谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
系列文章目录
- 谣言检测文献阅读一—A Review on Rumour Prediction and Veracity Assessment in Online Social Network
- 谣言检测文献阅读二—Earlier detection of rumors in online social networks using certainty‑factor‑based convolutional neural networks
- 谣言检测文献阅读三—The Future of False Information Detection on Social Media:New Perspectives and Trends
- 谣言检测文献阅读四—Reply-Aided Detection of Misinformation via Bayesian Deep Learning
- 谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
- 谣言检测文献阅读六—Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate
- 谣言检测文献阅读七—EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
- 谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
- 谣言检测文献阅读九—人工智能视角下的在线社交网络虚假信息 检测、传播与控制研究综述
文章目录
- 系列文章目录
- 前言
- 摘要
- 1 介绍
- 2 相关工作
-
- 2.1 谣言检测与分析
- 2.2 假新闻检测
- 3. 突发新闻谣言检测的深度学习模型
-
- 3.1 问题陈述
- 3.2 递归神经网络
- 3.3. 提出模型
-
- 3.3.1. word2vec
- 3.3.2. LSTM-RNN
- 3.3.3. Model training
- 4、实验
-
- 4.1. Datasets
- 4.2. 基线和要素集
- 4.3. 实验设置
- 4.4. 结果
-
- 4.4.1. 与基线分类器的比较
- 4.4.2. 实验帖子的句法表达
- 4.4.3. 不同嵌入训练策略的比较
- 4.4.4.表征数据集
- 4.5. 案例研究
-
- 4.5.1. 案例研究1:发现突发新闻中新兴子话题的谣言
- 4.5.2. 案例研究2:发现多个新兴突发新闻主题的谣言
- 4.5.3. 案例研究结果讨论
- 5、限制
- 6、结论
前言
文章:Detecting breaking news rumors of emerging topics in social media
发表会议:Information Processing and Management (B 类会议论文)
时间:2019年
摘要
提出了一种新方法,该方法联合学习词嵌入并训练具有两个不同目标的循环神经网络来自动识别谣言。所提出的策略简单但有效地缓解了主题转移问题。
1 介绍
突发新闻谣言比发现长期存在的谣言更具挑战性。首先,突发新闻涵盖了我们在训练数据集中可能找不到的主题和事件,这需要在监督学习中考虑跨主题。否则,检测模型很可能会过拟合训练数据集。其次,突发新闻往往包含训练数据集中不存在的新词,例如新的主题标签或实体名称。词汇外(OOV)词的问题是另一个挑战。新出现的谣言包含不在训练样本中的单词,尤其是对于主题标签。由于之前没有观察到的新术语,使用预训练的词嵌入无法解决这个问题。此外,考虑到它们的上下文,与过去相比,相同的术语可能具有非常不同的含义。
为了应对这些挑战,我们联合训练了一个 word2vec (Mikolov, Sutskever, Chen, Corrado, & Dean, 2013) 模型,该模型具有无监督目标来学习词嵌入,并训练具有监督目标的循环神经网络模型进行谣言检测。我们建议使用循环神经网络的输入动态训练 word2vec 模型。通常,使用循环神经网络来更新词嵌入层。相比之下,我们保持与循环神经网络平行的 word2vec 模型,并使用它来更新嵌入空间。通过这种方式,我们的模型可以逐步学习输入文本中单词的分布式向量表示,从中捕获深层潜在特征及其相关性,并使用它们来构建突发新闻谣言的检测模型。此外,学习术语的分布式向量表示使我们的模型能够更好地处理在训练过程中没有看到的突发新闻新兴主题的新 OOV 词。我们发现这种简单的设计可以有效解决上述挑战。
创新点:
- 我们通过将无监督学习目标与监督学习目标相结合,提出了一种新的半监督学习解决方案,用于突发新闻谣言检测。据我们所知,这是第一个使用深度学习模型的表征学习来检测社交媒体上出现的突发新闻谣言的工作
- 我们提出了一种新的策略来在训练过程中动态更新词嵌入缓解突发新闻谣言检测中的跨主题和OOV问题。与现有工作相比,我们不基于手工制作的特征来训练我们的模型。相反,我们提出的模型在监督训练的同时学习分布式表示。
2 相关工作
2.1 谣言检测与分析
工作主要分为四类:谣言检测、谣言跟踪、谣言立场分类和谣言真实性分类
2.2 假新闻检测
3. 突发新闻谣言检测的深度学习模型
3.1 问题陈述
突发新闻谣言检测的研究问题可以定义如下:对于一个给定的微博,关于一条特定的信息,任务是确定它是否是谣言。这个问题可以表述为一个二元分类问题,如下所示: w = w 1 , w 2 … w T w= w_1,w_2…w_T w=w1,w2…wT 是长度为 T 的微博 w 中的单词序列。给定 w 作为输入,目标是通过从 L = { R , N R } L=\{ R,NR\} L={R,NR} 分配标签。
3.2 递归神经网络
3.3. 提出模型

3.3.1. word2vec
这篇博文讲的特别好
3.3.2. LSTM-RNN
3.3.3. Model training
为了帮助训练过程缓解突发新闻谣言检测中的跨主题和OOV问题,我们将word2vec模型与递归神经网络模型保持平行,并使用它动态更新嵌入空间。
4、实验
使用交叉熵损失函数,然后进行数据更新。我们需要使模型能够学习更一般的特征表示,这些特征表示可以捕获所有事件之间的共同特征。这种表示应该是事件不变的,并且不包括任何特定于事件的特征。为了实现这个目标,我们需要去除每个事件的唯一性。特别是,我们测量不同事件之间特征表示的差异性并将它们删除以捕获事件不变的特征表示。
4.1. Datasets
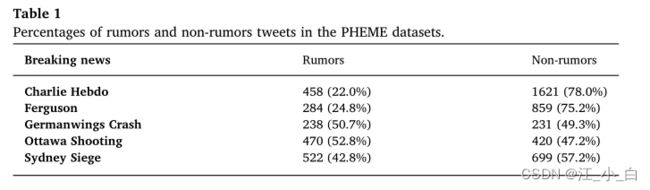
在我们的实验中,我们使用了来自PHEME的五组真实推文(Zubiaga、Hoi、Liakata和Procter,2016),其中每一组推文都与一条突发新闻相关。PHEME可公开访问。表1总结了每一条推文中谣言和非谣言的百分比。
4.2. 基线和要素集
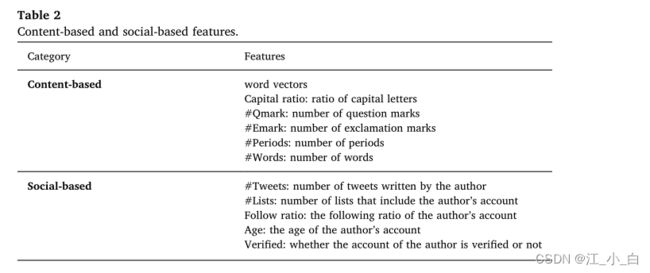
4.3. 实验设置
使用5折交叉验证。在每次运行中,我们使用四个突发新闻故事的数据集来训练我们的模型以及基线分类器。然后使用第五个数据集评估这些分类器在精确度、召回率和F1方面的性能。最终结果使用五次五折交叉验证作为结果。
4.4. 结果
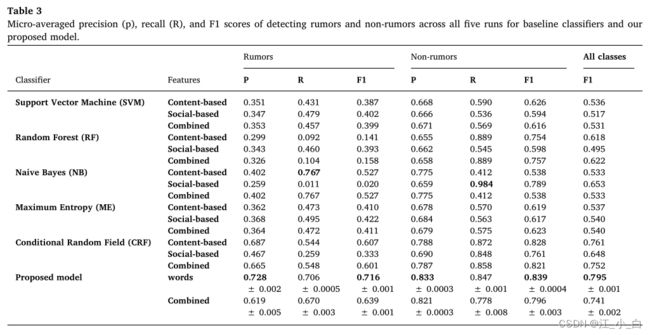
4.4.1. 与基线分类器的比较
4.4.2. 实验帖子的句法表达
为了进一步评估我们模型的分类性能,我们将推特的以下语法表示作为输入进行了实验:
- 词性标记(POS)。受敏感文本检测工作的启发(McDonald、Macdonald和Ounis,2015),我们想探索是否将推特表示为一系列POS标签可以提高分类性能。
- N-gram单词和N-gram字符。我们还将每个输入tweet表示为一系列N-gram单词或N-gram字符,以进一步探索这种表示是否可以提高我们模型的分类性能。
在这个实验中,我们为N-gram单词设置N=1、2、3,为N-gram字符设置N=3、5、7。然后,我们进行了5次重复的5倍交叉验证,并使用不同的输入表示来评估我们的模型。表4显示了N-gram单词、N-gram字符和POS标记在两个类别(谣言和非谣言)在精确度、召回率和F1方面5次重复交叉验证的微平均±方差得分。

4.4.3. 不同嵌入训练策略的比较
为了评估知识转移是否有助于提高我们的深度学习模型的分类性能,我们使用三种不同的设置,通过word2vec模型学习单词的分布式向量表示,比较了我们的模型的性能:

- 静态word2vec模型。在此设置中,在培训阶段,我们使用训练集共同学习word2vec和LSTM-RNN模型。然后,为了评估我们的模型,word2vec模型被用作查找表,将测试数据集中的每一条新推特转换为其单词的向量表示序列,然后将其输入LSTM-RNN模型。14
- 动态word2vec模型。在此设置中,在培训阶段,我们使用培训数据集共同学习word2vec和LSTM-RNN模型。然后,为了评估我们的模型,word2vec模型在对测试数据集中的每一条新推特进行分类的同时进行了增量训练和更新
- 升级训练过的Google word2vec模型。在此设置中,我们没有从头开始学习单词的分布式向量表示,而是使用通用word2vec模型作为单词的初始分布式victor表示。该模型在谷歌的新闻数据集上训练,包含300万个单词和短语,每个单词和短语在嵌入空间中表示为一个300维向量。
结果表明与构建 LSTM-RNN 模型并行构建 word2vec 模型有助于谣言检测模型从输入文本中学习潜在特征及其相关性。此外,随着每条新推文逐步更新 word2vec 模型,有助于模型减轻与新兴突发新闻谣言相关的主题转移和 OOV 问题。
4.4.4.表征数据集
在本节中,我们旨在评估将基于社交的特征添加到每个数据集的基于内容的特征中对分类性能的影响。我们首先在每个数据集上评估每个分类器的精度两次:一次仅使用基于内容的特征,另一次使用基于社交的特征和基于内容的特征作为我们的输入。结果表明,在为Ferguson数据集添加基于社会的特征后,四个分类器的精度得到了提高,而其他数据集只有一个分类器得到了提高。
 这些结果使我们分析了每个数据集基于社会和基于内容的特征。我们首先使用增益比特征选择算法(Abeel、Van de Peer和Saeys,2009),测量每个特征在预测每个数据集中真实推文类别中的重要性。表7显示了获得的结果。粗体值表示每种情况下最重要的功能。结果表明,包含作者账户的列表数量(用#List表示)是Ferguson和Sydney Sakege数据集的一个重要社交特征,而验证(无论作者账户是否验证)是Charlie Hebdo和Germanwings Crash数据集的一个重要社交特征。我们进一步分析了每个数据集基于社会的特征,并使用标准差(SD)来衡量其值的变化量。表8显示了获得的结果。粗体值表示数据集中要素的SD值与其他数据集有显著差异的情况。表中的标准偏差值显示了五个数据集中每一个基于社会的特征值的稀疏性。每列表示一个基于社交的特征的变化量。不同的尺度是由于不同的特征具有非常不同的值尺度。如表所示,在具有重要社交功能的四个数据集中,Ferguson数据集的特点是#list功能的SD值与其他数据集相比非常低。同样,Sydney Sakege数据集的特点是#List的SD值较高。另一方面,Charlie Hebdo和Germanwings Crash数据集中验证特征的SD值与其他数据集几乎相同,这无助于描述这些数据集的特征。
这些结果使我们分析了每个数据集基于社会和基于内容的特征。我们首先使用增益比特征选择算法(Abeel、Van de Peer和Saeys,2009),测量每个特征在预测每个数据集中真实推文类别中的重要性。表7显示了获得的结果。粗体值表示每种情况下最重要的功能。结果表明,包含作者账户的列表数量(用#List表示)是Ferguson和Sydney Sakege数据集的一个重要社交特征,而验证(无论作者账户是否验证)是Charlie Hebdo和Germanwings Crash数据集的一个重要社交特征。我们进一步分析了每个数据集基于社会的特征,并使用标准差(SD)来衡量其值的变化量。表8显示了获得的结果。粗体值表示数据集中要素的SD值与其他数据集有显著差异的情况。表中的标准偏差值显示了五个数据集中每一个基于社会的特征值的稀疏性。每列表示一个基于社交的特征的变化量。不同的尺度是由于不同的特征具有非常不同的值尺度。如表所示,在具有重要社交功能的四个数据集中,Ferguson数据集的特点是#list功能的SD值与其他数据集相比非常低。同样,Sydney Sakege数据集的特点是#List的SD值较高。另一方面,Charlie Hebdo和Germanwings Crash数据集中验证特征的SD值与其他数据集几乎相同,这无助于描述这些数据集的特征。

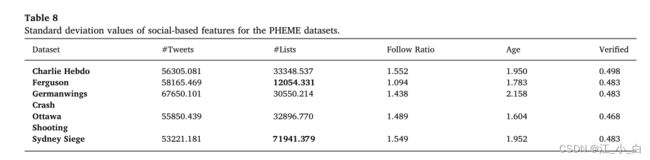 通过比较表6-8中的结果,我们观察到,虽然Ferguson和Sydney Siege数据集可以通过具有高重要分数和非常不同的SD值的基于社会的特征与其他数据集进行区分,Ferguson添加基于社会的特征改善了大多数分类器的分类性能,但是Sydney Siege数据集值只提高了一个分类器的分类效果。Sydney Siege数据集中#List的SD值非常高,这表明其值具有更高的稀疏性。因此,添加此功能非但没有改善分类性能,反而使分类性能恶化。
通过比较表6-8中的结果,我们观察到,虽然Ferguson和Sydney Siege数据集可以通过具有高重要分数和非常不同的SD值的基于社会的特征与其他数据集进行区分,Ferguson添加基于社会的特征改善了大多数分类器的分类性能,但是Sydney Siege数据集值只提高了一个分类器的分类效果。Sydney Siege数据集中#List的SD值非常高,这表明其值具有更高的稀疏性。因此,添加此功能非但没有改善分类性能,反而使分类性能恶化。
4.5. 案例研究
4.5.1. 案例研究1:发现突发新闻中新兴子话题的谣言
为了在实时推特上展示我们的模型在突发新闻子主题上的表现,我们收集了一条关于新兴突发新闻故事的推特,其中指出美国政府在将近1500名举目无亲的移民儿童安置在赞助者家中后,失去了他们的踪迹。这条突发新闻最近在推特上传播开来,成千上万的人在标签上纳闷,孩子们在哪里了解这条新闻的许多方面。虽然这条消息已经得到了普遍证实,但许多推特都在散布关于故事不同方面和细节的谣言。政府尚未证实或驳斥这些谣言。我们收集了50条关于这条突发新闻的推文,并手动对每条推文进行了事实检查,只保留了我们知道的属于两类之一的34条推文:谣言和非谣言。然后,我们将这些推文输入到我们的模型中,将每一条推文归类为谣言与否。表10显示了收集到的推文的示例,以及它们是如何按照我们的模型进行分类的。表9显示了我们的谣言检测模型在准确度、召回率和F1方面应用于这些推文的分类性能。这些结果表明,我们的模型能够高精度地检测出不可见主题的突发新闻谣言。

4.5.2. 案例研究2:发现多个新兴突发新闻主题的谣言
我们进行了另一个案例研究,以证明我们的模型在实时推特流中检测多条突发新闻的不同新兴主题方面的性能。我们首先收集了关于以下三条未经证实的突发新闻的推特,这些新闻最近出现,尚未得到政府的证实或反驳:
- “44.9万加州居民拒绝了陪审团的职责,因为他们不是美国公民,尽管他们已经登记投票”。这条消息在社交媒体上传播得很快,用户超时添加了更多的声明。然而,这一消息尚未得到证实
- “危地马拉当局从移民商队中的人口走私犯手中救出了一群未成年人”。尽管危地马拉政府高级官员声称存在独家信息和照片,但这条新闻仍然没有得到证实
- “美国纽约南区检察官已于2018年12月开始起诉特朗普总统的就职委员会。尽管这一指控由知名新闻机构发表,但尚未得到证实,而且仅基于匿名来源的信息。
此外,为了演示推特流不限于预定义事件或主题的真实场景,我们收集了以下两个主要突发新闻来源的推特流:
- 一家著名通讯社的官方推特账号。我们收集了CNN推特账户时间线前两页的所有推特。这些推文代表了一个实时的微帖子流,涉及世界各地经常发生的突发新闻和事件的未指明主题
- 一个通用的所有时间趋势标签。我们还收集了广泛采用的时尚标签#OOTD时间线前两页的所有推文。我们选择这个标签有两个主要原因。首先,此标签中的时尚数据表示与新闻无关的未看到的一般主题。这模拟了每天通用的实时推特流。其次,与趋势突发新闻标签类似,趋势时尚标签总是包含有许多新出现的主题、术语/词汇和命名实体的推特。
接下来,我们手动检查每个收集到的推特,只保留了89条我们知道属于两类之一的推特:谣言和非谣言。然后,我们将这些推文随机洗牌,并将它们输入到我们的检测模型中。表11显示了我们的谣言检测模型在准确度、召回率和F1方面应用于这些推文时的分类性能。这些结果表明,我们的模型能够在每天的推特流中高精度地检测出多个突发新闻谣言中的不可见话题。

4.5.3. 案例研究结果讨论
为了进一步了解我们的谣言检测模型所获得的结果,我们仔细检查了正确分类的推文文本,并将其与两个案例研究中错误分类的推文进行了比较。我们有两个主要的观察结果。首先,我们注意到大多数流言推特的写作风格非常相似。同样,大多数非谣言推特也有自己的写作风格。这一观察结果可以在未来通过提出一个突发新闻谣言检测模型来进一步检验,该模型以推特的不同写作风格为条件。其次,我们注意到许多新的OOV术语和命名实体的存在,这些实体最初并不是由我们的模型训练的,例如就职典礼、危地马拉、走私者、特朗普、移民和机构。案例研究的结果表明,我们的模型能够自适应地捕捉突发新闻谣言检测中的漂移,并缓解OOV和话题转移问题。
5、限制
根据我们采用的定义,谣言被定义为“真实价值未经证实的故事或陈述”,谣言不一定是虚假的;它们以后可以被认为是真的或假的。这一定义意味着,标记为谣言的新兴推特稍后可能是非谣言。然而,我们提出的模型没有明确建模或记忆随时间变化的事实。为了解决这个问题,所提出的模型可以与持久的谣言检测模型相结合。该模型负责标记和存储新出现的谣言,并且可以在检查事实时训练持久的谣言检测模型。然而,我们的实验和案例研究表明,尽管我们的模型没有明确地跨时间建模和记忆事实,但只要查看当前时刻的推文,它的表现就相当好。我们怀疑可能有两个原因。首先,word2vec模型以增量方式更新。它可能会记住新概念,并随着时间推移而漂移。其次,该模型可以通过记忆来区分谣言和非谣言在自然语言中的传播方式。它们可能对应一种非常不同的写作风格,这与我们在案例研究中的观察结果一致。
6、结论
随着社交媒体作为突发新闻的主要来源的适应度不断提高,区分已证实的信息和未证实的谣言成为一项极其困难和关键的任务。社交媒体的几个特点有助于发布具有未确立的真实值的信息,并在世界各地的用户中快速传播。突发新闻谣言,如果不尽早发现,可能会产生极其严重的破坏性后果。在这项工作中,我们通过提出一个联合构建word2vec模型和LSTM-RNN谣言检测模型的模型来解决识别Twitter上传播的新兴话题的突发新闻谣言的问题。该模型能够仅根据推特的文本准确识别突发新闻谣言。我们在真实数据集上的实验表明,我们提出的模型在精度、召回率和F1方面的性能优于最先进的分类器以及其他基线分类器。