【目标检测】55、损失函数 | 分类检测分割中的损失函数和评价指标
文章目录
-
- 一、分类
-
- 1.1 CrossEntropy Loss
- 1.2 带权重的交叉熵Loss
- 1.3 Focal Loss
- 1.4 Varifocal loss
- 二、检测
-
- 2.1 bbox 回归损失函数
-
- 2.1.1 L1 损失
- 2.1.2 L2 损失
- 2.1.3 Smooth L1 损失
- 2.1.4 IoU 损失
- 2.1.5 GIoU 损失
- 2.1.6 Distance-IoU 损失
- 2.1.7 Foal-EIoU 损失
- 2.1.8 R-IoU 损失
- 2.1.9 Alpha-IoU 损失
- 2.2 评价指标
-
- 2.2.1 PR 曲线
- 2.2.2 AP
- 2.2.3 mAP
- 2.2.4 ROC 曲线
- 2.3 NMS
- 三、分割
-
- 3.1 Dice Loss
- 3.2 语义分割中的 IoU
本博客还有多个超详细综述,感兴趣的朋友可以移步:
卷积神经网络:卷积神经网络超详细介绍
目标检测:目标检测超详细介绍
语义分割:语义分割超详细介绍
NMS:让你一文看懂且看全 NMS 及其变体
数据增强:一文看懂计算机视觉中的数据增强
损失函数:分类检测分割中的损失函数和评价指标
Transformer:A Survey of Visual Transformers
机器学习实战系列:决策树
YOLO 系列:v1、v2、v3、v4、scaled-v4、v5、v6、v7、yolof、yolox、yolos、yolop
损失函数是用来衡量真实值和预测值不一致程度的,越小越好。
一、分类
1.1 CrossEntropy Loss
信息量:用来衡量一个事件所包含的信息大小,一个事件发生的概率越大,则不确定性越小,信息量越小。公式如下,从公式中可以看出,信息量是概率的负对数:
h ( x ) = − l o g 2 p ( x ) h(x) = -log_2p(x) h(x)=−log2p(x)
熵:用来衡量一个系统的混乱程度,代表系统中信息量的总和,是信息量的期望,信息量总和越大,表明系统不确定性就越大。
E n t r o p y = − ∑ p l o g ( p ) Entropy = -\sum p log(p) Entropy=−∑plog(p)
交叉熵:用来衡量实际输出和期望输出的接近程度的量,交叉熵越小,两个概率分布就越接近。
L = ∑ c = 1 M y c l o g ( p c ) L = \sum_{c=1}^My_clog(p_c) L=c=1∑Myclog(pc)
其中,M表示类别数, y c y_c yc是label,即one-hot向量, p c p_c pc是预测概率,当M=2时,就是二元交叉熵损失
pytorch中的交叉熵:
Pytorch中CrossEntropyLoss()函数的主要是将softmax-log-NLLLoss合并到一块得到的结果。
- Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。
- 然后将Softmax之后的结果取log,将乘法改成加法减少计算量,同时保障函数的单调性 。
- NLLLoss的结果就是把上面的输出与Label对应的那个值拿出来,去掉负号,再求均值。
交叉熵loss可以用到大多数语义分割场景中,但他有一个明显的缺点,对于只用分割前景和背景时,前景数量远远小于背景像素的数量,损失函数中y=0的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
语义分割 cross entropy loss计算方式:
输入 model_output=[2, 19, 128, 256] # 19 代表输出类别
标签 target=[2, 512,1024]
1、将model_output的维度上采样到 [512, 1024]
2、softmax处理:这个函数的输入是网络的输出预测图像,输出是在dim=1(19)上计算概率。输出维度不变,dim=1维度上的值变成了属于每个类别的概率值。
x_softmax = F.softmax(x,dim=1)
3、log处理:
log_softmax_output = torch.log(x_softmax)
4、nll_loss 函数(negative log likelihood loss):这个函数目的就是把标签图像的元素值,作为索引值,在temp3中选择相应的值,并求平均。
output = nn.NLLLoss(log_softmax_output, target)
如果第一个点真值对应的3,则在预测结果中第3个通道去找该点的预测值,假设该点预测结果为-0.62,因为是loss前右负号,则最终结果变为0.62。其余结果依次类推,最后求均值即时最终损失结果。
- 当一个点真实类别=3时,假设其对应第三个类别的特征图上的点为0.9,则其-log的结果非常接近0,此时loss会非常小
- 当一个点真实类别=3时,假设其对应第三个类别的特征图上的点为0.2,则其-log的结果会比较大,此时loss会非常大

1.2 带权重的交叉熵Loss
L = ∑ c = 1 M w c y c l o g ( p c ) L = \sum_{c=1}^Mw_cy_clog(p_c) L=c=1∑Mwcyclog(pc)
这个参数 w c w_c wc计算公式为 w c = N − N c N w_c = \frac{N-N_c}{N} wc=NN−Nc,其中N表示总的像素格式, N c N_c Nc 表示GT类别为c的像素个数,相比原来的loss,在样本数量不均衡的情况下可以获得更好的效果。
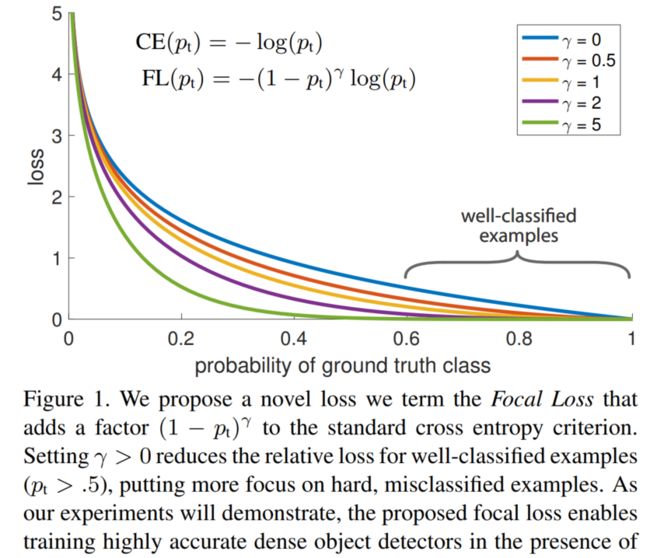
1.3 Focal Loss
在one-stage检测算法中,目标检测器通常会产生10k数量级的框,但只有极少数是正样本,会导致正负样本数量不平衡以及难易样本数量不平衡的情况,为了解决这一问题提出了focal loss。
Focal Loss是为one-stage的检测器的分类分支服务的,它支持0或者1这样的离散类别label。
目的是解决样本数量不平衡的情况:
- 正样本loss增加,负样本loss减小
- 难样本loss增加,简单样本loss减小
一般分类时候通常使用交叉熵损失:
C r o s s E n t r o p y ( p , y ) = { − l o g ( p ) , y = 1 − l o g ( 1 − p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -log(p), & y=1 \\ -log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={−log(p),−log(1−p),y=1y=0
为了解决正负样本数量不平衡的问题,我们经常在二元交叉熵损失前面加一个参数 α \alpha α。负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定 α \alpha α的值来控制正负样本对总的loss的共享权重。 α \alpha α取比较小的值来降低负样本(多的那类样本)的权重。即:
C r o s s E n t r o p y ( p , y ) = { − α l o g ( p ) , y = 1 − ( 1 − α ) l o g ( 1 − p ) , y = 0 CrossEntropy(p,y)= \begin{cases} -\alpha log(p), & y=1 \\ -(1-\alpha) log(1-p), & y=0 \end{cases} CrossEntropy(p,y)={−αlog(p),−(1−α)log(1−p),y=1y=0
虽然平衡了正负样本的数量,但实际上,目标检测中大量的候选目标都是易分样本。这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。
因此,Focal loss 论文中认为易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本 。一个简单的想法就是只要我们将高置信度样本的损失降低一些, 也即是下面的公式:
F o c a l l o s s = { − ( 1 − p ) γ l o g ( p ) , y = 1 − p γ l o g ( 1 − p ) , y = 0 Focalloss = \begin{cases} -(1-p)^ \gamma log(p), & y=1 \\ -p^\gamma log(1-p), & y=0 \end{cases} Focalloss={−(1−p)γlog(p),−pγlog(1−p),y=1y=0
当 γ = 0 \gamma=0 γ=0 时,即为交叉熵损失函数,当其增加时,调整因子的影响也在增加,实验发现为2时效果最优。
假设取 γ = 2 \gamma=2 γ=2,如果某个目标置信得分p=0.9,即该样本学的非常好,那么这个样本的权重为 ( 1 − 0.9 ) 2 = 0.001 (1-0.9)^2=0.001 (1−0.9)2=0.001,损失贡献降低了1000倍。
为了同时平衡正负样本问题,Focal loss还结合了加权的交叉熵loss,所以两者结合后得到了最终的Focal loss:
F o c a l l o s s = { − α ( 1 − p ) γ l o g ( p ) , y = 1 − ( 1 − α ) p γ l o g ( 1 − p ) , y = 0 Focal loss = \begin{cases} -\alpha (1-p)^\gamma log(p), & y=1 \\ -(1-\alpha) p^\gamma log(1-p), & y=0 \end{cases} Focalloss={−α(1−p)γlog(p),−(1−α)pγlog(1−p),y=1y=0
取 α = 0.25 \alpha=0.25 α=0.25 在文中,即正样本要比负样本占比小,这是因为负样本易分。
单单考虑alpha的话,alpha=0.75时是最优的。但是将gamma考虑进来后,因为已经降低了简单负样本的权重,gamma越大,越小的alpha结果越好。最后取的是alpha=0.25,gamma=2.0
https://zhuanlan.zhihu.com/p/49981234
class FocalLoss(nn.Module):
def __init__(self, gamma=0, alpha=None, size_average=True):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
if isinstance(alpha,(float,int,long)): self.alpha = torch.Tensor([alpha,1-alpha])
if isinstance(alpha,list): self.alpha = torch.Tensor(alpha)
self.size_average = size_average
def forward(self, input, target):
if input.dim()>2:
input = input.view(input.size(0),input.size(1),-1) # N,C,H,W => N,C,H*W
input = input.transpose(1,2) # N,C,H*W => N,H*W,C
input = input.contiguous().view(-1,input.size(2)) # N,H*W,C => N*H*W,C
target = target.view(-1,1)
logpt = F.log_softmax(input)
logpt = logpt.gather(1,target)
logpt = logpt.view(-1)
pt = Variable(logpt.data.exp())
if self.alpha is not None:
if self.alpha.type()!=input.data.type():
self.alpha = self.alpha.type_as(input.data)
at = self.alpha.gather(0,target.data.view(-1))
logpt = logpt * Variable(at)
loss = -1 * (1-pt)**self.gamma * logpt
if self.size_average: return loss.mean()
else: return loss.sum()
1.4 Varifocal loss
Varifocal 论文中提出了一个概念 IACS:分类得分向量中的一个标量元素
- 真实类别位置的得分:预测框和真实框的 IoU
- 其他位置的得分:0
为了学习 IACS 得分( localization-aware 或 IoU-aware 的 classification score),作者设计了一个 Varifocal Loss,灵感得益于 Focal Loss。
Focal Loss:

- p:预测的类别得分, p ∈ [ 0 , 1 ] p\in[0,1] p∈[0,1]
- y:真实类别, y ∈ ± 1 y\in{\pm1} y∈±1
- 降低前景/背景中,简单样例对 Loss 的贡献
Varifocal Loss:

- p:预测的 IACS
- q:target score(真实类别:q 为预测和真值的 IoU,其他类别:q 为 0,如图 1)
Focal loss 对正负样本的处理是对等的(也就是使用相同的参数来加权),而 Varifocal loss 是使用不对称参数来对正负样本进行加权。
Varifocal loss 是如何不对等的处理前景和背景对 loss 的贡献的呢:VFL 只对负样本进行了的衰减,这是由于正样本太少了,希望更充分利用正样本的监督信号
- 对正样本,使用 q q q 进行了加权,如果正样本的 gt_IoU 很高时,则对 loss 的贡献更大一些,可以让网络聚焦于那些高质量的样本上,也就是说训练高质量的正例对AP的提升比低质量的更大一些。
- 对负样本,使用 p γ p^{\gamma} pγ 进行了降权,降低了负例对 loss 的贡献,因为负样本的预测 p p p 肯定更小,取次幂后更小,这样就能够降低负样本对 loss 的整体贡献了
二、检测
检测中有两个任务,分类+回归
2.1 bbox 回归损失函数
2.1.1 L1 损失
画图如下:
x = np.linspace(-2, 2, 300)
y = abs(x)
y2 = x**2
y3 = [0.5*(xx**2) if abs(xx)<1 else (abs(xx)-0.5) for xx in x]
plt.plot(x, y, label="L1")
plt.plot(x, y2, label="L2")
plt.plot(x, y3, label="Smooth L1")
plt.legend(loc=1)
plt.show()

L 1 ( x ) = ∣ x ∣ L_1(x)=|x| L1(x)=∣x∣
L1损失的梯度:
Δ L 1 ( e ) Δ ( e ) = { 1 , x > = 0 − 1 , o t h e r w i s e \frac{\Delta L_1(e)}{\Delta(e)}= \begin{cases} 1, & x>=0 \\ -1, & otherwise \end{cases} Δ(e)ΔL1(e)={1,−1,x>=0otherwise
2.1.2 L2 损失
L 2 ( x ) = x 2 L_2(x)=x^2 L2(x)=x2
L2损失的梯度:
Δ L 2 ( e ) Δ ( e ) = 2 e \frac{\Delta L_2(e)}{\Delta(e)}=2e Δ(e)ΔL2(e)=2e
L2 loss 的缺点:
- 对于不同质量的 anchor,可能得到相同的 L2 距离结果。
- L2 loss 对框的四个边分别优化,忽略了一个目标的四条边界之间的关系,可能导致一个框的某两条边非常准确,但另外的边误差很大。
- 对尺度非常敏感,大的 gt 框和其对应的 anchor 框可能距离较大,但相比框本身的大小来说这个距离较小,但模型会更注重大框的优化来拉低 Loss,忽略了一些小目标。
L1 loss 和 L2 loss 的对比:
- L1 Loss 相比较于L2 Loss收敛速度慢,0点处无梯度且其他位置梯度为常数,因此在极值点附近容易产生震荡,但其对离群点的处理上要好于L2 Loss。
- L1 Loss与L2 Loss都没有那么完美,因此就有了微软RGB大神在Fast RCNN中提出的Smooth L1 Loss,
2.1.3 Smooth L1 损失
公式如下:
s m o o t h L 1 ( x ) = { 0.5 x 2 , i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 , o t h e r w i s e smooth_{L1}(x) = \begin{cases} 0.5x^2, & if |x|<1 \\ |x|-0.5, & otherwise \end{cases} smoothL1(x)={0.5x2,∣x∣−0.5,if∣x∣<1otherwise
Smooth L1 Loss特点:
- 在 e 较大时,使用的L1 Loss的形式,以防止离群点的影响;
- 在 e 较小时,使用的L2 Loss的形式,以获得较小的梯度(收敛速度),防止在极值点附近震荡。
smooth L1 loss 相对于 L2 loss的优点:
- 当预测框和GT差别过大时,梯度值不会过大
- 当预测框和GT差别很小时,梯度值足够小
上面三种 Loss 用于计算目标检测的bounding-box loss时,独立的求出4个点的loss,然后进行相加得到最终的bounding-box loss。
2.1.4 IoU 损失
论文:UnitBox: An Advanced Object Detection Network
出处:ACM MM 2016
IoU loss:L1 和 L2 loss是将bbox四个点分别求loss然后相加,并没有考虑靠坐标之间的相关性,而实际评价指标 IoU 是具备相关性。
有一些情况的 L1 loss一样,但实际上两个框的 IoU 有很大的不同,所以难以很好的衡量 anchor 的质量。
IoU loss 常用版本:
L I o U = 1 − I o U L_{IoU} = 1-IoU LIoU=1−IoU

-
上图展示了L2 Loss和 IoU Loss 的求法,图中红点表示目标检测网络结构中Head部分上的点 ( i , j ) (i,j) (i,j),绿色的框表示GT框, 蓝色的框表示Prediction的框。
-
IoU loss的定义如上,先求出2个框的IoU,然后再求个 − l n ( I o U ) -ln(IoU) −ln(IoU),在实际使用中,实际很多IoU常常被定义为 I o U L o s s = 1 − I o U IoU Loss = 1-IoU IoULoss=1−IoU。
-
其中IoU是真实框和预测框的交集和并集之比,当它们完全重合时,IoU就是1,那么对于Loss来说,Loss是越小越好,说明他们重合度高,所以IoU Loss就可以简单表示为 1- IoU。
IoU Loss 的优点:
- 收敛速度快于 L2 loss
- 对尺度不太敏感,能够适应不同尺度的特征

IoU Loss 的缺点:
- 当两个框没有重叠的时候,IoU=0,则 IoU loss 始终为 1,无法优化
- IoU 只能反应两个框的交并比,无法反应其实如何相交的,如下图所示
- 当两个框为包含关系时,IoU 不变,无法继续优化

2.1.5 GIoU 损失
由于 IoU loss 无法反应两框如何相交,且无法优化未重叠框,则 GIoU Loss 被提出。
方法:
在 IoU 基础上加了一个惩罚项,当bbox的距离越大时,惩罚项将越大:

- C 是覆盖 B B B 和 B g t B^{gt} Bgt 的最小的盒子, ∣ C ∣ |C| ∣C∣ 表示其面积
- 引入该惩罚参数,距离越远,则 C 越大,该惩罚项就会越大,Loss 会越大
GIoU 的优点:
- 使用最小外接矩形的概念,解决了 IoU 不能处理的无相交情况的问题
- 惩罚项能够反映两个框的距离远近,距离越远,惩罚越大,能改善 IoU 对无重叠的框无法优化的问题
- 惩罚项能够反映两个框的重合质量,重合质量越高,则惩罚项越小,重合质量月底,则惩罚项越大
- GIoU 保留了 IoU 的一般特性,又避免了其缺点,可以代替 IoU 来衡量两个框的重叠质量
GIoU存在的问题:
- 两框包含的时候,GIoU会退化成IoU,IoU 是不变的,无法继续指导优化
- 使用惩罚项会让网络趋于选择更大的和 gt 有相交的 anchor,收敛速度很慢,当两框为包含关系时,退化为 IoU loss
- GIoU 主要是在收敛最小框面积-并集面积,作者经过实验发现这么收敛会导致网络优先选择扩大 bounding box 的面积来覆盖 ground truth,而不是去移动 bounding box 的位置去覆盖 ground truth,所以收敛很慢
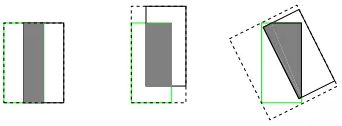
- 对水平和竖直条状的 anchor 回归的误差较大(如下图实验可视化图得到的)
2.1.6 Distance-IoU 损失
论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
代码:https://github.com/Zzh-tju/DIoU
出处:AAAI2020
DIoU 损失:
Distance-IoU 和 Complete-IoU 来自同一篇文章。
由于 GIoU 存在收敛较慢等问题,作者提出了新的损失函数。提出该损失函数的前提是,作者认为一个好的 loss 函数,需要同时考虑三个方面:
- 重叠面积
- 中心点距离
- 纵横比
所以,Distance-IoU 在 IoU 的基础上添加了对两个框中心点距离的约束,从公式可以看出,D-IoU 能够同时最小化外接矩形的面积和两框中心点的距离,这会使得网络更倾向于移动 bbox 的位置来减少 loss:

- b b b 和 b g t b^{gt} bgt 分别为中心点
- ρ \rho ρ 是欧式距离
- c c c 是最小包围盒的对角线距离

DIoU loss 的优点:
- DIoU Loss 是不随回归问题的尺度而变的
- DIoU Loss 可以给不和 gt box 相交的 anchor 提供移动的方向
- DIoU 可以直接最小化两个 bbox 的距离,加速收敛

DIoU 被用于 NMS 中,得到 DIoU-NMS,使用 DIoU 作为 NMS 中框排序的依据,同时考虑了重合率和中心点距离作为衡量指标。
对于有高得分的框 M,DIoU-NMS 被定义如下:

- B i B_i Bi 是同时考虑了 IoU 和中心点的距离后,才会被确定是否移除
- s i s_i si 是分类得分
- ϵ \epsilon ϵ 是 NMS 阈值
- 作者认为,两个框的中心点距离越远,则越可能是两个不同的目标,越不应该被移除。
- 所以 D − I o U − N M S D-IoU-NMS D−IoU−NMS 更加灵活有效
CIoU 损失:
当两个框中心点重合的情况下,DIoU loss 无法继续优化,c 和 d 的值都不变,所以引入了框的宽高比。
Complete-IoU 在 IoU 的基础上同时考虑了对中心点距离和纵横比的约束,公式如下:

其中:
- α \alpha α 是正的平衡参数
- v v v 是衡量纵横比的一致性的,也就是说要让两个框的 w / h w/h w/h 尽可能的相同, v v v 才会很低,所以这里并非是 w 和 h 进行单独的优化,而是优化的 w / h w/h w/h 这个值,让其和 gt 的尽量一致。

Loss 函数定义如下:

α \alpha α 定义如下,

CIoU 的优化和 DIoU 一致,除过 v v v 要对 w w w 和 h h h 分别求导:

- w 2 + h 2 w^2+h^2 w2+h2 通常是一个很小的值, h h h 和 w w w 都是 [0,1] 之间的值,容易出现梯度爆炸,所以令其为 1
CIoU 的优点(在 DIoU 优点的基础上):
- 同时考虑了相交比、中心点距离、纵横比来优化 anchor,加快了收敛速度
CIoU 的缺点:
- 当两个框为等比例缩放的时候, v = 0 v=0 v=0,难以被优化
- w w w 和 h h h 其中一个增大,另一个必然减小,无法同时增大或减小,抑制了模型的优化。
因为 ∂ v ∂ w = − h w . ∂ v ∂ h \frac{\partial v}{\partial w} = - \frac{h}{w}.\frac{\partial v}{\partial h} ∂w∂v=−wh.∂h∂v,而偏导又是正值,所以有这样的关系。 - 只关心两者比例,而非每个边对应的真实差距,容易导致不期望的优化方式。
2.1.7 Foal-EIoU 损失
虽然 CIoU 同时考虑了交并比、中心点距离和纵横比,但纵横比是对一个比例的优化,而非对单独参数的优化,导致 w 和 h 无法同大同小,必须一个变大,一个变小,这会限制模型的优化效果。所以 EIoU 将纵横比的优化改为了对 w 和 h 的单独优化,分别求两个框的 w 和 h 的差,用于模型优化。
EIoU Loss 定义如下:

- w c w^c wc 和 h c h^c hc 是最小包围框的宽和长
- EIoU loss 可以分为 3 部分:IoU loss + 距离 loss + 纵横比 loss
- EIoU loss 直接最小化 anchor 和 gt 的宽和高的差异,使得收敛速度更快,定位效果更好

Focal-EIoU 要实现的目标:IoU 越高的高质量样本,损失越大,也就是回归越好的目标,给的损失的权重越大,相当于加权,让网络更关注那些回归好的目标,毕竟后面还要做 NMS,低质量的框可以给更少的关注。
Focal-EIoU loss:
在框回归问题中,高质量的 anchor 总是比低质量的 anchor 少很多,这也对训练过程有害无利。所以,需要研究如何让高质量的 anchor 起到更大的作用。这里的高质量就是指的回归误差小的框。
下图中,经过实验, β = 0.8 \beta=0.8 β=0.8 效果最优,

所以 Focal-EIoU loss 公式如下, γ = 0.5 \gamma=0.5 γ=0.5 最优(图 9c):
L F o c a l − E I o U = I o U γ L E I o U L_{Focal-EIoU}=IoU^{\gamma} L_{EIoU} LFocal−EIoU=IoUγLEIoU
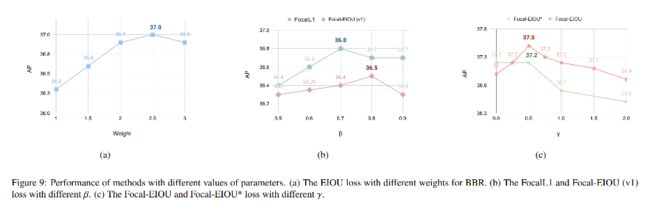
- γ \gamma γ 越大,会对难例(即 IoU 小的框)进行抑制,并减慢收敛速度
- γ = 0.5 \gamma =0.5 γ=0.5 效果最优
这里以 IoU loss 的形式来分析一下 Focal 形式的曲线(EIoU 曲线不太好画),蓝线为 ( 1 − I o U ) (1-IoU) (1−IoU) 曲线,橘色线为 I o U 0.5 ( 1 − I o U ) IoU^{0.5}(1-IoU) IoU0.5(1−IoU),所以在 IoU 小的时候(0-0.8), I o U 0.5 ( 1 − I o U ) IoU^{0.5}(1-IoU) IoU0.5(1−IoU) 会被拉低,在 IoU 大的时候(0.8-1), I o U 0.5 ( 1 − I o U ) IoU^{0.5}(1-IoU) IoU0.5(1−IoU) 基本保持不变。
从这个曲线可以看出,Focal-EIoU loss 能够通过降低难样本的 loss 来让网络更关注简单样本。

2.1.8 R-IoU 损失
作者认为,在检测任务中,IoU 经常被用来选择预选框,但这种直接的做法也忽略了样本分布的不均衡的特点,这会影响定位 loss 的梯度,从而影响最终的效果。
所以作者思考,能不能在训练的过程中不断 rectify 所有样本的梯度,来提升效果。于是就提出了 Rectified IoU (RIoU) loss。
该损失函数和 Focal-EIoU 类似,都是为了提高 high IoU 样本的权重,来让网络更关注简单样本,提升训练的稳定性,并且让不同难易程度的样本更平衡。
Rectified IoU (RIoU) loss 的目的:增大 high IoU 样本的梯度,抑制 low IoU 样本的梯度
Rectified IoU (RIoU) loss 的特点:在使用 RIoU 训练时,大量简单样本(IoU 大)的梯度会被增大,让网络更关注这些样本,而少量的难样本(IoU 小)的梯度会被抑制。这样会使得每种类型的样本的贡献更均衡,训练过程更高效和稳定。
为什么抑制难样本的梯度后,每类样本的贡献会更均衡呢?
因为 IoU 低的样本占大多数,所以对应的 loss 更大,所以作者通过提高简单样本对 loss 的贡献,来让难易样本的贡献更均衡。
L I o U L_{IoU} LIoU 的形式如下:
L I o U = 1 − I o U L_{IoU}=1-IoU LIoU=1−IoU
L I o U L_{IoU} LIoU 的偏导如下:
∣ g r a d i e n t s ( I o U ) ∣ = ∣ ∂ L I o U ∂ I o U ∣ = 1 |gradients(IoU)|=|\frac{\partial L_{IoU}}{\partial_{IoU}}|=1 ∣gradients(IoU)∣=∣∂IoU∂LIoU∣=1
由此可看出, ∣ g r a d i e n t s ( I o U ) ∣ |gradients(IoU)| ∣gradients(IoU)∣ 是一个常数,对难易样本无差别对待,但不同 IoU 样本的分布是很不均衡的。low IoU 样本的数量大于 high IoU 样本的数量,也就是说,在训练过程中,low IoU 样本掌握着梯度,让网络更偏向于难样本的回归。
Rectified IoU (RIoU) loss 的目的:增大 high IoU 样本的梯度,抑制 low IoU 样本的梯度
如何修正呢:
如果梯度总是随着 IoU 的增大而增大,则会面临一个问题,即当某个框回归的非常好时( I o U → 1 IoU \to 1 IoU→1),其梯度会最大,这是不合适的。
所以作者提出了如下的方式,a, b, c, k 可以控制梯度曲线的形状。上升后,在 I o U = β IoU =\beta IoU=β 处快速下降,本文 β = 0.95 \beta=0.95 β=0.95。
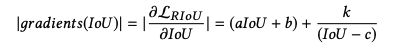

当 β = 0.95 \beta=0.95 β=0.95 时的 Loss 曲线对应如下, I o U < β IoU<\beta IoU<β 时是凸型, I o U > β IoU>\beta IoU>β 时是凹型:


2.1.9 Alpha-IoU 损失
前面了 Focal-EIoU 和 R-IoU loss 都是通过提高 high IoU object 对 loss 的贡献,来平稳训练过程,提升训练效果,这两个方法主要是提高 high IoU object 的梯度,但这两者都不够简洁,并且没有进行全面的实验对比。
所以有研究者提出了一个对 IoU loss 的统一形式,通过 power transformation 来生成 IoU 和其对应惩罚项的统一形式,来动态调整不同 IoU 目标的 loss 和 gradient。
α \alpha α-IoU 的形式是怎样的:
首先,在 IoU loss L I o U = 1 − I o U L_{IoU} = 1-IoU LIoU=1−IoU 上使用 Box-Cox 变换,得到 α \alpha α-IoU:
L α − I o U = ( 1 − I o U α ) α , α > 0 L_{\alpha-IoU}=\frac{(1-IoU^{\alpha})}{\alpha}, \alpha>0 Lα−IoU=α(1−IoUα),α>0
对 α \alpha α 的分析如下,可以得到很多形式:
- 当 α → 0 \alpha \to 0 α→0, l i m α → 0 L α − I o U = − l o g ( I o U ) = L l o g ( I o U ) lim_{\alpha \to 0}L_{\alpha-IoU}=-log(IoU)=L_{log(IoU)} limα→0Lα−IoU=−log(IoU)=Llog(IoU)
- 当 α = 1 \alpha=1 α=1 时, L 1 − I o U = 1 − I o U = L I o U L_{1-IoU}=1-IoU=L_{IoU} L1−IoU=1−IoU=LIoU
- 当 α = 2 \alpha=2 α=2 时, L 2 − I o U = 1 2 ( 1 − I o U 2 ) = 1 2 L I o U 2 L_{2-IoU}=\frac{1}{2}(1-IoU^2)=\frac{1}{2}L_{IoU^2} L2−IoU=21(1−IoU2)=21LIoU2
对 α \alpha α-IoU 简化得到:


图 1 左侧展示了 IoU 和 L I o U L_{IoU} LIoU 的关系,图 1 右侧展示了 IoU 和梯度模值的关系。
- IoU Loss( α = 1 \alpha=1 α=1)和 IoU 呈线性关系,梯度是恒值
- L α − I o U L_{\alpha-IoU} Lα−IoU 会动态 reweight 不同 IoU 的目标的 loss, α > 1 \alpha>1 α>1 时,是凸型曲线,会增大 loss, 0 < α < 1 0<\alpha<1 0<α<1 时,是凹型曲线,会降低 loss
- 从 loss 的斜率来看,high iou 处,斜率更大,更有利于参数更新。
α > 1 \alpha>1 α>1,能够让网络更加关注 high IoU 的样本,且能够在训练后期提升训练效果,本文作者发现 α = 3 \alpha=3 α=3 对大多数情况表现都较好,所以选择了 α = 3 \alpha=3 α=3。
L α − I o U L_{\alpha-IoU} Lα−IoU 是如何动态调整的:
- 动态策略是基于绝对和相对特性的
- α > 1 \alpha>1 α>1 时,会先学习简单样本,提升到 I o U = 1 IoU=1 IoU=1,后面学习难样本,如图 3 所示,up-weighting 高 IoU 样本的 loss 和 gradient 会在训练后期提升效果
- 0 < α < 1 0<\alpha<1 0<α<1 时,会降低高 IoU 样本的 loss 和 gradient,使得定位效果变差。

2.2 评价指标
- mAP: mean Average Precision, 即各类别AP的平均值
- AP: PR曲线下面积,后文会详细讲解
- PR曲线: Precision-Recall曲线
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
一般来说mAP针对整个数据集而言的;AP针对数据集中某一个类别而言的;而percision和recall针对单张图片某一类别的。
2.2.1 PR 曲线
precision = TP/( TP+FP)
recall/TPR = TP/(TP+FN)
FPR = FP/(FP+TN)
F1 = 2TP/(2TP+FP+FN)
PR 曲线:Precision 纵轴,Recall 横轴
如果模型的精度越高,召回率越高,那么模型的性能越好。也就是说PR曲线下面的面积越大,模型的性能越好。绘制的时候也是设定不同的分类阈值来获得对应的坐标,从而画出曲线。
PR 曲线特点:
- PR曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡。
- PR曲线有一个缺点就是会受到正负样本比例的影响。比如当负样本增加10倍后,在racall不变的情况下,必然召回了更多的负样本,所以精度就会大幅下降,所以PR曲线对正负样本分布比较敏感。对于不同正负样本比例的测试集,PR曲线的变化就会非常大。
2.2.2 AP
AP 是以每个数据集计算一个值,也定义为 PR 曲线下的面积:
A P = ∫ 0 1 p ( r ) d r AP =\int_0^1p(r) dr AP=∫01p(r)dr
不同数据集某个类别的AP计算方法大同小异,主要有三种:
-
VOC2010之前,选取当 recall>=0, 0.1, 0.2, 1.0 这11个点时的 precision 最大值,然后将其平均就是 AP, mAP 就是所有类别 AP 的平均,也就是 AP 计算之前,会对 PR 曲线进行平滑,平滑方法为对每一个 Precision值,使用其右边最大的precision值替代,如下图所示:

平滑之后就变成了红色的虚线,实际计算的时候对这11个点(0.1间隔)求平均即可。

-
VOC2010之后,需要针对每一个不同的recall值(包括0和1),选取其>=这些recall值的precision最大值,然后计算PR曲线下的面积作为AP值。
由于上述11点法插值点数过少,容易导致结果不准,一个解决方法就是内插所有点,也就是对上述平滑之后的曲线计算曲线下的面积。
-
COCO数据集,设定多个IoU阈值(0.5~0.95,step为0.005),在每个IoU阈值下的AP平均,就是所求的最终的某类别的AP值。
COCO 数据集来说,其实也是内插 AP 的计算方式,但与 VOC2008 不同的是,COCO 在 PR 曲线上采样了 100 个点进行计算,IoU 的阈值从固定的 0.5 调整为 0.5~0.95(间隔 0.05)区间上每隔 0.05 计算一次 AP 的值,取所有结果的平均值作为最终结果。而且在 COCO 语境下,AP 就是 mAP。
-
A P 50 AP_{50} AP50:IoU阈值为0.5时的AP测量值
-
A P 75 AP_{75} AP75:IoU阈值为0.75时的测量值
-
A P S AP_{S} APS : 像素面积小于 3 2 2 32^2 322 的目标框的AP测量值
-
A P M AP_{M} APM : 像素面积在 3 2 2 32^2 322 - 9 6 2 96^2 962 之间目标框的测量值
-
A P L AP_{L} APL : 像素面积大于 9 6 2 96^2 962 的目标框的AP测量值
-
计算某个类别的 AP:
我们知道 AP 是 PR 曲线下的面积,所以首先需要绘制这个类别的 PR 曲线。
第一步:计算 Precision 和 Recall
- P r e c i s i o n = T P / ( T P + F P ) Precision = TP/(TP+FP) Precision=TP/(TP+FP)
- R e c a l l = T P / ( T P + F N ) Recall = TP/(TP+FN) Recall=TP/(TP+FN)
第二步:统计 TP/FP/FN
- 通过阈值过滤掉低于置信得分阈值的预测结果
- 将剩下的框按置信得到从高到第排序
- 将得分最高的框和GT判断其 IoU:
- 如果 IoU>th,则判定为 TP,其余框都判定为 FP
- 如果 IoU
- 由于图片中某个类别一共多少个 GT 我们是已知的,所以 GT-TP=FN
2.2.3 mAP
mAP 是数据集中所有类别AP的平均值
2.2.4 ROC 曲线
ROC 曲线:FPR 横轴,TPR 纵轴
特点:
- ROC曲线有个很好的特性,当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。
- ROC曲线可以反映二分类器的总体分类性能,但是无法直接从图中识别出分类最好的阈值,事实上最好的阈值也是视具体的场景所定。ROC曲线一定在y=x之上,否则就是一个不好的分类器。
ROC曲线特点:
-
优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
-
缺点:提到ROC曲线的优点是不会随着类别分布的改变而改变,这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不对了。在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。ROC曲线的横轴采用FPR,根据FPR ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(也可以只分析ROC曲线左边一小段)。
PR曲线:
PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
使用场景:
1、ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
2、如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
3、如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
4、类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
5、最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
2.3 NMS
非极大值抑制:在所有预测结果中先保留得分最高的框,然后剔除掉和该框iou大于设定阈值的框
测试的时候需要做 NMS,上述的 mAP 等指标也是在做了 NMS 之后才计算的,因为训练的时候需要大量的正负样本来学习。
计算步骤:
- 计算出每个b-box的面积,然后根据置信度进行排序,把置信度最大的 b-box 作为对列中首个要比较的对象
- 计算其余b-box与当前最大score框的iou,丢掉iou大于设定阈值的b-box,保留小iou的框
- 重复上面过程直到走完所有候选框
三、分割
分割其实是对每个像素点进行分类,一般也就是使用分类的损失,如交叉熵等。
3.1 Dice Loss
Dice Loss:
D i c e L o s s = 1 − D i c e C o e f f i c i e n t Dice Loss = 1-Dice Coefficient DiceLoss=1−DiceCoefficient
Dice 系数:
根据 Lee Raymond Dice命名,是一种集合相似度度量函数,通常用于计算两个样本的相似度(值范围为 [0, 1]),公式如下,分子有2是因为分母加了两次TP:
D i c e C o e f f i c i e n t = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DiceCoefficient = \frac{2|X \cap Y|}{|X|+|Y|} DiceCoefficient=∣X∣+∣Y∣2∣X∩Y∣
其中, ∣ X ∣ |X| ∣X∣和 ∣ Y ∣ |Y| ∣Y∣分别表示集合的元素个数,分割任务中,两者分别表示GT和预测。

所以 Dice Loss 公式如下:
D i c e L o s s = 1 − 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DiceLoss = 1-\frac{2|X \cap Y|}{|X|+|Y|} DiceLoss=1−∣X∣+∣Y∣2∣X∩Y∣
从IoU过度到Dice:

- 黄色区域:预测为negative,但是GT中是positive的False Negative区域;
- 红色区域:预测为positive,但是GT中是Negative的False positive区域;
IoU的算式:
I o U = T P T P + F P + F N IoU = \frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP
简单的说就是,重叠的越多,IoU越接近1,预测效果越好。
Dice 系数:
D i c e C o e f f i c i e n t = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DiceCoefficient = \frac{2|X \cap Y|}{|X|+|Y|} DiceCoefficient=∣X∣+∣Y∣2∣X∩Y∣
- ∣ X ∩ Y ∣ |X \cap Y| ∣X∩Y∣ → T P TP TP
- X X X 是 G T GT GT → T P + F N TP+FN TP+FN
- Y Y Y 是 P r e d Pred Pred→ T P + F P TP+FP TP+FP
所以:
D i c e C o e f f i c i e n t = 2 × T P T P + F N + T P + F P DiceCoefficient = \frac{2 \times TP}{TP+FN+TP+FP} DiceCoefficient=TP+FN+TP+FP2×TP
所以我们可以得到Dice和IoU之间的关系了,这里的之后的Dice默认表示Dice Coefficient:
I o U = D i c e 2 − D i c e IoU=\frac{Dice}{2-Dice} IoU=2−DiceDice
这个函数图像如下图,我们只关注0~1这个区间就好了,可以发现:

- IoU和Dice同时为0,同时为1;这很好理解,就是全预测正确和全部预测错误
- 假设在相同的预测情况下,可以发现Dice给出的评价会比IoU高一些,哈哈哈。所以Dice的数据会更加好看一些。
需要注意的是Dice Loss存在两个问题:
(1)训练误差曲线非常混乱,很难看出关于收敛的信息。尽管可以检查在验证集上的误差来避开此问题。
(2)Dice Loss比较适用于样本极度不均的情况,一般的情况下,使用 Dice Loss 会对反向传播造成不利的影响,容易使训练变得不稳定。
所以在一般情况下,还是使用交叉熵损失函数。
3.2 语义分割中的 IoU
I o U = T P T P + F P + F N IoU = \frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP
语义分割中,IoU是用mask来评价的:
GT:

Prediction:

Intersection:

Union:

mIoU:各个类别的IoU的均值
mIoU 的计算:
- 步骤一:先求混淆矩阵
- 步骤二:再求mIoU
混淆矩阵:
| 真实情况 | 预测结果 | 预测结果 |
|---|---|---|
| 真实情况 | 正例 | 反例 |
| 正例 | TP | FN |
| 反例 | FP | TN |
混淆矩阵的对角线上的值表示预测正确的值,IoU是只求正例的IoU,如何找出和正例有关的混淆矩阵元素呢,可以通过划线法来得到,

假设有N个类别,则混淆矩阵就是一个NxN的矩阵,对角表示TP,横看真实,竖看预测。
假设一个3类的预测输出的混淆矩阵如下所示:
| 真实 | 预测 | 预测 | 预测 |
|---|---|---|---|
| 真实 | 0 | 1 | 2 |
| 0 | 3 | 0 | 0 |
| 1 | 0 | 2 | 1 |
| 2 | 0 | 1 | 2 |
- 对角线上的元素表示预测类别正确的像素数目
- 每一行表示该类别真实的像素个数
- 每一列表示预测为该类别的像素个数
| 真实 | 预测 | 预测 | 预测 |
|---|---|---|---|
| 真实 | 0 | 1 | 2 |
| 0 | a | b | c |
| 1 | d | e | f |
| 2 | g | h | i |
精确率:
p r e c i s i o n 0 = a / ( a + d + g ) precision_0 = a/(a+d+g) precision0=a/(a+d+g)
p r e c i s i o n 1 = e / ( b + e + h ) precision_1 = e/(b+e+h) precision1=e/(b+e+h)
p r e c i s i o n 2 = i / ( c + f + i ) precision_2 = i/(c+f+i) precision2=i/(c+f+i)
p r e c i s i o n 0 = 3 / ( 3 + 0 + 0 ) = 1 precision_0 = 3/(3+0+0)=1 precision0=3/(3+0+0)=1
p r e c i s i o n 1 = 2 / ( 2 + 1 + 0 ) = 2 / 3 precision_1 = 2/(2+1+0)=2/3 precision1=2/(2+1+0)=2/3
p r e c i s i o n 2 = 2 / ( 2 + 1 + 0 ) = 2 / 3 precision_2 = 2/(2+1+0)=2/3 precision2=2/(2+1+0)=2/3
召回率:
r e c a l l 0 = a / ( a + b + c ) recall_0 = a/(a+b+c) recall0=a/(a+b+c)
r e c a l l 1 = e / ( d + e + f ) recall_1 = e/(d+e+f) recall1=e/(d+e+f)
r e c a l l 2 = i / ( g + h + i ) recall_2 = i/(g+h+i) recall2=i/(g+h+i)
r e c a l l 0 = 3 / ( 3 + 0 + 0 ) recall_0 = 3/(3+0+0) recall0=3/(3+0+0)
r e c a l l 1 = 2 / ( 2 + 1 + 0 ) = 2 / 3 recall_1 = 2/(2+1+0)=2/3 recall1=2/(2+1+0)=2/3
r e c a l l 2 = 2 / ( 2 + 1 + 0 ) = 2 / 3 recall_2 = 2/(2+1+0)=2/3 recall2=2/(2+1+0)=2/3
PA:Pixel Accuracy(像素精度)→标记正确的像素占总像素的比例
P A = 对角线元素之和 / 矩阵所有元素之和 PA = 对角线元素之和/矩阵所有元素之和 PA=对角线元素之和/矩阵所有元素之和
P A = 3 + 2 + 2 3 + 2 + 2 + 0 + 0 + 0 + 0 + 1 + 1 = 0.78 PA = \frac{3+2+2}{3+2+2+0+0+0+0+1+1}=0.78 PA=3+2+2+0+0+0+0+1+13+2+2=0.78
CPA:Class Pixel Accuracy(每类的像素精度)→按类别计算正确的像素占总像素的比例
P i = 对角线值 / 对应列的像素总数 P_i = 对角线值/对应列的像素总数 Pi=对角线值/对应列的像素总数
p 0 = 3 / ( 3 + 0 + 0 ) = 1 p_0 = 3/(3+0+0) = 1 p0=3/(3+0+0)=1
p 1 = 2 / ( 0 + 2 + 1 ) = 0.67 p_1 = 2/(0+2+1) = 0.67 p1=2/(0+2+1)=0.67
p 2 = 2 / ( 0 + 1 + 2 ) = 0.67 p_2 = 2/(0+1+2) = 0.67 p2=2/(0+1+2)=0.67
MPA:Mean Pixel Accuracy→每类正确分类像素比例的平均
M P A = s u m ( p i ) / 类别数 = ( 1 + 0.67 + 0.67 ) / 3 = 0.78 MPA = sum(p_i)/类别数 = (1+0.67+0.67)/3=0.78 MPA=sum(pi)/类别数=(1+0.67+0.67)/3=0.78
IoU:
-
划线法:
I o U 0 = 3 / ( 3 + 0 + 0 + 0 + 0 ) = 1 IoU_0 = 3/(3+0+0+0+0) = 1 IoU0=3/(3+0+0+0+0)=1
I o U 1 = 2 / ( 0 + 2 + 1 + 1 + 1 ) = 0.5 IoU_1 = 2/(0+2+1+1+1) = 0.5 IoU1=2/(0+2+1+1+1)=0.5
I o U 2 = 2 / ( 0 + 1 + 2 + 2 + 1 ) = 0.5 IoU_2 = 2/(0+1+2+2+1) = 0.5 IoU2=2/(0+1+2+2+1)=0.5 -
代码方法: S A ∪ B = S A + S B − S A ∩ B S_{A\cup B} = S_A+S_B-S_{A\cap B} SA∪B=SA+SB−SA∩B
I o U 0 = 3 / [ ( 3 + 0 + 0 ) + ( 3 + 0 + 0 ) − 3 ] = 1 IoU_0 = 3/[(3+0+0)+(3+0+0) - 3] = 1 IoU0=3/[(3+0+0)+(3+0+0)−3]=1
I o U 1 = 2 / [ ( 0 + 2 + 1 ) + ( 1 + 2 + 1 ) − 2 ] = 0.5 IoU_1 = 2/[(0+2+1)+(1+2+1) - 2]= 0.5 IoU1=2/[(0+2+1)+(1+2+1)−2]=0.5
I o U 2 = 2 / [ ( 0 + 1 + 2 ) + ( 0 + 2 + 1 ) − 2 ] = 0.5 IoU_2 = 2/[(0+1+2)+(0+2+1) - 2] = 0.5 IoU2=2/[(0+1+2)+(0+2+1)−2]=0.5
mIoU:
m I o U = s u m ( I o U i ) / c l a s s mIoU = sum(IoU_i)/class mIoU=sum(IoUi)/class
代码:
# gt 为 label,predict 为预测的结果,num_category 是分割的类别
# 输出为混淆矩阵
def gen_confusion_matrix(predict, gt, num_category):
mask = (gt >= 0) & (gt < num_category)
label = num_category * gt[mask] + predict[mask]
count = np.bincount(label, minlength=num_category**2)
confusion_matrix = count.reshape(num_category, num_category)
return confusion_matrix
# 依据混淆矩阵计算 IoU,这里 IoU 是一个列表,每个值表示对应的类别的 IoU
def cal_iou(confusion_matrix):
intersection = np.diag(confusion_matrix)
union = np.sum(confusion_matrix, axis=1) + np.sum(confusion_matrix, axis=0) - np.diag(confusion_matrix)
union = [np.nan if x == 0 else x for x in union]
IoU = intersection / union
return IoU
# 求 mIoU
for seg_result, label in zip(seg_results, labels):
confusion_matrix += gen_confusion_matrix(seg_result, label, num_category)
IoU = cal_iou(confusion_matrix)
IoU_per_category = dict(zip(classes_names, IoU))
mIoU = np.nanmean(IoU)
metric_output = {
"mIoU": mIoU,
"IoU": IoU_per_category,
}
print("metric_output:", metric_output)
import numpy as np
class IOUMetric:
"""
Class to calculate mean-iou using fast_hist method
"""
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
# 找出标签中需要计算的类别,去掉了背景
mask = (label_true >= 0) & (label_true < self.num_classes)
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
# 输入:预测值和真实值
# 语义分割的任务是为每个像素点分配一个label
def evaluate(self, predictions, gts):
for lp, lt in zip(predictions, gts):
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
#miou
iou = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
miou = np.nanmean(iu)
#其他性能指标
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.nanmean(np.diag(self.hist) / self.hist.sum(axis=1))
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, iou, miou, fwavacc