手把手实战PyTorch手写数据集MNIST识别项目全流程
目录
摘要
一、认识MNIST手写数据集
二、实战流程
1、加载必要的库
2、定义超参数
3、构建transform,对图像做处理
4、下载、处理、加载数据集
下载、处理数据集
加载数据集
5、构建网络模型
6、定义优化器
7、定义训练方法
8、定义测试方法
9、调用方法7和8
10、运行
三、完整代码
摘要
MNIST手写数据集是跑深度学习模型中很基础的、几乎所有初学者都会用到的数据集,认真领悟手写数据集的识别过程对于深度学习框架有着弥足重要的意义。然而目前各类文章中关于项目完全实战的记录较少,无法满足广大初学者的要求,故本文受B站Tommy启发来手把手从引入库开始进行对整个手写数据集识别的流程,这对于笔者以后的深度学习有着很大的必要性。
一、认识MNIST手写数据集

可以看到,每个阿拉伯数字都形态各异,而本文的任务就是把它们识别出来。
二、实战流程
1、加载必要的库
MNIST手写识别需要的库有基本库torch、包含了构筑神经网络结构基本元素的包torch.nn、torch.nn.functional、优化器optim、对数据库进行操作的torchvision。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
2、定义超参数
超参数:在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
由于实操中数据往往会过多,一次加载不完,内存不够,所以我们将数据切割,选择超参数batch_size(每批处理的数据)为128(根据性能)。
第二个超参数定义一个DEVICE来判断用CPU还是GPU训练。
第三个超参数决定进行几轮训练,本文选择100轮训练.
BATCH_SIZE = 128
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCHS = 203、构建transform,对图像做处理
PyTorch内置很多库,直接调用方法transforms即可:
将图片转换成PyTorch处理的tensor格式,然后进行正则化(对抗过拟合)。
其中0.1307,0.3081分别为官网查得的均值和方差值。
tranform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) #正则化
])4、下载、处理、加载数据集
下载、处理数据集
由于笔者已经提前下载MNIST文件到项目目录里,故download = False,如果提前未下载改成True等待下载成功即可。
from torch.utils.data import DataLoader
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=tranform,
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=tranform,
download=False)加载数据集
其中shuffle决定的是是否打乱数据,为了提高模型精度选择True打乱。
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True)5、构建网络模型
class Digit(nn.Module): #继承父类
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5) # 二维卷积、输入通道,输出通道,5*5 kernel
self.conv2 = nn.Conv2d(10, 20, 3)
self.fc1 = nn.Linear(20*10*10, 500) # 全连接层,输入通道, 输出通道
self.fc2 = nn.Linear(500, 10)
def forward(self, x): # 前馈
input_size = x.size(0) # 得到batch_size
x = self.conv1(x) # 输入:batch*1*28*28, 输出:batch*10*24*24(28-5+1)
x = F.relu(x) # 使表达能力更强大的激活函数, 输出batch*10*24*24
x = F.max_pool2d(x, 2, 2) # 最大池化层,输入batch*10*24*24,输出batch*10*12*12
x = self.conv2(x) # 输入batch*10*12*12,输出batch*20*10*10
x = F.relu(x)
x = x.view(input_size, -1) # 拉平, 自动计算维度,20*10*10= 2000
x = self.fc1(x) # 输入batch*2000,输出batch*500
x = F.relu(x)
x = self.fc2(x) # 输入batch*500 输出batch*10
output = F.log_softmax(x, dim=1) # 计算分类后每个数字的概率值
return output6、定义优化器
将模型部署到GPU
优化器:更新模型参数,使训练结果达到最优值
model = Digit().to(DEVICE)
optimizer = optim.Adam(model.parameters())7、定义训练方法
enumerate函数:来遍历一个集合对象,它在遍历的同时还可以得到当前元素的索引位置。
反向传播:不断迭代权重,降低误差。
loss.item():取出单元素张量的元素值(loss值)并返回该值,保持原元素类型不变。
def train_model(model, device, train_loader, optimizer, epoch):
model.train() #PyTorch提供的训练方法
for batch_index, (data, label) in enumerate(train_loader):
#部署到DEVICE
data, label = data.to(device), label.to(device)
#梯度初始化为0
optimizer.zero_grad()
#训练后的结果
output = model(data)
#计算损失(针对多分类任务交叉熵,二分类用sigmoid)
loss = F.cross_entropy(output, label)
#找到最大概率的下标
pred = output.argmax(dim=1)
#反向传播Backpropagation
loss.backward()
#参数的优化
optimizer.step()
if batch_index % 3000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))8、定义测试方法
def test_model(model, device, test_loader):
#模型验证
model.eval()
#统计正确率
correct = 0.0
#测试损失
test_loss = 0.0
with torch.no_grad(): # 不计算梯度,不反向传播
for data, label in test_loader:
data, label = data.to(device), label.to(device)
#测试数据
output = model(data)
#计算测试损失
test_loss += F.cross_entropy(output, label).item()
#找到概率值最大的下标
pred = output.argmax(dim=1)
#累计正确率
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test —— Average loss : {:.4f}, Accuracy : {:.3f}\n".format(test_loss, 100.0 * correct / len(test_loader.dataset)))9、调用方法7和8
for epoch in range(1, EPOCHS + 1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
test_model(model, DEVICE, test_loader)10、运行
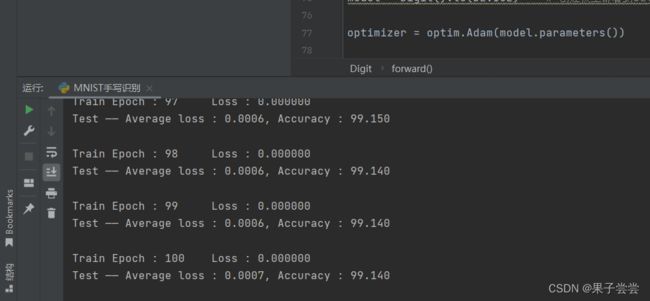
接下来运行即可,笔者运行结果如下图示:
三、完整代码
完整代码如下:
#1加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
#2定义超参数(参数:由模型学习来决定的)数据太多一次放不完,切割
BATCH_SIZE = 128 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # CPU还是GPU?
EPOCHS = 100
#3构建transform, 对图像进行各种处理(旋转拉伸,放大缩小等)
tranform = transforms.Compose([
transforms.ToTensor(), # 将图片转换成Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 均值和方差,正则化(对抗过拟合):降低模型复杂度
])
#4下载、加载数据集
from torch.utils.data import DataLoader
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=tranform,
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=tranform,
download=False)
#加载数据集
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True)
#5构建网络模型
class Digit(nn.Module):
def __init__(self): #继承父类
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5) # 输入通道,输出通道,5*5 kernel
self.conv2 = nn.Conv2d(10, 20, 3)
self.fc1 = nn.Linear(20*10*10, 500) # 全连接层,输入通道, 输出通道
self.fc2 = nn.Linear(500, 10)
def forward(self, x): # 前馈
input_size = x.size(0) # 得到batch_size
x = self.conv1(x) # 输入:batch*1*28*28, 输出:batch*10*24*24(28-5+1)
x = F.relu(x) # 使表达能力更强大激活函数, 输出batch*10*24*24
x = F.max_pool2d(x, 2, 2) # 最大池化层,输入batch*10*24*24,输出batch*10*12*12
x = self.conv2(x) # 输入batch*10*12*12,输出batch*20*10*10
x = F.relu(x)
x = x.view(input_size, -1) # 拉平, 自动计算维度,20*10*10= 2000
x = self.fc1(x) # 输入batch*2000,输出batch*500
x = F.relu(x)
x = self.fc2(x) # 输入batch*500 输出batch*10
output = F.log_softmax(x, dim=1) # 计算分类后每个数字的概率值
return output
#6定义优化器
model = Digit().to(DEVICE) # 创建模型部署到DEVICE
optimizer = optim.Adam(model.parameters())
#7定义训练方法
def train_model(model, device, train_loader, optimizer, epoch):
model.train() #PyTorch提供的训练方法
for batch_index, (data, label) in enumerate(train_loader):
#部署到DEVICE
data, label = data.to(device), label.to(device)
#梯度初始化为0
optimizer.zero_grad()
#训练后的结果
output = model(data)
#计算损失(针对多分类任务交叉熵,二分类用sigmoid)
loss = F.cross_entropy(output, label)
#找到最大概率的下标
pred = output.argmax(dim=1)
#反向传播Backpropagation
loss.backward()
#参数的优化
optimizer.step()
if batch_index % 3000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))
#8定义测试方法
def test_model(model, device, test_loader):
#模型验证
model.eval()
#统计正确率
correct = 0.0
#测试损失
test_loss = 0.0
with torch.no_grad(): # 不计算梯度,不反向传播
for data, label in test_loader:
data, label = data.to(device), label.to(device)
#测试数据
output = model(data)
#计算测试损失
test_loss += F.cross_entropy(output, label).item()
#找到概率值最大的下标
pred = output.argmax(dim=1)
#累计正确率
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test —— Average loss : {:.4f}, Accuracy : {:.3f}\n".format(test_loss, 100.0 * correct / len(test_loader.dataset)))
#9 调用方法7和8
for epoch in range(1, EPOCHS + 1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
test_model(model, DEVICE, test_loader)