【论文笔记_知识蒸馏_目标检测_2022】Decoupled Knowledge Distillation

摘要
目前最先进的蒸馏方法主要是基于从中间层蒸馏出深层特征,而对数蒸馏的意义被大大忽略了。为了提供一个研究Logit蒸馏的新观点,我们将经典的KD损失重新表述为两个部分,即目标类知识蒸馏(TCKD)和非目标类知识蒸馏(NCKD)。我们对这两部分的效果进行了实证调查和证明。TCKD传递有关训练样本 "难度 "的知识,而NCKD则是Logit蒸馏法发挥作用的突出原因。更重要的是,我们揭示了经典的KD损失是一个耦合的表述,它(1)抑制了NCKD的有效性,(2)限制了平衡这两部分的灵活性。为了解决这些问题,我们提出了解耦知识蒸馏法(DKD),使TCKD和NCKD能够更有效、更灵活地发挥它们的作用。与复杂的基于特征的方法相比,我们的DKD在CIF AR-100、ImageNet和MSCOCO数据集的图像分类和物体检测任务中取得了相当甚至更好的结果,并具有更好的训练效率。本文证明了logit蒸馏法的巨大潜力,我们希望它对未来的研究有所帮助。
代码地址: https://github.com/megvii-research/mdistiller
1.介绍
在过去的几十年里,计算机视觉领域已经被深度神经网络(DNN)彻底改变,它成功地推动了各种真实场景的任务,例如,图像分类[9,13,21],目标检测[8,27],和语义分割[31,45]。然而,强大的网络通常得益于大的模型容量,引入了高的计算和存储成本。这种成本在工业应用中是不可取的,因为在工业应用中,轻量级的模型被广泛部署。在文献中,削减成本的一个潜在方向是知识蒸馏(KD)。KD代表了一系列集中于将知识从重模型(教师)转移到轻模型(学生)的方法,这可以提高轻模型的性能而不引入额外的成本。

图1. 经典的KD[12]和我们的DKD的说明。我们将KD重新表述为两部分的加权和,即TCKD和NCKD。第一个方程显示,KD(1)将NCKD与pT t(教师对目标类的可信度)耦合,(2)将两部分的重要性耦合。此外,我们还证明,第一个耦合抑制了有效性,第二个耦合限制了知识转移的灵活性。我们提出DKD来解决这些问题,它采用了TCKD的超参数α和NCKD的超参数β,一石二鸟。
KD的概念首先在[12]中提出,通过最小化教师和学生预测对数之间的KL散度来传递知识(图1a)。自[28]以来,大部分的研究注意力被吸引到从中间层的深度特征中提炼知识。与基于logits的方法相比,特征蒸馏的性能在各种任务上都比较优越,所以对logits提炼的研究几乎没有人触及。然而,基于特征的方法的训练成本并不令人满意,因为在训练时间内为提炼深层特征引入了额外的计算和存储用量(如网络模块和复杂操作)。
logits蒸馏需要边际的计算和存储成本,但性能却较差。从直觉上讲,logits蒸馏应该达到与特征蒸馏相当的性能,因为logits比深度特征处于更高的语义水平。我们认为,logit蒸馏法的潜力受到未知原因的限制,导致其性能不尽人意。为了重振基于Logits的方法,我们从深入研究KD的机制开始这项工作。首先,我们把一个分类预测分为两个层次。(1)对目标类和所有非目标类的二元预测;(2)对每个非目标类的多类预测。在此基础上,我们将经典的KD损失[12]重新表述为两个部分,如图1b所示。一个是对目标类的二元logit提炼,另一个是对非目标类的多类别logit提炼。为了简化,我们分别将其命名为目标分类知识蒸馏法(TCKD)和非目标分类知识蒸馏法(NCKD)。重新表述后,我们可以独立研究这两部分的效果。
TCKD通过二元logit蒸馏法转移知识(意思是只看未软化的预测标签和真实标签),这意味着只提供目标类的预测,而每个非目标类的具体预测是未知的。一个合理的假设是,TCKD转移了关于训练样本 "难度 "的知识,也就是说,该知识描述了识别每个训练样本的难度。为了验证这一点,我们从三个方面设计实验来增加训练数据的 “难度”,即更强的增强、更嘈杂的标签和固有的挑战性数据集。
NCKD只考虑非目标Logits中的知识(意思是进行软化后的logits)。有趣的是,我们从经验上证明,只有应用NCKD才能取得与经典KD相当甚至更好的结果,这表明非目标Logits中包含的知识至关重要,这可能是突出的 “暗知识”。
更重要的是,我们的重新表述表明,经典的KD损失是一个高度耦合的表述(如图1b所示),这可能是Logit蒸馏潜力有限的原因。首先,NCKD损失项由一个系数加权,该系数与教师对目标类的预测信心呈负相关。因此,较大的预测分数会导致较小的权重。这种耦合大大抑制了NCKD对预测良好的训练样本的影响。这种抑制是不可取的,因为教师对训练样本越有信心,它可以提供的知识就越可靠和有价值。其次,TCKD和NCKD的意义是耦合的,也就是说,不允许将TCKD和NCKD分开加权。这种限制是不可取的,因为TCKD和NCKD应该分开考虑,因为它们的贡献来自不同方面。
为了解决这些问题,我们提出了一种灵活有效的Logit蒸馏方法,名为解耦知识蒸馏(DKD,图1b)。DKD将NCKD的损失从与教师信心负相关的系数中解耦出来,用一个常数代替,提高了对预测良好的样本的蒸馏效率。同时,NCKD和TCKD也被解耦,因此可以通过调整各部分的权重来分别考虑它们的重要性。
本论文的主要贡献如下:
- 我们通过将经典的KD分为TCKD和NCKD,为研究Logit蒸馏提供了一个深刻的观点。此外,还分别分析和证明了两部分的影响。
- 我们揭示了经典KD损失的局限性是由其高度耦合的表述造成的。将NCKD与教师的信心耦合起来,抑制了知识转移的有效性。将TCKD与NCKD耦合限制了平衡这两部分的灵活性。
3.我们提出了一种有效的名为DKD的Logit蒸馏方法来克服这些限制。DKD在各种任务上实现了最先进的性能。我们还从经验上验证了与基于特征的蒸馏方法相比,DKD具有更高的训练效率和更好的特征转移能力。
2.相关工作
…
3.重新考虑知识蒸馏
在本节中,我们深入探讨了知识蒸馏的机制。我们将KD损失重新表述为两部分的加权和,一部分与目标类相关,另一部分则不相关。我们探讨了知识提炼框架中每个部分的影响,并揭示了经典KD的一些局限性。在研究结果的启发下,我们进一步提出了一种新型的Logit蒸馏方法,在各种任务上取得了显著的性能。
3.1 重新制定KD
符号:对于第t类的训练样本,分类概率可以表示为p = [p1, p2, …, pt, …, pC]∈R1×C,其中p i是第i类的概率,C是类的数量。p中的每个元素都可以通过softmax函数得到:

其中zi代表第i类的logit。
为了区分与目标类相关和不相关的预测,我们定义了以下符号。b = [pt, p\t] ∈ R1×2 代表目标类(pt)和所有其他非目标类(p\t)的二元概率,可以通过以下方式计算:

同时,我们宣布ˆp = [ˆp1, …, ˆpt-1, ˆpt+1, …, ˆpC] ∈R1×(C-1)来独立建立非目标类之间的概率模型(即不考虑第t类)。每个元素的计算方法是:

重新表述:在这部分1中,我们试图用二元概率b和非目标类的概率ˆp来重新表述KD。T和S分别表示教师和学生。经典的KD使用KL散度作为损失函数,它可以写成:

根据公式(1)和公式(2),我们有![]() ,所以我们可以将公式(3)改写为:
,所以我们可以将公式(3)改写为:

然后,等式4可以被写成:

正如等式5所反映的,KD损失是由两部分损失加权和组成的。![]() 代表教师和学生对目标类别的二元概率的相似性。因此,我们将其命名为 “目标类知识蒸馏”(TCKD)。
代表教师和学生对目标类别的二元概率的相似性。因此,我们将其命名为 “目标类知识蒸馏”(TCKD)。![]() 代表教师和学生在非目标类中的概率的相似性,命名为非目标类知识蒸馏(NCKD)。公式(5)可以改写为:
代表教师和学生在非目标类中的概率的相似性,命名为非目标类知识蒸馏(NCKD)。公式(5)可以改写为: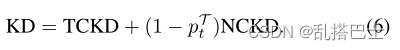
很明显,NCKD的权重是与pTt相联系的。
3.2 TCKD和NCKD的影响
各部分的性能增益。我们分别研究了TCKD和NCKD对CIFAR-100[16]的影响。选择ResNet[9]、WideResNet(WRN)[42]和ShuffleNet[21]作为训练模型,其中考虑了相同和不同的架构。实验结果在表1中报告。对于每个师生对,我们报告了(1)学生基线(传统训练),(2)经典KD(同时使用TCKD和NCKD),(3)单TCKD和(4)单NCKD的结果。每个损失的权重被设置为1.0(包括默认的交叉熵损失)。其他实施细节与第4节中的内容相同。
直观地说,TCKD集中于与目标类有关的知识,因为相应的损失函数只考虑二元概率。相反,NCKD侧重于非目标类的知识。我们注意到,单一应用TCKD可能对学生没有帮助(例如,在ShuffleNet-V1上获得0.02%和0.12%的收益),甚至有害(例如,在WRN-16-2上下降2.30%,在ResNet8×4上下降3.87%)。然而,NCKD的蒸馏性能与经典的KD相当,甚至更好(例如,在ResNet8×4上为1.76%对1.13%)。实验结果表明,目标类相关的知识可能不如非目标类的知识重要。为了深入研究这一现象,我们提供了如下的进一步分析。

表1. 在CIFAR-100验证集上的准确率(%)。∆代表比基线的性能改进。
TCKD传递的是关于训练样本 "难度 "的知识。根据公式(5),TCKD通过二元分类任务传递 “暗知识”,这可能与样本的 "难度 "有关。例如,一个pTt=0.99的训练样本与另一个pTt=0.75的样本相比,对学生来说可能 "更容易 "学习。由于TCKD传达了训练样本的 “难度”,我们认为当训练数据变得具有挑战性时,其有效性就会显现出来。然而,CIFAR-100的训练集很容易适应。因此,教师提供的关于 "难度 "的知识是没有信息的。在这一部分,我们从三个方面进行了实验来验证:训练数据越困难,TCKD就越能提供好处。
(1) 应用强增量是提高训练数据难度的直接方法。我们在CIFAR-100上用AutoAugment[5]训练一个ResNet32×4模型作为教师,取得81.29%的top-1验证准确率。至于学生,我们训练ResNet8×4和ShuffleNetV1模型,有/没有TCKD。表2的结果显示,如果应用强增强,TCKD获得了明显的性能提升。
(2) 噪声标签也会增加训练数据的难度。我们按照[7, 35]的做法,在CIFAR-100上以{0.1, 0.2, 0.3}的对称噪声比率训练ResNet32×4模型作为教师,ResNet8×4作为学生。如表3所示,结果表明,TCKD在较嘈杂的训练数据上取得了更多的性能提升。
(3) 还考虑了具有挑战性的数据集(如ImageNet[29])。表4显示,TCKD在ImageNet上可以带来+0.32%的性能提升。

表2. CIFAR-100验证的准确率(%)。我们设定ResNet32×4为教师,ResNet8×4为学生。教师和学生都是用AutoAugment[5]训练的。
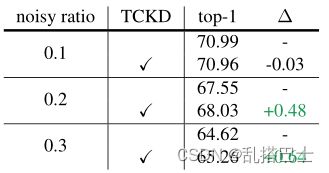
表3. 训练集上不同噪声比例下的CIFAR-100验证的准确率(%)。我们设定ResNet32×4为教师,ResNet8×4为学生。

表4. ImageNet验证的准确率(%)。我们设定ResNet34为教师,ResNet-18为学生。
最后,我们通过试验各种增加训练数据难度的策略(如强增量、噪声标签、困难任务)来证明TCKD的有效性。结果验证了有关训练样本 "难度 "的知识在对更具挑战性的训练数据进行知识提炼时可能会更有益处。
NCKD是Logit蒸馏工作的突出原因,但却被大大抑制了。有趣的是,我们在表1中注意到,当只应用NCKD时,其性能与经典KD相当,甚至比它更好。这表明,非目标类的知识对Logit蒸馏法至关重要,这可能是突出的 “暗知识”。然而,通过回顾公式(5),我们注意到NCKD的损失与(1-pTt)耦合,其中pTt代表教师对目标类的信心。因此,更有信心的预测会导致更小的NCKD权重。我们认为,教师对训练样本越有信心,它能提供的知识就越可靠和有价值。然而,损失权重被这种自信的预测高度压制。我们认为这一事实会限制知识转移的有效性,这首先要归功于我们对公式(5)中KD的重新表述。
我们设计了一个消融实验,以验证预测良好的样本确实比其他样本传递了更好的知识。首先,我们根据pTt对训练样本进行排名,并将其平均分成两个子集。为了清楚起见,一个子集包括pTt排名前50%的样本,而其余的样本则在另一个子集中。然后,我们在每个子集上用NCKD训练学生网络,以比较性能增益(而交叉熵损失仍然是在整个集合上)。表5显示,在前50%的样本上利用NCKD实现了更好的性能,这表明预测良好的样本的知识比其他样本更丰富。然而,预测良好的样本的损失权重被教师的高信心所压制。

表5. 在CIFAR-100验证集上的准确率(%)。我们设定ResNet32×4为教师,ResNet8×4为学生。
3.3解耦的知识蒸馏
到目前为止,我们已经将经典的KD损失重新表述为两个独立部分的加权和,并进一步验证了TCKD的有效性,揭示了NCKD的抑制性。具体来说,TCKD传递了有关训练样本 "难度 "的知识。在更具挑战性的训练数据上,通过TCKD可以获得更明显的改进。NCKD在非目标类之间转移知识,在权重(1-pTt)相对较小的条件下,NCKD会被抑制。
从本能上讲,TCKD和NCKD都是不可缺少的关键。然而,在经典的KD表述中,TCKD和NCKD从以下几个方面结合起来:
1.首先,NCKD是与(1-pTt)耦合的,这可能会抑制NCKD在预测良好的样本上的表现。由于表5中的结果显示,预测良好的样本可以带来更多的性能增益,耦合形式可能会限制NCKD的有效性。
2.另外,在经典的KD框架下,NCKD和TCKD的权重是耦合的。它不允许改变每个部分的权重来平衡其重要性。我们认为TCKD和NCKD应该分开考虑,因为它们的贡献来自不同方面。

受益于我们对KD的重新表述,我们提出了一种新的Logit蒸馏方法,即解耦知识蒸馏(DKD)来解决上述问题。我们提出的DKD在一个解耦公式中独立考虑TCKD和NCKD,如图1b所示。具体来说,我们引入两个超参数α和β,分别作为TCKD和NCKD的权重。DKD的损失函数可以写成如下:
![]()
在DKD中,会抑制NCKD有效性的(1-pTt )被β所取代。更重要的是,允许调整α和β来平衡TCKD和NCKD的重要性。通过对NCKD和TCKD的解耦,DKD为Logit蒸馏提供了一种有效和灵活的方式。算法1以类似PyTorch[24]的方式提供了DKD的伪代码。
4.实验
我们主要在两个有代表性的任务上进行实验,即图像分类和目标检测,包括…:

表6. CIFAR-100的验证结果。教师和学生的架构相同。而∆代表比经典KD的性能改进。所有结果都是5次试验的平均值。
…
5.结论
本文提供了一个新的观点来解释Logit蒸馏法,将经典的KD损失重新表述为两个部分,目标类知识蒸馏(TCKD)和非目标类知识蒸馏(NCKD)。这两部分的效果分别被调查和证明。更重要的是,我们揭示了KD的耦合表述限制了知识转移的有效性和灵活性。为了克服这些问题,我们提出了解耦知识蒸馏法(DKD),它在CIFAR-100、ImageNet和MS-COCO数据集的图像分类和物体检测任务上取得了明显的改进。此外,DKD在训练效率和特征转移性方面的优势也得到了证明。我们希望本文能对未来的Logit提炼研究有所贡献。
限制和未来的工作。值得注意的局限性讨论如下。DKD在物体检测任务上的表现不能超过基于特征的方法(例如ReviewKD[1]),因为基于logits的方法不能传递关于定位的知识。此外,我们在补充文件中提供了一个关于如何调整β的直观指导。然而,蒸馏性能和β之间的严格关联性还没有被充分研究,这将是我们未来的研究方向。