kaggle点赞最多的 泰坦尼克号数据竞赛模型融合方法(附代码)
听说很多大佬都是从kaggle上获取的知识, 加工整理成一套属于自己的竞赛体系
今年7月份我开始参加大数据竞赛, 现在差不多有10场比赛了, 都是结构化比赛. 小的比赛还能进Top名次, 大点的比赛就比较难了, 问题在于没有形成系统, 所以计划将kaggle结构化, 时序比赛中比较好的notebook进行简单翻译并整理, 总结有用的信息, 期望在以后的比赛中能有更好的成绩.
本文重点
以kaggle上泰坦尼克比赛数据为例, 介绍如何进行stacking模型融合, kaggle上点赞数超过5000, 原文链接: kaggle泰坦尼克
仔细研究后, 有以下思路可以借鉴:
特征工程
- 分类特征通过是否为缺失值归为2类, 也可填充为数量最多的类
- 数值特征年龄的缺失值填充方法
- 数值等距和等频离散化
- 文本的处理, 外国人姓名中有些信息
模型
- 创建了一个类SklearnHelper, 提高代码效率
- 第1层为5个基模型, 第2层为xgboost(也有文章用线型回归的)
- 第1层的每个基模型都使用k折交叉验证, 输出了train和test的预测值, 然后将数据拼接构造成新的train_new 和 test_new, 标签还是原来的标签
- 最后用新的数据训练第2层模型, 输出最终的预测值
# 导入工具包
import pandas as pd
import numpy as np
import re
import sklearn
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
# 5个基本模型
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
from sklearn.cross_validation import KFold
特征工程与处理
我们像大多数其他内核结构一样, 首先对手头的数据进行探索, 确定可能的特征工程, 以及文本特征数值化
# 导入训练数据和测试数据
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
# 存储乘客ID
PassengerId = test['PassengerId']
train.head(3)
毫无疑问, 我们将从分类特征中提取信息
特征工程
# 组合训练数据和测试数据
full_data = [train, test]
# 姓名长度
train['Name_length'] = train['Name'].apply(len)
test['Name_length'] = test['Name'].apply(len)
# 乘客在船上是否有客舱号
train['Has_Cabin'] = train["Cabin"].apply(lambda x: 0 if type(x) == float else 1)
test['Has_Cabin'] = test["Cabin"].apply(lambda x: 0 if type(x) == float else 1)
# 将SibSp和Parch特征组合
for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
# 是否一个人
for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
# 登船港口为空的填充为S类
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
# 票价缺失值填充为均值
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
# 票价按分位数离散化
train['CategoricalFare'] = pd.qcut(train['Fare'], 4)
# 年龄缺失值填充
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
# 年龄按分位数离散化
train['CategoricalAge'] = pd.cut(train['Age'], 5)
# 定义函数处理乘客姓名
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
# 创建新特征, 简称title
for dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
# 将不常见的归为1类, 其他替换
for dataset in full_data:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
for dataset in full_data:
# 性别数值编码
dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
# 将title数值编码
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
# 登船港口数值编码
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
# 票价离散化
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
# 年龄离散化
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ;
# 特征选择
drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp']
# 删除原来的文本特征
train = train.drop(drop_elements, axis = 1)
# 删除2个创建了但是不使用的特征(估计之前是查看分布用)
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1)
test = test.drop(drop_elements, axis = 1)
现在我们清洗并提取了相关的信息, 删除了文本列, 特征全部是数值列适合机器学习模型. 在我们继续之前, 我们先做一些简单的相关和分布图
可视化
train.head(3)
皮尔逊相关热图
生成一些特征的相关图,以查看一个特征与下一个特征的相关性。
colormap = plt.cm.RdBu
plt.figure(figsize=(14,12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(train.astype(float).corr(),linewidths=0.1,vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True)
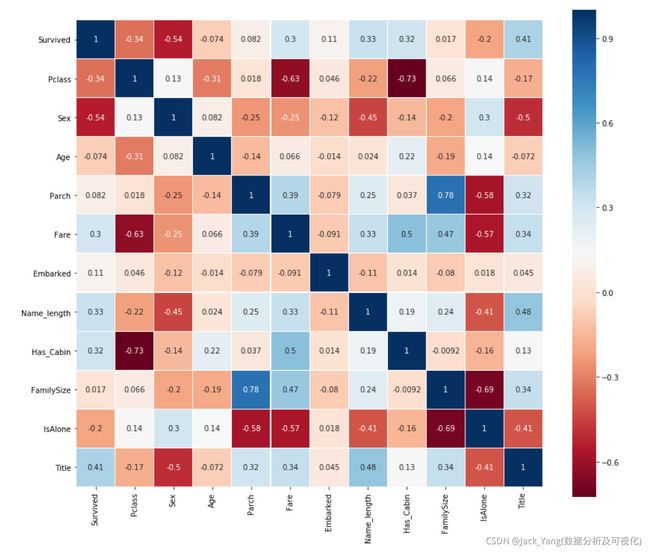
从图中获取信息
皮尔逊相关图可以告诉我们的一件事是,没有太多的特征彼此之间有着强烈的相关性。从将这些功能输入到学习模型的角度来看,这很好,因为这意味着我们的训练集中没有太多冗余或多余的数据,我们很高兴每个特征都带有一些独特的信息。这里有两个最相关的特征是家庭规模和Parch(父母和孩子)。出于本练习的目的,我仍将保留这两个特征。
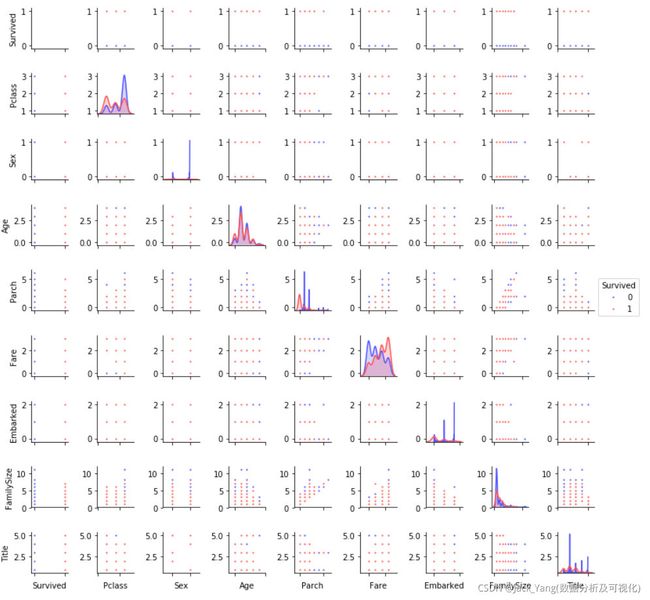
Pairplots
最后,让我们生成一些配对图来观察数据特征间的分布
g = sns.pairplot(train[[u'Survived', u'Pclass', u'Sex', u'Age', u'Parch', u'Fare', u'Embarked',
u'FamilySize', u'Title']], hue='Survived', palette = 'seismic',size=1.2,diag_kind = 'kde',diag_kws=dict(shade=True),plot_kws=dict(s=10) )
g.set(xticklabels=[])
集成并融合模型(stacking)
# 一些参数
ntrain = train.shape[0]
ntest = test.shape[0]
SEED = 0 # 复现用
NFOLDS = 5 #
kf = KFold(ntrain, n_folds= NFOLDS, random_state=SEED)
# 创建一个机器学习扩展类
class SklearnHelper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def train(self, x_train, y_train):
self.clf.fit(x_train, y_train)
def predict(self, x):
return self.clf.predict(x)
def fit(self,x,y):
return self.clf.fit(x,y)
def feature_importances(self,x,y):
print(self.clf.fit(x,y).feature_importances_)
# Class to extend XGboost classifer
对于那些已经知道这一点的人,请原谅我,但是对于那些以前没有在Python中创建类或对象的人,让我解释一下上面给出的代码是做什么的。在创建基本分类器时,我将只使用Sklearn库中已经存在的模型,因此只扩展该类。
def init : Python标准的调用类的默认构造函数。这意味着,当您想要创建一个对象(分类器)时,必须为其提供clf(您想要的sklearn分类器)、seed(随机种子)和params(分类器的参数)的参数。
其余的代码只是类的方法,它们只是调用sklearn分类器中已经存在的相应方法。本质上,我们创建了一个封装类来扩展各种Sklearn分类器,这样当我们实现多个学习器时,就可以减少反复编写相同代码的次数。
Out-of-Fold Predictions
现在,正如上面在介绍部分提到的,stacking使用基本分类器的预测作为第二级模型训练的输入。然而,不能简单地根据完整的训练数据训练基本模型,在完整的测试集上生成预测,然后输出这些预测用于第二级训练。这会导致您的基础模型预测已经“看到”了测试集,因此在输入这些预测时会出现过度拟合的风险。
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest))
for i, (train_index, test_index) in enumerate(kf):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.train(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
# 代码居然和书上89页很像, 原来很多都来自kaggle
生成第1层模型
现在让我们准备五个学习模型作为第一级分类。这些模型都可以通过Sklearn库方便地调用,如下所示:
- Random Forest classifier
- Extra Trees classifier
- AdaBoost classifer
- Gradient Boosting classifer
- Support Vector Machine
参数
为了完整起见,我们将在这里列出参数的简要摘要,
n_jobs : 训练过程中内核使用数. 如果设置成-1, 将使用所有
n_estimators : 学习模型中分类数的数量
max_depth : 树的最大深度,或者一个节点应该扩展多少。注意,如果设置太高的数字将会有过度拟合的风险
verbose : 控制在学习过程中是否要输出任何文本。值0将抑制所有文本,而值3将在每次迭代时输出树学习过程。
请通过Sklearn官方网站查看完整描述。在这里,您会发现有许多其他有用的参数,您可以使用它们。
# 输入所属分类器的参数
# Random Forest parameters 随机森林
rf_params = {
'n_jobs': -1,
'n_estimators': 500,
'warm_start': True,
#'max_features': 0.2,
'max_depth': 6,
'min_samples_leaf': 2,
'max_features' : 'sqrt',
'verbose': 0
}
# Extra Trees Parameters
et_params = {
'n_jobs': -1,
'n_estimators':500,
#'max_features': 0.5,
'max_depth': 8,
'min_samples_leaf': 2,
'verbose': 0
}
# AdaBoost parameters
ada_params = {
'n_estimators': 500,
'learning_rate' : 0.75
}
# Gradient Boosting parameters
gb_params = {
'n_estimators': 500,
#'max_features': 0.2,
'max_depth': 5,
'min_samples_leaf': 2,
'verbose': 0
}
# Support Vector Classifier parameters 支持向量机
svc_params = {
'kernel' : 'linear',
'C' : 0.025
}
Furthermore, since having mentioned about Objects and classes within the OOP framework, let us now create 5 objects that represent our 5 learning models via our Helper Sklearn Class we defined earlier.
# Create 5 objects that represent our 4 models
rf = SklearnHelper(clf=RandomForestClassifier, seed=SEED, params=rf_params)
et = SklearnHelper(clf=ExtraTreesClassifier, seed=SEED, params=et_params)
ada = SklearnHelper(clf=AdaBoostClassifier, seed=SEED, params=ada_params)
gb = SklearnHelper(clf=GradientBoostingClassifier, seed=SEED, params=gb_params)
svc = SklearnHelper(clf=SVC, seed=SEED, params=svc_params)
使用训练集和测试集构建数组
在准备好第一层基本模型之后,我们现在可以通过从原始数据生成NumPy数组来准备训练和测试数据,以便输入分类器,如下所示::
# Create Numpy arrays of train, test and target ( Survived) dataframes to feed into our models
y_train = train['Survived'].ravel()
train = train.drop(['Survived'], axis=1)
x_train = train.values # Creates an array of the train data
x_test = test.values # Creats an array of the test data
输出第1层预测数
现在,我们将训练和测试数据输入到5个基分类器中,并使用我们之前定义的Out-of-Fold预测函数来生成我们的第一层预测。允许下面的代码块运行几分钟。
# 创建训练集和测试集预测值.
et_oof_train, et_oof_test = get_oof(et, x_train, y_train, x_test) # Extra Trees
rf_oof_train, rf_oof_test = get_oof(rf,x_train, y_train, x_test) # Random Forest
ada_oof_train, ada_oof_test = get_oof(ada, x_train, y_train, x_test) # AdaBoost
gb_oof_train, gb_oof_test = get_oof(gb,x_train, y_train, x_test) # Gradient Boost
svc_oof_train, svc_oof_test = get_oof(svc,x_train, y_train, x_test) # Support Vector Classifier
print("Training is complete")
从不同分类器生成的特征重要性
现在,在学习了第一级分类器之后,我们可以利用Sklearn模型的一个非常出色的功能,即用一行非常简单的代码输出训练集和测试集中各种功能的重要性。
根据Sklearn文档,大多数分类器都内置了一个属性,该属性只需输入**.feature_importances即可返回功能重要性。因此,我们将通过我们的函数Earlian调用这个非常有用的属性,并以此来绘制特征的重要性
rf_feature = rf.feature_importances(x_train,y_train)
et_feature = et.feature_importances(x_train, y_train)
ada_feature = ada.feature_importances(x_train, y_train)
gb_feature = gb.feature_importances(x_train,y_train)
rf_features = [0.10474135, 0.21837029, 0.04432652, 0.02249159, 0.05432591, 0.02854371
,0.07570305, 0.01088129 , 0.24247496, 0.13685733 , 0.06128402]
et_features = [ 0.12165657, 0.37098307 ,0.03129623 , 0.01591611 , 0.05525811 , 0.028157
,0.04589793 , 0.02030357 , 0.17289562 , 0.04853517, 0.08910063]
ada_features = [0.028 , 0.008 , 0.012 , 0.05866667, 0.032 , 0.008
,0.04666667 , 0. , 0.05733333, 0.73866667, 0.01066667]
gb_features = [ 0.06796144 , 0.03889349 , 0.07237845 , 0.02628645 , 0.11194395, 0.04778854
,0.05965792 , 0.02774745, 0.07462718, 0.4593142 , 0.01340093]
创建一个dataframe
cols = train.columns.values
# Create a dataframe with features
feature_dataframe = pd.DataFrame( {'features': cols,
'Random Forest feature importances': rf_features,
'Extra Trees feature importances': et_features,
'AdaBoost feature importances': ada_features,
'Gradient Boost feature importances': gb_features
})
通过绘制散点图确定交互特征的重要性
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['Random Forest feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Random Forest feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Random Forest Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['Extra Trees feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Extra Trees feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Extra Trees Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['AdaBoost feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['AdaBoost feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'AdaBoost Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['Gradient Boost feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Gradient Boost feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Gradient Boosting Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
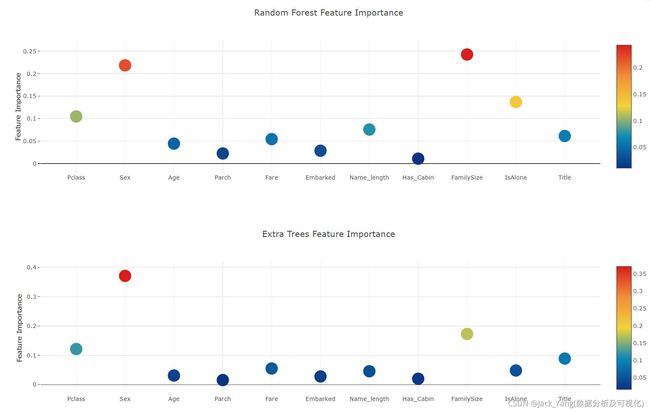
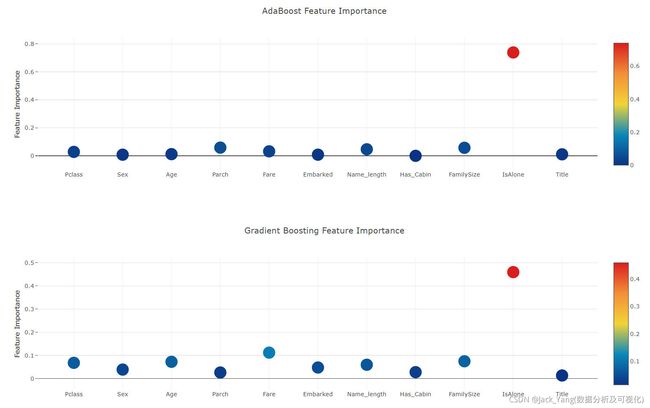
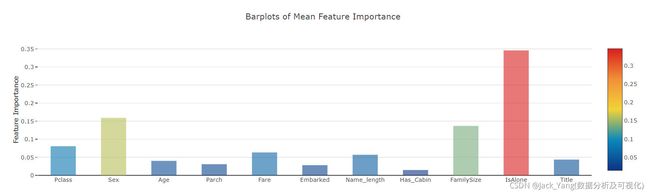
现在,让我们计算所有特征重要性的平均值,并将其作为新列存储在特征重要性数据框中。
# 均值
feature_dataframe['mean'] = feature_dataframe.mean(axis= 1) # axis = 1 computes the mean row-wise
feature_dataframe.head(3)
特征重要性条形图
y = feature_dataframe['mean'].values
x = feature_dataframe['features'].values
data = [go.Bar(
x= x,
y= y,
width = 0.5,
marker=dict(
color = feature_dataframe['mean'].values,
colorscale='Portland',
showscale=True,
reversescale = False
),
opacity=0.6
)]
layout= go.Layout(
autosize= True,
title= 'Barplots of Mean Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='bar-direct-labels')
第2层预测
作为新特性的第一级输出
现在已经获得了我们的第一级预测,我们可以认为它本质上构建了一组新的特征,用作下一个分类器的训练数据。因此,根据下面的代码,我们的新列中包含了来自早期分类器的第一级预测,并在此基础上训练下一个分类器。
base_predictions_train = pd.DataFrame( {'RandomForest': rf_oof_train.ravel(),
'ExtraTrees': et_oof_train.ravel(),
'AdaBoost': ada_oof_train.ravel(),
'GradientBoost': gb_oof_train.ravel()
})
base_predictions_train.head()
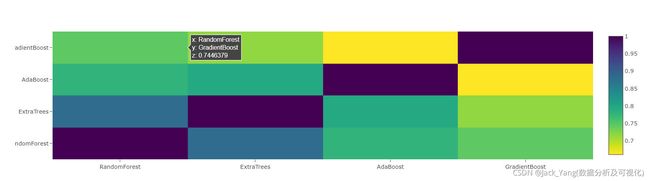
相关热图
data = [
go.Heatmap(
z= base_predictions_train.astype(float).corr().values ,
x=base_predictions_train.columns.values,
y= base_predictions_train.columns.values,
colorscale='Viridis',
showscale=True,
reversescale = True
)
]
py.iplot(data, filename='labelled-heatmap')
x_train = np.concatenate(( et_oof_train, rf_oof_train, ada_oof_train, gb_oof_train, svc_oof_train), axis=1)
x_test = np.concatenate(( et_oof_test, rf_oof_test, ada_oof_test, gb_oof_test, svc_oof_test), axis=1)
基于XGBoost的二级学习模型
在这里,我们选择了非常著名的boosted树学习模型库XGBoost。它是用来优化大规模boosted树算法的。
gbm = xgb.XGBClassifier(
#learning_rate = 0.02,
n_estimators= 2000,
max_depth= 4,
min_child_weight= 2,
#gamma=1,
gamma=0.9,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread= -1,
scale_pos_weight=1).fit(x_train, y_train)
predictions = gbm.predict(x_test)
生成提交文件
# Generate Submission File
StackingSubmission = pd.DataFrame({ 'PassengerId': PassengerId,
'Survived': predictions })
StackingSubmission.to_csv("StackingSubmission.csv", index=False)
水平有限, 有解释不通的地方请谅解, 如果对你有帮助, 欢迎点赞收藏!