多后端深度学习开发框架TensorlayerX发布
Tensorlayer团队的最新作品,跨平台开源框架TensorLayerX来了!
国内启智平台:TensorLayerX
或GitHub开源地址:GitHub - tensorlayer/TensorLayerX: TensorLayerX: A Unified Deep Learning and Reinforcement Learning Framework for All Hardwares, Backends and OS.
文档地址:Welcome to TensorLayerX
这个项目由北京大学、鹏城实验室、爱丁堡大学、帝国理工、清华、普林斯顿、斯坦福等机构的研究人员维护。
TensorLayerX是新一代的多后端深度学习框架,兼容TensorFlow、Pytorch、PaddlePaddle、MindSpore等国内外主流深度学习计算引擎作为计算后端,用户可以在各类操作系统和AI硬件上(如英伟达GPU 和 国产华为Ascend)使用相同的代码进行开发。
TensorLayerX是为了顺应深度学习跨平台开发的趋势而诞生的。如果你有以下需求,请选择TensorLayerX:
- 使用统一的代码在多中框架环境开发深度学习应用
- 使用国产AI框架和芯片,希望降低学习成本
- 参与中国人为主的一线开发者社区
跨平台开发趋势
深度学习发展到2022年,呈现出计算框架、计算硬件、操作系统、应用种类的多样化趋势。在百花齐放、欣欣向荣的背后也存在着弊端:由于计算引擎众多、它们的接口差异化明显,而且不同厂家的计算引擎往往与特点的芯片绑定,造成开源生态的割裂。因此,跨平台、跨硬件的开发需求愈发强烈。

现在深度学习研究的主流框架包括TensorFlow、Pytorch和国内的PaddlePaddle、MindSpore等。
近年来,国内AI计算框架和芯片得到了很大的发展,这对我国人工智能进步起到了基础性的作用。包括百度的PaddlePaddle和华为的MindSpore在内的优秀国产计算框架都在蓬勃发展,百度昆仑、华为Ascend等优秀国产芯片国产AI芯片获得了更多的使用。
国外的TensorFlow和Pytorch框架的用户最多、生态最完善,大多数公布的新论文算法都是用这两个框架实现的。然而,这两个框架所代表的深度学习生态完全由欧美主导,优先支持的是英伟达GPU和谷歌TPU等计算设备,几乎不支持国内的计算设备和操作系统。
各位开发者可能都遇到过这样的困惑:为了运行几个开源算法,需要安装多个框架多个版本的环境、cuda等依赖库版本冲突,需要使用国产框架的时候学习成本高、生态资源少。总之,在开发深度学习应用的过程中,需要耗费很大的精力处理不同框架间的差异,而且国产计算硬件和框架的发展受到了很大的阻碍。
如今,行业内人工智能开发工具很多,很多开发者开始发现,这些工具的使用方法越来越像。工具随着行业的发展形成统一的规范,开发者们将更容易得到便利。
开发者们对一个跨平台、跨硬件、兼容多后端的开发工具的需求愈发强烈。
回顾:Tensorlayer和Keras高级API
2016 年,北京大学董豪教授在帝国理工读博期间,在 Github 上开源 TensorLayer1.0,Github上总Star项目超过1万次,TensorLayer开发框架下载量超过40万次,开源应用涉及计算机视觉和强化学习。
TensorLayer 是一款基于 TensorFlow 开发的深度学习与强化学习库。当时的TensorFlow的定位是“基于图的科学计算库”缺少用于深度学习的网络组件和高级API,TensorLayer提供了高级别的深度学习 API,非常易于修改和扩展,可以同时用于机器学习的研究与产品开发。

2015年,Keras——由Python编写的开源人工神经网络库发布了,它提供了一套深度学习模型的设计、调试、评估、应用的高级API,可以使用Tensorflow、Microsoft-CNTK和Theano作为计算后端。一直以来,Keras因为其便捷直观的接口和跨平台跨后端的特性,受到了广大开发者的欢迎。

但是在Google正式接管Keras以后,Keras基本上变成了TensorFlow的高级API模块,不再继续支持更多框架作为计算后端,导致市场上失去了跨平台跨框架开发的工具。
TensorLayer 最初的版本和 Keras 很相似,但 Keras 当时兼容多框架,而 TensorLayer 当初只支持 TensorFlow 一个框架。随着近几年国内的开发框架和 AI 芯片厂商的发展,不论从软件层还从芯片层的生态圈,都出现了割裂分散的形势。
基于这个背景,TensorLayer 团队希望打造一套通用的与平台无关的一种开发框架, 发布了的TensorLayer 升级版本 TensorLayer X。
TensorLayerX 是一个兼容众多计算引擎的开发框架,目前兼容的引擎包括TensorFlow、Pytorch、PaddlePaddle、MindSpore等,基本具备了兼容国内外主流深度学习开发平台的跨平台开发能力,接下来就请随我详细了解一下TensorLayerX吧!
快速入门
千言万语的介绍,不如动手用几行代码体验TensorLayerX的便利性!
安装
TensorLayerX的安装非常简单,只需要一行pip命令,除了自动安装普通依赖库外,程序还会帮你检查并安装支持的后端框架!
pip3 install tensorlayerx#==0.5.2比如程序检测到你的环境中已经安装了TensorFlow、Pytorch、PaddlePaddle、MindSpore框架之一,就不会额外下载后端框架。反之,如果你的环境没有安装任何后端框架,则会自动帮你下载后端框架库!
指定后端
TensorlayerX目前支持包括TensorFlow、Pytorch、PaddlePaddle、MindSpore作为计算后端,指定计算后端的方法也非常简单,只需要设置环境变量即可
import os
os.environ['TL_BACKEND'] = 'tensorflow'
# os.environ['TL_BACKEND'] = 'mindspore'
# os.environ['TL_BACKEND'] = 'paddle'除了在代码中使用os模块定义外,你也可以在运行程序前使用命令来指定
#Linux
export TL_BACKEND= 'tensorflow'
#Windows
set TL_BACKEND= 'tensorflow'搭建模型
TensorLayerX在设计模型的搭建方式时,为了照顾开发者的习惯,尽可能的和主流的深度学习框架保持一致。
同时,作为特色,TensorLayerX提供了自动推断输入张量形状的功能,开发者不必再手动计算并指定in_channels和in_features参数了!
对于结构简单的、序列式的模型,你可以使用Sequential方式搭建,短短的几行代码即可完成一个模型的搭建
from tensorlayerx.nn import Sequential #序列式模型
from tensorlayerx.nn import Linear #全连接层
layer_list = [] #空的层列表
#依次添加各层
layer_list.append(Linear(out_features=800, act=tlx.ReLU, in_features=784, name='linear1'))
layer_list.append(Linear(out_features=800, act=tlx.ReLU, in_features=800, name='linear2'))
layer_list.append(Linear(out_features=10, act=tlx.ReLU, in_features=800, name='linear3'))
MLP = Sequential(layer_list)对于结构复杂的,需要自定义计算顺序的模型,你可以继承nn.Module类型来编写
from tensorlayerx.nn import Module
import tensorlayerx as tlx
from tensorlayerx.nn import (Conv2d, Linear, Flatten, MaxPool2d, BatchNorm2d)
class CNN(Module):
def __init__(self):
super(CNN, self).__init__()
# weights init
W_init = tlx.nn.initializers.truncated_normal(stddev=5e-2)
W_init2 = tlx.nn.initializers.truncated_normal(stddev=0.04)
b_init2 = tlx.nn.initializers.constant(value=0.1)
self.conv1 = Conv2d(64, (5, 5), (1, 1), padding='SAME', W_init=W_init, b_init=None, name='conv1', in_channels=3)
self.bn = BatchNorm2d(num_features=64, act=tlx.ReLU)
self.maxpool1 = MaxPool2d((3, 3), (2, 2), padding='SAME', name='pool1')
self.conv2 = Conv2d(
64, (5, 5), (1, 1), padding='SAME', act=tlx.ReLU, W_init=W_init, b_init=None, name='conv2', in_channels=64
)
self.maxpool2 = MaxPool2d((3, 3), (2, 2), padding='SAME', name='pool2')
self.flatten = Flatten(name='flatten')
self.linear1 = Linear(384, act=tlx.ReLU, W_init=W_init2, b_init=b_init2, name='linear1relu', in_features=2304)
self.linear2 = Linear(192, act=tlx.ReLU, W_init=W_init2, b_init=b_init2, name='linear2relu', in_features=384)
self.linear3 = Linear(10, act=None, W_init=W_init2, name='output', in_features=192)
def forward(self, x):
z = self.conv1(x)
z = self.bn(z)
z = self.maxpool1(z)
z = self.conv2(z)
z = self.maxpool2(z)
z = self.flatten(z)
z = self.linear1(z)
z = self.linear2(z)
z = self.linear3(z)
return z数据加载
TensorLayerX提供了高效、简洁的数据加载及处理接口,你可以使用Dataset和DataLoader轻松地加载训练所用的数据
import tensorlayerx as tlx
from tensorlayerx.dataflow import Dataset, DataLoader
from tensorlayerx.vision.transforms import (
Compose, Resize, RandomFlipHorizontal, RandomContrast, RandomBrightness, StandardizePerImage, RandomCrop
)
X_train, y_train, X_test, y_test = tlx.files.load_cifar10_dataset(shape=(-1, 32, 32, 3), plotable=False)
class cifar10_dataset(Dataset):
def __init__(self, data, label, transforms):
self.data = data
self.label = label
self.transforms = transforms
def __getitem__(self, idx):
x = self.data[idx].astype('uint8')
y = self.label[idx].astype('int64')
x = self.transforms(x)
return x, y
def __len__(self):
return len(self.label)
train_transforms = Compose(
[
RandomCrop(size=[24, 24]),
RandomFlipHorizontal(),
RandomBrightness(brightness_factor=(0.5, 1.5)),
RandomContrast(contrast_factor=(0.5, 1.5)),
StandardizePerImage()
]
)
test_transforms = Compose([Resize(size=(24, 24)), StandardizePerImage()])
train_dataset = cifar10_dataset(data=X_train, label=y_train, transforms=train_transforms)
test_dataset = cifar10_dataset(data=X_test, label=y_test, transforms=test_transforms)
train_dataset = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = DataLoader(test_dataset, batch_size=batch_size)模型训练
TensorLayerX提供了两种训练方式,一种是高级封装的训练API,一种是用户自定义的按Step训练。
如果你希望尽快开始模型的训练,我们建议你使用高级封装的训练API,只需要几行代码就可以开始模型训练。
# 搭建网络
net = CNN()
# 设置训练参数
batch_size = 128
n_epoch = 500
learning_rate = 0.0001
print_freq = 5
n_step_epoch = int(len(y_train) / batch_size)
n_step = n_epoch * n_step_epoch
shuffle_buffer_size = 128
# 定义损失函数、优化器等
optimizer = tlx.optimizers.Adam(learning_rate)
metrics = tlx.metrics.Accuracy()
loss_fn = tlx.losses.softmax_cross_entropy_with_logits
#使用高级API构建可训练模型
net_with_train = tlx.model.Model(
network=net, loss_fn=loss_fn, optimizer=optimizer, metrics=metrics
)
#执行训练
net_with_train.train(n_epoch=n_epoch, train_dataset=train_loader, print_freq=print_freq, print_train_batch=False)
如果你希望细粒度的控制训练工程,那么可以使用TrainOneStep的方式
class WithLoss(Module):
def __init__(self, net, loss_fn):
super(WithLoss, self).__init__()
self._net = net
self._loss_fn = loss_fn
def forward(self, data, label):
out = self._net(data)
loss = self._loss_fn(out, label)
return loss
net_with_loss = WithLoss(net, loss_fn=tlx.losses.softmax_cross_entropy_with_logits)
net_with_train = TrainOneStep(net_with_loss, optimizer, train_weights)
for epoch in range(n_epoch):
start_time = time.time()
net.set_train()
train_loss, train_acc, n_iter = 0, 0, 0
for X_batch, y_batch in train_dataset:
_loss_ce = net_with_train(X_batch, y_batch)
train_loss += _loss_ce
n_iter += 1
_logits = net(X_batch)
metrics.update(_logits, y_batch)
train_acc += metrics.result()
metrics.reset()
print("Epoch {} of {} took {}".format(epoch + 1, n_epoch, time.time() - start_time))
print(" train loss: {}".format(train_loss / n_iter))
print(" train acc: {}".format(train_acc / n_iter))TensorLayerx介绍
TensorLayerX特色
TensorLayerX是一套跨平台的深度学习开发工具,它使用纯Python代码开发。通过对多后端的Python接口进行封装,TensorLayerX提供了一套兼容多个框架的深度学习开发统一API,再由各后端框架的底层程序负责调用硬件计算,使得开发者可以无视后端框架和硬件平台地进行深度学习开发。在这个过程中,几乎没有计算性能的损耗。

TensorLayerX的开发范式是面向对象的,所有的层和模型的定义都通过继承并改写nn.Module类型。
TensorLayerX的底层,是对于各个后端框架的基础张量操作进行的包装tlx.ops,在此基础上通过改写 nn.Module类型,TensorLayerX封装了许多常用的神经网络层、模块,开发者可以轻松地编写自己的算法。
同时,TensorLayerX在设计时考虑了简洁的训练过程和定制化的训练过程。用户既可以使用封装的model.train()方法一键开始模型训练,也可以使用循环的方式精确控制每个Step的训练过程。
TensorLayerx生态
TensorLayerX不只是一个框架,而是一系列开源产品、开源社区、开源活动组成的深度学习开源平台,从多方面构成了TensorLayerX的开源生态。我们为构建并完善这个国产深度学习生态的工作,命名为“腾龙开源计划”
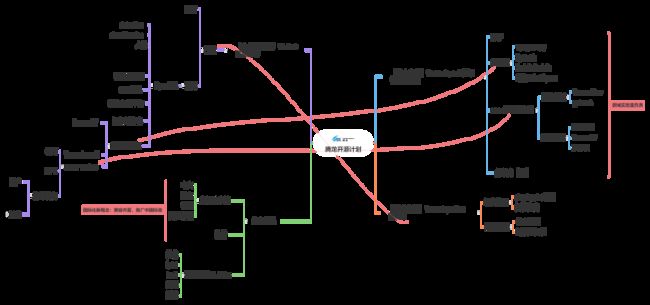
TLXZOO算法库
TLXZoo算法库,是基于TensorLayerX开发的常用算法库,方便开发者复用。其中的算法涵盖计算机视觉、自然语言处理等领域各类常用神经网络算法。同时,会及时复现学术界最新的算法。
目前支持的算法包括:
- NLP:
- 文本分类:T5、BERT
- 实体标注:T5、BERT
- 文本翻译:T5
- 文本推理(NLI):T5
- 语音:
- 语音识别:wav2vec
- CV:
- 图像分类:ResNet、VGG
- 目标检测:Detr、YOLO
- 语义分割:Unet
- OCR识别:trocr
- 人脸识别:retinaface+Arcface
- 人体姿态估计 HRNet
当前的深度学习算法生态,是一个经典学术算法—最新学术算法—工业落地的生态闭环
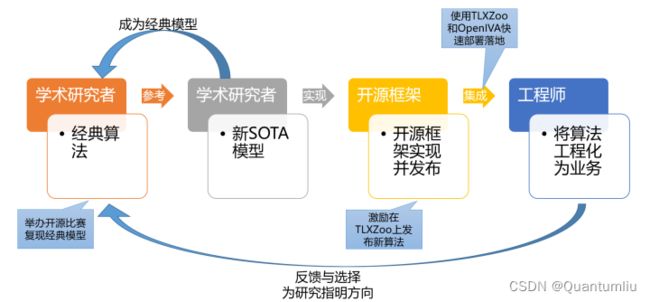
我们希望TLXZOO算法,可以为整个生态带来帮助
- 对于学术研究者,可以方便的找到相关领域的最新模型,进行学习和对比;
- 对于工业界开发者,可以灵活的使用模型库内的预训练模型作为核心模块,进行部署或进一步训练。
- 鼓励学术研究者使用TensorLayerX框架开源自己的新算法代码,惠及整个生态的研究者、开发者
RLZOO强化学习工具箱

RLzoo 是最实用的强化学习算法、框架和应用程序的集合。它使用 Tensorflow 2.0 和TensorLayerX中的神经网络层 API 实现,为强化学习实践和基准测试提供动手快速开发的方法。它支持基本的toy测试,如OpenAI Gym和DeepMind Control Suite,配置非常简单。此外,RLzoo 支持基于Vrep/Pyrep模拟器的机器人学习基准环境RLBench 。
同时,你也可以结合我们的配套教材深度强化学习:基础、研究与应用 进行理论+实践的学习。

开发者社区
一个活跃的开发者社区对开源软件的发展至关重要。
TensorLayerX将持续的建设中国人为主的深度学习开发者社区,包括线上交流群组、举办比赛、线下沙龙(视疫情情况),以及和高校师生的合作等。
目前国内开源社区面临参与贡献国外框架难、大企业非开放式开源、普遍只借鉴不贡献等问题,我们希望在开发TensorLayerX这一国产开源项目的过程中,能够与更多的开源贡献者一起成长,成为中国开源界的一支生力军。
前景展望
TensorLayerX目前处于刚刚发布的阶段,还有很多的功能正在改进完善,更多的模块和生态产品也在开发当中。
即将开发完成的包括:
- 多种硬件的分布式训练
- TLX2ONNX,实现了TensorLayerX模型转换为onnx模型,最大程度上和主流深度学习生态接轨。
- OpenIVA,一个端到端的基于多推理后端的智能视觉分析开发套件,旨在帮助个人用户和初创企业快速部署启动自己的视觉AI服务。支持TensorLayerX/TensorRT/onnxruntime等多推理后端。
加入我们
TensorLayerX刚刚发布,羽翼未丰,迫切的需要广大开发者提供宝贵的意见,也欢迎各位开源贡献者参与,一起打造中国人主导的深度学习生态社区!
您可以加入我们的微信群进行日常的问题解答/交流: liuyiliang100(个人v,加好友拉群)

可以通过Star 启智社区仓库、GitHub仓库来跟踪最新进展,参与开源软件开发。
如果您有关于开源软件、学术合作方面的意向,请联系董豪老师邮箱[email protected]