pytorch深度学习实战lesson5
目录
实践部分
数据操作
数据处理
课程网站:
04 数据操作 + 数据预处理【动手学深度学习v2】_哔哩哔哩_bilibili
第五课 数据操作
从本节课开始,我们将跟着李沐老师学习《动手学深度学习》

李沐老师
使用的架构是当今非常火热的pytorch架构,我们将从易到难学习这门课程,请你做好准备~
理论部分

当数据结构为矩阵时,每一行表示的是一个样本,每一列表示的是样本的特征。

访问元素:


上图中的“[1:3,1:]”表示的是取第一行到第3-1行且第一列之后的所有元素。
而“[::3,::2]”则表示:取从第零行开始每三行且从第零列开始每两列的元素。
实践部分
数据操作
首先导入torch,请注意,虽然架构名称是pytorch,但是我们导入的是torch而不是pytorch。
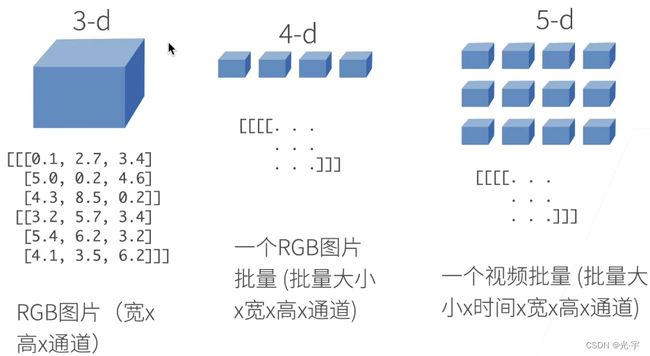
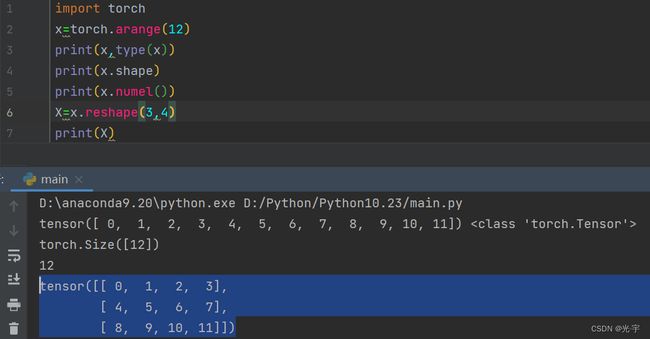
张量表示的是一个数值组成的数组,这个数组可能有多个维度,比如:

我们还可以使用张量的shape属性来访问张量的形状;使用numel访问张量中元素的总数。


要改变一个张量的形状而不改变元素数量和元素值,可以调用reshape()函数。
使用全0、全1、其他常量或者从特定分布中随机采样的数字。可以使用zeros和ones。

通过提供包含数值的Python列表来为所需张量中的每个元素赋予确定值。两层方括号表示是二维的,三个方括号就表示是三维的。
![]()

常见的标准算术符运算符(加减乘除)都可以被升级为按元素运算。


还有按指数运算的exp()函数

![]()
矩阵拼接,需要考虑好维度。


可以通过逻辑运算符构建二元张量:
![]()

也就是判断X1和Y1之间有几个元素一样。一样的置TRUE不一样的置FALSE。
这里有个好玩的机制,叫做广播机制,即使形状不同的两个向量或矩阵,当他们相加时会变得形状相同。这就是广播机制:

数据的访问:
X[-1]表示访问X的最后一行;
X[1:3]表示访问X的第一行和第二行;
X[1,2]=9表示把第一行第二列的元素赋值成9;
X[0:2,:]=12表示0至一行的所有列赋值成12;
这里要注意:对矩阵进行赋值操作时,可能会导致内存发生变化。
比如13,14,15行:
但是如17,18,19,20行所示当我进行原地操作时,也就是提前保存好内存地址后再进行加法操作,内存地址就不会变。
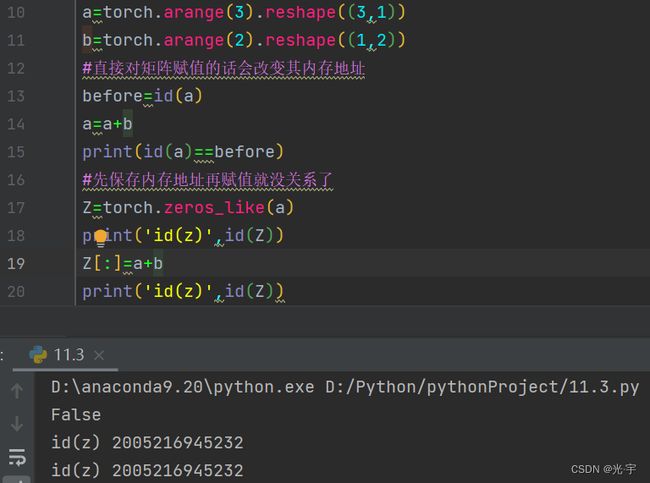
还有一种方法就是,如果后续计算中没有重复使用X,那我们也可以使用X[:]=X+Y或者X+=Y来减少内存的开销。

数据处理
创建一个人工数据集,并存储在csv(逗号分隔符)文件中。

从创建的csv文件中加载原始数据集,这里使用pandas

为了处理缺失的数据,典型的方法包括插值和删除,这里考虑插值,如14,15,16行;
对于inputs中的类别值或离散值,将NAN视为一个类别,如17,18行;
现在inputs和outputs中的所有条目都是数值类型,他可以转换为张量格式如最后几行。

