Pytorch 转ONNX详解
Pytorch 转ONNX详解
文章目录
- Pytorch 转ONNX详解
-
- 模型部署
-
- torch.onnx.export
-
- 计算图导出方法
- 参数解释
- PyTorch对ONNX的算子支持
- 附录
-
- 中间表示
- 计算图
-
- 张量和算子
- 静态图和动态图
- 参考
模型部署
模型部署是让训练好的深度学习模型在特定环境中运行的过程。深度学习模型通常在深度学习框架(比如,Pytorch和TensorFl)下训练得到,这些深度学习框架依赖较多,规模较大,不适合在生产环境中安装;通常深度学习模型需要大量的算力才能满足实时运行需求,因此,需要优化模型的运行效率。总结一下,模型部署面临两大问题,如何让开发者不受开发框架的限制和如何提升模型的运算效率。
经过工业界和学术界数年的探索,一般流行的模型部署流水线是:
- 首先开发者们在任意一种深度学习框架下定义网络结构,训练得到网络参数
- 然后,将模型的结构和参数转换成一种只描述网络结构的中间表示。针对网络结构的优化会在这步进行。ONNX就是一种模型中间表示。
- 最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写能高效执行深度学习网络中算子的推理引擎,推理引擎将中间表示转换成特定的文件格式,并在对应硬件平台上高效运行。常见的推理引擎有ONNX Runtime,TensorRT,ncnn ,openppl,OpenVINO等等。
torch.onnx.export
torch.onnx.export是PyTorch自带的将模型转换成ONNX的函数。下述一段代码描述了如何使用torch.onnx.export将pytorch模型转换成onnx格式的模型。torch.onnx.export中的三个默认参数是模型、模型的输入和导出的onnx文件名。那么模型转换时,为什么要给模型提供一组输入呢?
# 将pytorch模型转换成onnx格式的模型
x = torch.randn(1, 3, 256, 256) # 随机输入
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 随机一组输入
"srcnn.onnx", # 导出的onnx文件名称
opset_version=11, # ONNX算子集版本
input_names=['input'], # 输入tensor的名称
output_names=['output']) # 输出tensor的名称
计算图导出方法
TorchScript 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个torch.nn.Module模型会被转换成 TorchScript 的torch.jit.ScriptModule模型。把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);脚本化则能通过解析模型来正确记录所有的控制流。
对于一个有循环的模型,参数 n n n控制输入张量被卷积的次数。由于静态图难以描述控制流,直接对其引入控制语句会导致不同的计算图。使用跟踪法,不同的 n n n得到的不同的ONNX模型结构;使用脚本化,最终的 ONNX 模型用 Loop 节点来表示循环。这样哪怕对于不同的 n,ONNX 模型也有同样的结构。
torch.onnx.export默认使用跟踪的方法导出ONNX模型,给定一组随机数据,上述代码中的参数 x x x,实际执行一遍模型,把这组输入对应的计算图记录下来,保存为ONNX格式。由于推理引擎对静态图的支持更好,通常在模型部署时,不需要显式地把PyTorch模型转换成TorchScript模型,直接把PyTorch模型用torch.onnx.export函数跟踪导出即可。

参数解释
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL, input_names=None, output_names=None, aten=False, export_raw_ir=False, operator_export_type=None, opset_version=None, _retain_param_name=True, do_constant_folding=True, example_outputs=None, strip_doc_string=True, dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None, enable_onnx_checker=True, use_external_data_format=False):
- export_params:ONNX使用同一个文件表示记录模型的结构和权重的。部署时,一般默认为True。
- input_names, outputs_names:设置输入和输出张量的名称。如果不设置,会自动分配一些简单的名字
- dynamic_axes: 指定输入输出张量的哪些维度是动态的。ONNX 默认所有参与运算的张量都是静态的。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。
# 定义第二维第三维动态
dynamic_axes_23 = {
'in' : [2, 3],
'out' : [2, 3]
}
# 导出ONNX模型,无动态维度。
torch.onnx.export(model, dummy_input, model_names[0],
input_names=['in'], output_names=['out'])
# 导出ONNX模型,第二维第三维动态。
torch.onnx.export(model, dummy_input, model_names[2],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
PyTorch对ONNX的算子支持
PyTorch转ONNX时最容易出现的问题就是算子不兼容。在转换普通的torch.nn.Module模型时, PyTorch一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch还会把遇到的每个算子翻译成ONNX中定义的算子。
- 该算子可以一对一地翻译成一个 ONNX 算子。
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
- 该算子没有定义翻译成 ONNX 的规则,报错。
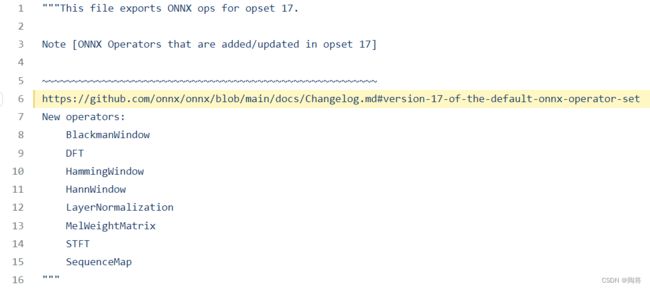
PyTorch 算子是向 ONNX 对齐的, ONNX 算子的定义情况都可以在官方的算子文档中查看(见参考6)。在PyTorch中,和ONNX有关的定义全部放在torch.onnx目录下(https://github.com/pytorch/pytorch/tree/master/torch/onnx). 其中symbloic_opset{n}.py(符号表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容。 目前最高是第17版本。在第17版本中新增加了LN,DFT,STFT等算子。
附录
中间表示
**中间表示(IR),**是编译器用于表示源代码的数据结构或代码,是程序编译过程中介于源语言和目标语言之间的程序表示。几乎所有的编译器都需要某种形式的中间表示,来对被分析、转换和优化的代码进行建模。在编译过程中,**中间表示必须具备足够的表达力,在不丢失信息的情况下准确表达源代码,**并且充分考虑从源代码到目标代码编译的完备性、编译优化的易用性和性能。
引入中间表示后,中间表示既能面向多个前端,表达多种源程序语言,又能对接多个后端,连接不同目标机器。在此基础上,编译流程就可以在前后端直接增加更多的优化流程,这些优化流程以现有IR为输入,又以新生成的IR为输出,被称为优化器。优化器负责分析并改进中间表示,极大程度地提高了编译流程的可拓展性,也降低了优化流程对前端和后端的破坏。

计算图
计算图是用来表示深度学习网络模型在训练与推理过程中计算逻辑与状态的工具。计算框架在后端会将前端语言构建的神经网络模型前向计算与反向梯度计算以计算图的形式来进行表示。计算图由**基本数据结构:张量(Tensor)和基本运算单元:算子(Operator)**构成。在计算图中通常使用节点来表示算子,节点间的有向线段来表示张量状态,同时也描述了计算间的依赖关系。

张量和算子
计算图中,张量是基本数据结构,数学定义中的张量是基于向量与矩阵的推广,涵盖标量、向量与矩阵的概念。在计算框架中张量不仅存储数据,还存储数据类型、数据形状、维度或秩以及梯度传递状态等多个属性。
算子是基本运算单元,算子按照功能可以分成张量操作、神经网络操作、数据流操作和控制流操作。
- 张量操作:包括张量的结构操作(创建、索引切片、维度变换和合并分割)和张量的数学运算(标量运算、向量运算和矩阵运算)
- 神经网络操作:包括特征提取(卷积操作)、激活函数、损失函数、优化算法等
- 数据流操作:包含数据的预处理与数据载入相关算子,数据预处理算子主要是针对图像数据和文本数据的裁剪填充、归一化、数据增强等操作。
- 控制流操作:可以控制计算图中的数据流向。使用频率比较高的控制流算子有条件运算符和循环运算符
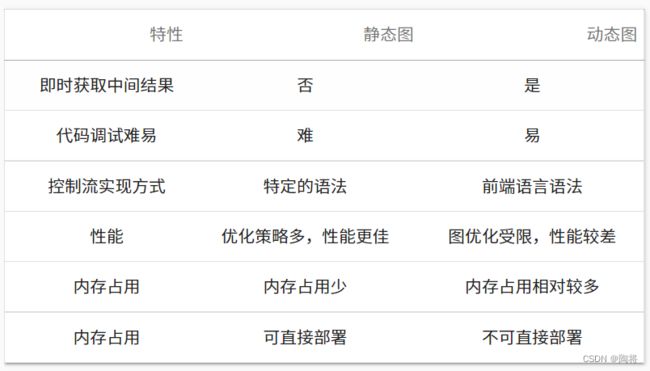
静态图和动态图
- 静态生成可以根据前端语言描述的神经网络拓扑结构以及参数变量等信息构建一份固定的计算图,因此静态图在执行期间可以不依赖前端语言描述,常用于神经网络模型的部署。
- 动态图则需要在每一次执行神经网络模型依据前端语言描述动态生成一份临时的计算图,这意味着计算图的动态生成过程灵活可变,该特性有助于我们在神经网络结构调整阶段提高效率
参考
- 第一章:模型部署简介
- 第二章:解决模型部署中的难题
- 第三章:PYTORCH 转 ONNX 详解
- 中间表示
- 计算图
- 算子文档