pytorch训练过程可视化(Visdom)
文章目录
- 一、 Visdom介绍
- 二、Visdom安装
- 三、Visdom常用的可视化方式
-
- 1.使用line方式loss可视化
- 2.使用image方式将训练过程中图片可视化
- 3.实时显示预测出的结果和标签
- 代码和可视化结果
-
- 1.训练代码
- 2.训练结果可视化
一、 Visdom介绍
在训练深度学习网络的时候,小伙伴尝试对训练过程可视化很多都会用tensorboard或者tensorboardx,但是这些是针对tensorflow设计的。对于pytorch的用户,使用该包之前还要安装tensorflow,而且训练过程的loss不能动态的查看。在本文中将介绍FaceBook开发的一款开源数据可视化工具Visdom。Visdom因其简单易用的特点,很快成为pytorch的一个数据可视化的工具。除了用来显示loss的可视化,还可以进行更多的可视化展示。
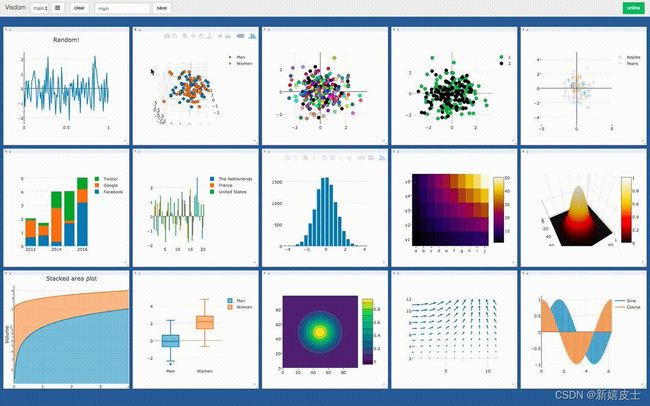
二、Visdom安装
直接使用pip下载
pip install visdom
验证能否正常使用
python -m visdom.server
看到以下结果说明visdom在正常运行
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
三、Visdom常用的可视化方式
1.使用line方式loss可视化
用折线显示训练过程loss变化
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
使用 update = ‘append’,为训练曲线添加点,来让曲线实时增长:
预先设置一个全局计算器:
count = 0
在每个batch或者周期(自定义)完成之后,为训练曲线添加点,来让曲线实时增长:
count = count + 1
viz.line([loss.item()],[count],win='train_loss',update='append')
2.使用image方式将训练过程中图片可视化
在本文中图片大小为512*512(尽量和图片大小一致)
viz.images(img[:1].view(-1,1,512,512),win='x')
3.实时显示预测出的结果和标签
用’[]‘将要显示的字符串包括在一起,用’,'隔开
viz.text(['label:',emotion_label,'predict:',emotion_predict],win='label&predict',opts=dict(titel='pred'))
代码和可视化结果
1.训练代码
本文使用了表情分类算法:https://blog.csdn.net/qq_39450134/article/details/121587376演示使用Visdom可视化训练过程(完整代码见博客):
from numpy.core.numeric import False_
from torch.utils.data import DataLoader,ConcatDataset
from torchvision.transforms import transforms
import numpy as np
from torch import nn,optim
import cv2 as cv
import torch
from torchvision.models import resnet50,resnet152
import argparse
from datasets import Face_Dataset
from tqdm import tqdm
from tensorboardX import SummaryWriter, writer
from visdom import Visdom
device = torch.device("cuda:0"if torch.cuda.is_available() else "cpu")
img_crop_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((512,512)),
transforms.RandomCrop(500),
transforms.Resize((512,512))
])
img_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((512,512))
])
emotion_list = ['afraid','angry','disgust','happy','netural','sad','suprise']
#----------------------------------------#
#学习率调整函数
#----------------------------------------#
def warmup_learning_rate(optimizer,iteration): # warmup函数在上升阶段的预热函数
lr_ini = 0.0001
for param_group in optimizer.param_groups:
param_group['lr'] = lr_ini+(args.initial_lr - lr_ini)*iteration/100
def cosin_deacy(optimizer,lr_base,current_epoch,warmup_epoch,global_epoch): # 余弦退火函数设计
lr_new = 0.5 * lr_base*(1+np.cos(np.pi*(current_epoch - warmup_epoch)/np.float(global_epoch-warmup_epoch)))
for param_group in optimizer.param_groups:
param_group['lr'] = lr_new
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def train(args):
net = nn.Sequential(
# nn.Conv2d(3,3,3,padding=1),
resnet152(),
nn.Linear(1000,100),
nn.Linear(100,7)
)
model = torch.nn.DataParallel(net,device_ids=[0,1])
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(),lr=args.initial_lr)
criterion = torch.nn.CrossEntropyLoss()
# criterion = torch.nn.L1Loss()
# writer = SummaryWriter('./log')
viz = Visdom()
viz.line([0.],[0.],win='train_loss',opts=dict(title='train loss'))
viz.line([[0.],[0.]],[0.],win='test',opts=dict(title='test loss&acc.',legend=['loss','acc.']))
count = 0
for i,epoch in enumerate(range(args.epochs)):
face_data_orign = Face_Dataset(args.train_datasets,img_transforms)
face_data_crop = Face_Dataset(args.train_datasets,img_crop_transforms)
face_data_equ = Face_Dataset(args.train_datasets,imgs_transform=img_crop_transforms,equalize=True)
face_data_con = Face_Dataset(args.train_datasets,imgs_transform=img_crop_transforms,contrast_enhanced=True)
face_data = ConcatDataset([face_data_orign,face_data_crop,face_data_equ,face_data_con])
face_dataloader = DataLoader(
face_data,
batch_size = args.batch_size,
shuffle = True,
num_workers = args.workers,
drop_last = False
)
print('#'+'_'*40+'#')
for img, emotion in tqdm(face_dataloader):
img = img.to(device)
img = img.type(torch.FloatTensor)
emotion = emotion.to(device)
out = model(img)
loss = criterion(out,emotion.squeeze())
loss.backward()
optimizer.step()
optimizer.zero_grad()
if epoch == args.warmup_epoch:
lr_base = optimizer.state_dict()['param_groups'][0]['lr']
if epoch >= args.warmup_epoch:
cosin_deacy(optimizer, lr_base, epoch,args.warmup_epoch, args.epochs)
viz.images(img[:1].view(-1,1,512,512),win='x')
count = count + 1
viz.line([loss.item()],[count],win='train_loss',update='append')
emotion_label = emotion[0].detach().cpu().numpy()
emotion_label = emotion_list[int(emotion_label[0])]
emotion_predict = out[0].detach().cpu().numpy()
emotion_predict = np.where(emotion_predict == np.max(emotion_predict))
emotion_predict = emotion_list[int(emotion_predict[0])]
viz.text(['label:',emotion_label,'predict:',emotion_predict],win='label&predict',opts=dict(titel='pred'))
writer.add_scalar('train_loss',loss/args.batch_size,global_step=epoch)
print('epoch:{0},train_loss:{1},learning_rate:{2}'.format(epoch+1,round(loss.item()/args.batch_size,6),round(optimizer.state_dict()['param_groups'][0]['lr'],6)))
torch.save(model.state_dict(),'{0}EMC{1}_Resnet152.pth'.format(args.weights,epoch+1))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--workers',default=16,type=int)
parser.add_argument('--initial_lr',default=0.0001,type=float)
parser.add_argument('--epochs',default=50,type=int)
parser.add_argument('--warmup_epoch',default=20,type=int)
parser.add_argument('--batch_size',default=10,type=int)
parser.add_argument('--weights',default="./weights/",type=str)
parser.add_argument('--train_datasets',default='./data/KDEF_ORDER_TRAIN/',type=str)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
train(args)
2.训练结果可视化
如果感觉有用,麻烦各位大佬点个赞,谢谢,best wishes!