Python快速刷题网站——牛客网 数据分析篇(十七)
一个帅气的boy,你可以叫我Love And Program
⌨个人主页:Love And Program的个人主页
如果对你有帮助的话希望三连支持一下博主
前言
本文将继续学习pandas 中级函数 最后一块内容,并对数据清洗模块部分内容展开讲解。
计算用户的名字长度
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
运营小周同学想要统计这些用户的名字长度,你可以帮助她吗?
输入描述: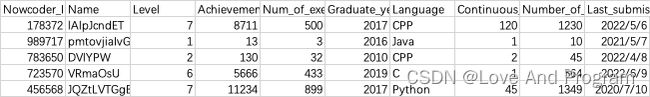
输出描述:
输出每一行用户名字的长度,包括行号。
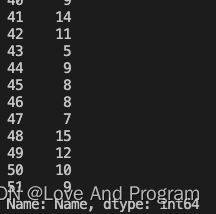
- 读题找出重点:统计用户的名字长度
- 使用pandas中
pandas.Series.str方法
首先我们要了解pandas.Series.str方法->序列和索引的矢量化字符串函数,简单来说就是经过str处理后可以使用Python常用的处理方案,根据题意我们使用计算长度的函数len():
(注意:经过str后被封装成不可见的类,需要用函数调用才能生成具体结果)
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":['sdfsd','asdf','a','xfdssdf','gfgd'],
"Level":[7,1,2,6,7],
"Achievement_value":[8711,13,130,5666,11234],
"Num_of_exercise":[500,3,32,433,899],
"Graduate_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java',np.nan,'C','Python'],
"Continuous_check_in_days":[1230,10,45,564,1349],
"Number_of_submissions":[120,1,2,1,np.nan]
})
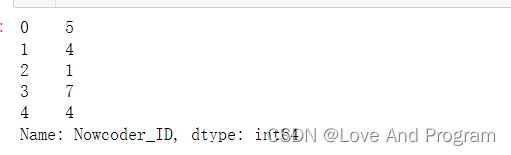
data['Nowcoder_ID'].str
#
data['Nowcoder_ID'].str.len()
当然还有其他的函数可以调用,比如split(),lstrip()等可自行尝试。
最终代码整理如下:
DA23 统计牛客网用户的名字长度
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder['Name'].str.len())
去掉信息不全的用户
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
运营同学正在做用户调研,为了保证调研的可靠性,想要去掉那些信息不全的用户,即去掉有缺失数据的行,请你帮助他去掉后输出全部数据。
输入描述:

输出描述:
直接输出清洗后的全部数据。

- 读题找出重点:去掉有缺失数据的行、输出全部数据
- 使用pandas中
dropna()函数
dropna():丢弃含空值的行、列
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":[178372,989717,783650,723570,456568],
"Level":[7,1,2,6,7],
"Achievement_value":[8711,13,130,5666,11234],
"Num_of_exercise":[500,3,32,433,899],
"Graduate_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java',np.nan,'C','Python'],
"Continuous_check_in_days":[1230,10,45,564,1349],
"Number_of_submissions":[120,1,2,1,np.nan]
})
data.dropna()

最终代码整理如下:
DA24 去掉信息不全的用户
import sys
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder.dropna())