卷积神经网络超详细介绍
- 1、卷积神经网络的概念
- 2、 发展过程
- 3、如何利用CNN实现图像识别的任务
- 4、CNN的特征
- 5、CNN的求解
- 6、卷积神经网络注意事项
- 7、CNN发展综合介绍
- 8、LeNet-5结构分析
- 9、AlexNet
- 10、ZFNet
-
- 10.1 意义
- 10.2 实现方法
- 10.3 训练细节
- 10.4 卷积网络可视化
- 10.6 总结
- 11、VGGNet
-
- 11.1 结构
- 11.2 网络特点:
- 11.3 分类框架:
- 12、GoogLeNet
-
- 12.1 GoogLeNet Inception V1——22层
- 12.2 GoogLeNet
- 12.3 GoogleNet Inception V2
- 12.4 GoogLeNet Inception V3
-
- 12.4.1 简介
- 12.4.2 一般情况的设计准则
- 12.4.3 利用大尺度滤波器进行图像的卷积
- 13、ResNet
-
- 13.1 ResNet的提出
- 13.2 ResNet的意义
- 13.3 ResNet结构
- 13.4 ResNet50和ResNet101
- 13.5 基于ResNet101的Faster RCNN
- 14、区域 CNN:R-CNN(2013年)、Fast R-CNN(2015年)、Faster R-CNN(2015年)
- 15、生成式对抗网络
- 16、深度学习在计算机视觉上的应用
- 17、深度有监督学习在计算机视觉领域的进展
-
- 17.1 图像分类
- 17.2 图像检测(Image Dection)
- 17.4 图像标注–看图说话(Image Captioning)
- 18、强化学习(Reinforcement Learning)
1、卷积神经网络的概念
计算机视觉和 CNN 发展十一座里程碑
上世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究,提出了感受野这个概念,到80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
卷积神经网络是多层感知机(MLP)的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来,视觉皮层的细胞存在一个复杂的构造,这些细胞对视觉输入空间的子区域非常敏感,称之为感受野。
CNN由纽约大学的Yann Lecun于1998年提出,其本质是一个多层感知机,成功的原因在于其所采用的局部连接和权值共享的方式:
-
一方面减少了权值的数量使得网络易于优化
-
另一方面降低了模型的复杂度,也就是减小了过拟合的风险
该优点在网络的输入是图像时表现的更为明显,使得图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程,在二维图像的处理过程中有很大的优势,如网络能够自行抽取图像的特征包括颜色、纹理、形状及图像的拓扑结构,在处理二维图像的问题上,特别是识别位移、缩放及其他形式扭曲不变性的应用上具有良好的鲁棒性和运算效率等。
| 名称 | 特点 |
|---|---|
| LeNet5 | 没啥特点-不过是第一个CNN应该要知道 |
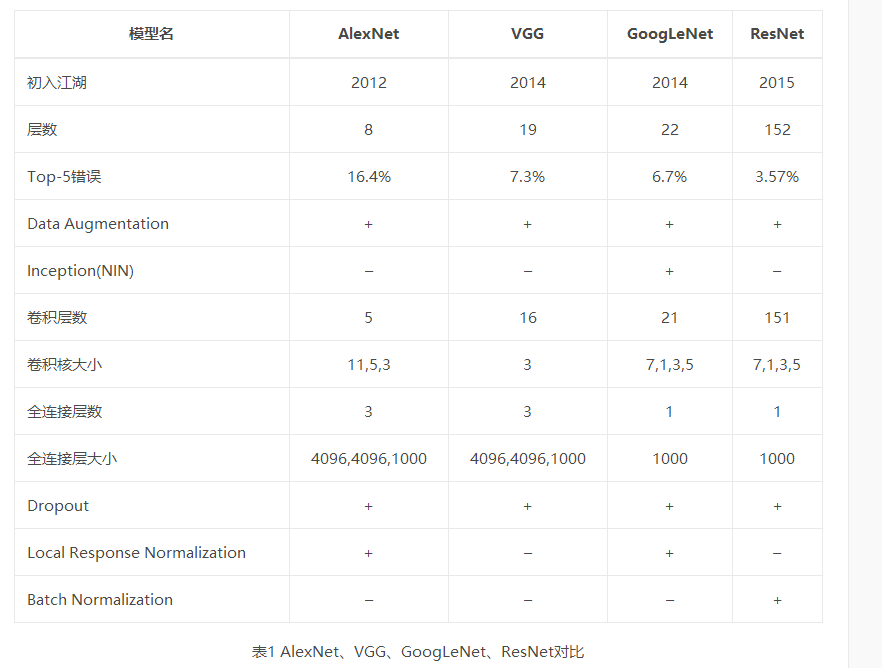
| AlexNet | 引入了ReLU和dropout,引入数据增强、池化相互之间有覆盖,三个卷积一个最大池化+三个全连接层 |
| VGGNet | 采用11和33的卷积核以及2*2的最大池化使得层数变得更深。常用VGGNet-16和VGGNet19 |
| Google Inception Net | 这个在控制了计算量和参数量的同时,获得了比较好的分类性能,和上面相比有几个大的改进:1、去除了最后的全连接层,而是用一个全局的平均池化来取代它; 2、引入Inception Module,这是一个4个分支结合的结构。所有的分支都用到了11的卷积,这是因为11性价比很高,可以用很少的参数达到非线性和特征变换。3、Inception V2第二版将所有的55变成2个33,而且提出来著名的Batch Normalization;4、Inception V3第三版就更变态了,把较大的二维卷积拆成了两个较小的一维卷积,加速运算、减少过拟合,同时还更改了Inception Module的结构。 |
| 微软ResNet残差神经网络(Residual Neural Network) | 1、引入高速公路结构,可以让神经网络变得非常深2、ResNet第二个版本将ReLU激活函数变成y=x的线性函数 |
2、 发展过程
1986年Rumelhart等人提出了人工神经网络的反向传播算法,掀起了神经网络在机器学习中的热潮,神经网络中存在大量的参数,存在容易发生过拟合、训练时间长的缺点,但是对比Boosting、Logistic回归、SVM等基于统计学习理论的方法(也可以看做具有一层隐层节点或不含隐层节点的学习模型,被称为浅层模型)来说,具有较大的优越性。
浅层模型为什么效果没有深层模型好?
浅层学习模型通常要由人工的方法来获得好的样本特性,在此基础上进行识别和预测,因此方法的有效性在很大程度上受到特征提取的制约。
深度学习的提出:
2006年,Hinton提出了深度学习,两个主要的观点是:
-
多隐层的人工神经网络具有优异的特征学习能力,学习到的数据更能反映数据的本质特征有利于可视化或分类
-
深度神经网络在训练上的难度,可以通过逐层无监督训练有效克服,
深度学习取得成功的原因:
-
大规模数据(例如ImageNet):为深度学习提供了好的训练资源
-
计算机硬件的飞速发展:特别是GPU的出现,使得训练大规模上网络成为可能
深度学习的思想:
深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。
什么是卷积神经网络:
卷积神经网络是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,其三个关键的操作,其一是局部感受野,其二是权值共享,其三是pooling层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
1)网络结构
**卷积神经网络整体架构:**卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。该网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。卷积神经网络的低隐层是由卷积层和最大池采样层交替组成,高层是全连接层对应传统多层感知器的隐含层和逻辑回归分类器。第一个全连接层的输入是由卷积层和子采样层进行特征提取得到的特征图像。最后一层输出层是一个分类器,可以采用逻辑回归,Softmax回归甚至是支持向量机对输入图像进行分类。
卷积神经网络结构包括:卷积层,降采样层,全链接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。
输入图像统计和滤波器进行卷积之后,提取该局部特征,一旦该局部特征被提取出来之后,它与其他特征的位置关系也随之确定下来了,每个神经元的输入和前一层的局部感受野相连,每个特征提取层都紧跟一个用来求局部平均与二次提取的计算层,也叫特征映射层,网络的每个计算层由多个特征映射平面组成,平面上所有的神经元的权重相等。
通常将输入层到隐藏层的映射称为一个特征映射,也就是通过卷积层得到特征提取层,经过pooling之后得到特征映射层。
2)局部感受野与权值共享
卷积神经网络的核心思想就是局部感受野、是权值共享和pooling层,以此来达到简化网络参数并使得网络具有一定程度的位移、尺度、缩放、非线性形变稳定性。
-
局部感受野:由于图像的空间联系是局部的,每个神经元不需要对全部的图像做感受,只需要感受局部特征即可,然后在更高层将这些感受得到的不同的局部神经元综合起来就可以得到全局的信息了,这样可以减少连接的数目。
-
权值共享:不同神经元之间的参数共享可以减少需要求解的参数,使用多种滤波器去卷积图像就会得到多种特征映射。权值共享其实就是对图像用同样的卷积核进行卷积操作,也就意味着第一个隐藏层的所有神经元所能检测到处于图像不同位置的完全相同的特征。其主要的能力就能检测到不同位置的同一类型特征,也就是卷积网络能很好的适应图像的小范围的平移性,即有较好的平移不变性(比如将输入图像的猫的位置移动之后,同样能够检测到猫的图像)
3)卷积层、下采样层、全连接层
卷积层:因为通过卷积运算我们可以提取出图像的特征,通过卷积运算可以使得原始信号的某些特征增强,并且降低噪声。
- 用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置bx,得到卷积层Cx。
下采样层:因为对图像进行下采样,可以减少数据处理量同时保留有用信息,采样可以混淆特征的具体位置,因为某个特征找出来之后,它的位置已经不重要了,我们只需要这个特征和其他特征的相对位置,可以应对形变和扭曲带来的同类物体的变化。
- 每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。 **
全连接层:采用softmax全连接,得到的激活值即卷积神经网络提取到的图片特征。
卷积神经网络相比一般神经网络在图像理解中的优点:
- 网络结构能够较好的适应图像的结构
- 同时进行特征提取和分类,使得特征提取有助于特征分类
- 权值共享可以减少网络的训练参数,使得神经网络结构变得简单,适应性更强
3、如何利用CNN实现图像识别的任务
输入层读入经过规则化(统一大小)的图像,每一层的每个神经元将前一层的一组小的局部近邻的单元作为输入,也就是局部感受野和权值共享,神经元抽取一些基本的视觉特征,比如边缘、角点等,这些特征之后会被更高层的神经元所使用。卷积神经网络通过卷积操作获得特征图,每个位置,来自不同特征图的单元得到各自不同类型的特征。一个卷积层中通常包含多个具有不同权值向量的特征图,使得能够保留图像更丰富的特征。卷积层后边会连接池化层进行降采样操作,一方面可以降低图像的分辨率,减少参数量,另一方面可以获得平移和形变的鲁棒性。卷积层和池化层的交替分布,使得特征图的数目逐步增多,而且分辨率逐渐降低,是一个双金字塔结构。
4、CNN的特征
1)具有一些传统技术所没有的优点:良好的容错能力、并行处理能力和自学习能力,可处理环境信息复杂,背景知识不清楚,推理规则不明确情况下的问题,允许样品有较大的缺损、畸变,运行速度快,自适应性能好,具有较高的分辨率。它是通过结构重组和减少权值将特征抽取功能融合进多层感知器,省略识别前复杂的图像特征抽取过程。
2)泛化能力要显著优于其它方法,卷积神经网络已被应用于模式分类,物体检测和物体识别等方面。利用卷积神经网络建立模式分类器,将卷积神经网络作为通用的模式分类器,直接用于灰度图像。
3)是一个前溃式神经网络,能从一个二维图像中提取其拓扑结构,采用反向传播算法来优化网络结构,求解网络中的未知参数。
4)一类特别设计用来处理二维数据的多层神经网络。CNN被认为是第一个真正成功的采用多层层次结构网络的具有鲁棒性的深度学习方法。CNN通过挖掘数据中的空间上的相关性,来减少网络中的可训练参数的数量,达到改进前向传播网络的反向传播算法效率,因为CNN需要非常少的数据预处理工作,所以也被认为是一种深度学习的方法。在CNN中,图像中的小块区域(也叫做“局部感知区域”)被当做层次结构中的底层的输入数据,信息通过前向传播经过网络中的各个层,在每一层中都由过滤器构成,以便能够获得观测数据的一些显著特征。因为局部感知区域能够获得一些基础的特征,比如图像中的边界和角落等,这种方法能够提供一定程度对位移、拉伸和旋转的相对不变性。
5)CNN中层次之间的紧密联系和空间信息使得其特别适用于图像的处理和理解,并且能够自动的从图像抽取出丰富的相关特性。
6)CNN通过结合局部感知区域、共享权重、空间或者时间上的降采样来充分利用数据本身包含的局部性等特征,优化网络结构,并且保证一定程度上的位移和变形的不变性。
7)CNN是一种深度的监督学习下的机器学习模型,具有极强的适应性,善于挖掘数据局部特征,提取全局训练特征和分类,它的权值共享结构网络使之更类似于生物神经网络,在模式识别各个领域都取得了很好的成果。
8) CNN可以用来识别位移、缩放及其它形式扭曲不变性的二维或三维图像。CNN的特征提取层参数是通过训练数据学习得到的,所以其避免了人工特征提取,而是从训练数据中进行学习;其次同一特征图的神经元共享权值,减少了网络参数,这也是卷积网络相对于全连接网络的一大优势。共享局部权值这一特殊结构更接近于真实的生物神经网络使CNN在图像处理、语音识别领域有着独特的优越性,另一方面权值共享同时降低了网络的复杂性,且多维输入信号(语音、图像)可以直接输入网络的特点避免了特征提取和分类过程中数据重排的过程。
9)CNN的分类模型与传统模型的不同点在于其可以直接将一幅二维图像输入模型中,接着在输出端即给出分类结果。其优势在于不需复杂的预处理,将特征抽取,模式分类完全放入一个黑匣子中,通过不断的优化来获得网络所需参数,在输出层给出所需分类,网络核心就是网络的结构设计与网络的求解。这种求解结构比以往多种算法性能更高。
10)隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。隐层的神经元个数,它和原图像,也就是输入的大小(神经元个数)、滤波器的大小和滤波器在图像中的滑动步长都有关。
5、CNN的求解
CNN在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
卷积网络执行的是监督训练,所以其样本集是由形如:**(输入向量,理想输出向量)**的向量对构成的。所有这些向量对,都应该是来源于网络即将模拟系统的实际“运行”结构,它们可以是从实际运行系统中采集来。
1)参数初始化:
在开始训练前,所有的权都应该用一些不同的随机数进行初始化。“小随机数”用来保证网络不会因权值过大而进入饱和状态,从而导致训练失败;“不同”用来保证网络可以正常地学习。实际上,如果用相同的数去初始化权矩阵,则网络无学习能力。
2)训练过程包括四步
① 第一阶段:前向传播阶段
-
从样本集中取一个样本,输入网络
-
计算相应的实际输出;在此阶段信息从输入层经过逐级的变换,传送到输出层,这个过程也是网络在完成训练之后正常执行时执行的过程
② 第二阶段:后向传播阶段
-
计算实际输出与相应的理想输出的差
-
按照极小化误差的方法调整权值矩阵
网络的训练过程如下:
-
选定训练组,从样本集中分别随机地寻求N个样本作为训练组;
-
将各权值、阈值,置成小的接近于0的随机值,并初始化精度控制参数和学习率;
-
从训练组中取一个输入模式加到网络,并给出它的目标输出向量;
-
计算出中间层输出向量,计算出网络的实际输出向量;
-
将输出向量中的元素与目标向量中的元素进行比较,计算出输出误差;对于中间层的隐单元也需要计算出误差;
-
依次计算出各权值的调整量和阈值的调整量;
-
调整权值和调整阈值;
-
当经历M后,判断指标是否满足精度要求,如果不满足,则返回(3),继续迭代;如果满足就进入下一步;
-
训练结束,将权值和阈值保存在文件中。这时可以认为各个权值已经达到稳定,分类器已经形成。再一次进行训练,直接从文件导出权值和阈值进行训练,不需要进行初始化。
6、卷积神经网络注意事项
1)数据集的大小和分块
数据驱动的模型一般依赖于数据集的大小,CNN和其他经验模型一样,能够适用于任意大小的数据集,但用于训练的数据集应该足够大, 能够覆盖问题域中所有已知可能出现的问题,
设计CNN的时候,数据集应该包含三个子集:训练集、测试集、验证集
训练集:包含问题域中的所有数据,并在训练阶段用来调整网络的权重
测试集:在训练的过程中用于测试网络对训练集中未出现的数据的分类性能,根据网络在测试集上的性能情况,网络的结构可能需要作出调整,或者增加训练循环次数。
验证集:验证集中的数据统一应该包含在测试集和训练集中没有出现过的数据,用于在网络确定之后能够更好的测试和衡量网络的性能
Looney等人建议,数据集中65%的用于训练,25%的用于测试,10%用于验证
2)数据预处理
为了加速训练算法的收敛速度,一般都会采用一些数据预处理技术,其中包括:去除噪声、输入数据降维、删除无关数据等。
数据的平衡化在分类问题中异常重要,一般认为训练集中的数据应该相对于标签类别近似于平均分布,也就是每一个类别标签所对应的数据集在训练集中是基本相等的,以避免网络过于倾向于表现某些分类的特点。
为了平衡数据集,应该移除一些过度富余的分类中的数据,并相应补充一些相对样例稀少的分类中的数据。
还有一个方法就是复制一部分这些样例稀少分类中的数据,并在这些数据中加入随机噪声。
3)数据规则化
将数据规则化到统一的区间(如[0,1])中具有很重要的优点:防止数据中存在较大数值的数据造成数值较小的数据对于训练效果减弱甚至无效化,一个常用的方法是将输入和输出数据按比例调整到一个和激活函数相对应的区间。
4)网络权值初始化
CNN的初始化主要是初始化卷积层和输出层的卷积核(权值)和偏置
网络权值初始化就是将网络中的所有连接权重赋予一个初始值,如果初始权重向量处在误差曲面的一个相对平缓的区域的时候,网络训练的收敛速度可能会很缓慢,一般情况下网络的连接权重和阈值被初始化在一个具有0均值的相对小的区间内均匀分布。
5)BP算法的学习速率
如果学习速率选取的较大,则会在训练过程中较大幅度的调整权值w,从而加快网络的训练速度,但是这和造成网络在误差曲面上搜索过程中频繁抖动,且有可能使得训练过程不能收敛。
如果学习速率选取的较小,能够稳定的使得网络逼近于全局最优点,但也可能陷入一些局部最优,并且参数更新速度较慢。
自适应学习率设定有较好的效果。
6)收敛条件
有几个条件可以作为停止训练的判定条件,训练误差、误差梯度、交叉验证等。一般来说,训练集的误差会随着网络训练的进行而逐步降低。
7)训练方式
训练样例可以有两种基本的方式提供给网络训练使用,也可以是两者的结合:逐个样例训练(EET)、批量样例训练(BT)。
在EET中,先将第一个样例提供给网络,然后开始应用BP算法训练网络,直到训练误差降低到一个可以接受的范围,或者进行了指定步骤的训练次数。然后再将第二个样例提供给网络训练。
EET的优点是相对于BT只需要很少的存储空间,并且有更好的随机搜索能力,防止训练过程陷入局部最小区域。
EET的缺点是如果网络接收到的第一个样例就是劣质(有可能是噪音数据或者特征不明显)的数据,可能使得网络训练过程朝着全局误差最小化的反方向进行搜索。
相对的,BT方法是在所有训练样例都经过网络传播后才更新一次权值,因此每一次学习周期就包含了所有的训练样例数据。
BT方法的缺点也很明显,需要大量的存储空间,而且相比EET更容易陷入局部最小区域。
而随机训练(ST)则是相对于EET和BT一种折衷的方法,ST和EET一样也是一次只接受一个训练样例,但只进行一次BP算法并更新权值,然后接受下一个样例重复同样的步骤计算并更新权值,并且在接受训练集最后一个样例后,重新回到第一个样例进行计算。
ST和EET相比,保留了随机搜索的能力,同时又避免了训练样例中最开始几个样例如果出现劣质数据对训练过程的过度不良影响。
7、CNN发展综合介绍
CNN的开山之作是LeCun提出的LeNet-5,而其真正的爆发阶段是2012年AlexNet取得ImageNet比赛的分类任务的冠军,并且分类准确率远远超过利用传统方法实现的分类结果,该模型能够取得成功的原因主要有三个:
- 海量的有标记的训练数据,也就是李飞飞团队提供的大规模有标记的数据集ImageNet
- 计算机硬件的支持,尤其是GPU的出现,为复杂的计算提供了强大的支持
- 算法的改进,包括网络结构加深、数据增强(数据扩充)、ReLU、Dropout等
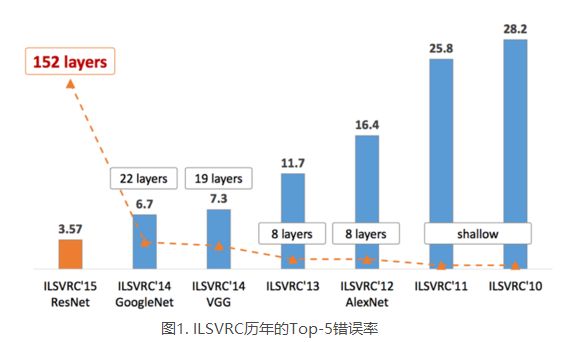
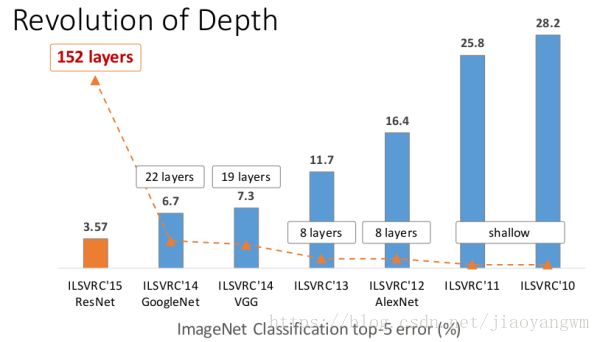
AlexNet之后,深度学习便一发不可收拾,分类准确率每年都被刷榜,下图展示了模型的变化情况,随着模型的变深,Top-5的错误率也越来越低,目前已经降低到了3.5%左右,同样的ImageNet数据集,人眼的辨识错误率大概为5.1%,也就是深度学习的识别能力已经超过了人类。
8、LeNet-5结构分析
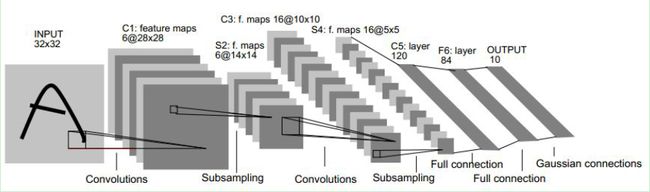
LeNet-5共包含8层
-
C1层是一个卷积层,由6个特征图Feature Map构成。特征图中每个神经元与输入为55的邻域相连。特征图的大小为2828,这样能防止输入的连接掉到边界之外(32-5+1=28)。C1有156个可训练参数(每个滤波器55=25个unit参数和一个bias参数,一共6个滤波器,共(55+1)6=156个参数),共156(28*28)=122,304个连接。
-
S2层是一个下采样层,有6个1414的特征图。特征图中的每个单元与C1中相对应特征图的22邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。每个单元的22感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12(6(1+1)=12)个可训练参数和5880(1414(2*2+1)*6=5880)个连接。
-
C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。 C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。
例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516(6*(325+1)+6(425+1)+3(425+1)+(256+1)=1516)个可训练参数和151600(10101516=151600)个连接。
-
S4层是一个下采样层,由16个55大小的特征图构成。特征图中的每个单元与C3中相应特征图的22邻域相连接,跟C1和S2之间的连接一样。S4层有32个可训练参数(每个特征图1个因子和一个偏置16*(1+1)=32)和2000(16*(2*2+1)55=2000)个连接。
-
C5层是一个卷积层,有120个特征图。每个单元与S4层的全部16个单元的55邻域相连。由于S4层特征图的大小也为55(同滤波器一样),故C5特征图的大小为11(5-5+1=1):这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比11大。C5层有48120(120*(1655+1)=48120由于与全部16个单元相连,故只加一个偏置)个可训练连接。
-
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164(84*(120*(1*1)+1)=10164)个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
-
最后,输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
1、输入层:N个32x32的训练样本
输入图像大小为32x32,比MNIST数据库中的字母大,这样做的原因是希望潜在的明显特征,如笔画断点或角点能够出现在最高层特征监测子感受野的中心。
2、C1层
- 输入图像大小:32x32
- 卷积核大小:5x5
- 卷积核个数:6
- 输出特征图数量:6
- 输出特征图大小:28x28(32-5+1)
- 神经元数量:4707(28x28x6)
- 连接数:122304((28x28x5x5x6)+(28x28x6))
- 可训练参数:156(5x5x6+6,权值+偏置)
3、S2层
- 输入图像大小:(28x28x6)
- 卷积核大小:2x2
- 卷积核个数:6
- 输出特征图数量:6
- 输出特征图大小:14x14(28/2,28/2)
- 神经元数量:1176(14x14x6)
- 连接数:5880((2x2x14x14x6)+(14x14x6))
- 可训练参数:12(1x6+6,权值+偏置)
备注:S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。
如果系数比较小,那么运算近似于线性运算,下采样相当于模糊图像。
如果系数比较大,根据偏置的大小下采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。
每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。
4、C3层
- 输入图像大小:(14x14x6)
- 卷积核大小:5x5
- 卷积核个数:16
- 输出特征图数量:16
- 输出特征图大小:10x10(14-5+1)
- 神经元数量:1600(10x10x16)
- 连接数:151600(1516x10x10)
- 可训练参数:1516
备注:C3层也是一个卷积层,通过5x5的卷积核去卷积S2层,然后得到的特征图map就有10x10个神经元,但是有16种不同的卷积核,就存在16个不同的特征map。
C3中每个特征图由S2中的所有6个或几个特征图组合而成,为什么不把S2中的所有特征图都连接到C3的特征图呢:
- 第一,不完全的连接机制将连接的数量保持在合理的范围内
- 第二,也是最重要的,这样一来就可以破坏网络的对称性,由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征。
5、S4层
- 输入图像大小:(10x10x16)
- 卷积核大小:2x2
- 卷积核个数:16
- 输出特征图数量:16
- 输出特征图大小:5x5x16
- 神经元数量:400(5x5x16)
- 连接数:2000((2x2x5x5x16)+(5x5x16))
- 可训练参数:32((1+1)x16)
备注:S4是一个下采样层,由16个5x5大小的特征图构成,特征图的每个单元与C3中相应的特征图的2x2邻域相连,S4层有32个可训练参数(每个特征图1个因子和一个偏置)和2000个连接。
6、C5层
- 输入图像大小:5x5x16
- 卷积核大小:5x5
- 卷积核个数:120
- 输出特征图数量:120
- 输出特征图大小:1X1(5-5+1)
- 神经元数量:120(1x120)
- 连接数:48120(5x5x16x120x1+120x1)
- 可训练参数:48120(5x5x16x120+120)
备注:C5层是一个卷积层,有120个特征图,每个单元与S4层的全部16个单元的5x5邻域相连,构成了S4和C5的全连接,之所以仍将C5标识为卷积层而非全连接层是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1x1大。
7、F6层
- 输入图像大小:(1x1x120)
- 卷积核大小:1x1
- 卷积核个数:84
- 输出特征图数量:1
- 输出特征图大小:84
- 神经元数量:84
- 连接数:10164(120x84+84)
- 可训练参数:10164(120x84+84)
备注:F6有84个单元(之所以选择84是源于输出层的设计),与C5层相连,有10164个可训练参数,类似经典的全连接神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置,之后将其传递给sigmoid函数产生一个单元i的状态。
8、output层
- 输入图像大小:1x84
- 输出特征图数量:1x10
9、AlexNet
超详细介绍AlexNet
这篇论文,题目叫做“ImageNet Classification with Deep Convolutional Networks”,迄今被引用6184次,被业内普遍视为行业最重要的论文之一。Alex Krizhevsky、Ilya Sutskever和 Geoffrey Hinton创造了一个“大型的深度卷积神经网络”,赢得了2012 ILSVRC(2012年ImageNet 大规模视觉识别挑战赛)。稍微介绍一下,这个比赛被誉为计算机视觉的年度奥林匹克竞赛,全世界的团队相聚一堂,看看是哪家的视觉模型表现最为出色。2012年是CNN首次实现Top 5误差率15.4%的一年(Top 5误差率是指给定一张图像,其标签不在模型认为最有可能的5个结果中的几率),当时的次优项误差率为26.2%。这个表现不用说震惊了整个计算机视觉界。可以说,是自那时起,CNN才成了家喻户晓的名字。
ImageNet 2012比赛分类任务的冠军,将分类错误率降低到了15.315%,使用传统计算机视觉的第二名小组的分类错误率为26.172%。
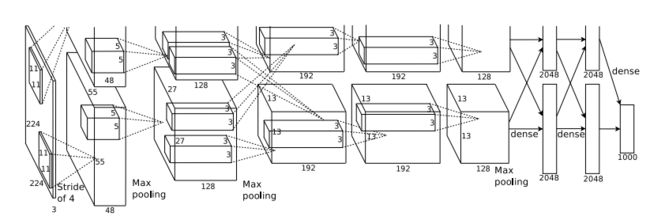
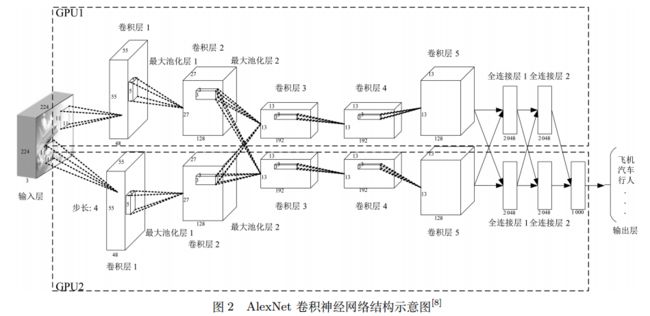
上图所示是caffe中alexnet的网络结构,上图采用是两台GPU服务器,所有会看到两个流程图。下边把AlexNet的网络结构示意一下:

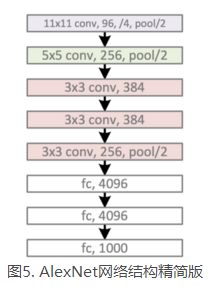
简化的结构:
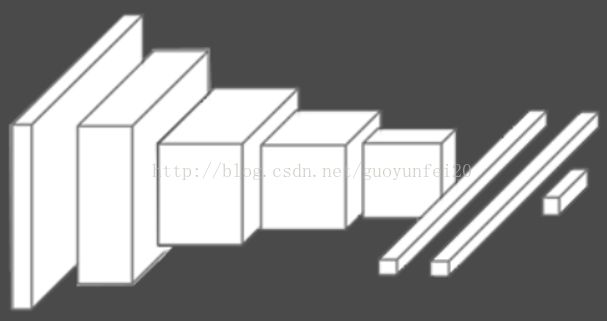
架构:
因为使用了两台GPU训练,因而有两股“流”。使用两台GPU训练的原因是计算量太大,只能拆开来。
要点:
数据集:ImageNet数据集,含1500多万个带标记的图像,超过2.2万个类别
激活函数:ReLU(训练速度快,一定程度上减小了梯度消失的问题)
数据增强:平移、镜像、缩放等
过拟合:dropout
如何训练:批处理梯度下降训练模型,注明了动量衰减值和权值衰减值
训练时间:使用两台GTX 580 GPU,训练了5到6天
Alex Krizhevsky等人于2012年的ImageNet比赛中提出了新型卷积神经网络AlexNet,并获得了图像分类问题的最好成绩(Top-5错误率为15.3%)。
网络结构:
其实AlexNet的结构很简单,只是LeNet的放大版,输入是一个224x224的图像,经过5个卷积层,3个全连接层(包含一个分类层),达到了最后的标签空间。
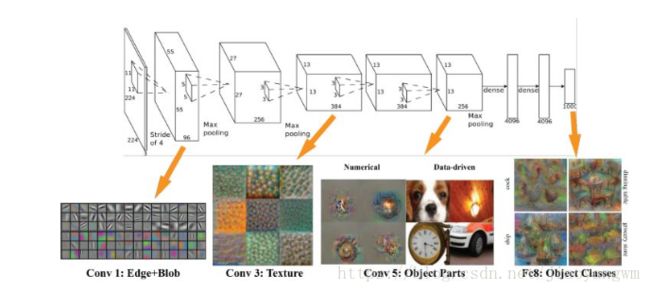
AlexNet学习出来的特征是什么样子的?
- 第一层:都是一些填充的块状物和边界等特征
- 中间层:学习一些纹理特征
- 更高层:接近于分类器的层级,可以明显的看到物体的形状特征
- 最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
即无论对什么物体,学习过程都是:边缘
→
\to
→部分
→
\to
→整体
该方法训练了一个端到端的卷积神经网络实现对图像特征提取和分类,网络结构共7层,包含5层卷积层和2层全连接层。
AlexNet包含了6亿三千万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。
AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积神经网络)在计算机界的统治地位,同时也推动了深度学习在语音识别、自然语言处理、强化学习等方面的拓展。
**训练技巧:dropout防止过拟合,提高泛化能力 **
训练阶段使用了Dropout技巧随机忽略一部分神经元,缓解了神经网络的过拟合现象,和防止对网络参数优化时陷入局部最优的问题,Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
该网络是利用Dropout在训练过程中将输入层和中间层的一些神经元随机置零,使得训练过程收敛的更慢,但得到的网络模型更加具有鲁棒性。
数据扩充 / 数据增强:防止过拟合
通过图像平移、水平翻转、调整图像灰度等方法扩充样本训练集,扩充样本训练集,使得训练得到的网络对局部平移、旋转、光照变化具有一定的不变性,数据经过扩充以后可以达到减轻过拟合并提升泛化能力。进行预测时,则是取图像的四个角加上中间共5个位置,并进行左右翻转,一共获得10张图像,对它们进行预测并对10次结果求均值。
-
水平翻转:

-
随机裁剪、平移旋转:

-
颜色变换:

池化方式:
AlexNet全部使用最大池化的方式,避免了平均池化所带来的模糊化的效果,并且步长<池化核的大小,这样一来池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
此前的CNN一直使用平均池化的操作。
激活函数:ReLU
Relu函数:f(x)=max(0,x)
采用非饱和线性单元——ReLU代替传统的经常使用的tanh和sigmoid函数,加速了网络训练的速度,降低了计算的复杂度,对各种干扰更加具有鲁棒性,并且在一定程度上避免了梯度消失问题。
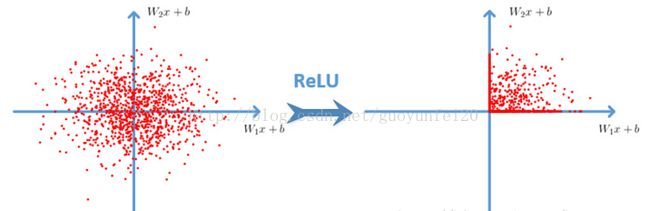
优势:
- ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
- ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
- ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
- ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
缺点:
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
提出了LRN层(Local Response Normalization):
LRN即Local Response Normalization,局部响应归一化处理,实际就是利用临近的数据做归一化,该策略贡献了1.2%的准确率,该技术是深度学习训练时的一种提高准确度的技术方法,LRN一般是在激活、池化后进行的一种处理方法。
LRN是对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
为什么输入数据需要归一化(Normalized Data)?
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
分布式计算:
AlexNet使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算,AlexNet使用两个GTX580的GPU进行训练,单个GTX580只有3GB的显存,限制了可训练网络的最大规模,因此将其分布在两个GPU上,在每个GPU的显存中储存一般的神经元参数。
有多少层需要训练
整个AlexNet有8个需要训练参数的层,不包括池化层和LRN层,前5层为卷积层,后3层为全连接层,AlexNet的最后一层是由1000类输出的Softmax层用作分类,LRN层出现在第一个和第二个卷积层之后,最大池化层出现在两个LRN之后和最后一个卷积层之后。
每层的超参数、参数量、计算量:

虽然前几个卷积层的计算量很大,但是参数量都很小,在1M左右甚至更小。只占AlexNet总参数量的很小一部分,这就是卷积层的作用,可以通过较小的参数量有效的提取特征。
为什么使用多层全连接:
-
全连接层在CNN中起到分类器的作用,前面的卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间,全连接层是将学到的特征映射映射到样本标记空间,就是矩阵乘法,再加上激活函数的非线性映射,多层全连接层理论上可以模拟任何非线性变换。但缺点也很明显: 无法保持空间结构。
-
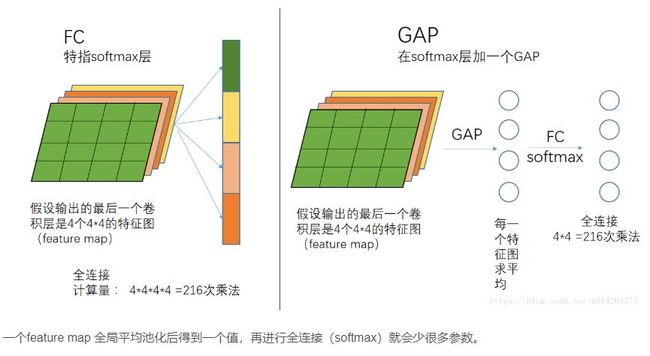
由于全连接网络的冗余(占整个我拿过来参数的80%),近期一些好的网络模型使用全局平均池化(GAP)取代FC来融合学到的深度特征,最后使用softmax等损失函数作为网络目标函数来指导学习过程,用GAP替代FC的网络通常有较好的预测性能。
-
全连接的一个作用是维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。全连接另一个作用是隐含语义的表达(embedding),把原始特征映射到各个隐语义节点(hidden node)。对于最后一层全连接而言,就是分类的显示表达。不同channel同一位置上的全连接等价与1x1的卷积。N个节点的全连接可近似为N个模板卷积后的均值池化(GAP)。
GAP:假如最后一层的数据是10个66的特征图,global average pooling是将每个特征图计算所有像素点的均值,输出一个数据值,10个特征图就会输出10个值,组成一个110的特征向量。
-
用特征图直接表示属于某类的置信率,比如有10个输出,就在最后输出10个特征图,每个特征图的值加起来求均值,然后将均值作为其属于某类的置信值,再输入softmax中,效果较好。
-
因为FC的参数众多,这么做就减少了参数的数量(在最近比较火的模型压缩中,这个优势可以很好的压缩模型的大小)。
-
因为减少了参数的数量,可以很好的减轻过拟合的发生。
为什么过了20年才卷土重来:
1. 大规模有标记数据集的出现,防止以前不可避免的过拟合现象
**2. 计算机硬件的突飞猛进,卷积神经网络对计算机的运算要求比较高,需要大量重复可并行化的计算,在当时CPU只有单核且运算能力比较低的情况下,不可能进行个很深的卷积神经网络的训练。随着GPU计算能力的增长,卷积神经网络结合大数据的训练才成为可能。 **
3. 卷积神经网络有一批一直在坚持的科学家(如Lecun)才没有被沉默,才没有被海量的浅层方法淹没。然后最后终于看到卷积神经网络占领主流的曙光。
10、ZFNet
和AlexNet很像,只是把参数优化了。
2012年AlexNet出尽了风头,ILSVRC 2013就有一大批CNN模型冒了出来。2013年的冠军是纽约大学Matthew Zeiler 和 Rob Fergus设计的网络 ZF Net,错误率 11.2%。ZF Net模型更像是AlexNet架构的微调优化版,但还是提出了有关优化性能的一些关键想法。还有一个原因,这篇论文写得非常好,论文作者花了大量时间阐释有关卷积神经网络的直观概念,展示了将滤波器和权重可视化的正确方法。
在这篇题为“Visualizing and Understanding Convolutional Neural Networks”的论文中,Zeiler和Fergus从大数据和GPU计算力让人们重拾对CNN的兴趣讲起,讨论了研究人员对模型内在机制知之甚少,一针见血地指出“发展更好的模型实际上是不断试错的过程”。虽然我们现在要比3年前知道得多一些了,但论文所提出的问题至今仍然存在!这篇论文的主要贡献在于提出了一个比AlexNet稍微好一些的模型并给出了细节,还提供了一些制作可视化特征图值得借鉴的方法。
10.1 意义
该论文是在AlexNet基础上进行了一些细节的改动,网络结构上并没有太大的突破。该论文最大的贡献在于通过使用可视化技术揭示了神经网络各层到底在干什么,起到了什么作用。
从科学的观点出发,如果不知道神经网络为什么取得了如此好的效果,那么只能靠不停的实验来寻找更好的模型。
使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
10.2 实现方法
训练过程:
对前一层的输入进行卷积 -> relu -> max pooling(可选) -> 局部对比操作(可选) -> 全连接层 -> softmax分类器。
输入是(x,y),计算y与y的估计值之间的交叉熵损失,反向传播损失值的梯度,使用随机梯度下降算法来更新参数(w和b)以完成模型的训练。
反卷积可视化:
一个卷积层加一个对应的反卷积层;
输入是feature map,输出是图像像素;
过程包括反池化操作、relu和反卷积过程。
反池化:
严格意义上的反池化是无法实现的。作者采用近似的实现,在训练过程中记录每一个池化操作的一个z*z的区域内输入的最大值的位置,这样在反池化的时候,就将最大值返回到其应该在的位置,其他位置的值补0。
relu:
卷积神经网络使用relu非线性函数来保证输出的feature map总是为正数。在反卷积的时候,也需要保证每一层的feature map都是正值,所以这里还是使用relu作为非线性激活函数。
滤波:
使用原卷积核的转秩和feature map进行卷积。反卷积其实是一个误导,这里真正的名字就是转秩卷积操作。
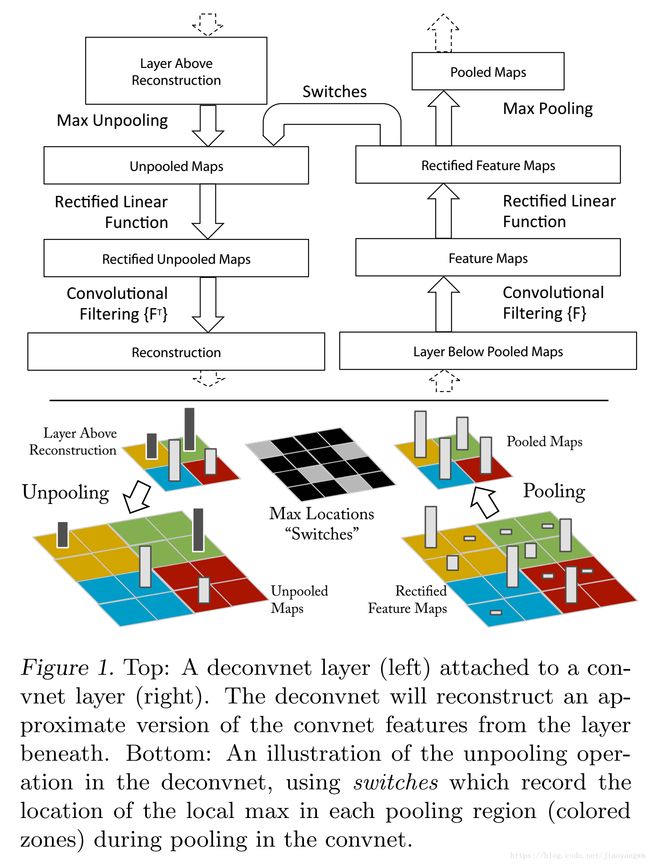
上图左边是一个解卷积层,右边为一个卷积层,解卷积层将会重建一个来自下一层的卷积特征近似版本,图中使用switch来记录在卷积网中进行最大池化操作时每个池化区域的局部最大值的位置,经过非池化操作后,原来的非最大值的位置全都置为0。
预处理:
网络对输入图片进行预处理,裁剪图片中间的256x256区域,并减去整个图像每个像素的均值,然后用10个不同的对256x256图像进行224x224的裁剪(中间区域加上四个角落,以及他们的水平翻转图像),对以128个图片分的块进行随机梯度下降法来更新参数。起始学习率为$10 ^{−2} $ ,动量为0.9,当验证集误差停滞时,手动调整学习率。在全连接网络中使用概率为0.5的dropout,并且所有权值都初始化为$10 ^{−2} $ ,偏置设为0。
在训练时第一层的可视化揭露了一些占主导的因素,为了了解这些,我们采用重新归一化每个卷积层的滤波器,这些滤波器的均方根值超过了一个固定半径的$10 ^{−1} $ 。这是非常关键的,尤其是在模型中的第一层,因为输出图片大约在[-128,128]的范围内。
特征可视化:
每个特征单独投影到像素空间揭露了不同的结构能刺激不同的一个给定的特征图,因此展示了它对于变形的输入内在的不变性。下图即在一个已经训练好的网络中可视化后的图。
10.3 训练细节
网络结构类似于AlexNet,有两点不同,一是将3,4,5层的变成了全连接,二是卷积核的大小减小。
图像预处理和训练过程中的参数设置也和AlexNet很像。
-
AlexNet用了1500万张图像,ZFNet用了130万张图像。
-
AlexNet在第一层中使用了大小为11×11的滤波器,而ZF使用的滤波器大小为7x7,整体处理速度也有所减慢。做此修改的原因是,对于输入数据来说,第一层卷积层有助于保留大量的原始象素信息。11×11的滤波器漏掉了大量相关信息,特别是因为这是第一层卷积层。
-
随着网络增大,使用的滤波器数量增多。
-
利用ReLU的激活函数,将交叉熵代价函数作为误差函数,使用批处理随机梯度下降进行训练。
-
使用一台GTX 580 GPU训练了12天。
-
开发可视化技术“解卷积网络”(Deconvolutional Network),有助于检查不同的特征激活和其对输入空间关系。名字之所以称为“deconvnet”,是因为它将特征映射到像素(与卷积层恰好相反)。
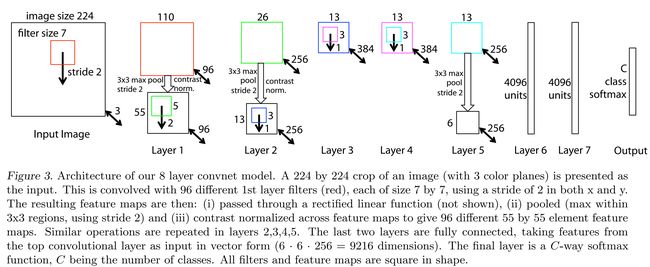
解卷积层DeConvNet:
DeConvNet工作的基本原理是,每层训练过的CNN后面都连一层“deconvet”,它会提供一条返回图像像素的路径。输入图像进入CNN之后,每一层都计算激活。然而向前传递。现在,假设我们想知道第4层卷积层某个特征的激活值,我们将保存这个特征图的激活值,并将这一层的其他激活值设为0,再将这张特征图作为输入送入deconvnet。Deconvnet与原来的CNN拥有同样的滤波器。输入经过一系列unpool(maxpooling倒过来),修正,对前一层进行过滤操作,直到输入空间满。
这一过程背后的逻辑在于,我们想要知道是激活某个特征图的是什么结构。下面来看第一层和第二层的可视化。

ConvNet的第一层永远是低层特征检测器,在这里就是对简单的边缘、颜色进行检测。第二层就有比较圆滑的特征了。再来看第三、第四和第五层。

第二层应对角落和其他边缘或者颜色的结合;第三层有更加复杂的不变性,捕捉到了相似的纹理;第四层显示了特定类间显著的差异性;第五层显示了有显著构成变化的整个物体。
这些层展示出了更多的高级特征,比如狗的脸和鲜花。值得一提的是,在第一层卷积层后面,我们通常会跟一个池化层将图像缩小(比如将 32x32x32 变为16x16x3)。这样做的效果是加宽了第二层看原始图像的视野。更详细的内容可以阅读论文。
训练时的特征演变过程:
外表突然的变化导致图像中的一个变换即产生了最强烈的激活。模型的底层在少数几个epoches就能收敛聚集,然而上层在一个相当多的epoches(40-50)之后才能有所变化,这显示了让模型完全训练到完全收敛的必要性。可以由下图看到颜色对比度都逐步增强。

特征不变性:
一般来说,小的变化对于模型的第一层都有非常大的影响,但对于最高层的影响却几乎没有。对于图像的平移、尺度、旋转的变化来说,网络的输出对于平移和尺度变化都是稳定的,但却不具有旋转不变性,除非目标图像时旋转对称的。下图为分别对平移,尺度,旋转做的分析图。

上图按行顺序分别为对5类图像进行不同程度的垂直方向上的平移、尺度变换、旋转对输出结果影响的分析图。按列顺序分别为原始变换图像,第一层中原始图片和变换后的图片的欧氏距离,第7层中原始图片和变换后的图片的欧氏距离,变换后图片被正确分类的概率图。
可视化不仅能够看到一个训练完的模型的内部操作,而且还能帮助选择好的网络结构。
ZF Net为什么重要?
ZF Net不仅是2013年比赛的冠军,还对CNN的运作机制提供了极好的直观信息,展示了更多提升性能的方法。论文所描述的可视化方法不仅有助于弄清CNN的内在机理,也为优化网络架构提供了有用的信息。Deconv可视化方法和 occlusion 实验也让这篇论文成了我个人的最爱。
10.4 卷积网络可视化
特征可视化:
通过对各层卷积核学习到的特征进行可视化发现神经网络学习到的特征存在层级结构。第二层是学习到边缘和角点检测器,第三层学习到了一些纹理特征,第四层学习到了对于指定类别图像的一些不变性的特征,例如狗脸、鸟腿,第五层得到了目标更显著的特征并且获取了位置变化信息。
训练过程中的特征演化:
低层特征经过较少epoch的训练过程之后就学习的比较稳定了,层数越高越需要更多的epoch进行训练。因此需要足够多的epoch过程来保证顺利的模型收敛。
特征不变性:
卷积神经网络具有平移和缩放不变性,并且层数越高不变性越强。但是不具有旋转不变性。
特征结构选择:
作者通过可视化AlexNet第一层和第二层的特征,发现比较大的stride和卷积核提取的特征不理想,所以作者将第一层的卷积核从1111减小到77,将stride从4减小到2,实验说明,这样有助于分类性能的提升。
遮挡实验:
遮挡实验说明图像的关键区域被遮挡之后对分类性能有很大的影响,说明分类过程中模型明确定位出了场景中的物体。
一致性分析:
不同图像的指定目标局部块之间是否存在一致性的关联,作者认为深度模型可能默认学习到了这种关联关系。作者通过对五张不同的狗的图像进行局部遮挡,然后分析原图和遮挡后的图像的特征之间的汉明距离的和值,值越小说明一致性越大。实验表明,对不同的狗的图像遮挡左眼、右眼和鼻子之后的汉明距离小于随机遮挡,证明存在一定的关联性。
10.6 总结
-
提出了一种可视化方法;
-
发现学习到的特征远不是无法解释的,而是特征间存在层次性,层数越深,特征不变性越强,类别的判别能力越强;
-
通过可视化模型中间层,在alexnet基础上进一步提升了分类效果;
-
遮挡实验表明分类时模型和局部块的特征高度相关;
-
模型的深度很关键;
-
预训练模型可以在其他数据集上fine-tuning得到很好的结果。
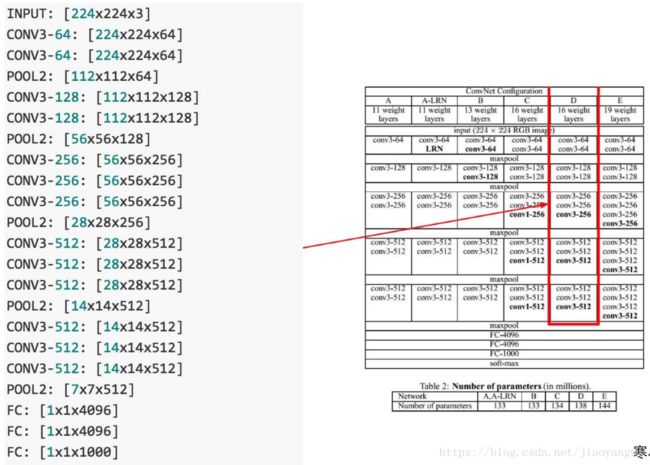
11、VGGNet
很适合做迁移学习,提到了一系列,VGG-16、VGG-19,不同层,参数也不同,最后选择了D的参数,结果最好。
传统的网络训练19层的网络很不容易,很厉害。
VGGNet是牛津大学计算机视觉组(Visual?Geometry?Group)和Google DeepMind公司的研究员一起研发的的深度卷积神经网络。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠33的小型卷积核和22的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。
VGGNet论文中全部使用了33的卷积核和22的池化核,通过不断加深网络结构来提升性能。下图所示为VGGNet各级别的网络结构图,和每一级别的参数量,从11层的网络一直到19层的网络都有详尽的性能测试。
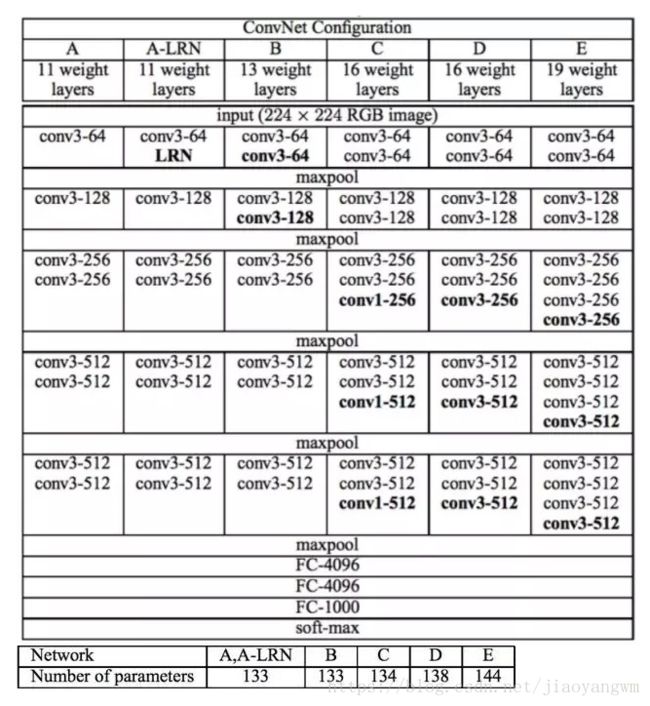
A网络(11层)有8个卷积层和3个全连接层,E网络(19层)有16个卷积层和3个全连接层,卷积层宽度(通道数)从64到512,每经过一次池化操作,扩大一倍。
11.1 结构
-
输入:训练时输入大小为224x224大小的RGB图像;
-
预处理:在训练集中的每个像素减去RGB的均值
-
卷积核:3x3大小的卷积核,有的地方使用1x1的卷积,这种1x1的卷积可以被看做是对输入通道的线性变换。
-
步长:步长stride为1
-
填充:填充1个像素
-
池化:max-pooling,共有5层在一部分卷积层之后,连接的max-pooling的窗口是2x2,步长为2
-
全连接层:前两个全连接层均有4096个通道,第三个全连接层由1000个通道,用来分类。所有网络的全连接层配置相同。
-
激活函数:ReLU
-
不使用LRN,这种标准化并不能带来很大的提升,反而会导致更多的内存消耗和计算时间
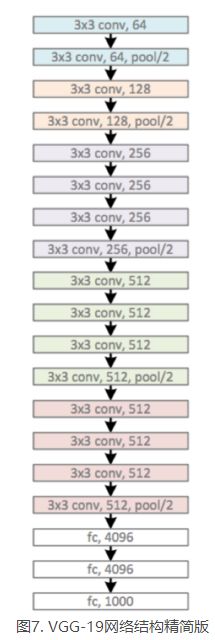
相比AlexNet的变化:
- LRN层作用不大,还耗时,抛弃
- 网络越深,效果越好
- 卷积核使用更小的卷积核,比如3x3
VGG虽然比AlexNet模型层数多,且每轮训练时间会比AlexNet更长,但是因为更深的网络和更小的卷积核带来的隐式正则化结果,需要的收敛的迭代次数减小了许多。
要点:
这里使用3x3的滤波器和AlexNet在第一层使用11x11的滤波器和ZF Net 7x7的滤波器作用完全不同。作者认为两个3x3的卷积层组合可以实现5x5的有效感受野。这就在保持滤波器尺寸较小的同时模拟了大型滤波器,减少了参数。此外,有两个卷积层就能够使用两层ReLU。
-
3卷积层具有7x7的有效感受野。
-
每个maxpool层后滤波器的数量增加一倍。进一步加强了缩小空间尺寸,但保持深度增长的想法。
-
图像分类和定位任务都运作良好。
-
使用Caffe工具包建模。
-
训练中使用scale jittering的数据增强技术。
-
每层卷积层后使用ReLU层和批处理梯度下降训练。
-
使用4台英伟达Titan Black GPU训练了两到三周。
为什么重要?
VGG Net是最重要的模型之一,因为它再次强调CNN必须够深,视觉数据的层次化表示才有用。深的同时结构简单。
11.2 网络特点:
- VGGNet使用3x3的卷积
AlexNet和ZFNet在第一个卷积层的卷积分别是11x11 、步长为4,7x7、步长为2)
- 使用三个3x3的卷积,而不是一个7x7的卷积
两个连续的3x3的卷积相当于5x5的感受野,三个相当于7x7的感受野,优势在于:① 包含三个ReLU层而不是一个,使得决策函数更有判别性;② 减少了参数,比如输入输出都是c个通道,使用3x3的3个卷积层需要3(3x3xCxC)=27xCxC,使用7x7的1个卷积层需要7x7xCxC=49xCxC,这可以看做是为7x7x的卷积施加一种正则化,使它分解为3个3x3的卷积。
- 使用1x1的卷积层,该层主要是为了增加决策函数的非线性,而不影响卷积层的感受野,虽然1x1的卷积操作是线性的,但是ReLU增加了非线性
11.3 分类框架:
a. 训练过程:
除了从多尺度的训练图像上采样输入图像外,VGGNet和AlexNet类似
**优化方法:**是含有动量的随机梯度下降SGD+momentum(0.9)
批尺度: batch size = 256
**正则化:**采用L2正则化,weight decay 是5e-4,dropout在前两个全连接层之后,p=0.5
为什么能在相比AlexNet网络更深,参数更多的情况下,VGGNet能在更少的周期内收敛:
① 更大的深度和更小的卷积核带来隐式正则化;② 一些层的预训练
参数初始化:
对于较浅的A网络,参数进行随机初始化,权值w从N(0,0.01)中采样,偏差bias初始化为0;对于较深的网络,先用A网络的参数初始化前四个卷积层和三个全连接层。
数据预处理:
为了获得224x224的输入图像,要在每个SGD迭代中对每张重新缩放的图像进行随机裁剪,为了增强数据集,裁剪的图像还要随机水平翻转和RGB色彩偏移。
b. 测试过程
- 对输入图像重新缩放到一个预定义的最小图像边的尺寸Q
- 网络密集地应用在重缩放后的图像上,也就是说全连接层转化为卷积层(第一个全连接层转化为7x7的卷积层,后两个全连接层转化为1x1的卷积层),然后将转化后的全连接层应用在整张图中)
- 为了获得固定尺寸的类别分数向量,对分数图进行空间平均化处理。
c. 实现
基于C++ Caffe,进行一些重要修改,在单系统多GPU上训练。
在装有4个NVIDIA Titan Black GPUs的电脑上,训练一个网络需要2-3周。
12、GoogLeNet
ImageNet 2014比赛分类任务的冠军,将错误率降低到了6.656%,突出的特点是大大增加了卷积神经网络的深度。
将最后的全连接层都换成了1x1的卷积层,大大加速了训练速率。
12.1 GoogLeNet Inception V1——22层
GoogLeNet Incepetion V1《Going deeper with convolutions》。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬。
1)动机:
深度学习以及神经网络快速发展,人们不再只关注更给力的硬件、更大的数据集、更大的模型,而是更在意新的idea、新的算法以及模型的改进。
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献1表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。 虽然数学证明有着严格的条件限制,但Hebbian准则有力地支持了这一点:fire together,wire together。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。

2012年AlexNet做出历史突破以来,直到GoogLeNet出来之前,主流的网络结构突破大致是网络更深(层数),网络更宽(神经元数)。所以大家调侃深度学习为“深度调参”,但是纯粹的增大网络的缺点:
- 参数太多,容易过拟合,若训练数据集有限;
- 网络越大计算复杂度越大,难以应用;
- 网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型
那么解决上述问题的方法当然就是增加网络深度和宽度的同时减少参数,Inception就是在这样的情况下应运而生。
2)网络结构
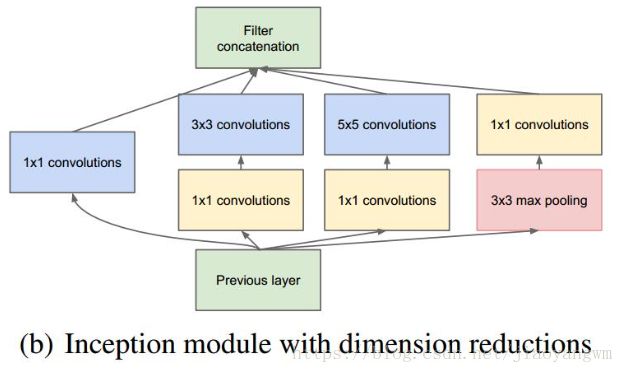
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构,基本结构如下:

上图说明:
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合
- 之所以卷积核采用1x1,3x3和5x5,主要是为了方便对齐,设定卷积步长stride=1,只要分别设定padding=0,1,2,那么卷积之后便可以得到相同维度的特征,然后将这些特征就可以直接拼接在一起了。
- 文章中说pooling被证明很有效,所以网络结构中也加入了
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也变大了,因此随着层数的增加,3x3和5x5的比例也要增加。
但是使用5x5的卷积核仍然会带来巨大的计算量,为此文章借鉴NIN,采用1x1的卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
卷积层参数数量计算:
输入通道数为K,输出通道数为L,那么卷积核个数为K*L。因为高维卷积计算是多个通道与多个卷积核分别进行二维计算,
所以K个通道会需要K个卷积核,计算之后,合并也就是相加得到一个通道,又因为输出通道为L,所以需要K*L个卷积核。
然后就是如何求解参数数量?
其实很简单,就是卷积核个数乘以卷积核尺寸,para=IJK*L。
- 1
- 2
- 3
- 4
- 5
- 6
输入是3个3232, 共31024=3072。每条边padding为2,则内存里实际为3个36*36.
卷积核个数是3维的55分别与3个输入进行卷积运算,得到3维的3232的输出,这里将3维的3232对应位相加得到一张3232的feature Map
如果有64个3维的5*5卷积核就有64张feature Map
具体过程图示为:
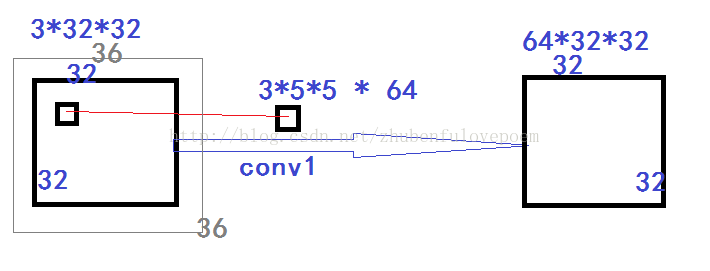
卷积的权值存取方式为:
第1个5*5作用于第一张输入全图,
第2个5*5作用于第二张输入全图,
第3个5*5作用于第三张输入全图,
再把这三个对应位置相加,在加上biases,得到第一张feature map
最后64个553重复上面的过程,得到64个featuremap
这里weights有355*64个,biases有64个.
这里输入是3 输出是64,卷积核是55权值个数是64 553
具体改进后的Inception Module如下:
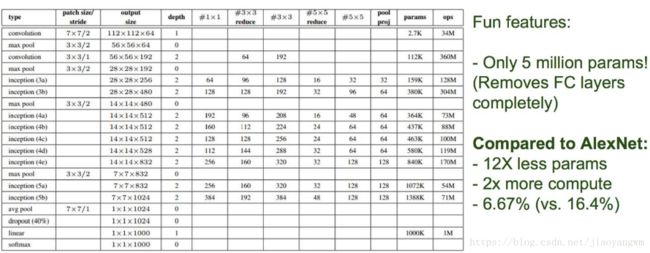
GoogLeNet Incepetion V1比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
Inception V1降低参数量的目的有两点:
-
第一,参数越多模型越庞大,需要供模型学习的数据量就越大,而目前高质量的数据非常昂贵;
-
第二,参数越多,耗费的计算资源也会更大。
Inception V1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:
-
其一,去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。
-
其二,Inception V1中精心设计的Inception Module提高了参数的利用效率,其结构如上图所示。这一部分也借鉴了Network In Network的思想,形象的解释就是Inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。
Inception Module的基本结构:
其中有4个分支:
-
第一个分支对输入进行11的卷积,这其实也是NIN中提出的一个重要结构。11的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。
Inception Module的4个分支都用到了1x1的卷积,来进行低成本(计算量比3x3小很多)的跨通道的特征变换 -
第二个分支,先使用了1x1卷积,然后连接3x3卷积,相当于进行了两次特征变换
-
第三个分支,先使用1x1卷积,然后连接5x5卷积
-
第四个分支,3x3最大池化后直接使用1x1卷积
四个分支在最后通过一个聚合操作合并,在输出通道这个维度上聚合。
我们立刻注意到,并不是所有的事情都是按照顺序进行的,这与此前看到的架构不一样。我们有一些网络,能同时并行发生反应,这个盒子被称为 Inception 模型。
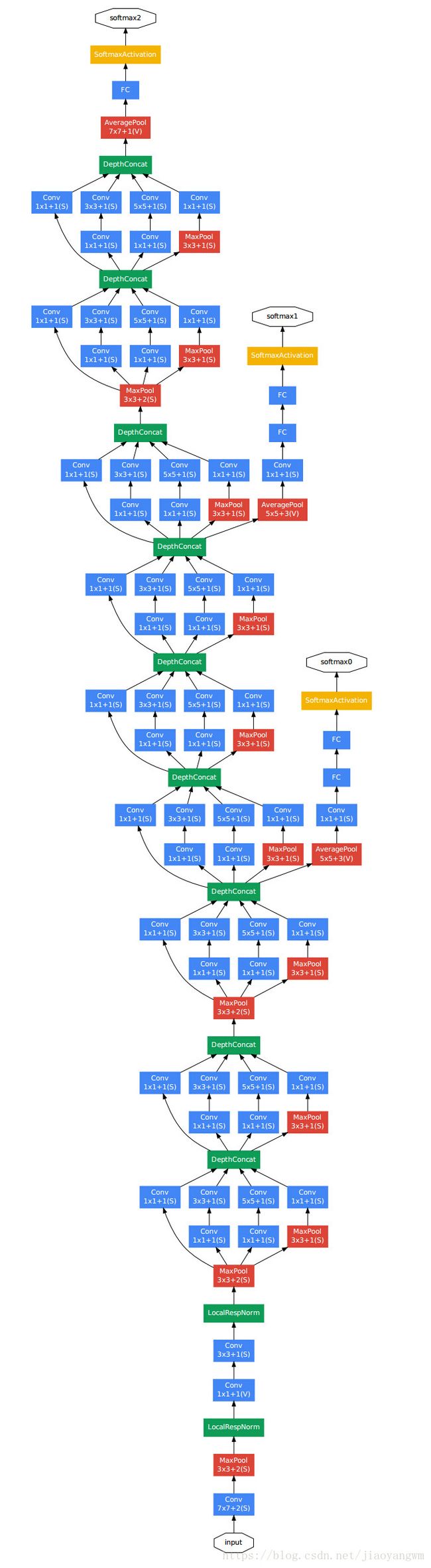
12.2 GoogLeNet

先小心翼翼的训练得到一组权重参数(第一个出来的分支),再利用这些参数作为初始化参数,训练网络,之后再进行一次初始化,训练得到22层的网络。
上图说明:
- GoogLeNet 采用了模块化的几个,方便增添和修改
- 网络最后采用了平均池化来代替全连接层,想法来自NIN,事实证明可以将TOP accuracy 提高0.6%,但是,实际在最后一层还是加了一个全连接层,主要为了方便之后的微调
- 虽然移除了全连接,但是网络中依然使用了Dropout
- 为了避免梯度消失,网络额外增加了2个辅助的softmax用于前向传导梯度,文章中说着两个辅助分类器的loss应该加一个衰减系数,但是caffe中的模型没有加任何衰减,此外,实际测试的时候,这两个额外的softmax会被去掉。
比较清晰的结构图:
结论:
GoogLeNet是谷歌团队为了参加ILSVRC 2014比赛而精心准备的,为了达到最佳的性能,除了使用上述的网络结构外,还做了大量的辅助工作:包括训练多个model求平均、裁剪不同尺度的图像做多次验证等等。详细的这些可以参看文章的实验部分。
本文的主要想法其实是想通过构建密集的块结构来近似最优的稀疏结构,从而达到提高性能而又不大量增加计算量的目的。GoogleNet的caffemodel大小约50M,但性能却很优异。
12.3 GoogleNet Inception V2
V2和V1的最大的不同就是,V2增加了Batch Normalization。《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
Inception V2学习了VGGNet,用两个3x3的卷积代替5x5的卷积,用以降低参数量并减轻过拟合,还提出了著名的Batch Normalization方法,该方法是一个很有效的正则化的方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅度的提高。
BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化(normalization)处理,使输出规范化到N(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。
BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。
而达到之前的准确率后,可以继续训练,并最终取得远超于Inception V1模型的性能——top-5错误率4.8%,已经优于人眼水平。因为BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
12.3.1 动机:
文章作者认为,网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使得每一层适应输入的分布,因此我们不得不降低学习率、小心的初始化,分布发生变化称为internal covariate shift。
一般在训练网络时会对数据进行预处理,包括去掉均值、白化操作等,目的是为了加快训练:
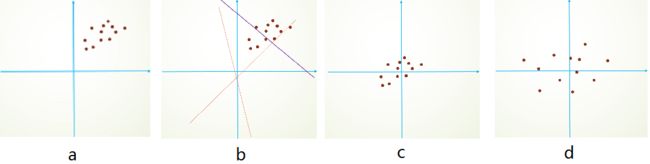
去均值化:
首先,图像数据是高度相关的,假设其分布如下图a所示(简化为2维),由于初始化的时候,我们的参数一般都是0均值的,因此开始的拟合y=Wx+b基本过原点附近,如图b红色虚线,因此,网络需要经过多次学习才能逐步达到紫色实线的拟合,即收敛的比较慢。
如果对数据先去均值化,如图c,显然可以加快学习,更进一步的,我们对数据在进行去相关操作,使得数据更加容易区分,这样又会加快训练,如图d。
去均值是一种常用的数据处理方式,它是将各个特征值减去其均值,几何上的展现是可以将数据的中心移到坐标原点,python代码为X=X-np.mean(X,axis=0),对于图像来说,就是对每个像素的值都要减去平均值。
PCA:
由于计算需要,需要实现进行前面所说的均值0化。
PCA要做的是将数据的主成分找出。流程如下:
- 计算协方差矩阵
- 求特征值和特征向量
- 坐标转换
- 选择主成分
首先我们需要求出数据各个特征之间的协方差矩阵,以得到他们之间的关联程度,Python代码如下:
# Assume input data matrix X of size [N x D]
X -= np.mean(X, axis = 0) # zero-center the data (important)
cov = np.dot(X.T, X) / X.shape[0] # get the data covariance matrix,公式含义可按照协方差矩阵的定义得到
- 1
- 2
- 3
其中得到的矩阵中的第(i,j)个元素代表第i列和第j列的协方差,对角线代表方差。协方差矩阵是对称半正定矩阵可以进行SVD分解:
U,S,V = np.linalg.svd(cov)1
- 1
U 的列向量是特征向量, S 是对角阵其值为奇异值也是特征值的平方.奇异值分解的直观展示:
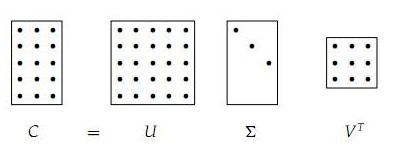
详细介绍
我们可以用特征向量(正交且长度为1可以看做新坐标系的基)右乘X(相当于旋转坐标系)就可以得到新坐标下的无联系(正交)的特征成分:
Xrot = np.dot(X, U) # decorrelate the data1
- 1
注意上面使用的np.linalg.svd()已经将特征值按照大小排序了,这里仅需要取前几列就是取前几个主要成分了(实际使用中我们一般按照百分比取),代码:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced becomes [N x 100]
- 1
白化:
白化的方式有很多种,常用的有PCA白化,就是对数据进行PCA操作之后,再进行方差归一化,这样数据基本满足0均值、单位方差、弱相关性。
作者首先尝试了对每一层数据都是用白化操作,但分析认为这是不可取的,因为白化需要计算协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,白化操作不一定可导,于是使用了Normalization的操作。
# whiten the data:
# divide by the eigenvalues (which are square roots of the singular values)
Xwhite = Xrot / np.sqrt(S + 1e-5)
- 1
- 2
- 3
但是白化因为将数据都处理到同一个范围内了,所以如果原始数据有原本影响不大的噪声,它原本小幅的噪声也会被放大到与全局相同的范围内了。
另外我们防止出现除以0的情况,在分母处多加了0.00001,如果增大它会使得噪声减小。
白化之后,得到的是一个多元高斯分布。
上面两种处理的结果如下:
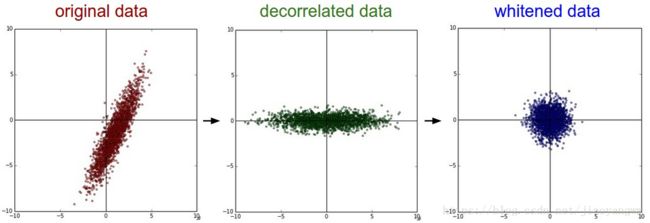
可以看出,经过PCA的去相关操作,将原始数据的坐标轴旋转,并且可以看出x方向的信息量比较大,如果只选择一个特征,那么久选横轴方向的特征,经过白化之后数据进入了相同的范围。
下面以处理之前提到过的CIFAR-10为例,看PCA和Whitening的作用:
左边是原始图片,每张图片都是一个3072维的一行向量,经过PCA之后选取144维最重要的特征(左2),将特征转化到原来的坐标系U.transpose()[:144,:]得到了降维之后的图形(左3),图形变模糊了,说明我们的主要信息都是低频信息,关于高低频的含义在下一段展示一下,图片模糊了但是主要成分都还在,最后一个图是白化之后再转换坐标系之后的结果。
-
1. CNN不用进行PCA和白化,只需要进行零均值化就好
-
2. 注意进行所有的预处理时训练集、验证集、测试集都要使用相同的处理方法,比如减去相同的均值。
12.3.2 对小批量进行统计特性的标准化
标准化 Normalization:
标准化是将矩阵X中的Dimensions都保持在相似的范围内,有两种实现方式:
-
先使得均值为0,然后除以标准差,
X=X / np.std(X, axis=0) -
在数据不在同一范围,而且各个维度在同一范围内对算法比较重要时,可以将其最大最小值分别缩放为1和-1,对于图像处理而言,因为一般数据都在0~255之间,所以不用再进行这一步了。
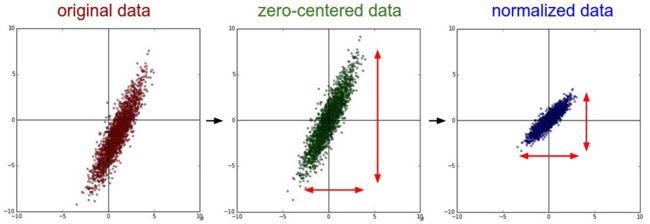
数据归一化的方法很简单,就是让数据具有0均值和单位方差:
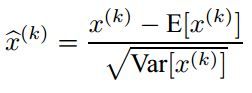
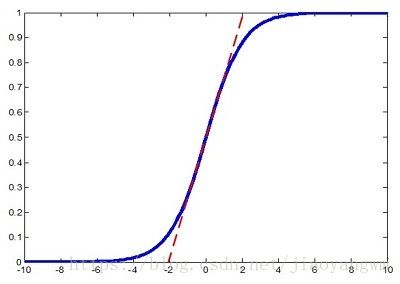
但是作者又说如果简单的这么干,会降低层的表达能力。比如下图,在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。
因此,作者又为BN增加了2个参数,用来保持模型的表达能力,于是最后的输出为:
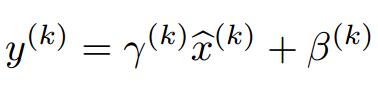
上述公式中用到了均值E和方差Var,需要注意的是理想情况下E和Var应该是针对整个数据集的,但显然这是不现实的。因此,作者做了简化,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
BN算法实现如下:

输入:输入数据
x
1
.
.
.
x
m
x_1...x_m
x1...xm(这些数据是准备进入激活函数的数据)
计算过程:
- 求数据均值
- 求数据方差
- 数据进行标准化
- 训练参数
γ , β \gamma , \beta γ,β - 输出y通过 γ \gamma γ 与 β \beta β的线性变换得到新的值
正向传播的过程:通过可学习的
γ
\gamma
γ与
β
\beta
β参数求出新的分布值
反向传播的过程:通过链式求导方式,求出
γ
,
β
\gamma,\beta
γ,β以及相关权值
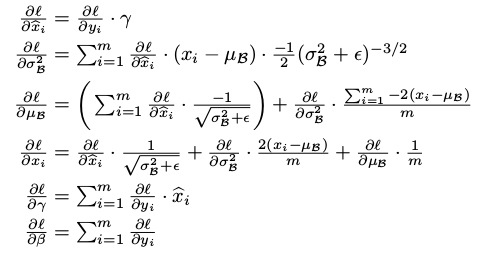
12.3.3 BN的意义:
解决的问题是梯度消失和梯度爆炸的问题
a. 关于梯度消失:
以sigmoid函数为例,sigmoid函数使得输出在[0,1]之间:

事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,如下图:
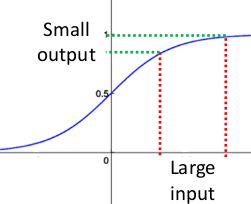
如果输入很大,其对应的斜率就很小,我们知道其斜率在反向传播中是权值学习速率,所以就会出现以下问题:
在深度网络中,如果网络的激活输出很大,那么其梯度就很小,学习速率就很慢,假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就打,学习速率就快。
影响:在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是后面几层基本可以表示整个网络,失去了深度的意义。
b. 关于梯度爆炸:
根据链式求导法则:
第一层偏移量的梯度 = 激活层斜率1 x 权值1 x 激活层斜率2 x …激活层斜率(n-1) x 权值(n-1) x 激活层斜率n
假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。
12.3.4 BN在CNN中的用法
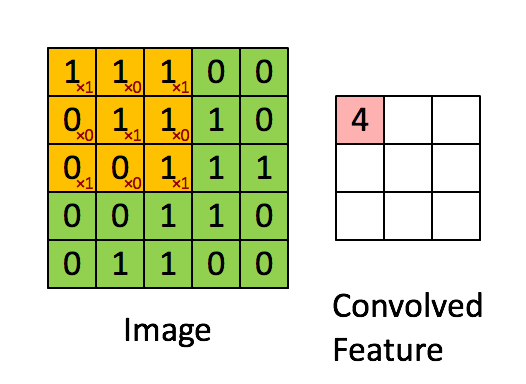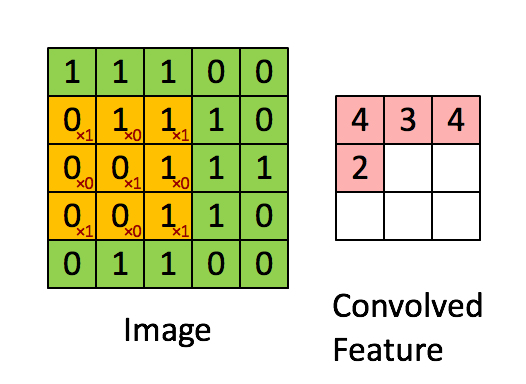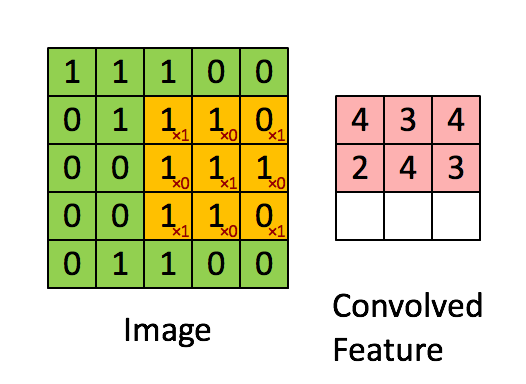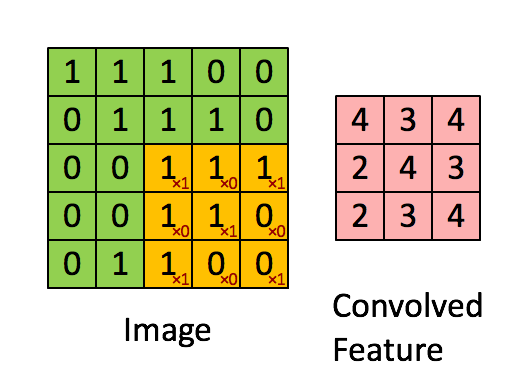
首先解释对图像的卷积是如何使用BN层的,上图是CNN中的5x5的图像通过valid卷积得到的3x3的特征图,特征图里边的值作为BN的输入,也就是这9个数值通过BN计算并保存
γ
,
β
\gamma,\beta
γ,β,通过
γ
,
β
\gamma,\beta
γ,β使得输出与输入不变。
假设输入的batch_size=m,那就有m x 9个数值,计算这m x 9个数据的
γ
,
β
\gamma,\beta
γ,β并保存,这就是正向传播的过程,反向传播就是根据求得的
γ
,
β
\gamma,\beta
γ,β来计算梯度。
重要说明:
-
网络训练中以batch_size为最小单位不断迭代,很显然新的batch_size进入网络,就会有新的
γ , β \gamma,\beta γ,β,因此在BN层中,共有总图像数 / batch_size组 γ , β \gamma,\beta γ,β被保存下来。 -
图像卷积过程中,通常是使用多个卷积核,得到多张特征图,对于多个的卷积核需要保存多个 γ , β \gamma,\beta γ,β。

输入:待进入激活函数的变量
输出:
-
对于k维的输入,假设每一维包含m个变量,所以需要k个循环,每个循环中按照上面所介绍的方法计算
γ , β \gamma,\beta γ,β,这里的k维,在卷积网络中可以看做卷积核个数,如网络中的第n层有64个卷积核,就需要计算64次。(注意:在正向传播时,会使用 γ , β \gamma,\beta γ,β使得BN层输入与输出一样。) -
在反向传播时利用 γ , β \gamma,\beta γ,β求得梯度,从而改变训练权值(变量)
-
通过不断迭代直到结束,求得关于不同层的 γ , β \gamma,\beta γ,β,如果有n个BN层,每层根据batch_size决定有多少个变量,设定为m,这里的mini_batcher指的是特征图大小 x batch_size,即m=特征图大小 x batch_size,因此对于batch_size为1,这里的m就是每层特征图的大小。
-
不断遍历训练集中的图像,取出每个batch_size的 γ , β \gamma,\beta γ,β,最后统计每层BN的 γ , β \gamma,\beta γ,β各自的和除以图像数量,得到平均值,并对其做无偏估计值作为每一层的E[x]与Var[x]。
-
在预测的正向传播时,对测试数据求取 γ , β \gamma,\beta γ,β,并使用该层的E[x]与Var[x],通过图中所表示的公式计算BN层的输出。
12.3.5 BN应该放在激活层之前还是之后
作者在文章中说应该把BN放在激活函数之前,这是因为Wx+b具有更加一致和非稀疏的分布。但是也有人做实验表明放在激活函数后面效果更好。这是实验链接,里面有很多有意思的对比实验:https://github.com/ducha-aiki/caffenet-benchmark
**12.3.6 实验 **
作者在文章中也做了很多实验对比,我这里就简单说明2个。
下图a说明,BN可以加速训练。图b和c则分别展示了训练过程中输入数据分布的变化情况。

下表是一个实验结果的对比,需要注意的是在使用BN的过程中,作者发现Sigmoid激活函数比Relu效果要好。

12.4 GoogLeNet Inception V3
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此Google团队又对其进行了进一步发掘改进,产生了升级版本的GoogLeNet。这一节介绍的版本记为V3,文章为:《Rethinking the Inception Architecture for Computer Vision》。
12.4.1 简介
2014年以来,构建更深网络的同时逐渐成为主流,但是模型的变大也使得计算效率越来越低,这里文章试图找到不同方法来扩大网络的同时又尽可能的发挥计算性能。
首先,GoogLeNet V1出现的同期,性能与之接近的大概只有VGGNet了,并且二者在图像分类之外的很多领域都得到了成功的应用。但是相比之下,GoogLeNet的计算效率明显高于VGGNet,大约只有500万参数,只相当于Alexnet的1/12(GoogLeNet的caffemodel大约50M,VGGNet的caffemodel则要超过600M)。
GoogLeNet的表现很好,但是,如果想要通过简单地放大Inception结构来构建更大的网络,则会立即提高计算消耗。此外,在V1版本中,文章也没给出有关构建Inception结构注意事项的清晰描述。因此,在文章中作者首先给出了一些已经被证明有效的用于放大网络的通用准则和优化方法。这些准则和方法适用但不局限于Inception结构。
12.4.2 一般情况的设计准则
下面的准则来源于大量的实验,因此包含一定的推测,但实际证明基本都是有效的。
1)避免表达瓶颈,特别是在网络靠前的地方
信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。
另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)
这种情况一般发生在pooling层,字面意思是,pooling后特征图变小了,但有用信息不能丢,不能因为网络的漏斗形结构而产生表达瓶颈,解决办法是作者提出了一种特征图缩小方法,更复杂的池化。
2)高维特征更容易处理
高维特征更加容易区分,会加快训练
3)可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息
比如在进行3x3卷积之前,可以对输入先进行降维而不会产生严重的后果,假设信息可以被简单的压缩,那么训练就会加快。
4)平衡网络的深度和宽度
上述的这些并不能直接用来提高网络质量,而仅用来在大环境下作指导。
12.4.3 利用大尺度滤波器进行图像的卷积
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,(保持感受野范围的同时又减少了参数量)如下图:
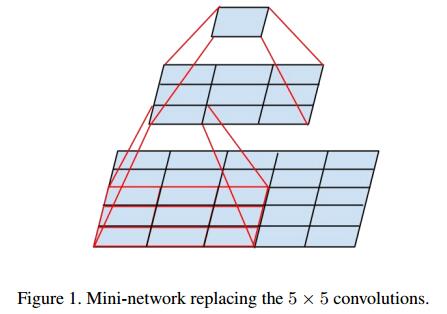
问题:
- 这种代替会造成表达能力的下降吗?
实验证明该操作不会造成表达缺失
- 3x3卷积之后还要再激活吗?
添加非线性激活之后会提高性能
从上面来看,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核。
如下图所示的取代3x3卷积:
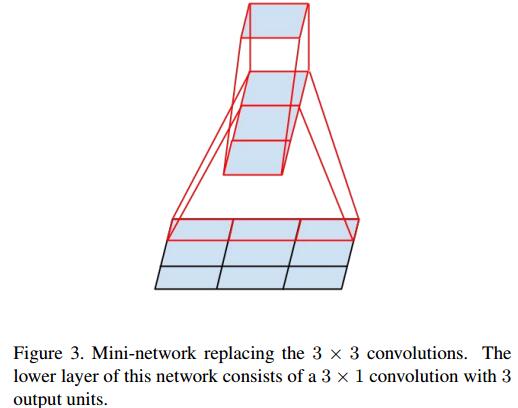
于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
总结如下图:
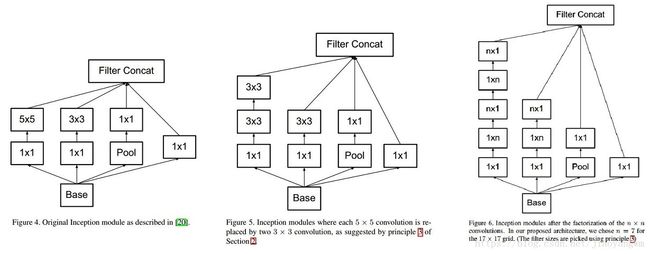
(1) 图4是GoogLeNet V1中使用的Inception结构;
(2) 图5是用3x3卷积序列来代替大卷积核;
(3) 图6是用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。即非对称个卷积核,其实类似于卷积运算中,二维分解为1维计算,提高了计算速度。
13、ResNet
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。
训练神经网络的反向传播,导致很容易出现梯度消失。
对常规的网络(plain network,也称平原网络)直接堆叠很多层次,经对图像识别结果进行检验,训练集、测试集的误差结果如下图:
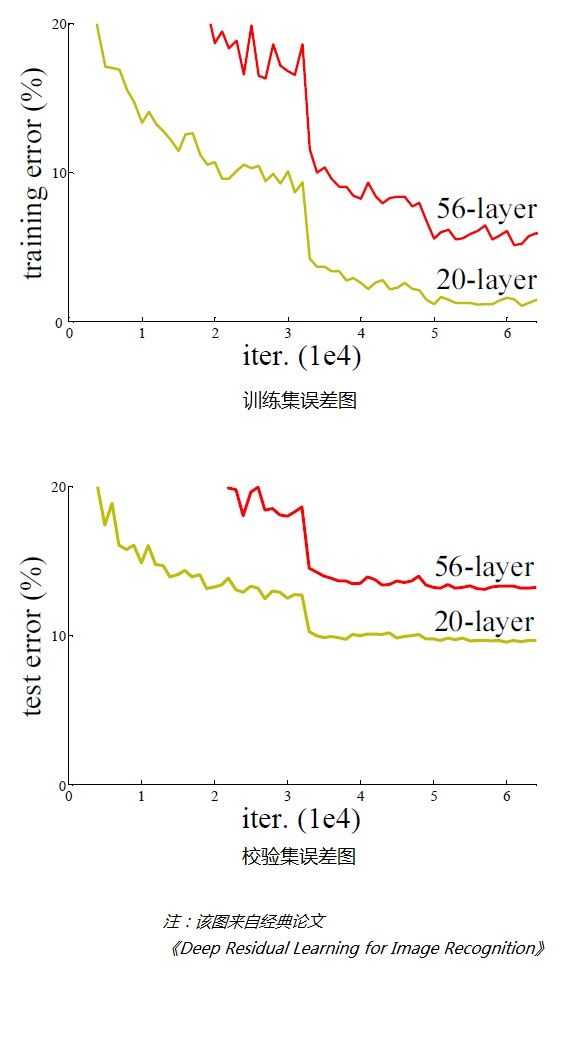
从上面两个图可以看出,在网络很深的时候(56层相比20层),模型效果却越来越差了(误差率越高),并不是网络越深越好。
通过实验可以发现:随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。
下图是一个简单神经网络图,由输入层、隐含层、输出层构成:

回想一下神经网络反向传播的原理,先通过正向传播计算出结果output,然后与样本比较得出误差值Etotal

根据误差结果,利用著名的“链式法则”求偏导,使结果误差反向传播从而得出权重w调整的梯度。下图是输出结果到隐含层的反向传播过程(隐含层到输入层的反向传播过程也是类似):

通过不断迭代,对参数矩阵进行不断调整后,使得输出结果的误差值更小,使输出结果与事实更加接近。
从上面的过程可以看出,神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
那么,如何又能加深网络层数、又能解决梯度消失问题、又能提升模型精度呢?
13.1 ResNet的提出
前面描述了一个实验结果现象,在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降,示意图如下:
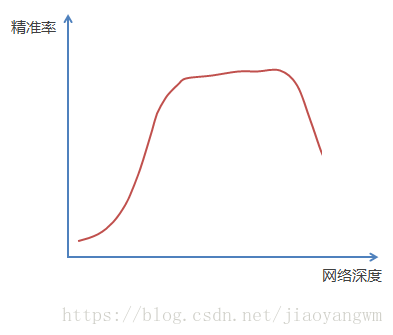
那么我们作这样一个假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:
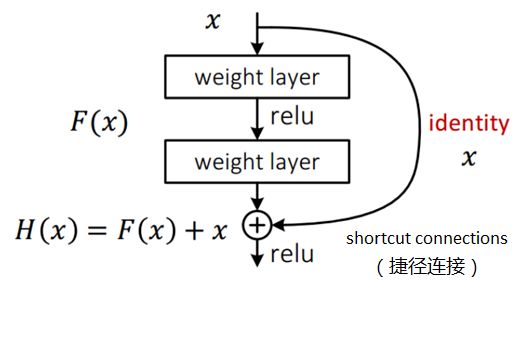
残差网络借鉴了高速网络的跨层连接的思想,但是对其进行了改进,残差项原本是带权值的,但ResNet用恒等映射代替了它。
假设:
神经网络输入:x
期望输出:H(x),即H(x)是期望的复杂映射,如果要学习这样的模型,训练的难度会比较大。
此时,如果已经学习到较为饱和的准确率,或者发现下层的误差变大时,接下来的目标就转化为恒等映射的学习,也就是使得输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
上图的残差网络中,通过捷径连接的方式直接将输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,H(x)=x,也就是恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
学习的目标:目标值H(x)和输入x的差值,即F(x):=H(x)-x,将残差逼近于0,使得随着网络加深,准确率不下降。
13.2 ResNet的意义
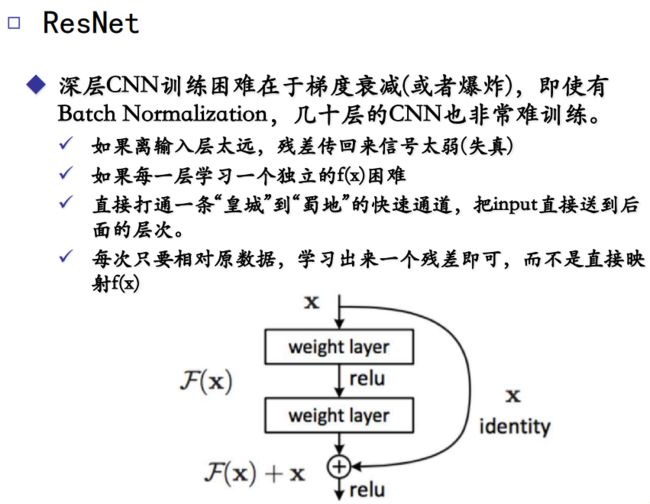
图像是层次非常深的数据,所以要层次深的网络来进行特征提取,网络深度是很有意义的。
一般的卷积神经网络,输入图像x,输出卷积后的特征F(x),一次性抽出所有的信息,梯度消失会出现,Res网络就说只学习残差即可。
第一条直接向下传递的网络:试图从x中直接学习残差F(x)
第二条捷径网络:输入x
整合:将残差和x相加,即H(x)=F(x)+x,也就是所要求的映射H(x)
好处:只有一条通路的反向传播,会做连乘导致梯度消失,但现在有两条路,会变成求和的形式,避免梯度消失。后面的层可以看见输入,不至于因为信息损失而失去学习能力。
如果连乘的方式会造成梯度消失的话,那么连加。传统的网络每次学习会学习x->f(x)的完整映射,那么ResNet只学习残差的映射,
随着网络的加深,出现了训练集准确率下降的现象,但是我们又可以确定这不是由过拟合造成的,因为过拟合的情况下,训练集应该准确率很高,所以作者针对这个问题提出了一种全新的网络,称为深度残差网络,它能够允许网络尽可能的假设,其中引入了一种全新的结构:

残差指什么:
ResNet提出了两种mapping:
-
其一:identity mapping,指的“本身的线”,也就是公式中的
x x x,就是图中弯曲的曲线; -
其二:residual mapping,指的是“差”,也就是 y − x y-x y−x,所以残差指的是 F ( x ) 部 分 F(x)部分 F(x)部分,也就是除过identity mapping之外的其余的线;
所以最后的输出为,
y
=
F
(
x
)
+
x
y=F(x)+x
y=F(x)+x
为什么ResNet可以解决随着网络加深,准确率不下降的问题?
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
13.3 ResNet结构
传统的神经网络都是以层叠卷积层的方式提高网络深度,从而提高识别精度,但层叠过多的卷积层会出现一个问题,就是梯度消失,使得反向传播的过程中无法有效的将梯度更新到前面的网络层,导致前面的层的参数无法更新。
而BN和ResNet的skip connection就是为了解决这个问题,BN通过规范化输入数据,改变数据的分布,在前向传播的过程中,防止梯度消失的问题,而skip connection则能在后传过程中更好地把梯度传到更浅的层次中。
问题:为什么加了一个捷径就可以把梯度传到浅层网络?
这和神经网络参数更新的过程密切相关,cs231n 2016视频有很好的讲解。
前向传播:
首先x与w1相乘,得到1;1与w2相乘,得到0.1,以此类推,如下面的gif图绿色数字表示
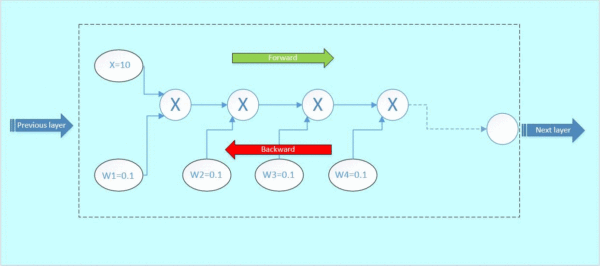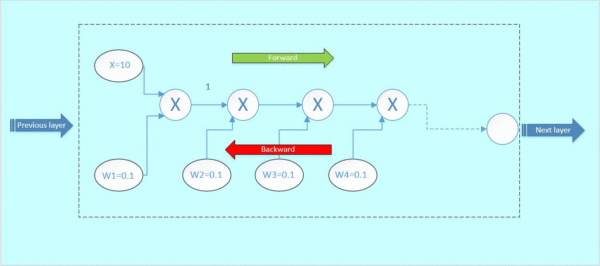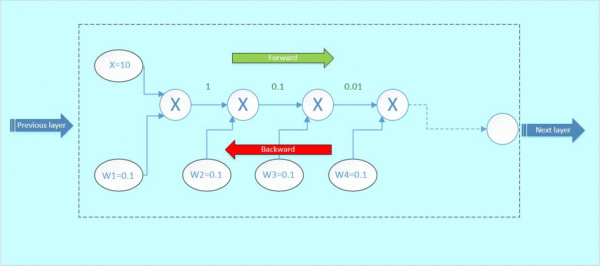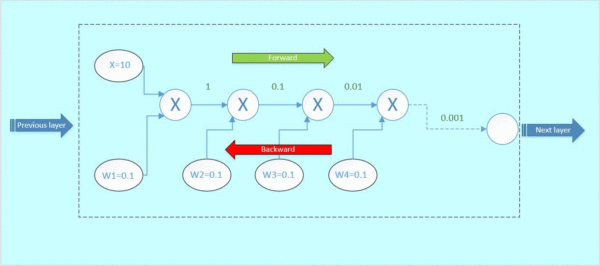
反向传播:
假设从下一层网络传回来的梯度为1(最右边的数字),后向传播的梯度数值如下面gif图红色数字表示:
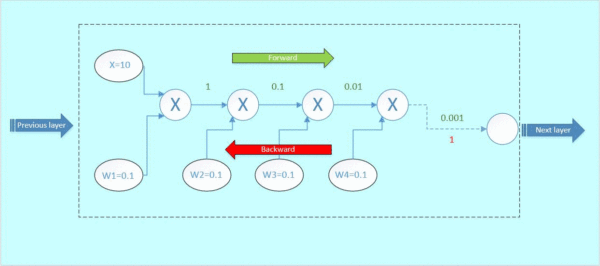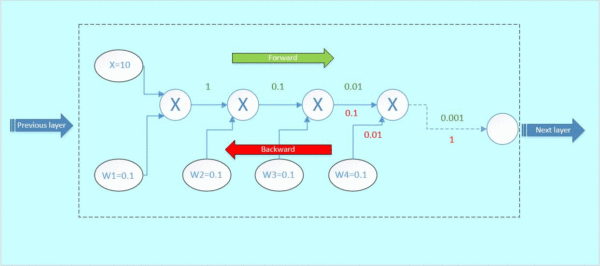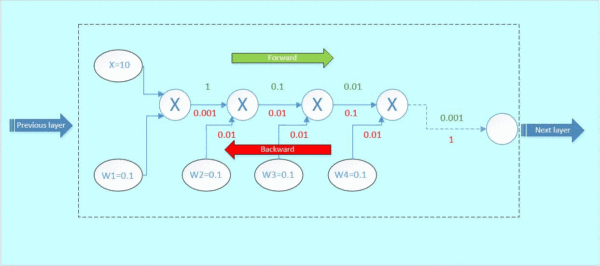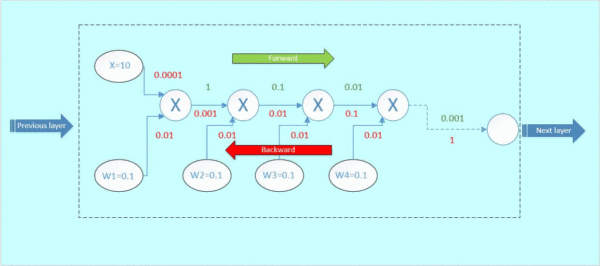
那么这里可以看到,本来从上一层传过来的梯度为1,经过这个block之后,得到的梯度已经变成了0.0001和0.01,也就是说,梯度流过一个blcok之后,就已经下降了几个量级,传到前一层的梯度将会变得很小!
当权重很小的时候,前向传播之后到输出层的参数值会非常小,反向传播时依然要和小的权重值相乘,参数值只会越来越小,数量级下降的非常快。
这就是梯度弥散。假如模型的层数越深,这种梯度弥散的情况就更加严重,导致浅层部分的网络权重参数得不到很好的训练,这就是为什么在Resnet出现之前,CNN网络都不超过二十几层的原因。
防止梯度消失的方法:

假如,我们在这个block的旁边加了一条“捷径”(如图5橙色箭头),也就是常说的“skip connection”。假设左边的上一层输入为x,虚线框的输出为f(x),上下两条路线输出的激活值相加为h(x),即h(x) = F(x) + x,得出的h(x)再输入到下一层。
当进行后向传播时,右边来自深层网络传回来的梯度为1,经过一个加法门,橙色方向的梯度为dh(x)/dF(x)=1,蓝色方向的梯度也为1。这样,经过梯度传播后,现在传到前一层的梯度就变成了[1, 0.0001, 0.01],多了一个“1”!正是由于多了这条捷径,来自深层的梯度能直接畅通无阻地通过,去到上一层,使得浅层的网络层参数等到有效的训练!
这个想法是何等的简约而伟大,不得不佩服作者的强大的思维能力!
ResNet网络:

直观理解:
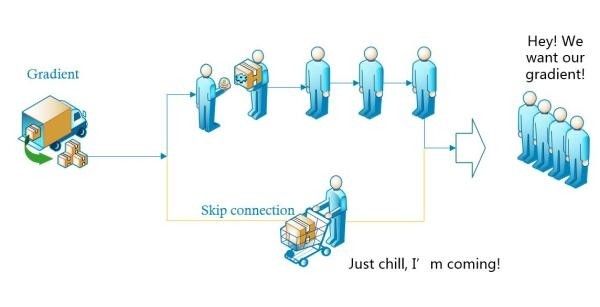
如图,左边来了一辆装满了“梯度”商品的货车,来领商品的客人一般都要排队一个个拿才可以,如果排队的人太多,后面的人就没有了。于是这时候派了一个人走了“快捷通道”,到货车上领了一部分“梯度”,直接送给后面的人,这样后面排队的客人就能拿到更多的“梯度”。
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解:
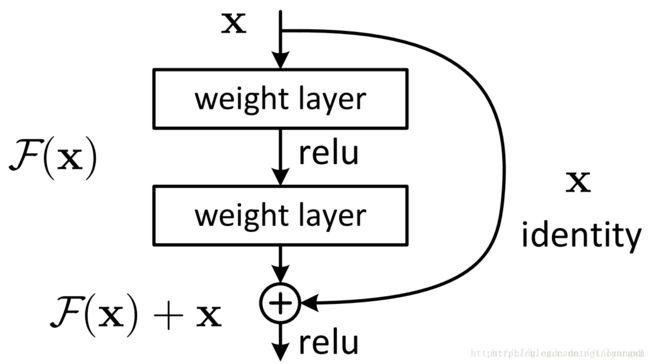
图1 Shortcut Connection
这是文章里面的图,我们可以看到一个“弯弯的弧线“这个就是所谓的”shortcut connection“,也是文中提到identity mapping,这张图也诠释了ResNet的真谛,当然真正在使用的ResNet模块并不是这么单一,文章中就提出了两种方式:

图2 两种ResNet设计
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个“building block”,其中右图为“bottleneck design”,目的就是为了降低参数数目,第一个1x1的卷积把256维的channel降到64维,然后在最后通过1x1卷积恢复,整体上用到参数数目+ 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量(实用目的)。
问题:图1中的F(x)和x的channel个数不同怎么办,因为F(x)和x是按照channel维度相加的,channel不同怎么相加呢?
解释:
针对channel个数是否相同,要分成两种情况考虑,如下图:
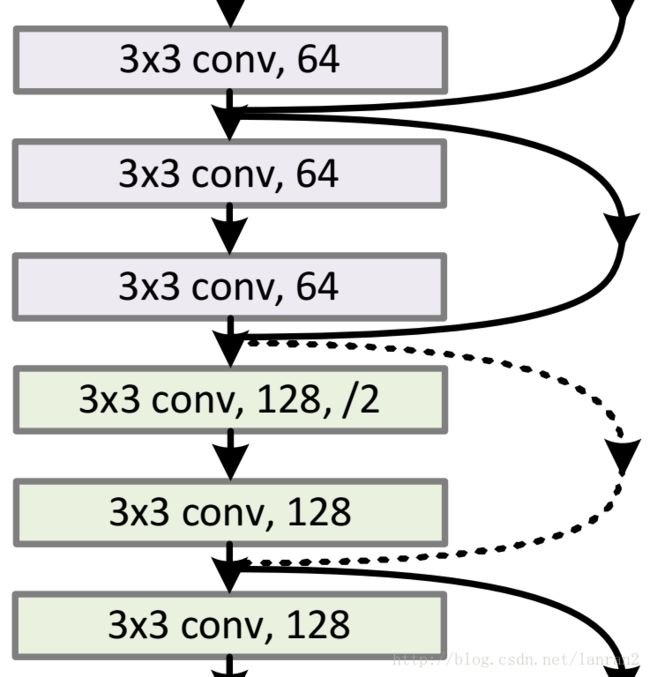
图3 两种Shortcut Connection方式
如图3所示,我们可以清楚的”实线“和”虚线“两种连接方式:
-
实线的的Connection部分(”第一个粉色矩形和第三个粉色矩形“)都是3x3x64的特征图,他们的channel个数一致,所以采用计算方式: $y=F(x)+x $
-
虚线的Connection部分(”第一个绿色矩形和第三个绿色矩形“)分别是3x3x64和3x3x128的特征图,他们的channel个数不同(64和128),所以采用计算方式: $y=F(x)+Wx $
其中W是卷积操作,用来调整x的channel维度的;
两个实例:

图4 两种Shortcut Connection方式实例(左图channel一致,右图channel不一样)
13.4 ResNet50和ResNet101
这里把ResNet50和ResNet101特别提出,主要因为它们的出镜率很高,所以需要做特别的说明。给出了它们具体的结构:

表2,Resnet不同的结构
首先我们看一下表2,上面一共提出了5中深度的ResNet,分别是18,34,50,101和152,首先看表2最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,之后的其他论文也会专门用这个称呼指代ResNet50或者101的每部分。
拿101-layer那列,我们先看看101-layer是不是真的是101层网络,首先有个输入7x7x64的卷积,然后经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,最后有个fc层(用于分类),所以1 + 99 + 1 = 101层,确实有101层网络;
注:101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内;
这里我们关注50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,查了17个block,也就是17 x 3 = 51层。
13.5 基于ResNet101的Faster RCNN
文章中把ResNet101应用在Faster RCNN上取得了更好的结果,结果如下:
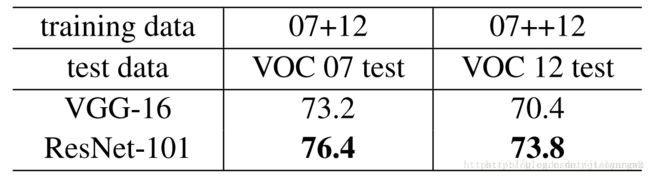

表3,Resnet101 Faster RCNN在Pascal VOC07/12 以及COCO上的结果
**问题:Faster RCNN中RPN和Fast RCNN的共享特征图用的是conv5_x的输出么? **
针对这个问题我们看看实际的基于ResNet101的Faster RCNN的结构图:
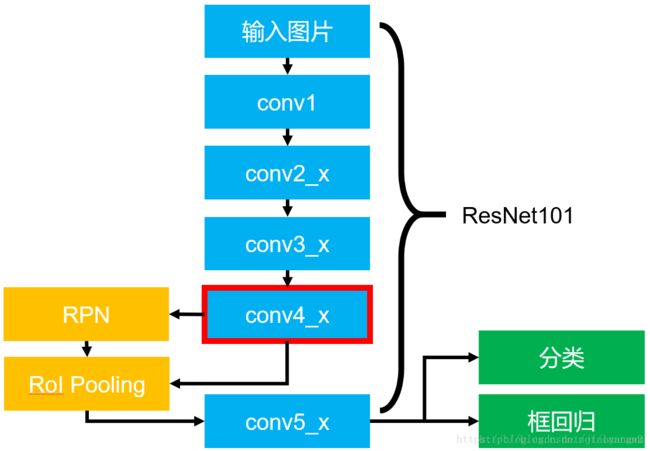
图5 基于ResNet101的Faster RCNN
图5展示了整个Faster RCNN的架构,其中蓝色的部分为ResNet101,可以发现conv4_x的最后的输出为RPN和RoI Pooling共享的部分,而conv5_x(共9层网络)都作用于RoI Pooling之后的一堆特征图(14 x 14 x 1024),特征图的大小维度也刚好符合原本的ResNet101中conv5_x的输入;
最后一定要记得最后要接一个average pooling,得到2048维特征,分别用于分类和框回归。
14、区域 CNN:R-CNN(2013年)、Fast R-CNN(2015年)、Faster R-CNN(2015年)
一些人可能会认为,R-CNN的出现比此前任何关于新的网络架构的论文都有影响力。第一篇关于R-CNN的论文被引用了超过1600次。Ross Girshick 和他在UC Berkeley 的团队在机器视觉上取得了最有影响力的进步。正如他们的文章所写, Fast R-CNN 和 Faster R-CNN能够让模型变得更快,更好地适应现代的物体识别任务。
R-CNN的目标是解决物体识别的难题。在获得特定的一张图像后, 我们希望能够绘制图像中所有物体的边缘。这一过程可以分为两个组成部分,一个是区域建议,另一个是分类。
论文的作者强调,任何分类不可知区域的建议方法都应该适用。Selective Search专用于RCNN。Selective Search 的作用是聚合2000个不同的区域,这些区域有最高的可能性会包含一个物体。在我们设计出一系列的区域建议之后,这些建议被汇合到一个图像大小的区域,能被填入到经过训练的CNN(论文中的例子是AlexNet),能为每一个区域提取出一个对应的特征。这个向量随后被用于作为一个线性SVM的输入,SVM经过了每一种类型和输出分类训练。向量还可以被填入到一个有边界的回归区域,获得最精准的一致性。非极值压抑后被用于压制边界区域,这些区域相互之间有很大的重复。
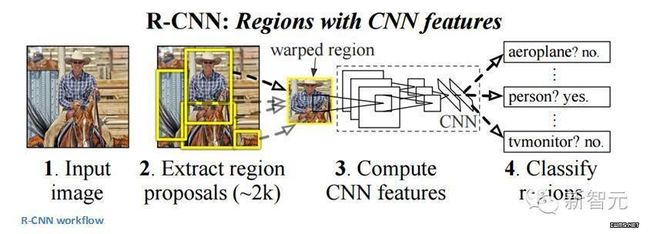
Fast R-CNN:
原始模型得到了改进,主要有三个原因:训练需要多个步骤,这在计算上成本过高,而且速度很慢。Fast R-CNN通过从根本上在不同的建议中分析卷积层的计算,同时打乱生成区域建议的顺利以及运行CNN,能够快速地解决问题。
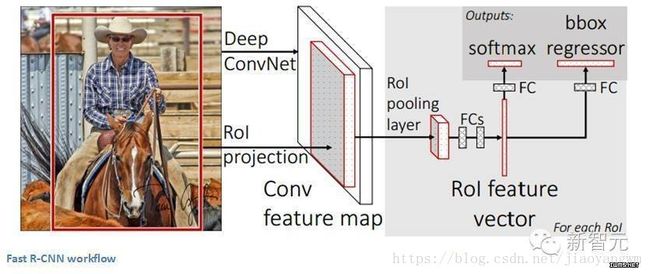
Faster R-CNN
Faster R-CNN的工作是克服R-CNN和 Fast R-CNN所展示出来的,在训练管道上的复杂性。作者 在最后一个卷积层上引入了一个区域建议网络(RPN)。这一网络能够只看最后一层的特征就产出区域建议。从这一层面上来说,相同的R-CNN管道可用。
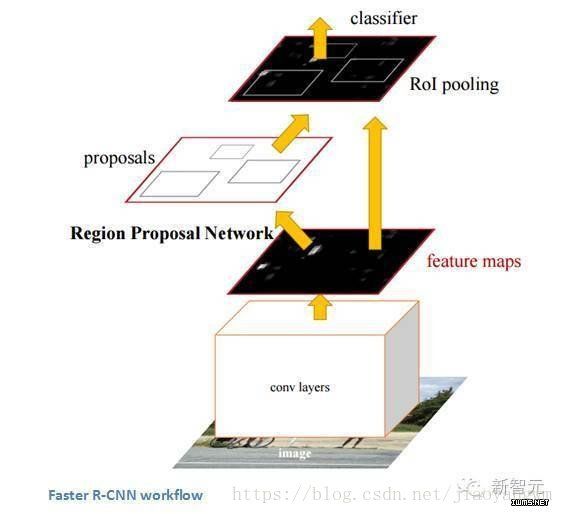
重要性:
能够识别出一张图像中的某一个物体是一方面,但是,能够识别物体的精确位置对于计算机知识来说是一个巨大的飞跃。更快的R-CNN已经成为今天标准的物体识别程序。
15、生成式对抗网络
按照Yann LeCun的说法,生成对抗网络可能就是深度学习下一个大突破。假设有两个模型,一个生成模型,一个判别模型。判别模型的任务是决定某幅图像是真实的(来自数据库),还是机器生成的,而生成模型的任务则是生成能够骗过判别模型的图像。这两个模型彼此就形成了“对抗”,发展下去最终会达到一个平衡,生成器生成的图像与真实的图像没有区别,判别器无法区分两者。

左边一栏是数据库里的图像,也即真实的图像,右边一栏是机器生成的图像,虽然肉眼看上去基本一样,但在CNN看起来却十分不同。
为什么重要?
听上去很简单,然而这是只有在理解了“数据内在表征”之后才能建立的模型,你能够训练网络理解真实图像和机器生成的图像之间的区别。因此,这个模型也可以被用于CNN中做特征提取。此外,你还能用生成对抗模型制作以假乱真的图片。
16、深度学习在计算机视觉上的应用
计算机视觉中比较成功的深度学习的应用,包括人脸识别,图像问答,物体检测,物体跟踪。
人脸识别:
这里说人脸识别中的人脸比对,即得到一张人脸,与数据库里的人脸进行比对;或同时给两张人脸,判断是不是同一个人。
这方面比较超前的是汤晓鸥教授,他们提出的DeepID算法在LWF上做得比较好。他们也是用卷积神经网络,但在做比对时,两张人脸分别提取了不同位置特征,然后再进行互相比对,得到最后的比对结果。最新的DeepID-3算法,在LWF达到了99.53%准确度,与肉眼识别结果相差无几。
图片问答问题:
这是2014年左右兴起的课题,即给张图片同时问个问题,然后让计算机回答。比如有一个办公室靠海的图片,然后问“桌子后面有什么”,神经网络输出应该是“椅子和窗户”。
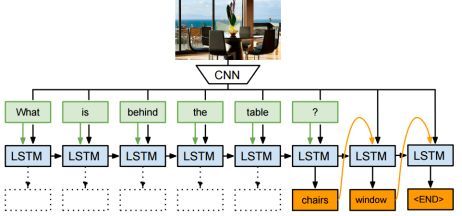
这一应用引入了LSTM网络,这是一个专门设计出来具有一定记忆能力的神经单元。特点是,会把某一个时刻的输出当作下一个时刻的输入。可以认为它比较适合语言等,有时间序列关系的场景。因为我们在读一篇文章和句子的时候,对句子后面的理解是基于前面对词语的记忆。
图像问答问题是基于卷积神经网络和LSTM单元的结合,来实现图像问答。LSTM输出就应该是想要的答案,而输入的就是上一个时刻的输入,以及图像的特征,及问句的每个词语。
物体检测问题:
① Region CNN
深度学习在物体检测方面也取得了非常好的成果。2014年的Region CNN算法,基本思想是首先用一个非深度的方法,在图像中提取可能是物体的图形块,然后深度学习算法根据这些图像块,判断属性和一个具体物体的位置。
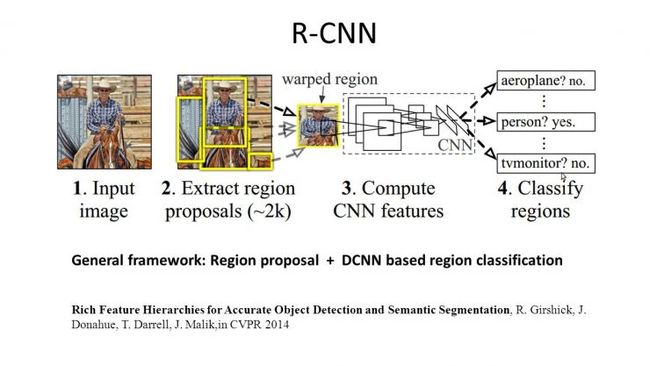
为什么要用非深度的方法先提取可能的图像块?因为在做物体检测的时候,如果你用扫描窗的方法进行物体监测,要考虑到扫描窗大小的不一样,长宽比和位置不一样,如果每一个图像块都要过一遍深度网络的话,这种时间是你无法接受的。
所以用了一个折中的方法,叫Selective Search。先把完全不可能是物体的图像块去除,只剩2000左右的图像块放到深度网络里面判断。那么取得的成绩是AP是58.5,比以往几乎翻了一倍。有一点不尽如人意的是,region CNN的速度非常慢,需要10到45秒处理一张图片。
② Faster R-CNN方法
而且我在去年NIPS上,我们看到的有Faster R-CNN方法,一个超级加速版R-CNN方法。它的速度达到了每秒七帧,即一秒钟可以处理七张图片。技巧在于,不是用图像块来判断是物体还是背景,而把整张图像一起扔进深度网络里,让深度网络自行判断哪里有物体,物体的方块在哪里,种类是什么?
经过深度网络运算的次数从原来的2000次降到一次,速度大大提高了。
Faster R-CNN提出了让深度学习自己生成可能的物体块,再用同样深度网络来判断物体块是否是背景?同时进行分类,还要把边界和给估计出来。
Faster R-CNN可以做到又快又好,在VOC2007上检测AP达到73.2,速度也提高了两三百倍。
③ YOLO
去年FACEBOOK提出来的YOLO网络,也是进行物体检测,最快达到每秒钟155帧,达到了完全实时。它让一整张图像进入到神经网络,让神经网络自己判断这物体可能在哪里,可能是什么。但它缩减了可能图像块的个数,从原来Faster R-CNN的2000多个缩减缩减到了98个。

同时取消了Faster R-CNN里面的RPN结构,代替Selective Search结构。YOLO里面没有RPN这一步,而是直接预测物体的种类和位置。
YOLO的代价就是精度下降,在155帧的速度下精度只有52.7,45帧每秒时的精度是63.4。
④ SSD
在arXiv上出现的最新算法叫Single Shot MultiBox Detector,即SSD。
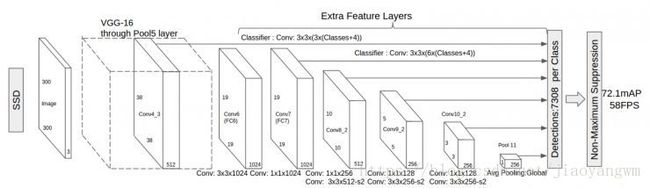
它是YOLO的超级改进版,吸取了YOLO的精度下降的教训,同时保留速度快的特点。它能达到58帧每秒,精度有72.1。速度超过Faster R-CNN 有8倍,但达到类似的精度。
物体跟踪
所谓跟踪,就是在视频里面第一帧时锁定感兴趣的物体,让计算机跟着走,不管怎么旋转晃动,甚至躲在树丛后面也要跟踪。
深度学习对跟踪问题有很显著的效果。是第一在线用深度学习进行跟踪的文章,当时超过了其它所有的浅层算法。
今年有越来越多深度学习跟踪算法提出。去年十二月ICCV 2015上面,马超提出的Hierarchical Convolutional Feature算法,在数据上达到最新的记录。它不是在线更新一个深度学习网络,而是用一个大网络进行预训练,然后让大网络知道什么是物体什么不是物体。
将大网络放在跟踪视频上面,然后再分析网络在视频上产生的不同特征,用比较成熟的浅层跟踪算法来进行跟踪,这样利用了深度学习特征学习比较好的好处,同时又利用了浅层方法速度较快的优点。效果是每秒钟10帧,同时精度破了记录。
最新的跟踪成果是基于Hierarchical Convolutional Feature,由一个韩国的科研组提出的MDnet。它集合了前面两种深度算法的集大成,首先离线的时候有学习,学习的不是一般的物体检测,也不是ImageNet,学习的是跟踪视频,然后在学习视频结束后,在真正在使用网络的时候更新网络的一部分。这样既在离线的时候得到了大量的训练,在线的时候又能够很灵活改变自己的网络。
基于嵌入式系统的深度学习
回到ADAS问题(慧眼科技的主业),它完全可以用深度学习算法,但对硬件平台有比较高的要求。在汽车上不太可能把一台电脑放上去,因为功率是个问题,很难被市场所接受。
现在的深度学习计算主要是在云端进行,前端拍摄照片,传给后端的云平台处理。但对于ADAS而言,无法接受长时间的数据传输的,或许发生事故后,云端的数据还没传回来。
那是否可以考虑NVIDIA推出的嵌入式平台?NVIDIA推出的嵌入式平台,其运算能力远远强过了所有主流的嵌入式平台,运算能力接近主流的顶级CPU,如台式机的i7。那么慧眼科技在做工作就是要使得深度学习算法,在嵌入式平台有限的资源情况下能够达到实时效果,而且精度几乎没有减少。
具体做法是,首先对网络进行缩减,可能是对网络的结构缩减,由于识别场景不同,也要进行相应的功能性缩减;另外要用最快的深度检测算法,结合最快的深度跟踪算法,同时自己研发出一些场景分析算法。三者结合在一起,目的是减少运算量,减少检测空间的大小。在这种情况下,在有限资源上实现了使用深度学习算法,但精度减少的非常少。
17、深度有监督学习在计算机视觉领域的进展
17.1 图像分类
自从Alex和他的导师Hinton(深度学习鼻祖)在2012年的ImageNet大规模图像识别竞赛(ILSVRC2012)中以超过第二名10个百分点的成绩(83.6%的Top5精度)碾压第二名(74.2%,使用传统的计算机视觉方法)后,深度学习真正开始火热,卷积神经网络(CNN)开始成为家喻户晓的名字,从12年的AlexNet(83.6%),到2013年ImageNet 大规模图像识别竞赛冠军的88.8%,再到2014年VGG的92.7%和同年的GoogLeNet的93.3%,终于,到了2015年,在1000类的图像识别中,微软提出的残差网(ResNet)以96.43%的Top5正确率,达到了超过人类的水平(人类的正确率也只有94.9%).
Top5精度是指在给出一张图片,模型给出5个最有可能的标签,只要在预测的5个结果中包含正确标签,即为正确
17.2 图像检测(Image Dection)
伴随着图像分类任务,还有另外一个更加有挑战的任务–图像检测,图像检测是指在分类图像的同时把物体用矩形框给圈起来。从14年到16年,先后涌现出R-CNN,Fast R-CNN, Faster R-CNN, YOLO, SSD等知名框架,其检测平均精度(mAP),在计算机视觉一个知名数据集上PASCAL VOC上的检测平均精度(mAP),也从R-CNN的53.3%,到Fast RCNN的68.4%,再到Faster R-CNN的75.9%,最新实验显示,Faster RCNN结合残差网(Resnet-101),其检测精度可以达到83.8%。深度学习检测速度也越来越快,从最初的RCNN模型,处理一张图片要用2秒多,到Faster RCNN的198毫秒/张,再到YOLO的155帧/秒(其缺陷是精度较低,只有52.7%),最后出来了精度和速度都较高的SSD,精度75.1%,速度23帧/秒。

####17.3 图像分割(Semantic Segmentation)
图像分割也是一项有意思的研究领域,它的目的是把图像中各种不同物体给用不同颜色分割出来,如下图所示,其平均精度(mIoU,即预测区域和实际区域交集除以预测区域和实际区域的并集),也从最开始的FCN模型(图像语义分割全连接网络,该论文获得计算机视觉顶会CVPR2015的最佳论文的)的62.2%,到DeepLab框架的72.7%,再到牛津大学的CRF as RNN的74.7%。该领域是一个仍在进展的领域,仍旧有很大的进步空间。

17.4 图像标注–看图说话(Image Captioning)
图像标注是一项引人注目的研究领域,它的研究目的是给出一张图片,你给我用一段文字描述它,如图中所示,图片中第一个图,程序自动给出的描述是“一个人在尘土飞扬的土路上骑摩托车”,第二个图片是“两只狗在草地上玩耍”。由于该研究巨大的商业价值(例如图片搜索),近几年,工业界的百度,谷歌和微软 以及学术界的加大伯克利,深度学习研究重地多伦多大学都在做相应的研究。

####17.5 图像生成–文字转图像(Image Generator)
图片标注任务本来是一个半圆,既然我们可以从图片产生描述文字,那么我们也能从文字来生成图片。如图6所示,第一列“一架大客机在蓝天飞翔”,模型自动根据文字生成了16张图片,第三列比较有意思,“一群大象在干燥草地行走”(这个有点违背常识,因为大象一般在雨林,不会在干燥草地上行走),模型也相应的生成了对应图片,虽然生成的质量还不算太好,但也已经中规中矩。

18、强化学习(Reinforcement Learning)
在监督学习任务中,我们都是给定样本一个固定标签,然后去训练模型,可是,在真实环境中,我们很难给出所有样本的标签,这时候,强化学习就派上了用场。简单来说,我们给定一些奖励或惩罚,强化学习就是让模型自己去试错,模型自己去优化怎么才能得到更多的分数。2016年大火的AlphaGo就是利用了强化学习去训练,它在不断的自我试错和博弈中掌握了最优的策略。利用强化学习去玩flyppy bird,已经能够玩到几万分了。
强化学习在机器人领域和自动驾驶领域有极大的应用价值,当前arxiv上基本上每隔几天就会有相应的论文出现。机器人去学习试错来学习最优的表现,这或许是人工智能进化的最优途径,估计也是通向强人工智能的必经之路。