------------
None
6 开始训练并保存模型
参数说明:
- batch_idx:第几组送入网络训练中的数据,计算方法:训练集总数据个数/batch_size,向上取整
- data:送入网络中训练的tensor
- target:对应数据的label
def train():
# 读取dataloader中的数据,data是tensor变量,target是真实label
for batch_idx, (data, target) in enumerate(data_train):
# 清除grad累积值
optimizer.zero_grad()
# forward之后得到预测值
output = net(data)
# 计算loss
loss = cost_fun(output, target) # FP得到的预测值与真实值送入损失函数中
# backward
loss.backward()
# 收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数
optimizer.step()
# 给出loss和acc
train_loss.append(loss)
_, pred = torch.max(output.data, 1) # 根据softmax给出的概率值,选择最大的值作为预测值
correct_num = torch.sum(pred == target).item() # 预测值和真实值做比较,对预测准确的个数求和
print("Train Epoch:{}[{}/{} ({:.0f}%)]\t Loss:{:.6f} acc:{:.2f}".format(epoch, batch_idx * batch_size,
len(data_train.dataset),100. * batch_size * batch_idx / len(data_train.dataset), loss.item(),correct_num / batch_size))
# 只保存网络中训练好的权重文件
def save_state():
print('===> Saving models...')
state = {
'state': net.state_dict(),
'epoch': epoch # 将epoch一并保存
}
if not os.path.isdir('checkpoint'): # 如果没有这个目录就创建一个
os.mkdir('./checkpoint')
torch.save(state, path_model + 'Epoch:' + str(epoch) + ' Loss:' +
str(train_loss[-1].item()) + '.pth')
7 开始测试并加载权重预测
test部分和train很相似,但是不需要进行反向传播更新梯度,所以需要在进行FP之前,要加上with torch.no_grad():
def test():
net.eval() # 切换到测试模式
test_correct_num = 0
with torch.no_grad(): # 不更新参数
for batch_idx,(data,target) in enumerate(data_test):
output = net(data) # 正向传播得到预测值
_, pred = torch.max(output.data, 1)
test_correct_num += torch.sum(pred==target).item()
print("Test Epoch:{} [{}/{} ({:.0f}%)]\t acc:{:.2f}".format(epoch,batch_idx*batch_size,len(data_test.dataset),
100. * batch_size*batch_idx/len(data_test.dataset),test_correct_num/len(data_test.dataset)))
def predict():
state_path = './checkpoint/***' # ***为指定加载的权重文件名称
print('===> Loading weights : ' + state_path)
torch.load(state_path) # 加载最后训练出的权重
# 从测试集中选取一个batch做预测
pred_test = enumerate(data_test)
batch_idx, (pred_data, pred_gt) = next(pred_test)
output = net(pred_data)
_, pred = torch.max(output.data, 1) # 得到预测值
print("ground truth: ",pred_gt)
print("predict value: ",pred)
8 使用Tensorboard绘制loss曲线
- writer = SummaryWriter(log_dir=‘logs’)在工程目录下生成logs文件
- writer.add_scalar(‘Train_loss’, loss, (epoch)) 每训练完一次epoch,记录一次loss的值
- writer.close() 训练结束后,关闭
- 在terminal内输入
tensorboard --logdir=D:\Study\Collection\Tensorboard-pytorch\logs再打开返回的网址即可
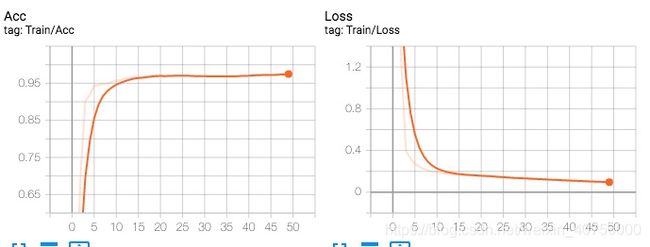
完整代码见下方链接
可用GPU进行训练
https://github.com/nin-yu/MNIST-with-PyTorch