卷积神经网络(ResNet-18)识别Fashion-MNIST数据集(Pytorch版)
卷积神经网络(ResNet-18)识别Fashion-MNIST数据集(Pytorch版)
- 1. 前言
-
- 1.1 案例介绍
- 1.2 环境配置
- 1.3 模块导入
- 2. 图像数据准备
-
- 2.1 训练验证集的准备
- 2.2 测试集的准备
- 3. 卷积神经网络的搭建
-
- 3.1 残差块的创建
- 3.2 ResNet模块的创建
- 3.3 ResNet网络的创建
- 4. 卷积神经网络训练与预测
- 5. 运行程序
1. 前言
1.1 案例介绍
本案例使用Pytorch搭建一个ResNet网络结构,用于Fashion-MNIST数据集的图像分类。针对该问题的分析可以分为数据准备、模型建立以及使用训练集进行训练和使用测试集测试模型的效果。
1.2 环境配置
⑴ 操作系统: Windows10
⑵ 编译器环境: PyCharm Community Edition 2021.2
⑶ 配置环境: Pytorch1.7.1 + torchvision8.2 + CUDA11.3
1.3 模块导入
本案例需要导入如下的库文件和相关模块:
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import copy
import time
import torch
import torch.nn as nn
from torch.optim import Adam
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
2. 图像数据准备
在模型建立与训练之前,首先准备FashionMNIST数据集,该数据集可以直接使用torchvision库中datasets模块的FashionMNIST()函数读取,如果指定的工作文件夹中没有当前数据,可以从网络上自动下载该数据。
2.1 训练验证集的准备
训练验证集的加载处理程序被包装成如下的train_data_process()函数 ,它的作用是导入训练数据集,然后使用Data.DataLoader()函数将其定义为数据加载器,每个batch中会包含64个样本,通过len()函数可以计算数据加载器中包含的batch数量,输出显示train_loader中包含938个batch。需要注意的是参数shuffle = False,表示加载器中每个batch使用的样本都是固定的,这样有利于在训练模型时根据迭代的次数将其分为训练集和验证集。同时为了观察数据集中每个图像的内容,可以获取一个batch的图像,然后将其可视化,以观察数据。
# 处理训练集数据
def train_data_process():
# 加载FashionMNIST数据集
train_data = FashionMNIST(root="./data/FashionMNIST", # 数据路径
train=True, # 只使用训练数据集
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]), # 把PIL.Image或者numpy.array数据类型转变为torch.FloatTensor类型
# 尺寸为Channel * Height * Width,数值范围缩小为[0.0, 1.0]
download=False, # 若本身没有下载相应的数据集,则选择True
)
train_loader = Data.DataLoader(dataset=train_data, # 传入的数据集
batch_size=64, # 每个Batch中含有的样本数量
shuffle=False, # 不对数据集重新排序
num_workers=0, # 加载数据所开启的进程数量
)
print("The number of batch in train_loader:", len(train_loader)) # 一共有938个batch,每个batch含有64个训练样本
# 获得一个Batch的数据
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
batch_x = b_x.squeeze().numpy() # 将四维张量移除第1维,并转换成Numpy数组
batch_y = b_y.numpy() # 将张量转换成Numpy数组
class_label = train_data.classes # 训练集的标签
class_label[0] = "T-shirt"
print("the size of batch in train data:", batch_x.shape)
# 可视化一个Batch的图像
plt.figure(figsize=(12, 5))
for ii in np.arange(len(batch_y)):
plt.subplot(4, 16, ii+1)
plt.imshow(batch_x[ii, :, :], cmap=plt.cm.gray)
plt.title(class_label[batch_y[ii]], size=9)
plt.axis("off")
plt.subplots_adjust(wspace=0.05)
plt.show()
return train_loader, class_label
得到的可视化图像如下:
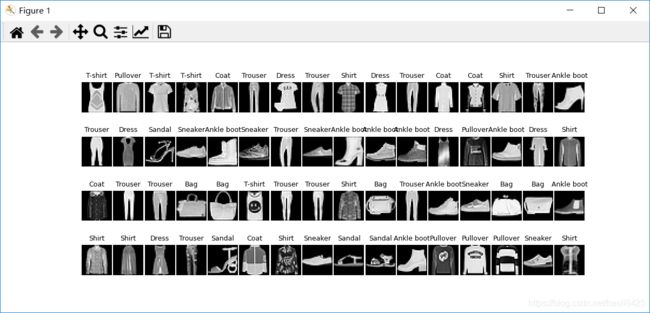
注:由于ResNet模型的输入尺寸为224,这里我们将Fashion-MNIST数据集的尺寸扩展到224,同时每个batch size为64,因此每个mini-batch的尺寸为64×224×224。
2.2 测试集的准备
测试集的加载处理程序被包装成如下的test_data_process()函数 ,它的作用是导入测试数据集,将其尺寸扩展到96,并且将所有的样本处理为一个整体,看作一个batch用于测试。。
# 处理测试集数据
def test_data_process():
test_data = FashionMNIST(root="./data/FashionMNIST", # 数据路径
train=False, # 不使用训练数据集
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]), # 把PIL.Image或者numpy.array数据类型转变为torch.FloatTensor类型
# 尺寸为Channel * Height * Width,数值范围缩小为[0.0, 1.0]
download=False, # 如果前面数据已经下载,这里不再需要重复下载
)
test_loader = Data.DataLoader(dataset=test_data, # 传入的数据集
batch_size=1, # 每个Batch中含有的样本数量
shuffle=True, # 不对数据集重新排序
num_workers=0, # 加载数据所开启的进程数量
)
# 获得一个Batch的数据
for step, (b_x, b_y) in enumerate(test_loader):
if step > 0:
break
batch_x = b_x.squeeze().numpy() # 将四维张量移除第1维,并转换成Numpy数组
batch_y = b_y.numpy() # 将张量转换成Numpy数组
print("The size of batch in test data:", batch_x.shape)
return test_loader
3. 卷积神经网络的搭建
3.1 残差块的创建
假设输入为 x x x,我们希望得到的理想映射为 f ( x ) f(x) f(x)。如下图,左边虚线框中的部分需要直接拟合出该映射 f ( x ) f(x) f(x),而右边虚线框中的部分则需要拟合出有关恒等映射的残差映射 f ( x ) − x f(x)−x f(x)−x。残差映射在实际中往往更容易优化。以恒等映射作为我们希望得到的理想映射 f ( x ) f(x) f(x),只需将右边虚线框内上方的加权运算(如仿射)的权重和偏差参数设置为0,那么 f ( x ) f(x) f(x)即为恒等映射。实际上,当理想映射 f ( x ) f(x) f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。右边是ResNet的基础块,即残差块(residual block)。在残差块中,输入可通过跨层的数据线路更快地向前传播。

ResNet沿用了VGG网络中全3×3卷积层的设计。残差块中首先有2个输出通道数相同的3×3卷积层,每个卷积层后接一个批量归一化层和ReLU激活函数,然后将输入跳过这两个卷积运算后直接加在最后的ReLU激活函数前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1): # 输入通道数,输出通道数,使能1x1卷积,步长
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride) # 定义第一个卷积块
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1) # 定义第二个卷积块
# 定义1x1卷积块
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
# Batch归一化
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
# 定义前向传播路径
def forward(self, x):
y = nn.functional.relu(self.bn1(self.conv1(x)))
y = self.bn2(self.conv2(y))
if self.conv3:
x = self.conv3(x)
return nn.functional.relu(y + x)
3.2 ResNet模块的创建
ResNet使用了4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块,其中第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大池化层,所以无需减小高度和宽度。之后的每个模块中,在第一个残差块里将上一个模块的通道数翻倍,并将高度和宽度减半。
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
3.3 ResNet网络的创建
ResNet的前两层与GoogLeNet一样,在输出通道数为64、步幅为2的7×7卷积层后接步幅为2、窗口大小为3×3的最大池化层,而不同之处在于ResNet在每个卷积层后添加了批量归一化层。接着我们为ResNet加入所有残差块,这里每个模块使用了两个残差块。最后加入全局平均池化层后接上全连接层输出。

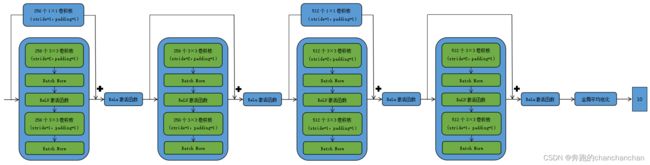
这里每个模块里有4个卷积层(不计算1×1卷积层),加上最开始的卷积层和最后的全连接层,共计18层,因此这个模型通常也被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet的类似,但ResNet结构更简单,修改也更方便。
# 定义一个全局平均池化层
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return nn.functional.avg_pool2d(x, kernel_size=x.size()[2:]) # 池化窗口形状等于输入图像的形状
# 定义ResNet网络结构
def ResNet():
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
net.add_module("fc", nn.Sequential(nn.Flatten(), nn.Linear(512, 10)))
return net
4. 卷积神经网络训练与预测
为了训练网络结构ResNet,定义了一个train_model()函数,该函数的作用是使用训练数据集来训练ResNet网络。训练数据集包含了60000张图像,划分成938个batch,其中80%的batch用于模型的训练,20%的batch用于模型的验证,因此在train_model()函数中,包含了模型的训练和验证两个过程。
# 定义网络的训练过程
def train_model(model, traindataloader, train_rate, criterion, device, optimizer, num_epochs=25):
'''
:param model: 网络模型
:param traindataloader: 训练数据集,会切分为训练集和验证集
:param train_rate: 训练集batch_size的百分比
:param criterion: 损失函数
:param device: 运行设备
:param optimizer: 优化方法
:param num_epochs: 训练的轮数
'''
batch_num = len(traindataloader) # batch数量
train_batch_num = round(batch_num * train_rate) # 将80%的batch用于训练,round()函数四舍五入
best_model_wts = copy.deepcopy(model.state_dict()) # 复制当前模型的参数
# 初始化参数
best_acc = 0.0 # 最高准确度
train_loss_all = [] # 训练集损失函数列表
train_acc_all = [] # 训练集准确度列表
val_loss_all = [] # 验证集损失函数列表
val_acc_all = [] # 验证集准确度列表
since = time.time() # 当前时间
# 进行迭代训练模型
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 初始化参数
train_loss = 0.0 # 训练集损失函数
train_corrects = 0 # 训练集准确度
train_num = 0 # 训练集样本数量
val_loss = 0.0 # 验证集损失函数
val_corrects = 0 # 验证集准确度
val_num = 0 # 验证集样本数量
# 对每一个mini-batch训练和计算
for step, (b_x, b_y) in enumerate(traindataloader):
b_x = b_x.to(device)
b_y = b_y.to(device)
if step < train_batch_num: # 使用数据集的80%用于训练
model.train() # 设置模型为训练模式,启用Batch Normalization和Dropout
output = model(b_x) # 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
pre_lab = torch.argmax(output, 1) # 查找每一行中最大值对应的行标
loss = criterion(output, b_y) # 计算每一个batch的损失函数
optimizer.zero_grad() # 将梯度初始化为0
loss.backward() # 反向传播计算
optimizer.step() # 根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值的作用
train_loss += loss.item() * b_x.size(0) # 对损失函数进行累加
train_corrects += torch.sum(pre_lab == b_y.data) # 如果预测正确,则准确度train_corrects加1
train_num += b_x.size(0) # 当前用于训练的样本数量
else: # 使用数据集的20%用于验证
model.eval() # 设置模型为评估模式,不启用Batch Normalization和Dropout
output = model(b_x) # 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
pre_lab = torch.argmax(output, 1) # 查找每一行中最大值对应的行标
loss = criterion(output, b_y) # 计算每一个batch中64个样本的平均损失函数
val_loss += loss.item() * b_x.size(0) # 将验证集中每一个batch的损失函数进行累加
val_corrects += torch.sum(pre_lab == b_y.data) # 如果预测正确,则准确度val_corrects加1
val_num += b_x.size(0) # 当前用于验证的样本数量
# 计算并保存每一次迭代的成本函数和准确率
train_loss_all.append(train_loss / train_num) # 计算并保存训练集的成本函数
train_acc_all.append(train_corrects.double().item() / train_num) # 计算并保存训练集的准确率
val_loss_all.append(val_loss / val_num) # 计算并保存验证集的成本函数
val_acc_all.append(val_corrects.double().item() / val_num) # 计算并保存验证集的准确率
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(epoch, train_loss_all[-1], train_acc_all[-1]))
print('{} Val Loss: {:.4f} Val Acc: {:.4f}'.format(epoch, val_loss_all[-1], val_acc_all[-1]))
# 寻找最高准确度
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1] # 保存当前的最高准确度
best_model_wts = copy.deepcopy(model.state_dict()) # 保存当前最高准确度下的模型参数
time_use = time.time() - since # 计算耗费时间
print("Train and val complete in {:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))
# 选择最优参数
model.load_state_dict(best_model_wts) # 加载最高准确度下的模型参数
train_process = pd.DataFrame(data={"epoch": range(num_epochs),
"train_loss_all": train_loss_all,
"val_loss_all": val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all}
) # 将每一代的损失函数和准确度保存为DataFrame格式
# 显示每一次迭代后的训练集和验证集的损失函数和准确率
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")
plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")
plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
return model, train_process
接下来定义一个test_model()函数,它的作用是使用测试集在最优模型上进行测试,从而验证该模型的性能。
# 测试模型
def test_model(model, testdataloader, device):
'''
:param model: 网络模型
:param testdataloader: 测试数据集
:param device: 运行设备
'''
# 初始化参数
test_corrects = 0.0
test_num = 0
test_acc = 0.0
# 只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in testdataloader:
test_data_x = test_data_x.to(device)
test_data_y = test_data_y.to(device)
model.eval() # 设置模型为评估模式,不启用Batch Normalization和Dropout
output = model(test_data_x) # 前向传播过程,输入为测试数据集,输出为对每个样本的预测
pre_lab = torch.argmax(output, 1) # 查找每一行中最大值对应的行标
test_corrects += torch.sum(pre_lab == test_data_y.data) # 如果预测正确,则准确度val_corrects加1
test_num += test_data_x.size(0) # 当前用于训练的样本数量
test_acc = test_corrects.double().item() / test_num # 计算在测试集上的分类准确率
print("test accuracy:", test_acc)
最后开始对模型进行训练和测试,其中优化算法使用了Adam优化器,学习率设置为0.001,损失函数为交叉熵函数。然后调用train_model()函数将训练集train_loader的80%用于训练,20%用于验证,一共训练25轮。
# 模型的训练和测试
def train_model_process(myconvnet):
optimizer = torch.optim.Adam(myconvnet.parameters(), lr=0.001) # 使用Adam优化器,学习率为0.001
criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵函数
device = 'cuda' if torch.cuda.is_available() else 'cpu' # GPU加速
train_loader, class_label = train_data_process() # 加载训练集
test_loader = test_data_process() # 加载测试集
myconvnet = myconvnet.to(device)
myconvnet, train_process = train_model(myconvnet, train_loader, 0.8, criterion, device, optimizer, num_epochs=25) # 开始训练模型
test_model(myconvnet, test_loader, device) # 使用测试集进行评估
在模型训练过程中,损失函数和分类准确率的变化曲线如下。可以看到,损失函数在训练集上逐渐减小,而在验证集上上下波动。分类准确率在训练集上也是逐步增大,而在验证集上小幅波动。

为了得到计算模型的泛化能力,将测试集给到训练好的模型进行预测,从而得到在测试集上的预测准确率(如下图)。
![]()
注:对于复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够高效,因此需要将模型移动到GPU,使用GPU加速计算。
5. 运行程序
如下是主函数中的内容,返回一个ResNet网络结构,并对该卷积神经网络进行训练和测试。
if __name__ == '__main__':
model = ResNet()
train_model_process(model)
注:在之前的程序中配置了使用多个进程同时加载训练集数据,多进程的使用必须在main()函数中进行,否则会在执行过程中报错。