【论文笔记_目标检测_2022】DaViT: Dual Attention Vision Transformers

摘要
在这项工作中,我们介绍了双注意视觉变换器(DaViT),这是一个简单而有效的视觉变换器架构,能够在保持计算效率的同时捕捉全局环境。我们建议从一个正交的角度来处理这个问题:利用 "空间标记 "和 "通道标记 "的自我注意机制。对于空间标记,空间维度定义了标记的范围,而通道维度定义了标记的特征维度。对于通道标记,我们有相反的情况:通道维度定义了标记的范围,而空间维度定义了标记的特征维度。我们进一步沿序列方向对空间和通道令牌进行分组,以保持整个模型的线性复杂性。我们表明,这两个self-attention是相互补充的。(i)由于每个通道标记包含整个图特征,通道注意力通过在计算通道之间的注意力分数时考虑到所有的空间位置,自然地捕捉到全局的联系和特征;(ii)空间注意力通过进行跨空间位置的细粒度的联系来完善局部特征,这反过来有助于通道注意力的全局信息建模。广泛的实验表明,我们的DaViT在四个不同的任务上以高效的计算实现了最先进的性能。在没有额外数据的情况下,DaViT-Tiny、DaViT-Small和DaViT-Base在ImageNet-1K上分别以2830万、4970万和8790万的参数达到了82.8%、84.2%和84.6%的最高精度。当我们用15亿个弱监督图像和文本对进一步扩大DaViT的规模时,DaViT-Gaint在ImageNet-1K上达到了90.4%的最高精度。
代码地址:https://github.com/dingmyu/davit
1.介绍
全局背景对于许多计算机视觉方法来说是至关重要的,例如图像分类和语义分割。卷积神经网络(CNN)[41]通过多层架构和下采样运算器逐渐获得了全局感受野。最近,(vision transformers)视觉变换器[7,18]引起了很多人的注意,它通过一个自我注意层直接捕捉长距离的视觉依赖性。虽然这些方法具有很强的全局建模能力,但其计算复杂度随着标记长度的增加而呈四次方增长,限制了其扩展到高分辨率场景的能力。
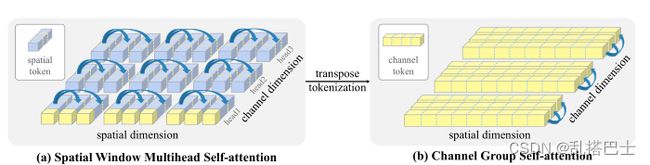
图1. (a) 空间窗口多头自注意力将空间维度分割成局部窗口,每个窗口包含多个空间标记物。每个标记也被分为多个头。(b) 通道组单头自我注意将通道标记(token)分成多组。注意力在每个通道组中进行,以整个图像级别的通道作为一个标记。在(a)中还强调了一个捕捉全局信息的通道级token。在这项工作中,我们交替使用这两种类型的注意力来获得局部细粒度和全局特征。
设计一个能够捕捉全局背景的架构,同时保持从高分辨率输入中学习的效率,仍然是一个开放的研究问题。iGPT[7]首先利用一个标准的变换器来解决视觉任务,将图像视为像素序列并进行像素级的互动。之后,ViT[18]将非重叠的图像patches作为tokens来模拟小的图像patches之间的关系,而不是像素,在中等分辨率的任务(如分类)上显示出预期的性能。为了进一步降低计算成本,人们提出了局部注意[40,82,58]和压缩投影[65,62],前者将注意力限制在一个空间上的局部窗口,后者则在下采样的标记上执行注意力。尽管局部注意方法得益于空间大小的线性复杂度,但像 “Shift”[40]、“Overlapping patch”[65,62]、“ConvFFN”[62,79,68]这样的操作对于补偿全局背景信息的损失是必不可少的。
所有先前的工作的一般模式是,他们在分辨率、全局背景和计算复杂性之间实现了不同的权衡:像素级[7]和patch级[18,40,65,63]的自我关注要么遭受二次计算开销的代价,要么失去全局背景信息。除了像素级和patch级的自我注意力的变化之外,我们能否设计一种图像级的自我关注机制,来捕捉全局信息,但在空间大小方面仍然有效?
在这项工作中,我们引入了这样一种自我注意力机制,它能够在保持计算效率的同时捕捉全局背景。除了图1(a)中由现有工作定义的代表图像patch特征的 "空间标记 "外,我们通过对标记矩阵的转置应用自我注意来引入 “通道标记”,如图1(b)所示。在通道标记中,通道维度定义了标记的范围,空间维度定义了标记的特征维度。这样,每个通道标记在空间维度上是全局的,包含整个图像的抽象表示。相应地,在计算通道间的注意分数时,通过考虑所有的空间位置,对这种通道标记进行自我注意,可以进一步捕捉到全局的联系。与传统的自我注意以二次计算成本对局部像素或patch tokens进行全局交互相比,通道自我注意的信息交换是自然地从全局角度而不是从像素/patch角度施加的。基于通道token的全局感受野,它融合表征以产生新的全局token,并将信息传递给以下各层。因此,人们可以把这种通道自我注意看作是对整个图像的一系列抽象表征的动态特征融合。
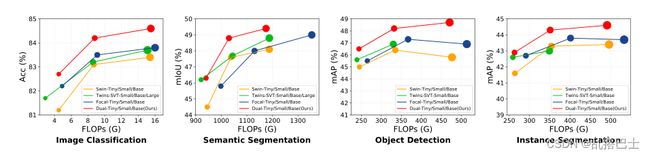
图2. 所提出的方法与现有的SoTA方法[40,72,10]在四个计算机视觉任务上的效率(即FLOPs)和性能(例如,Acc,mIoU,mAP)的比较。每种方法用一个圆圈表示,其大小代表参数的数量。在所有四个基准上,我们的方法在相似的FLOPs下取得了比同类方法更优越的性能。
虽然这种方法有很多优点,但必须克服一些挑战。首先,计算复杂度会随着通道维度的增加而突然增加,从而限制了各层的表示能力。受空间局部注意的启发[40,82,58],我们提出了通道组注意,将特征通道分为若干组,并在每组中进行图像级的交互。通过分组注意,我们将空间和通道两个维度的复杂性降低到线性。由于每个通道标记包含了整个图像的抽象表示,在这种情况下,自我注意自然而然地捕捉到了全局的互动,即使我们沿着通道维度局部应用它。
其次,尽管通道式的自我注意可以很容易地捕捉到全局信息,但图像级的标记会阻碍跨空间位置的局部互动。为了解决这个问题,我们引入了双注意视觉变换器(DaViT),交替应用空间窗注意和通道组注意来捕捉短距离和长距离的视觉依赖,如图1所示。我们的研究结果表明,这两种结构相辅相成:通道组注意提供了空间维度上的全局感受野,并通过跨全局通道标记的动态特征融合来提取高层次的全局图像表征;空间窗注意通过跨空间位置进行细粒度的局部交互来完善局部表征,这反过来又有助于通道注意中的全局信息建模。
总而言之,我们提出的DaViT包含两种无缝集成的自我注意:带有 "空间标记 "的空间窗口自我注意和带有 "通道标记 "的通道组自我注意。这两种形式的注意是互补和交替安排的,以计算效率高的方式提供局部细粒度和全局互动。我们通过对图像分类、物体检测和分割的综合经验研究来评估所提出的DaViT的有效性。图2中的结果显示,DaViT在三个基准和四个任务中的表现一直优于SoTA视觉变换器,而且计算成本更低。
2.相关工作
视觉变换器和MLPs。变换器[59,15]已经主导了广泛的自然语言处理任务。在计算机视觉中,开创性的工作iGPT[7]和ViT[18]将注意力直接应用于图像像素或patch的序列。同样,后续工作[25,55,63,51,66,20,80,46,47]对patch级标记的全局关系进行建模。所有这些工作都应用注意力来捕捉所有局部标记的相互作用,这些标记可以是像素级或patch级的。在这项工作中,我们从一个正交的角度对全局关系进行建模,并将注意力机制应用于空间标记以及它们的转置,我们称之为图像级(全局)通道标记。通过这种方式,我们既能捕捉到细粒度的结构模式,又能捕捉到全局的互动。
最近,基于MLP的模型[53,54,39,74,8,35,27]通过直接使用多层感知器(MLP)在patch特征上引起了人们的注意。MLP-Mixer[53]通过在空间位置或特征通道上重复应用MLP,充分利用了特征转置。然而,它既没有采用变换器架构,也没有采用自注意力层,而且只适用于图像分类任务。我们的工作重点是基于变换器的架构,以有利于各种任务,如分类、目标检测和分割。
层次化的视觉变压器。分层设计被广泛用于视觉中的变换器[40,63,65,16,82,58,43,76,34,1,32,84,52,58,9,31,73,29,71,33,85] 。PVT[63]和CvT[65]对挤压后的标记进行关注,以降低计算成本。Swin Transformer[40]、ViL[82]和HaloNet[58]将局部窗口注意应用于贴片标记,这些标记捕捉了细粒度的特征,并将二次复杂度降低为线性,但失去了全局建模的能力。为了弥补全局背景的损失,Swin Transformer[40]在连续区块之间交替地对移位的局部窗口进行关注,ViL[82]和HaloNet[58]对重叠的窗口进行发挥。
在这项工作中,所提出的方法分享了分层结构和细粒度的局部注意的优点,同时我们提出的组通道注意仍然有效地模拟了全局背景。
channel-wise注意力。[28]的作者首先提出了一个Squeeze-andExcitation(SE)块作为信道明智的注意,通过挤压的全局特征来重新校准信道的特征。与我们的工作相关的CNN中的其他操作是Dynamic Head[12]和DANet[19]。他们在CNN主干上沿着不同的特征维度应用注意力来完成特定的任务。一些转化器的架构也涉及到通道的操作,以减少计算成本。LambdaNetworks[2]首先将上下文转换为线性函数lambda,然后应用于相应的查询。XCiT[1]提出了交叉协方差注意(XCA),用于高效处理高分辨率图像。类似地,CoaT[70]引入了一个因子化的注意力机制,在多分支转化器骨架中有效地工作。

图3. 我们的双注意块的模型结构。它包含两个转换块:空间窗自我注意和通道组自我注意块。通过交替使用这两种类型的注意力,我们的模型享有捕捉局部细粒度和全局图像级的互动的好处。
我们的工作提出了通道组注意来捕捉变压器(transformers)中的全局信息。尽管它在通道和空间维度上都只有线性复杂度,但当它与空间窗口注意相结合时,我们展示了它的力量,形成了我们的双重注意机制。此外,我们详细分析了我们的双重注意是如何获得全局交互以及细粒度的局部特征的,显示了它对各种任务的有效性,如分类、异议检测和分割。
3.方法
我们提出了双注意视觉变换器(DaViT),这是一个干净、高效而又有效的变换器骨干,包含了局部细粒度的特征和全局表征。在本节中,我们首先介绍了我们模型的分层布局。然后我们详细介绍了我们的通道组注意以及与空间窗注意的结合[40]。
3.1概述
我们将模型分为四个阶段,在每个阶段的开始都插入了一个patch嵌入层。我们在每个阶段堆叠我们的双重注意块,分辨率和特征维度保持不变。图3(a)说明了我们的双注意块的结构,由一个空间窗注意块和一个通道组注意块组成。
前期准备。让我们假设一个RP×C维的视觉特征,其中P是总patch的数量,C是总通道的数量。简单地应用标准的全局自我注意会导致O(2P2C + 4PC2)的复杂性。它被定义为: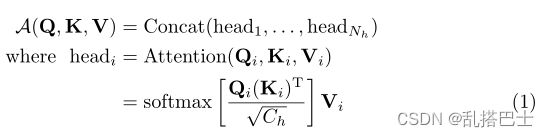
其中![]() 是RP×Ch维度的视觉特征,有Nh个头,Xi表示输入特征的第i个头,Wi表示Q、K、V的第i个头的投影权重,C = Ch ∗Nh。请注意,这里省略了输出投影WO。考虑到P可以非常大,例如128×128,计算成本是不高的。
是RP×Ch维度的视觉特征,有Nh个头,Xi表示输入特征的第i个头,Wi表示Q、K、V的第i个头的投影权重,C = Ch ∗Nh。请注意,这里省略了输出投影WO。考虑到P可以非常大,例如128×128,计算成本是不高的。
在DaViT中,我们交替安排了空间窗注意和通道组注意,以获得局部和全局特征,但对空间维度的复杂性是线性的,如图3所示。
3.2空间窗注意力
窗口注意力计算局部窗口内的自我注意力,如图1(a)所示。窗口的安排是为了以非重叠的方式均匀地划分图像。假设有Nw个不同的窗口,每个窗口包含Pw个patch,其中P = Pw ∗ Nw。那么窗口的注意力可以用以下方式表示:
![]()
其中Qi、Ki、Vi∈RPw×Ch是局部窗口的查询、键和值。基于窗口的自我关注的计算复杂度为O(2P PwC+4P C2),复杂度与空间大小P呈线性关系。图3(b)中显示了窗口关注的更多细节。虽然计算量减少了,但窗口注意失去了对全局信息建模的能力。我们将表明,我们提出的通道注意自然地解决了这个问题,并与窗口注意相互受益。
3.3通道群注意力
我们从另一个角度考察自我关注,并提出了通道式关注,如图3(c)所示。以前的视觉中的自我注意[59,40,65,58,81,7]用像素或patch定义标记,并沿着空间维度收集信息。我们没有在像素级或patch级上执行注意,而是在patch级标记的转置上应用注意机制。为了获得空间维度上的全局信息,我们把头的数量设为1。我们认为,每个转置的标记都是对全局信息的抽象。
以这种方式,信道token与信道维度上的全局信息以线性空间上的复杂性进行交互,如图1(b)所示。
简单地转置特征可以得到一个虚无的通道级注意力,其复杂度为O(6P C2)。为了进一步降低计算复杂度,我们将通道分成多个组,并在每个组内进行自我关注。形式上,让Ng表示组的数量,Cg表示每组中通道的数量,我们有C = Ng ∗ Cg。这样,我们的频道组注意力是全局性的,图像级别的标记在一组频道中互动。它被定义为:
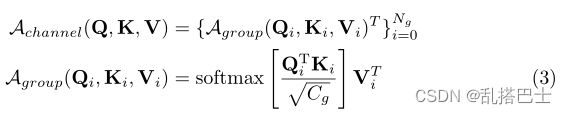
其中Qi、Ki、Vi∈RP×Cg是分组的通道级图像查询、键和值。请注意,尽管我们在通道关注中转置了标记,但投影层W和缩放系数1/√Cg仍然沿通道维度执行和计算,而非空间维度。考虑到空间斑块的数量随图像大小的变化而变化,上述设计确保我们的模型可以推广到任何图像大小。
复杂度分析。我们的通道组注意是在通道维度上的图像级标记上进行的。与产生大小为Pw×Pw的注意图的窗口注意相比,通道方面的注意图是Cg×Cg维的。我们模型的整体计算复杂度包括窗和通道注意的O(2P C(Pw + Cg)),线性投影的O(8P C2),以及FFN的O(16P C2)(扩展比为4)。可以看出,我们的双重关注在计算上是高效的,对空间和通道维度都有线性复杂度。FFN在FLOPs的数量和模型参数方面占优势。考虑到我们的双重注意同时具有通道维和空间维的相互作用,在这项工作中,我们进行了初步探索,以显示没有FFN的纯注意结构的潜力。详情可参见附录。
通道注意中的全局交互作用。通道注意自然地捕捉了视觉识别任务的全局信息和相互作用。(i) 转置特征后,每个通道标记本身在空间维度上是全局的,提供了图像的全局视图。(ii) 给定维度为P的Cg标记,通过涉及所有空间位置,即(Cg×P)-(P×Cg),计算出Cg×Cg维度的注意图。(iii) 有了这样的全局注意图,通道注意动态地融合了图像的多个全局视图,产生新的全局标记,并将信息传递给下面的spatial-wise层。与在不同空间位置进行交互的spatial-wise的全局注意[55,18]相比,我们的通道自我注意的信息交换是从全局角度而不是patch角度强加的,补充了空间窗口注意力。详细的分析可以在第4节找到。

图4. 说明通道注意力是如何通过可视化参加的特征图来收集全局信息的。第一列和第二列表示原始图像和我们的通道注意后的特征通道;而其他列是在注意前具有最高7个注意分数的通道标记。通道关注能够选择全局性的重要区域,并抑制背景区域以获得更好的识别。分类模型的第三个网络阶段是用于可视化的。
3.4模型实例化
在这项工作中,我们遵循以前的工作[40,72]所建议的设计策略。以一张H×W的图像为例,在第一个patch嵌入层之后,得到一个分辨率为H/4×W/4的C维特征。其分辨率进一步降低为H/8×W/8,H/16×W/16,H/32×W/32,在其他三个补丁(patch)嵌入层后,特征维度分别增加到2C,4C和8C。这里,我们的补丁嵌入层是通过跨度卷积实现的。我们的四个补丁嵌入层的卷积核和跨度值分别为{7,2,2,2}和{4,2,2}。
我们考虑三种不同的网络配置,用于图像分类、目标检测和分割:
- DaViT-Tiny。C = 96, L = {1, 1, 3, 1}, Ng = Nh = {3, 6, 12, 24}。
- DaViT-Small:C=96,L={1,1,9,1},Ng=Nh={3,6,12,24}。
- DaViT-BASE: C = 128, L = {1, 1, 9, 1}, Ng = Nh = {4, 8, 16, 32},
其中L是层数,Ng是通道注意中的组数,Nh是每个阶段的窗口注意中的头数。
当涉及到更多的训练数据时,我们进一步将DaViT扩展到大的、巨大的和巨型的规模,以验证所提出的架构对图像分类的扩展能力:
– DaViT-Large: C = 192, L = {1, 1, 9, 1}, Ng = Nh = {6, 12, 24, 48}
– DaViT-Huge: C = 256, L = {1, 1, 9, 1}, Ng = Nh = {8, 16, 32, 64}
– DaViT-Giant: C = 384, L = {1, 1, 12, 3}, Ng = Nh = {12, 24, 48, 96}.
更多细节和模型设置可以参见附录。
4.分析
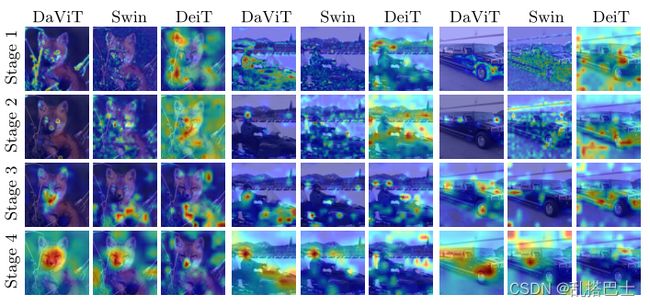
图5. 我们的DaViT、Swin[40]和DeiT[55]在四个不同网络阶段的特征图可视化(从上到下代表第1到4阶段)。DeiT[55]按2、2、6、2层分别分为四个阶段。对于所有的网络阶段,一个随机的特征通道是可视化的。
全局相互作用的解释。变换器中的全局交互可以归纳为不同的类型。传统的ViT[18]和DeiT[55]在整个图像中的不同patch之间进行信息交换;Focal Transformer[72]提出不同尺度的标记之间的互动,以获得更大的感受野;PVT[62]利用空间还原机制来获得全局注意的粗略近似;Swin[40]将多个分层堆叠,最终获得全局信息。与他们不同的是,具有我们通道注意力的单个区块能够从另一个角度学习全局的相互作用,在计算注意力分数时考虑到所有的空间位置,如(Cg×P)-(P×Cg)。它捕捉了来自多个全局标记的信息,这些标记代表了整个图像的不同抽象视图。例如,不同的通道可能包含来自物体不同部分的信息;这种部分信息可以被汇总到一个全局视图。
图4通过可视化关注前后的特征图来说明我们的通道关注是如何工作的。对于第一列中的每张图片,我们在网络的第三阶段随机选择一个输出通道(第二列)和其对应的前7个相关输入通道进行可视化。我们可以看到,通道注意力融合了多个标记的信息,选择了全局重要的区域,并抑制了不重要的区域。
与Swin和DeiT的关系。为了显示我们的双重自我关注的有效性,我们与两个有代表性的基线进行了详细比较。Swin[40]使用细粒度的局部特征,而DeiT[55]使用全局粗粒度的特征。请注意,尽管我们的工作和Swin都使用窗口注意力作为网络元素,但Swin的关键设计,即在连续的层之间使用 "移位的窗口分区 “来增加感受野,在我们的工作中没有使用。我们还简化了它的相对位置编码[11],在layer norm之前进行深度卷积,以获得一个更干净的结构,用于任意的输入大小。为了进一步保持我们结构的简洁和高效,我们不使用额外的操作比如"Overlappping patch重叠补丁”[65,62] 和 “ConvFFN” [79,68]。关于我们的模型与Swin的详细吞吐量比较,见附录。
表1:不同模型在ImageNet-1K上的图像分类比较。除非另有说明,所有模型都在ImageNet-1K上以224×224的分辨率进行默认训练和评估。为了公平比较,所有模型及其对应的模型都没有使用标记[30]和蒸馏[55]。†和‡表示模型分别以384×384和512×512的分辨率进行评估。

图5显示了我们的通道组注意力的有效性。我们在DaViT、Swin[40]和DeiT[55]的每个阶段随机地将一个特征通道可视化。我们观察到。(i) Swin在前两个阶段捕捉到了细微的细节,但没有焦点,因为它缺乏全局信息。直到最后一个阶段,它都不能集中在主要对象上。(ii) DeiT在图像上学习了粗粒度的全局特征,但失去了细节,因此难以集中在主要内容上。(iii) 我们的DaViT通过结合两种类型的自我注意来捕捉短距离和长距离的视觉依赖。它显示了强大的全局建模能力,在第一阶段找出主要内容的细微细节,并在第二阶段进一步关注一些关键点。然后,它从全局和局部的角度逐步细化感兴趣的区域,以实现最终的识别。
与CNN中的channel-wise 注意力的关系。传统的channel-wise 的注意块,例如SENet[28]和ECANet[61],通过通道间的全局平均特征对特征图进行自适应的重配。相比之下,我们的通道组自关注在变换器中执行跨全局标记(整个图像的不同全局视图)的动态特征融合。这样一来,我们的通道组自我关注就更加强大。我们通过用SE[28]和ECA[61]块替换我们微小模型中的通道自留地来进行定量比较。详细结果见附录。
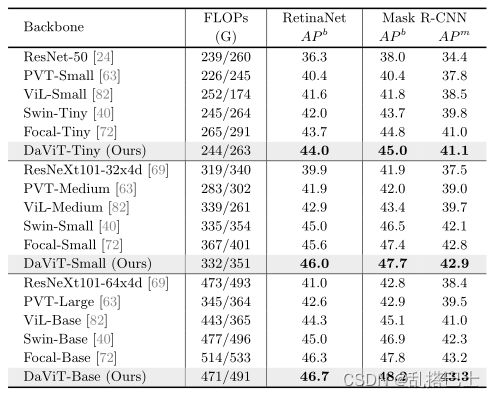
表2. 与CNN和Transformer基线以及SoTA方法在COCO物体检测方面的比较。报告了RetinaNet和Mask R-CNN的箱体mAP(AP b)和掩膜mAP(AP m),RetinaNet和Mask R-CNN是按照1×计划训练的。FLOPs按800×1280测量。更详细的与3×时间表的比较见表5。
5.实验
我们在ImageNet-1K图像分类[14]、COCO物体检测[38]和ADE20K语义分割[83]上进行了实验。在所有的实验和比较中都没有使用标记[30]和蒸馏[55]。
5.1图像分类
我们在ImageNet-1K[14]上比较了不同的方法。我们在timm框架[64]上实现我们的DaViT。按照[40,37,65,82],在排除重复增强[3,26]和指数移动平均(EMA)[44]后,我们使用了[55]中使用的同一套数据增强和正则化策略。我们对所有模型进行了300个历时的训练,批次大小为2048,并使用AdamW[42]作为优化器。权重衰减被设置为0.05,最大梯度规范被剪切为1.0。我们使用一个简单的三角形学习率时间表[49],如[57]。随机深度下降率被设置为0.1、0.2和0.4,分别用于我们的tiny,small和bese 模型。在训练过程中,我们将图像随机裁剪为224×224,而在验证集的评估过程中则使用中心裁剪。
在表1中,我们总结了基线模型和当前最先进的模型在图像分类任务上的结果。我们可以发现,我们的DaViT达到了新的最先进水平,并且在模型大小相似、计算量相似的情况下,一直优于其他方法。具体来说,DaViT-Tiny、Small和Base比Swin Transformer[40]分别提高了1.5%、1.1%和1.2%。值得注意的是,我们的DaViT-Small在49.7M的参数下达到了84.2%,超过了所有使用更少参数的对应-Base模型。例如,我们的DaViT-Small比Focal-Base和Swin-Base分别高0.4%和0.8%的准确率,计算量接近一半。
继[65,18,40]之后,当来自ImageNet-22k[14]的13M图像参与预训练时,DaViT-Base和DaViT-Large分别获得了86.9%和87.5%的最高精度。此外,当我们用1.5B私人收集的弱监督图像-文本对数据进一步扩大DaViT的规模,并用统一的对比学习[77]方法对DaViT进行预训练时,DaViT-Huge和DaViT-Gaint在ImageNet的362M和1.4B参数上分别达到90.2%和90.4%的最高准确率。
表3…
5.2…
6.结论
这项工作引入了双重注意机制,包含空间窗口注意和通道组注意,在保持计算效率的同时,捕捉全局背景。我们表明,这两种自我注意是相互补充的。(i)由于每个通道标记包含整个图像的抽象表征,通道注意通过在计算通道之间的注意分数时考虑所有的空间位置,自然地捕捉到全局的互动和表征;(ii)空间注意通过进行跨空间位置的细粒度互动来完善局部表征,这又有助于通道注意的全局信息建模。我们进一步形象地说明了我们的通道组注意是如何捕捉全局互动的,并在各种基准中证明了其有效性。