【目标检测】50、YOLOX | 回归 anchor-free 的 YOLO 依然能打!

文章目录
-
- 一、背景
- 二、方法
- 三、效果
论文:YOLOX: Exceeding YOLO Series in 2021
代码:https://github.com/Megvii-BaseDetection/YOLOX
作者:旷世
时间:2021.08
贡献:
- 将 YOLO 检测器建模成了 anchor-free 的形式
- 将一些优秀的检测方法嵌入,如 decoupled head 和 SimOTA
- YOLO-nano:在 COCO 上 25.3% AP,比 Nanodet 高了 1.8%
- YOLOv3:提升了 3% AP,达到了 47.3%
一、背景
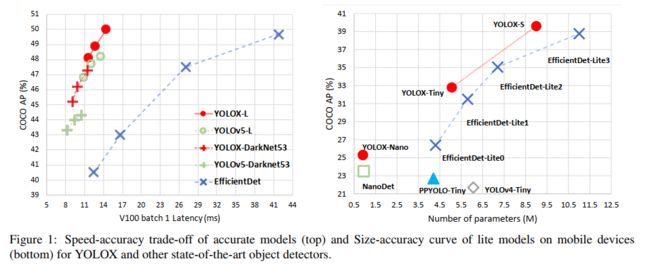
随着 YOLO 系列的发展,很大程度上推进了检测器在准确率和效率上的平衡,当时最优的应该是 YOLOv5,在 COCO 上 48.2% AP,耗时 13.7ms。
在近两年,目标检测的方法研究集中在 anchor-free(FCOS, CornerNet, CenterNet),advanced label assignment(Freeanchor, ATSS, Autoassign, Iqdet, Ota),end-to-end(NMS-free)( End-to-end object detection with transformers, End-to-end object detection with fully convolutional network, Object detection made simpler by eliminating heuristic nms)等方面,YOLO 系列还没有引入这些,YOLOv4 和 YOLOv5 都是 anchor-based,并且训练过程有手工选择的特征。
二、方法
1、baseline:
YOLOX 是以 YOLOv3 作为基准框架的,以 Darknet53 作为backbone,YOLOv3+Darknet53+SPP 作为 baseline,如图 1 所示。
- 分类和 objectness loss:BCE loss
- 回归 loss:IoU loss
2、解耦头
检测任务中的分类和回归头的互相影响会给网络结果带来不好的硬,所以需要对两个头进行解耦。
- 将 YOLO 的 head 使用解耦后的头替换后,收敛速度明显快了很多,如图 3
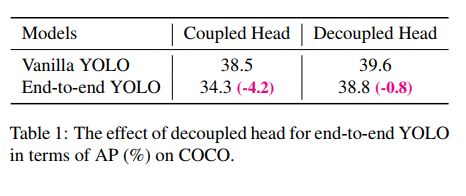
- 解耦头对 YOLO 的 end-to-end 的训练有好处。从表 1 中可以看出,使用耦合头时,end-to-end 的训练会下降 4.2% AP,使用解耦头的时候只会下降 0.8% AP
- 所以,使用了如图 2 所示的解耦头:1 个 1x1 conv 层来降通道,两个并行的 3x3 conv 分别进行不同的特征提取。经过实验后,也发现解耦层多了 1.1 ms 的耗时(11.6ms vs. 10.5ms)。


3、数据增强
使用了 Mosaic 和 Mixup 增强
如何使用数据增强:在最后 15 个 epoch 的时候,关掉这两个增强
4、Anchor-free
YOLOv4 和 YOLOv5 都是基于 YOLOv3 的结构的,都是 anchor-based 模式。
使用 anchor 有两个问题:
- 为了达到最优检测结果,需要在训练之前统计分析并确定最优 anchor,这些方法都是有阈限定的,很难泛化
- Anchor 方法提升了检测头的复杂性,在边缘设备上移除这些高复杂度的计算,可能会解决其瓶颈
如何将 YOLO 转换为 anchor-free 的:
- 将每个位置的预测从 3 改为 1,直接预测 4 个值:相对网格的左上角点的两个偏移 + 预测框的宽和高
- 将每个目标中心点位置当做正样本
- 预定义尺度范围,来定义 FPN 的每层学习多大的目标
- 上述操作降低了 GFLOPs 并且速度更快了,且获得了更好的效果 42.9%,如表 2

5、多个正样本
为了和 YOLOv3 的分配策略一致,如果只给每个目标选择一个正样本(中心点处),忽略其他的高质量预测结果,而这些高质量的预测结果也会给梯度带来益处,缓解正负样本的严重不平衡问题,所以,YOLOX 选择中心的 3x3 位置的样本为正样本,提升到了 45%。
6、SimOTA
作者总结的 advanced label assignment 的 4 个关键点:
- loss/quality aware
- Center prior
- Dynamic number of positive anchor for each gt
- Global view
OTA (Ota: Optimal transport assignment for object detection, CVPR2021)满足上述四点,所以选择了该策略。
OTA 从全局的角度分析了 label assignment,并且将标签分配的过程建模成了一个 Optimal Transport (OT)问题。但作者发现直接使用基于 Sinkhorn-Knopp 的 OT 的话,会额外带来 25% 的训练时间,所以简化成了动态的 top-k 策略,称为 SimOTA。
SimOTA 通过如下方式计算真值和预测值的 cost: c i j = L i j c l s + λ L i j r e g c_{ij} = L_{ij}^{cls} + \lambda L_{ij}^{reg} cij=Lijcls+λLijreg
然后,对每个 gt,都根据一个确定的 center region 来最小化 cost,并选择前 top-k的预测结果作为其正样本。
SimOTA 减少了训练时间,避免了 Sinkhorn-Knopp 的超参数,从 47.3 提升到了 45。
7、End-to-end YOLO
添加了 2 个 conv layer,one-to-one label assignment,stop gradient
三、效果
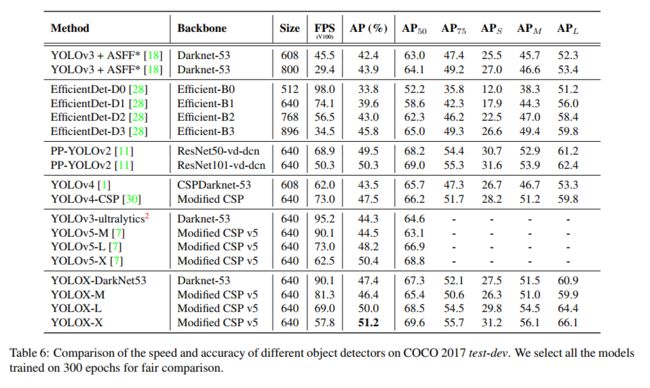
1、和其他 backbone 的对比

2、和 SOTA 的对比