推荐系统入门(四):Wide&Deep(附代码)
推荐系统入门(四):Wide&Deep(附代码)
目录
- 推荐系统入门(四):Wide&Deep(附代码)
-
- 引言
-
- 点击率预估简介
- FM它不香吗
- 1.Wide&Deep模型
- 2. “记忆能力”与“泛化能力”
- 3. 操作流程
- 4.实战
- 5.深度学习推荐系统的发展
- 思考
- 参考资料
引言
相关系列笔记:
推荐系统入门(一):概述
推荐系统入门(二):协同过滤(附代码)
推荐系统入门(三):矩阵分解MF&因子分解机FM(附代码)
推荐系统入门(四):Wide&Deep(附代码)
推荐系统入门(五):GBDT+LR(附代码)
推荐系统入门(六):新闻推荐实践1(附代码)
推荐系统入门(七):新闻推荐实践2(附代码)
推荐系统入门(八):新闻推荐实践3(附代码)
推荐系统入门(九):新闻推荐实践4(附代码)
推荐系统入门(十):新闻推荐实践5(附代码)
点击率预估简介
1)点击率预估是用来解决什么问题?
点击率预估是对每次广告点击情况作出预测,可以输出点击或者不点击,也可以输出该次点击的概率,后者有时候也称为pClick。
2)率预估模型需要做什么?
通过上述点击率预估的基本概念,我们会发现其实点击率预估问题就是一个二分类的问题,在机器学习中可以使用逻辑回归作为模型的输出,其输出的就是一个概率值,我们可以将机器学习输出的这个概率值认为是某个用户点击某个广告的概率。
3)率预估与推荐算法有什么不同?
广告点击率预估是需要得到某个用户对某个广告的点击率,然后结合广告的出价用于排序;而推荐算法很多大多数情况下只需要得到一个最优的推荐次序,即TopN推荐的问题。当然也可以利用广告的点击率来排序,作为广告的推荐。
FM它不香吗
之前我们已经学了FM模型,不是已经很好了吗,为啥还要整这个Wide&Deep呢?其缺点在于:当query-item矩阵是稀疏并且是high-rank的时候(比如user有特殊的爱好,或item比较小众),很难非常效率的学习出低维度的表示。这种情况下,大部分的query-item都没有什么关系。但是dense embedding会导致几乎所有的query-item预测值都是非0的,这就导致了推荐过度泛化,会推荐一些不那么相关的物品。相反,简单的linear model却可以通过cross-product transformation来记住这些exception rules,cross-product transformation是什么意思后面再提。
1.Wide&Deep模型
Wide&Deep模型是由 Google 于 2016 年提出的一种深度学习模型,用于推荐系统,它包含 Wide模块与 Deep 模块 2 个部分。
Wide 模块主要的作用是接收经过编码后的类别型特征,由于类别型特征能够很好地反映某一样本的独特性,因此可以对样本的信息进行很好的表达。
Deep 模块主要的作用是接收经过特征工程后的数值型特征与类别型特征,通过神经网络端对端的拟合特性将数值型特征进行充分的融合,提高模型对信息的表达效果。
Wide&Deep 模型则是将 Wide 模块与 Deep 模型进行结合的集成模型,其特点是能够同时拥有2 种模型对于类别型数据与数值型数据对数据信息表达方式的优点,其模型如下图所示。
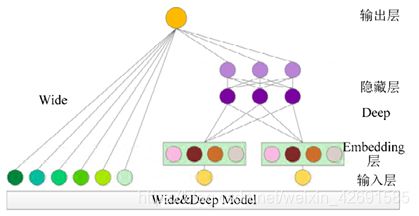
2. “记忆能力”与“泛化能力”
Memorization 和 Generalization是推荐系统很常见的两个概念,其中Memorization指的是通过用户与商品的交互信息矩阵学习规则,而Generalization则是泛化规则。我们前面介绍的FM算法就是很好的Generalization的例子,它可以根据交互信息学习到一个比较短的矩阵V,其中vi储存着每个用户特征的压缩表示(embedding),而协同过滤与SVD都是靠记住用户之前与哪些物品发生了交互从而推断出的推荐结果,这两者推荐结果当然存在一些差异,我们的Wide&Deep模型就能够融合这两种推荐结果做出最终的推荐,得到一个比之前的推荐结果都好的模型。
可以这么说:Memorization趋向于更加保守,推荐用户之前有过行为的items。相比之下,generalization更加趋向于提高推荐系统的多样性(diversity)。Memorization只需要使用一个线性模型即可实现,而Generalization需要使用DNN实现。
下面是wide&deep模型的结构图,由左边的wide部分(一个简单的线性模型),右边的deep部分(一个典型的DNN模型)。
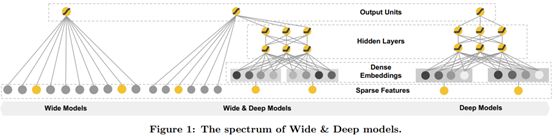
其实wide&deep模型本身的结构是非常简单的,对于有点机器学习基础和深度学习基础的人来说都非常的容易看懂,但是如何根据自己的场景去选择那些特征放在Wide部分,哪些特征放在Deep部分就需要理解这篇论文提出者当时对于设计该模型不同结构时的意图了,所以这也是用好这个模型的一个前提。
如何理解Wide部分有利于增强模型的“记忆能力”,Deep部分有利于增强模型的“泛化能力”?
- wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交互特征(cross-product transformation),对于交互特征可以定义为:
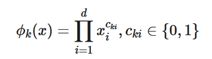
这个式子什么意思读者可以自行找原论文看看,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。用原论文的例子举例:
AND(userinstalledapp=QQ, impressionapp=WeChat),当特征userinstalledapp=QQ,和特征impressionapp=WeChat取值都为1的时候,组合特征AND(userinstalledapp=QQ,impression_app=WeChat)的取值才为1,否则为0。
对于wide部分训练时候使用的优化器是带L1正则的FTRL算法(Follow-the-regularized-leader),而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。例如Google W&D期望wide部分发现这样的规则:用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。
- Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
![]()
我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
Wide部分与Deep部分的结合
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:
![]()
3. 操作流程
-
Retrieval:利用机器学习模型和一些人为定义的规则,来返回最匹配当前Query的一个小的items集合,这个集合就是最终的推荐列表的候选集。
-
Ranking:
o 收集更细致的用户特征,如:
- User features(年龄、性别、语言、民族等)
- Contextual features(上下文特征:设备,时间等)
- Impression features(展示特征:app age、app的历史统计信息等)
o 将特征分别传入Wide和Deep一起做训练。在训练的时候,根据最终的loss计算出gradient,反向传播到Wide和Deep两部分中,分别训练自己的参数(wide组件只需要填补deep组件的不足就行了,所以需要比较少的cross-product feature transformations,而不是full-size wide Model)
- 训练方法是用mini-batch stochastic optimization。
- Wide组件是用FTRL(Follow-the-regularized-leader) + L1正则化学习。
- Deep组件是用AdaGrad来学习。
o 训练完之后推荐TopN
所以wide&deep模型尽管在模型结构上非常的简单,但是如果想要很好的使用wide&deep模型的话,还是要深入理解业务,确定wide部分使用哪部分特征,deep部分使用哪些特征,以及wide部分的交叉特征应该如何去选择。
4.实战
代码实战主要分为两大部分,第一部分是使用tensorflow中已经封装好的wide&deep模型,这一部分主要是熟悉模型训练的整体结构。第二部分是使用tensorflow中的keras实现wide&deep,这一部分主要是尽可能的看到模型内部的细节并将其实现。
Tensorflow内置的WideDeepModel
在Tensorflow的库中是已经内置了Wide-Deep model的,想要查看源代码了解具体实现过程可以看这里。下面参考Tensorflow官网的示例代码进行讲解。我们用到的数据集下载链接戳这里。
首先看全局实现:
tf.keras.experimental.WideDeepModel(
linear_model, dnn_model, activation=None, **kwargs
)
这一步很容易看出来就是将linearmodel与dnnmodel拼接在了一起,对应于Wide-Deep FM中的最后一步。比如我们可以将linearmodel与dnnmodel做一个最简单的实现:
linear_model = LinearModel()
dnn_model = keras.Sequential([keras.layers.Dense(units=64),
keras.layers.Dense(units=1)])
combined_model = WideDeepModel(linear_model, dnn_model)
combined_model.compile(optimizer=['sgd', 'adam'], 'mse', ['mse'])
# define dnn_inputs and linear_inputs as separate numpy arrays or
# a single numpy array if dnn_inputs is same as linear_inputs.
combined_model.fit([linear_inputs, dnn_inputs], y, epochs)
# or define a single `tf.data.Dataset` that contains a single tensor or
# separate tensors for dnn_inputs and linear_inputs.
dataset = tf.data.Dataset.from_tensors(([linear_inputs, dnn_inputs], y))
combined_model.fit(dataset, epochs)
这里第一步就是直接调用一个keras.experimental中的linearmodel,第二步简单实现了一个全连接神经网络,第三步使用WideDeepModel将前两步产生的两个model拼接在一起,形成最终的combinedmodel,接着就是常规的compile和fit了。
除此之外线性模型与DNN模型在联合训练之前均可进行分别训练:
linear_model = LinearModel()
linear_model.compile('adagrad', 'mse')
linear_model.fit(linear_inputs, y, epochs)
dnn_model = keras.Sequential([keras.layers.Dense(units=1)])
dnn_model.compile('rmsprop', 'mse')
dnn_model.fit(dnn_inputs, y, epochs)
combined_model = WideDeepModel(linear_model, dnn_model)
combined_model.compile(optimizer=['sgd', 'adam'], 'mse', ['mse'])
combined_model.fit([linear_inputs, dnn_inputs], y, epochs)
这里前三行代码训练了一个线性模型,中间三行代码训练了一个DNN模型,最后三行代码则将两个模型联合训练,以上就完成了对Tensorflow的WideDeepModel的调用,其中每个函数有一些其他参数我们这里不详细说明,读者若有需要可自行在tensorflow官网查询,另外该部分的源代码在Tensorflow的Github上有展示,链接在这。
Tensorflow实现wide&deep模型
这一部分对原始特征进行转换,以及deep特征和wide特征的选择,特征的交叉等一系列特征操作,模型也分成了wide部分和deep部分,相比于上述直接使用tensorflow内置的模型,更加的详细,可以对模型理解的更加的深刻。
在这里wide和deep部分的优化,为了简单实现,使用了同一个优化器优化两部分,详细内容参考代码中的注释。
代码参考源代码文档。
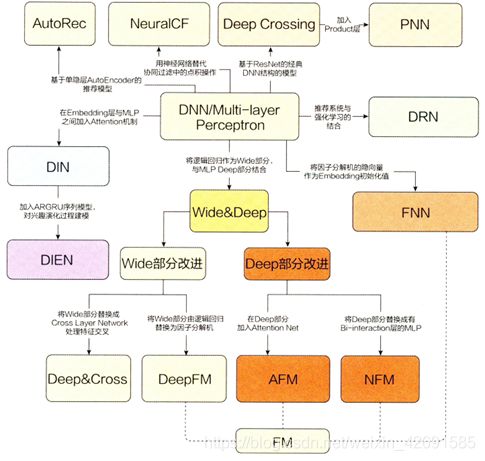
5.深度学习推荐系统的发展
在介绍部分就说过,Wide&Deep模型在深度学习发展中起到了非常重要的作用,从下图中我们就可以看到它对后续模型发展的一个影响。
思考
Wide&Deep模型仍然存在哪些不足,阵对这些不足工程师们有哪些改进?
(1)Wide&Deep 模型虽然能够同时对数值型与类别型的特征信息有很好的表达效果,但却不适用于电力系统的负荷预测问题。在 Wide&Deep 模型的基础上加以改良,吕海灿等人提出了 Wide&Deep-LSTM 模型。其模型结构如下图所示:
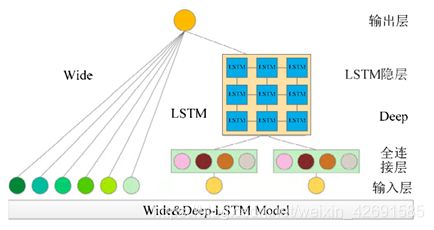
Wide&Deep-LSTM 模型借鉴了 Wide&Deep 模型对于输入特征的信息抽取方式,把用于将推荐系统的文本输入数据转变为向量的 embedding 层更改为全连接层,用于进行输入数据的信息融合;同时增加了 LSTM 模块,用于对输入数据的时序信息进行表达,并将 Wide&Deep 模型的输出层激活函数更改为 RELU,使得模型能够处理电力负荷预测问题。
(2)在现有宽深度模型的基础上, 利用门限循环单元对其多层普通神经网络进行改进, 王艺平等人提出宽深度门循环联合 (Wide&Deep-GRU) 模型, 进一步探索浅层部分和深度部分的联合训练。Wide&Deep-GRU层次结构图如下:
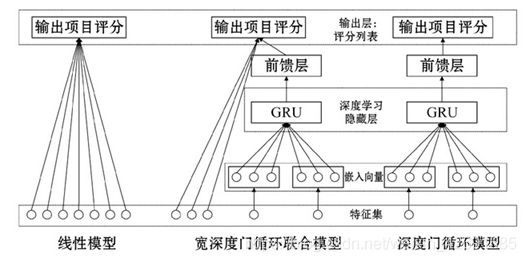
对现有推荐模型的局限性进行分析研究,结合传统机器学习浅层模型与深度模型各自的优点,提出了一种传统浅层线性模型与深度网络模型相结合的推荐排序方法。首先利用基于稀疏自编码器的主题提取方法对博文语料进行主题提取,在百万级的博文数据中取得数百个候选集。接着,在数百个候选集的基础上,一方面获取用户特征等信息,采用交叉特征法处理特征,输入到浅层模型当中。另一方面只需少量的特征工程,通过映射的方法,处理低维稠密特征得到密集矢量后输入到以门循环单元为核心的深度模型。最后,处理输出结果并得到博文项的推荐排序。实验表明,本文的方法分别单一逻辑回归模型、单一深度神经网络模型和宽深度模型等进行对比,不仅在短文本数据特征稀疏的情况下使博文推荐的准确率得到了提升,还在一定程度上提高了模型的训练和预测速度,具有更高的推荐效率。
参考资料
- Datawhale组队学习:推荐系统基础
- 吕海灿,王伟峰,赵兵,张毅,郭秋婷,胡伟.基于Wide&Deep-LSTM模型的短期台区负荷预测[J].电网技术,2020,44(02):428-436.
- 王艺平,冯旭鹏,刘利军,黄青松.基于改进的宽深度模型的推荐方法研究[J].计算机应用与软件,2018,35(11):49-54.