Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
显示,参加和讲述:具有视觉注意的神经图像字幕生成
Abstract
原文
Inspired by recent work in machine translation and object detection, we introduce an attention based model that automatically learns to describe
the content of images. We describe how we can train this model in a deterministic manner using standard backpropagation techniques and
stochastically by maximizing a variational lower bound. We also show through visualization how the model is able to automatically learn to fix its
gaze on salient objects while generating the corresponding words in the output sequence. We validate the use of attention with state-of-the art performance on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.
翻译
摘要 受机器翻译和对象检测领域最新工作的启发,引入了一种基于注意力的模型,该模型可以自动学习描述图像的内容,描述了如何使用标准的反向传播技术,以确定性的方式训练模型,并通过最大化变分下界随机地训练模型,还通过可视化展示了模型如何能够自动学习将注视固定在显着对象上,同时在输出序列中生成相应的单词,
我们通过**三个基准数据集(Flickr8k,Flickr30k和MS COCO)**验证了注意力的使用。
Introduction
原文
Automatically generating captions of an image is a task very close to the heart of scene understanding — one of the primary goals of computer vision. Not only must caption generation models be powerful enough to solve the computer vision challenges of determining which objects are in an image, but they must also be capable of capturing and expressing their relationships in a natural language. For this reason, caption generation has long been viewed as a difficult problem. It is a very important challenge for machine learning algorithms, as it amounts to mimicking the remarkable human ability to compress huge amounts of salient visual infomation into descriptive language.(描述性语言)
翻译
自动生成图像字幕非常接近场景理解核心的任务,这是计算机视觉的主要目标之一。字幕生成模型不仅必须足以解决确定图像中存在那些对象的计算机视觉挑战。而且其必须能够以自然语言捕获表达其关系,由于这个原因,字幕生成长期以来一直被视作一个难题,对于机器学习算法而言,这是一个非常重要的挑战,因为其相当于模仿人类将大量显着的视觉信息压缩为描述性语言的非凡能力。
相关技术
自动生成图像字幕
加粗样式图像字幕自动生成的目的是用准确并且有意义的句子描述图像所传达的最显著的信息。在本文系统介绍了图像字幕自动生成的方法。从早期的方法,到最近的深度学习方法。图像字幕的生成准确度不断提高,并且越来越多人在准确度基础上关注了字幕的多样性,能够生成更具风格的图像字幕。将图像用文本描述从而实现了对图像的高度概括,从而解决了复杂图像难理解、视觉障碍难以阅读图像以及图像检索等问题。
原文
Despite the challenging nature of this task, there has been a recent surge of research interest in attacking the image caption generation problem. Aided by advances in training neural networks (Krizhevsky et al., 2012) and large classification datasets (Russakovsky et al., 2014), recent work has significantly improved the quality of caption generation using a combination of convolutional neural networks (convnets) to obtain vectorial representation of images and recurrent neural networks to decode those representations
into natural language sentences (see Sec. 2).翻译
尽管此任务具有挑战性,但最近在解决图像字幕生成问题方面研究兴趣激增。在训练神经网络(Krizhevsky等人,2012)。和大型分类数据集(Russakovsky等人,2014)的进步帮助下,最近的工作通过使用卷积神经网络的组合显著改善了字幕生成的质量(卷积)以及图像的矢量表示。并通过递归神经网络将这些表示解码为自然语言句子。
原文
One of the most curious facets of the human visual system is the presence of attention (Rensink, 2000; Corbetta & Shulman, 2002). Rather than compress an entire image into a static representation, attention allows for salient features to dynamically come to the forefront as needed. This is
especially important when there is a lot of clutter in an image. Using representations (such as those from the top layer of a convnet) that distill information in image down to the most salient objects is one effective solution that has been widely adopted in previous work. Unfortunately, this has one potential drawback of losing information which could be useful for richer, more descriptive captions. Using more low-level representation can help preserve this information. However working with these features necessitates a powerful mechanism to steer the model to information important to the task at hand.翻译
视觉是人类视觉系统中最令人好奇的方面之一。(Rensink,2000; Corbetta&Shulman,2002)。注意,不是将整个图像压缩为正态表示。而是将显著特征根据需要动态地移到最前列。当图像中有很多混乱时,这一点尤其重要。使用表示(例如来自卷积网络顶层的表示)将图像中的信息提取到最显着的对象是一种有效的解决方案,在先前的工作中已被广泛采用。不幸的是,这具有丢失信息的潜在缺陷,这对于更丰富,更具有描述性的字幕可能有用。使用更底层的表示形式可以帮助保留此信息。但是,使用这些功能需要一种强大的机制来将模型引导到对手头任务很重要的信息。
原文
In this paper, we describe approaches to caption generation that attempt to incorporate a form of attention with wo variants: a “hard” attention mechanism and a “soft” attention mechanism. We also show how one advantage of including attention is the ability to visualize what the model “sees”. Encouraged by recent advances in caption generation and inspired by recent success in employing attention in machine translation (Bahdanau et al., 2014) and object recognition (Ba et al., 2014; Mnih et al., 2014), we investigate models that can attend to salient part of an image while generating its caption.
在本文中,我们将描述字幕生成方法,这些方法试图将注意力形式和两种变体结合起来。硬性注意力机制和软性注意力机制。还展示了吸引注意力的一个优势是可视化模型看到的能力。受到字幕生成的最新进展的鼓舞。并受近期在机器翻译(Bahdanau等,2014)和对象识别(Ba等,2014; Mnih等,2014)中运用注意力的成功所启发,我们进行了以下研究:门模型:可以在生成图像标题时关注图像的显着部分。
原文
The contributions of this paper are the following:
We introduce two attention-based image caption generators under a common framework (Sec. 3.1): 1) a “soft” deterministic attention mechanism trainable by standard back-propagation methods and 2) a “hard” stochastic attention mechanism trainable by maximizing an approximate variational lower bound or equivalently by REINFORCE (Williams, 1992).
• We show how we can gain insight and interpret the
results of this framework by visualizing “where” and
“what” the attention focused on. (see Sec. 5.4)
• Finally, we quantitatively validate the usefulness of
attention in caption generation with state of the art
performance (Sec. 5.3) on three benchmark datasets:
Flickr8k (Hodosh et al., 2013) , Flickr30k (Young
et al., 2014) and the MS COCO dataset (Lin et al.,
2014).翻译
我们在一个通用框架(第3.1节)中引入了两种基于注意力的图像字幕生成器:1)一种可通过标准反向传播方法训练的“软”确定性注意力机制,以及2一>一种可通过以下方法训练的“硬”随机注意力机制
用REINFORCE最大化或等效地最大化近似下限(Williams,1992)。
我们展示了如何通过可视化关注的重点在“何处”和“何处”来获得洞察力并解释该框架的结果。 (请参见第5.4节)
最后,我们在以下三个基准数据集上以最先进的性能(第5.3节)定量验证了注意力在字幕生成中的有用性:Flickr8k(Hodosh等人,2013),Flickr30k(Young等人,2014)和 MS COCO数据集(Lin等人,2014)
相关工作
在本节中,我们提供有关图像标题生成和关注的先前工作的相关背景。近来,已经提出了几种用于生成图像描述的方法。这些方法中许多都基于递归神经网络,并受到成功使用序列到神经网络进行机器翻译的序列训练的启发(Cho等人,2014; Bahdanau等人,2014; Sutskever等人)。图像字幕生成非常适合机器翻译的编码器-解码器框架的一个主要原因(Cho等,2014)是因为它类似于将图像“翻译”为句子。

使用神经网络进行字幕生成的第一种方法是Kiros等。 (2014a),他提出了一种多模式对数双线性模型,该模型受到图像特征的偏颇。 Kiros等人随后进行了这项工作。 (2014b),其方法旨在明确允许采用自然的方式进行排名和生成。 Mao et al。(2014)采取了类似的生成方法,但用递归模型代替了前馈神经语言模型。双方Vinyals等。 (2014)和Donahue等。 (2014年)将LSTM RNN用于其模型。与Kiros等人不同。 (2014a)和Mao等。 (2014年),Vinyals等人的模型在输出单词序列的每个时间步上看到了图像。 (2014)一开始只显示图片给RNN。除了图像,Donahue等。 (2014年)也将LSTM应用于视频,从而允许其模型生成视频描述。

所有这些作品都将图像表示为来自预训练卷积网络顶层的单个特征矢量。 相反,Karpathy&Li(2014)提议学习一种用于排名和生成的联合嵌入空间,该模型的模型学习根据R-CNN对象检测对句子和图像相似性进行评分的方法,并带有双向RNN的输出。 方等。 (2014)提出了一个三步流水线,通过结合对象检测来生成。 他们的模型首先基于多实例学习框架为几种视觉概念学习检测器。 然后将经过字幕训练的语言模型应用于检测器输出,然后从联合的图像-文本嵌入空间进行记录。 与这些模型不同,我们提出的注意框架没有显式使用对象检测器,而是从头开始学习潜在的对齐方式。 这使我们的模型超越了“客观性”,并学会关注抽象概念。
在使用神经网络生成字幕之前,主要采用两种主要方法。首先涉及生成字幕模板,这些模板根据对象检测和属性发现的结果进行填充(Kulkarni等人(2013),Li等人(2011),Yang等人(2011),Mitchell等人( 2012年),埃利奥特和凯勒(2013年)。第二种方法是基于首先从大型数据库中检索相似的字幕图像,然后修改这些检索到的字幕以适合查询(Kuznetsova等人,2012; 2014)。这些方法通常涉及一个中间的“一般化”步骤,以删除仅与检索到的图像相关的标题的详细信息,例如城市名称。从那以后,这两种方法都不适合现在占主导地位的神经网络方法。
以前有很长的工作将注意力集中到视觉相关任务的神经网络中。与我们的工作精神相同的一些人包括Larochelle&Hinton(2010); Denil等。 (2012); Tang等(2014)。但是,尤其是,我们的工作直接扩展了Bahdanau等人的工作。 (2014); Mnih等。 (2014); Ba等。 (2014)。
带有注意力机制的图像字幕生成
模型详情
本节中,我们先首先描述它们的通用框架来描述基于注意力机制的两个变体,主要区别在于 ϕ \phi ϕ
函数的定义:我们将在第4节中详细介绍:我们用加粗字体表示矢量。并用大写字母表示矩阵。在下面描述中,为了便于阅读,我们消除了偏见。
编码器:卷积功能
模型拍摄单个原始图像,并生成字母 y y y,该字幕 y y y编码为 k k k个编码字中的1个序列。
y = ( y 1 , y 2 , . . . , y c ) y i ∈ R k y = (y_1,y_2,...,y_c) y_i\in R^k y=(y1,y2,...,yc)yi∈Rk
其中k是词汇量,C是字幕长度。
我们使用卷积神经网络来提取一组特征向量,我们将其称为注释向量,提取器产生 L L L个向量。
每个向量对应于图像一部分的 D D D维表示。
α = ( α 1 , α 2 , . . . . , α L ) , α i ∈ R D \alpha = (\alpha_1,\alpha_2,....,\alpha_L), \alpha_i \in R^D α=(α1,α2,....,αL),αi∈RD
为了获得 特征向量和二维图像各部分之间的对应关系,我们从较低的卷积层中提取特征。这与以前的工作不同。后者使用的是全连接层。这允许解码器通过选择所有特征向量的子集来选择性地聚焦于图像的某些部分。
解码器:长期短时记忆网络
我们使用LSTM网络,该网络通过在上下文向量,先前的隐藏状态和先前生成单词的条件下的每个时间步生成一个单词来产生字幕。我们对LSTM的实现紧随Zaremba等人使用的LSTM。 (2014)(请参阅图4)。 使用Ts,t:Rs→Rt表示具有所学习参数的简单仿射变换
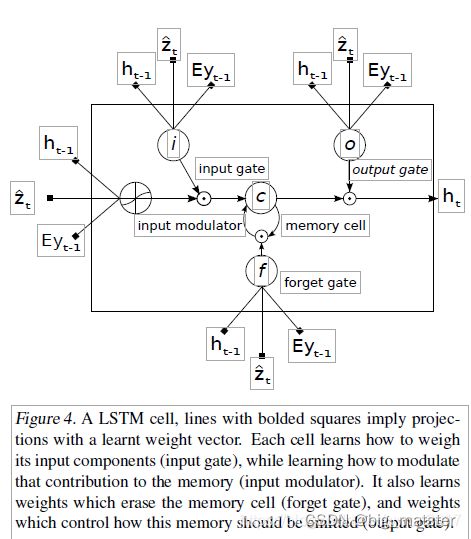
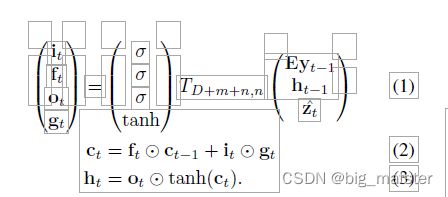
在这里 f t , c t , o t , h t ft,ct,ot, ht ft,ct,ot,ht分别表示LSTM的输入状态,忘记状态、存储状态。输出状态和隐藏状态。向量 Z ∈ R D Z \in R^D Z∈RD是上下文向量,捕获与特定输入位置相关的视觉信息。例如在下面抱怨: E ∈ R m ⋅ R k E \in R_m \cdot R_k E∈Rm⋅Rk是一个嵌入矩阵,令m和n分别表示嵌入和LSTM维度。而 α \alpha α和 l o g log log分别表示逻辑 S S S型激活和逐元素相乘。
简而言之 Z t Z_t Zt是在时间 t t t输入的图像相关部分动态地表示。我们定义一种机制$ \phi$ 其可以从注释向量 a i a_i ai 计算 Z T Z^T ZT。L对应于在不同图像位置处提取特征,对于每个位置 i i i,该机制都会产生正权重 α i \alpha_i αi。其可以解释为位置 i i i是产生下一个单词的正确焦点所在的可能性(硬但塑机的注意力),也可以解释为相对重要性在将 α i \alpha_i αi混合在一起时赋予的位置 i i i。每个注释向量 α i \alpha_i αi的权重 α i \alpha_i αi由注意力模型fatt计算出来。为此我们使用了基于先前隐藏的多层感知器状态 h t − 1 h_{t - 1} ht−1。这种注意力机制是由Bahdanau等人介绍的,为强调起见。我们注意到隐藏状态随输出RNN的输出顺序前进而变化,网络下一步的查找位置取决于已生成的单词顺序。
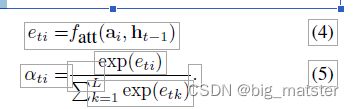
一旦计算了权重(总和为1),就可以通过以下方式计算上下文向量了 Z t Z^t Zt
![]()
其中, ϕ \phi ϕ是在给定注释矢量及其相应权重的情况下,返回单个矢量的函数。 ϕ \phi ϕ函数的详细内容将在第二节中讨论:
LSTM初始内存状态和隐藏状态由两个单独的MLP(init,c 和 init , h)馈送的注释向量的平均值来预测:

在这项工作中,我们使用一个深层输出层(Pascanu等人,2014)在给定LSTM状态,上下文向量和前一个单词的情况下计算输出单词概率:
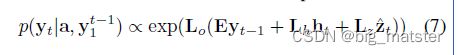
其中,啥是随机初始化学习参数。
学习随机的困难与确定性的软性注意力
随机硬注意力
确定性“软”注意力
双重随机注意力
各种注意力,文章中暂时读不懂,先搞后续,等积累深厚概念后在继研读各种注意力。
训练程序
我们的注意力模型的两个变体都使用了自适应学习率算法进行了随机梯度下降训练。对于Flickr8k数据集,我们发现了RM-SProp效果最佳。而对于Flickr30k / MS COCO数据集,我们使用了最近提出的Adam算法(Kingma&Ba,2014)。
为了创建解码器使用的批注 a i a_i ai,我们使用了在ImageNet上进行预训练的Oxford VGGnet(Simonyan&Zisserman,2014),而没有进行微调。 但是原则上可以使用任何编码功能。 另外,有了足够的数据,我们还可以从零开始(或微调)训练模型的其余部分的编码器。 在我们的实验中,我们在最大池化之前使用第四卷积层的14×14×512特征图。 这意味着我们的解码器可以对196×512(即L×D)扁平化编码进行操作。
由于我们的实现需要的时间与每次更新中最长句子的长度成正比,因此我们发现,对随机字幕组的训练在计算上是浪费的。 为了减轻这个问题,在预处理中,我们构建了一个字典,将句子的长度映射到相应的字幕子集。 然后,在训练过程中,我们随机取样一个长度,并检索该长度的大小为64的微型批次。 我们发现,这大大提高了收敛速度,而性能却没有明显下降。 在我们最大的数据集(MS COCO)上,我们的软注意力模型花费不到3天的时间在NVIDIA Titan Black GPU上进行训练。
除了辍学(Srivastava等,2014),我们使用的唯一其他正则化策略是尽早停止BLEU评分。 在实验的后期训练中,我们观察到验证集对数似然性与BLEU之间的相关性崩溃。 由于BLEU是最常报告的指标,因此我们在验证集上使用了BLEU进行模型选择。
在我们的实验中,我们在Flickr8k实验中还使用了Whet-lab1(Snoek等人,2012; 2014)。 我们从其探索的超参数区域获得的一些直觉在我们的Flickr30k和COCO实验中尤其重要。
我们将基于Theano的这些模型的代码(Bergstra等,2010)公开发布,以鼓励该领域的进一步研究。
实验
描述了我们的实验方法论和定量结果,验证了我们的字幕生成模型的有效性。
数据
我们报告了流行的Flickr8k和Flickr30k数据集的结果,该数据集分别具有8,000和30,000图像,以及更具挑战性的Microsoft COCO数据集具有82,783图像。 Flickr8k / Flickr30k数据集每个图像都带有5个参考语句,但是对于MS COCO数据集,某些图像的引用量超过5个,以确保我们丢弃的数据集的一致性。 我们仅对MS COCO应用了基本标记,因此它与Flickr8k和Flickr30k中存在的标记一致。 对于我们所有的实验**,我们使用的固定词汇量为10,000**
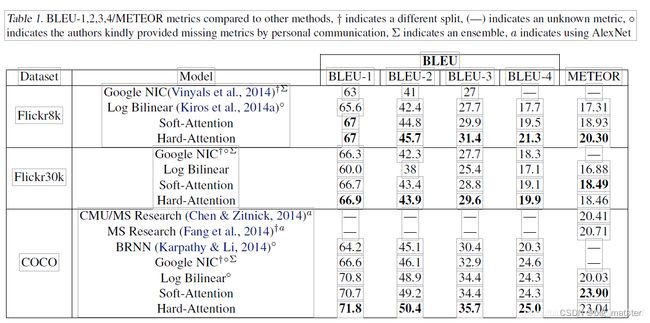
表4.2.1报告了基于关注的体系结构的结果。 我们使用常用的BLEU metric2报告结果,这是字幕生成文献中的标准。 我们报告BLEU从1到4,但没有简短规定。 但是,有人对BLEU提出了批评,因此我们还报告了另一种常见的METEOR流星(Denkowski&Lavie,2014年),并在可能的情况下进行比较。
评估程序
存在一些挑战供比较,我们在这里进行解释。 首先是卷积特征提取器选择的差异。 对于相同的解码器架构,请使用最新的架构,例如GoogLeNet或Ox-ford VGG Szegedy等。 (2014),Simonyan&Zisserman(2014)可以比使用AlexNet带来更高的性能(Krizhevsky et al。,2012)。 在我们的评估中,我们仅直接与使用可比的GoogLeNet / Oxford VGG功能的结果进行比较,但是对于METEOR比较,我们注意到一些使用AlexNet的结果。
第二个挑战是单一模型与整体比较。 虽然其他方法通过使用集成报告了性能提升,但在我们的结果中,我们报告了单个模型的性能。
最后,由于数据集拆分之间的差异,存在挑战。 在我们报告的结果中,我们使用Flickr8k的预定义拆分。 但是,Flickr30k和COCO数据集的挑战之一是缺乏标准化的分割。 结果,我们报告了先前工作中使用的公开可用拆分3(Karpathy&Li,2014)。 根据我们的经验,拆分的差异不会对整体性能产生实质性的影响,但是我们注意到存在差异的地方。
定量分析
在表4.2.1中,我们提供了验证注意力定量有效性的实验总结。 我们在Flickr8k,Flickr30k和MS COCO上获得了最先进的性能。 此外,我们注意到,在我们的实验中,我们能够显着改善MS COCO上最先进的性能流星,我们推测这与我们使用4.2.1和更低层表示的某些正则化技术有关。 最后,我们还注意到,我们可以使用单个模型获得整体的性能。
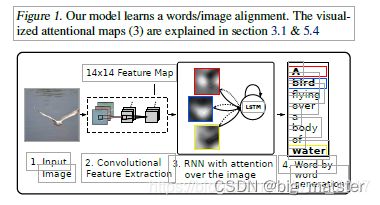
定性分析,学习参加
通过可视化模型学习到的注意力成分,我们可以在模型的输出中增加一层解释性(见图1)。 其他执行此操作的系统则依赖于对象检测系统来生成候选对齐目标(Karpathy&Li,2014)。 我们的方法更加灵活,因为模型可以处理“非对象”显着区域。
19层的OxfordNet使用3x3过滤器堆栈,这意味着特征图尺寸减小的唯一时间是由于最大池化层。调整输入图像的大小,以使最短的一面为256维,并保留长宽比。卷积网络的输入是中心裁剪的224x224图像。因此,在4个最大池化层的情况下,顶部卷积层的输出尺寸为14x14。因此,为了可视化软模型的注意权重,我们仅将权重上采样24 = 16倍,然后应用高斯滤波器。我们注意到,每个14x14单元的接收场高度重叠。
正如我们在图2和3中看到的那样,该模型学习了与人类直觉非常吻合的对齐方式。尤其是在错误示例中,我们看到可以利用这种可视化效果来直观了解为什么会犯这些错误。我们在附录A中为读者提供了更广泛的可视化列表。
结论
我们提出了一种基于关注的方法,该方法使用BLEU和METEOR指标在三个基准数据集上提供最新性能。 我们还展示了如何利用学习到的注意力为模型生成过程提供更多的可解释性,并证明学习到的对齐方式非常符合人类的直觉。 我们希望本文的结果能够鼓励将来使用视觉注意力的工作。 我们还期望将编码器/解码器方法的模块化与关注结合起来,使其在其他领域中有用。
总结:这篇CV领域的文章过于羞涩难懂,慢慢地将各种文章都给其搞清楚,全部都将其搞定都行啦的样子与打,先助攻NLP领域的知识,慢慢地将其搞定都行啦的回事与打算。
soft attentiond的简要概述
我们之前学习attention的机制就是Soft attention 其计算公式,我们已经熟悉:
e k j = s c o r e ( H k − 1 , h j ) e_{kj} = score(H^{k-1} , h^{j}) ekj=score(Hk−1,hj)
α k j = e x p ( e k j ) ÷ s u m i = 1 T x e x p ( e k i ) \alpha_{kj} = exp(e_{kj}) \div \ sum_{i = 1}^{T_x}exp(e_{ki}) αkj=exp(ekj)÷ sumi=1Txexp(eki)
C k = ∑ i = 1 T x a K i h i C_k = \sum_{i = 1}^{T_x}a_{Ki}h^i Ck=i=1∑TxaKihi
下图为完整的soft attention的工作示意图
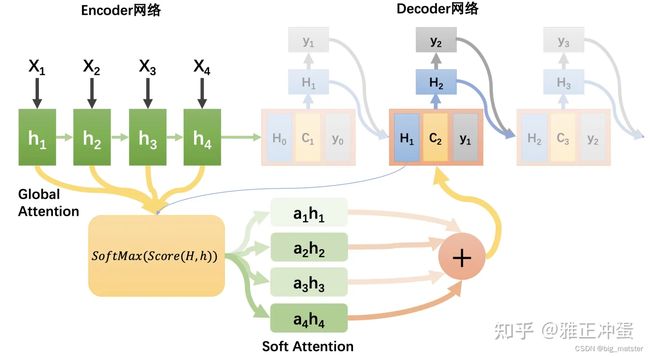
注意力机制的核心要素就是利用sofrmax函数求出权重,然后在进行加权运算求出中间语义向量表示。关键是求权重都行啦的样子与打算。
Hard Attention
该注意力机制不使用加权平均的方法,对于每个待选择的输入隐藏层,要完全采纳进入上下文向量,要就是彻底抛弃,具体如何选择需要注意隐藏层,有两种实现方式:
- 直接选择最高权重 α k i \alpha_{ki} αki的隐藏层。
- 按照 α k i \alpha_{ki} αki分布对隐藏层进行随机采样获取一个隐藏层
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息,因此最终损失函数与注意力之间的函数关系不可导,因此,无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。
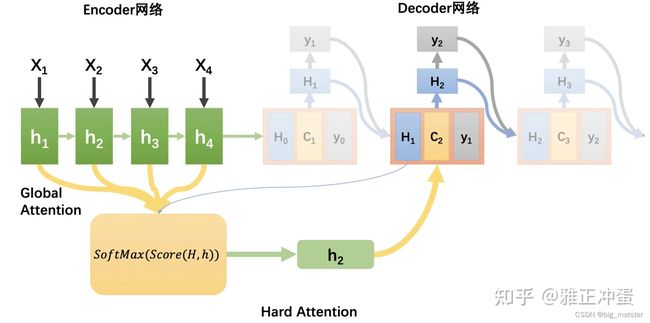
直接随机采样或者最高权重。来设定中间语义向量。
Glboal Attention 与Local Attention
之前了解过的所有attention机制都是Glboal Attention.我们把Encoder网络中的所有输入都带入计算全局对齐权重,作为候选加入 C k C_k Ck,但是如果我们需要翻译的文本是一篇很长的论文,那么大多的输入候选隐藏层可能会降低算法的运行速度。,如果我们可以首先挑选出可能比较有用的一批隐藏层,只对它们进行Attention计算,就可以大大加速算法。如何预选择出比较有用的隐藏层呢,是这样操作的:


下图展示了第二种方式来确定local attention的方法。
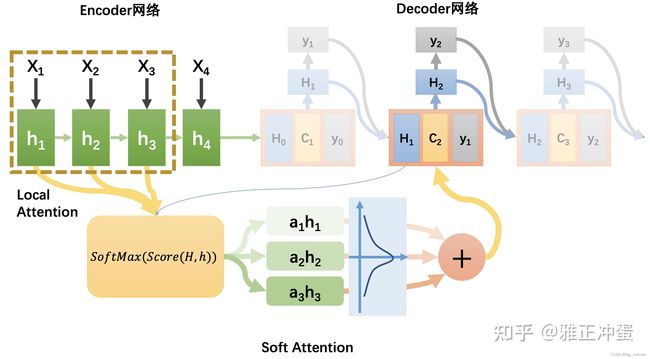
Soft attention
自监督(Self-Attention)英文也有叫Intra- Attention的,简单来说相比于在输出 H k H_k Hk和输入h之间寻找对齐关系的其他Attention方法,Self-Attention可以在一段文本内部寻找不同部分之间的关系来构建这段文本的表征。因此它多用于非seq2seq任务,因为通常Encoder-Decoder网络只能构建在seq2seq任务中,对于非seq2seq问题原先的Attention就没有办法排上用场了。自监督方法非常适合于解决阅读理解,文本摘要和建立文本蕴含关系的任务。

上图显示的就是当算法处理到红色字的表征时,它应该给文中其他文字的表征多大的注意力权重。接下来我们就会学习怎么实现一个Self-Attention过程,不过在此之前,我们需要先切换一下视角。
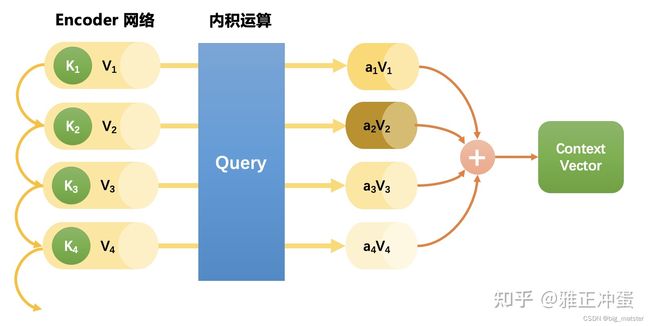
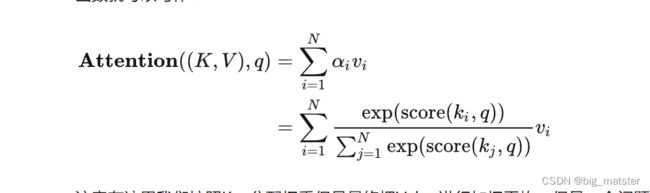
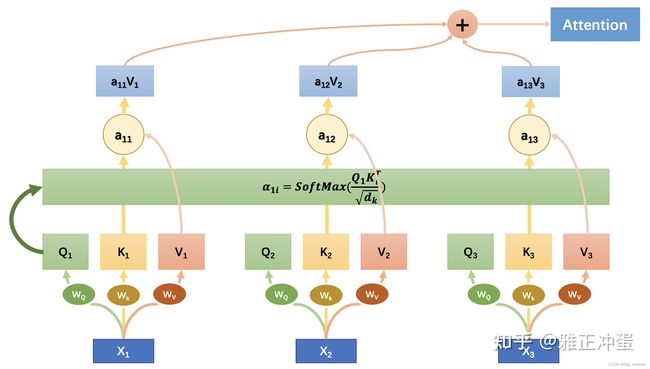
Soft attenion的实现
下面这张制作精美的图很简单地演示了如何计算Self-Attention,图中计算的是处理第一个单词时应该对全文三个单词分别分配多大的注意力:

Attention算法带来的改进
attention机制为机器翻译任务带来的曙光,具体来说,其能够给机器翻译任务带来以下改进:
Attention显著地提高了翻译算法的表现。它可以很好地使Decoder网络注意原文中的某些重要区域来得到更好的翻译。
Attention解决了信息瓶颈问题。原先的Encoder-Decoder网络的中间状态只能存储有限的文本信息,现在它已经从繁重的记忆任务中解放出来了,它只需要完成如何分配注意力的任务即可。
Attention减轻了梯度消失问题。Attention在网络后方到前方建立了连接的捷径,使得梯度可以更好的传递。
Attention提供了一些可解释性。通过观察网络运行过程中产生的注意力的分布,我们可以知道网络在输出某句话时都把注意力集中在哪里;而且通过训练网络,我们还得到了一个免费的翻译词典(soft alignment)!还是如下图所示,尽管我们未曾明确地告诉网络两种语言之间的词汇对应关系,但是显然网络依然学习到了一个大体上是正确的词汇对应表。
各种注意力机制的关键点,都是必须计算某种权重,结合某种网络结构来进行使用。
总结就到这里了,后续计算机回来,慢慢地将各种网络结构都给其搞定都行啦。
并会训练,学习其某种语义表示都行啦的回事与打算。全部都将其搞定都行啦的样子。
慢慢开始搞都行啦的理由!
总结
- 用一个网络进行提取特征,再用一个网络将其解码为序列句子。
- 图像视觉先大概了解其内容,专注其文本分类,不做过多了解。