深度学习论文笔记(知识蒸馏)—— FitNets: Hints for Thin Deep Nets
文章目录
- 主要工作
- 知识蒸馏的一些简单介绍
- 文中一些有意思的观念
- Method
最近看了不少文献,一直懒得总结,现在才爬起来写总结…,不少论文的idea还是不错的
主要工作
让小模型模仿大模型的输出(soft target),从而让小模型能获得大模型一样的泛化能力,这便是知识蒸馏,是模型压缩的方式之一,本文在Hinton提出knowledge distillation方法(下文简称KD)的基础上进行扩展,利用teacher模型特征提取器的中间层输出作为hints,结合KD,对更深但更窄的student模型进行知识蒸馏。
本文的工作背景为2014年,此时残差结构、MSRA初始化、BN算法还没有提出,训练深度网络往往存在一定困难,而本文提出的知识蒸馏方法可以有效训练深度网络
知识蒸馏的一些简单介绍
知识蒸馏本质是让小模型模拟大模型的输出,teacher模型可以看成是一个函数,简单起见,假设teacher模型为一个二维函数,将训练集上的 X X X输入到teacher模型,输出的集合记为 Y Y Y,设训练集上的 X X X取值范围为 [ a , b ] [a,b] [a,b],则student模型的任务为依据 { X , Y } \{X,Y\} {X,Y},模拟teacher模型在 [ a , b ] [a,b] [a,b]范围上的曲线。
如果让teacher模型拟合数据集 A A A,数据集 A A A自变量的取值范围记为 [ a , b ] [a,b] [a,b],蒸馏时使用数据集 B B B,数据集 B B B自变量的取值范围记为 [ c , d ] [c,d] [c,d]。
若数据集 B B B与数据集 A A A的差异较大,即 [ a , b ] [a,b] [a,b]与 [ c , d ] [c,d] [c,d]没有交集,则student模型在数据集 A A A上的表现往往比较差,在数据集 B B B上的表现也不如意,原因在于teacher模型在 [ c , d ] [c,d] [c,d]处的曲线并不是数据集 B B B的目标曲线,因此student模型在数据集 B B B上的表现不好,同时,student模型拟合的teacher模型在 [ c , d ] [c,d] [c,d]处的曲线,在 [ a , b ] [a,b] [a,b]区域的曲线可能与teacher模型相差较大,所以student模型在数据集 A A A上的表现也不如意,但如果 A A A与 B B B差异不大,则student模型在 A A A与 B B B上的表现都可能较好。
上述想法也能解释为什么增量学习的代表作 L w F LwF LwF效果不佳
文中一些有意思的观念
提高网络性能有三个主流的方式(个人观点),网络的深度、宽度、注意力机制,网络越深,某些函数族的表现能力更强,表现能力个人理解为拟合能力,在文章发表的那个年代,表现优异的网络深度往往比较大。
基于上述理念,文章选择的student模型将比teacher模型更深,但更窄。
Method
文章将knowledge distillation分为两个阶段,步骤如下图

具体步骤如下:
一、选择teacher模型特征提取器的第 N N N层输出作为hint,从第一层到第 N N N层的参数对应图(a)中的 W H i n t W_{Hint} WHint
二、选择student模型特征提取器的第 M M M层输出作为guided,从第一层到第 M M M层的参数对应图(a)中的 W G u i d e d W_{Guided} WGuided
三、步骤一与步骤二的特征图维度可能不匹配,因此引入卷积层调整器,记为 r r r,对guided的维度进行调整
四、进入阶段一训练,最小化如下损失函数:
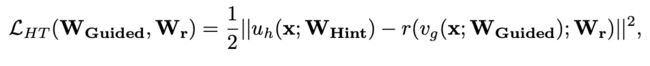
u h u_h uh表示teacher模型从第一层到第 N N N层对应的函数, v g v_g vg表示student模型从第一层到第 M M M层对应的函数, r r r表示卷积层调整器,对应的参数记为 W r W_r Wr,如图(b)
五、因为阶段一没有label信息,蒸馏粒度不够细,因此论文引入阶段二的训练,利用hinton提出的knowledge distillation对student模型进行蒸馏,如图©
阶段一的训练类似于一个正则化,因此 N N N与 M M M的取值应该自行调节, N N N与 M M M的取值越大,student模型正则化的程度就越大,原文如下:

该说法个人不太赞同,因为论文给出了阶段二,阶段二相当于在阶段一的基础上进行知识蒸馏,似乎和模型容量没有太大关系,神经网络的较浅层提取的是通用特征,较深层提取的是任务相关的特征,选择合适的 N N N与 M M M,可以避免student模型的任务相关层拟合teacher模型的通用特征层,这才是选择合适 N N N与 M M M的理由(个人理解)
整个算法的伪代码如下:

作者也尝试过将阶段一与阶段二合并训练,但是发现优化不动模型,实验部分在此不多做总结,有兴趣可以浏览原文