CS224W摘要03.Node Embedding
文章目录
- Encoder 和Decoder框架
-
- Encoder小例子
- Note
- 随机游走
-
- notation
- 特点
- 算法描述
- 负采样优化
- SGD
- 小结
- Node2Vec
-
- 小结
- Embedding entire graphs
-
- 新法 Learn Walk Embedding
CS224W: Machine Learning with Graphs
公式输入请参考: 在线Latex公式
上一节讲的是传统的图机器学习如何进行特征工程的(node-level, edge-level, graph-level features)
而这节课的目标是自动学习节点表征。
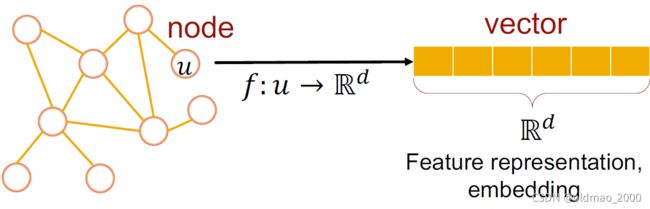
Encoder 和Decoder框架
基本的notation很简单:
V是节点集合,A是邻接矩阵,这里不为节点进行特征工程,或者添加额外信息。
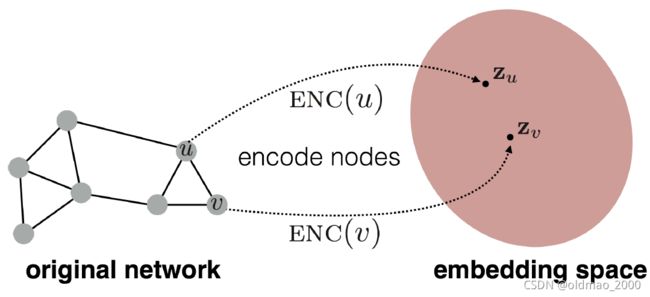
Goal is to encode nodes so that similarity in the embedding space (e.g., dot product) approximates similarity in the graph.
上图显示了Encoder,Decoder就是相似度计算部分:
D E C ( z v T z u ) DEC(z_v^Tz_u) DEC(zvTzu)
Encoder小例子
这里使用最简单的线性变换作为encoding方法为例子:
E N C ( v ) = z v = Z ⋅ v ENC(v)=z_v=Z\cdot v ENC(v)=zv=Z⋅v
Z就是参数矩阵维度是 d × ∣ V ∣ d\times |V| d×∣V∣;
v v v是节点的独热编码。
当然还有别的方法:DeepWalk, node2vec
Note
This is unsupervised/self-supervised way of learning node embeddings.
These embeddings are task independent. They are not trained for a specific task but can be
used for any task.
随机游走
notation
目标是要找到节点 u u u对应的表征 z u z_u zu
P ( v ∣ z u ) P(v|z_u) P(v∣zu)从节点 u u u游走到节点 v v v的概率
z u T z v z_u^Tz_v zuTzv表示u和v同时出现在随机游走序列的概率
特点
1.即可获得邻居的local信息,也可以获取多跳邻居信息
Idea: if random walk starting from node visits with high probability, and are similar (high-order multi-hop information)
2.无需考虑节点对的采样,只用考虑随机游走策略 R R R,更加高效
Efficiency: Do not need to consider all node pairs when training; only need to consider pairs that co-occur on random walks.
算法描述
给定图 G = ( V , E ) G=(V,E) G=(V,E)
目标是学习到一种映射 f : u → R d f:u\rightarrow\R^d f:u→Rd,记为 f ( u ) = z u f(u)=z_u f(u)=zu
目标最大化对数似然函数为:
max f ∑ u ∈ V log P ( N R ( u ) ∣ z u ) \underset{f}{\max}\sum_{u\in V}\log P(N_R(u)|z_u) fmaxu∈V∑logP(NR(u)∣zu)
N R ( u ) N_R(u) NR(u)表示用随机游走策略 R R R对节点u进行遍历得到的邻居节点
我们希望学习到节点u的特征表达,特征表达可以预测其随机游走的邻居
上面的最大化对数似然函数可以写成:
L = ∑ u ∈ V ∑ v ∈ N R ( u ) − log ( P ( v ∣ z u ) ) \mathcal{L}=\sum_{u\in V}\sum_{v\in N_R(u)}-\log(P(v|z_u)) L=u∈V∑v∈NR(u)∑−log(P(v∣zu))
上面加了负号求最小,其中 P ( v ∣ z u ) P(v|z_u) P(v∣zu)可以用softmax来求:
P ( v ∣ z u ) = exp ( z u T z v ) ∑ n ∈ V exp ( z u T z n ) P(v|z_u)=\cfrac{\exp(z_u^Tz_v)}{\sum_{n\in V}\exp(z_u^Tz_n)} P(v∣zu)=∑n∈Vexp(zuTzn)exp(zuTzv)
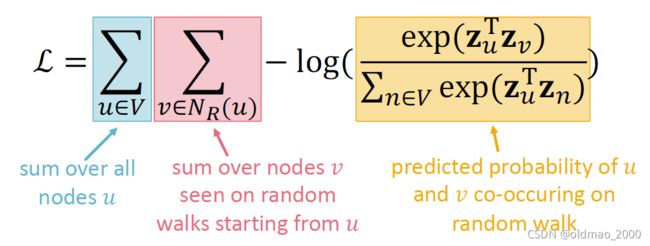
Optimizing random walk embeddings = Finding embeddings z u z_u zu that minimize L \mathcal{L} L
直接算计算量很大, ∑ u ∈ V , ∑ n ∈ V \sum_{u\in V},\sum_{n\in V} ∑u∈V,∑n∈V两部分都是对所有节点进行操作,使得复杂度高达 O ( ∣ V ∣ 2 ) O(|V|^2) O(∣V∣2)
负采样优化
这里主要针对黄色部分的进行优化,使得对所有节点的操作变成对某几个节点操作(k个采样的负样本):
log exp ( z u T z v ) ∑ n ∈ V exp ( z u T z n ) ≈ log ( σ ( z u T z v ) ) − ∑ i = 1 k log ( σ ( z u T z n i ) ) , n i ∼ P V \log\cfrac{\exp(z_u^Tz_v)}{\sum_{n\in V}\exp(z_u^Tz_n)}\approx\log\left(\sigma(z_u^Tz_v) \right)-\sum_{i=1}^k\log\left(\sigma(z_u^Tz_{ni}) \right),n_i\sim P_V log∑n∈Vexp(zuTzn)exp(zuTzv)≈log(σ(zuTzv))−i=1∑klog(σ(zuTzni)),ni∼PV
负样本的采样不是随机的,而是根据节点的度作为采样概率的依据进行采样。度越大,被采样的概率越大。通常采样的负样本个数为: k = 5 ∼ 20 k=5\sim20 k=5∼20
SGD
不解释,太多教程了
小结
1.Run short fixed-length random walks starting from each node on the graph
2. For each node collect R ( ) _R() NR(u), the multiset of nodes visited on random walks starting from
3. Optimize embeddings using Stochastic Gradient Descent:
Node2Vec
对随机游走策略进行优化,定义了二阶有偏随机游走的方式来生成 R ( ) _R() NR(u)
就是使用广度优先或胜读优先来进行随机游走,以获得不同的邻居信息。
BFS: Micro-view of neighbourhood
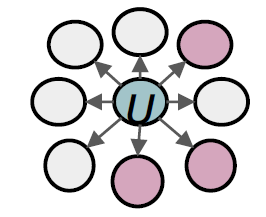
DFS: Macro-view of neighbourhood
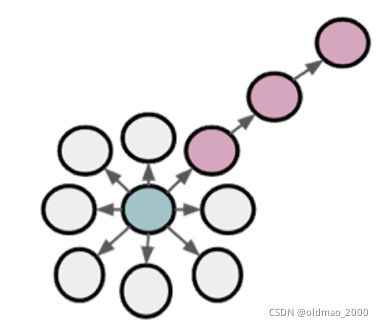
算法用到两个参数:
Return parameter : 用来控制是否Return back to the previous node
In-out parameter : 用来控制采用BFS vs. DFS来移动
具体看论文带读https://blog.csdn.net/oldmao_2001/article/details/108307211
从 s 1 s_1 s1出发后,当前游走到了 w w w
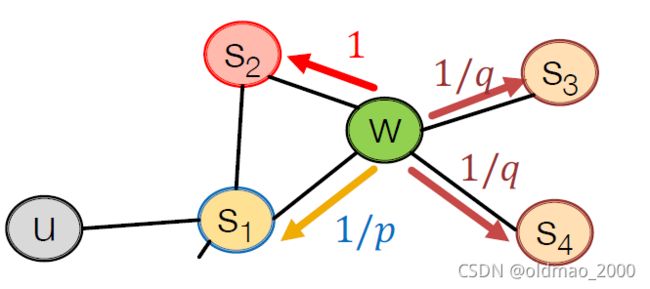
接下来该怎么走?
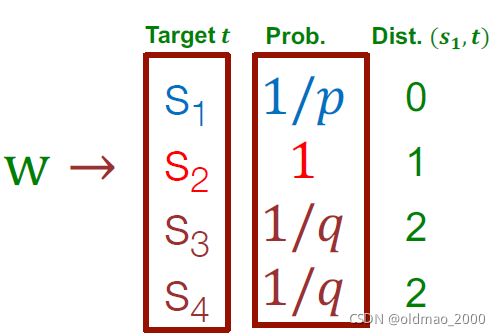
这里注意转移概率是非归一化的。
小结
Different notions of node similarity(Decoder做的事情):
Naïve: similar if 2 nodes are connected
Neighborhood overlap (上节)
Random walk approaches (本节)
Embedding entire graphs
目标是找到子图或者整个图的表征: Z G Z_G ZG
常见任务:
- 对有毒或无毒分子结构进行分类
- 检测异常图结构
法1:用所有节点的表征来计算整个图的表征:
Z G = ∑ v ∈ G Z v Z_G=\sum_{v\in G}Z_v ZG=v∈G∑Zv
法2:使用虚拟的全局节点,然后用哪个该节点的表征作为图的表征
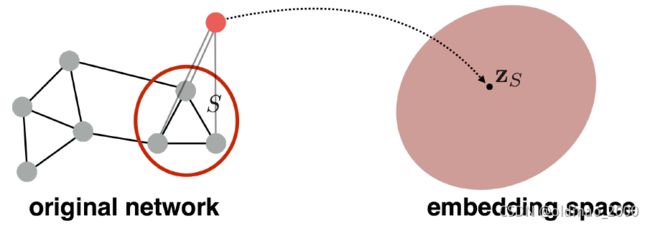
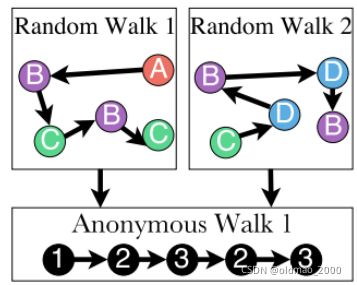
法3:使用anonymous walks表征,用游走序列中访问节点的顺序作为节点的index,然后得到index的序列作为图的表征。例如有图结构为:

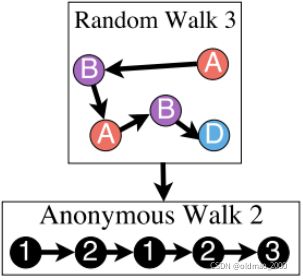
下面两种随机游走结果对应的index序列一样:
随着index序列的长度,节点组合也指数级增加:
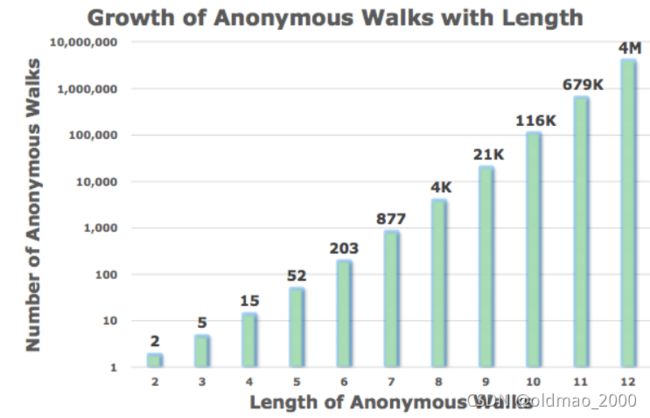
There are 5 anon. walks i _i wi of length 3:
1 = 111 , 2 = 112 , 3 = 121 , 4 = 122 , 5 = 123 _1=111, _2=112, _3= 121, _4= 122, _5= 123 w1=111,w2=112,w3=121,w4=122,w5=123
注意不会有133
有了anonymous walks结果后,用anonymous walks的概率分布来表征整个图。
例如:对于index长度为3的anonymous walks,我们知道可以表示一个5维向量
然后计算anonymous walks出现在 1 = 111 , 2 = 112 , 3 = 121 , 4 = 122 , 5 = 123 _1=111, _2=112, _3= 121, _4= 122, _5= 123 w1=111,w2=112,w3=121,w4=122,w5=123的次数即可。
采样anonymous walks的次数和我们想要得到的分布的概率参数有关,不展开,有公式。
新法 Learn Walk Embedding
这里是把anonymous walks的结果进行随机采样,然后得到一组anonymous walks的序列,例如图:
得到序列:
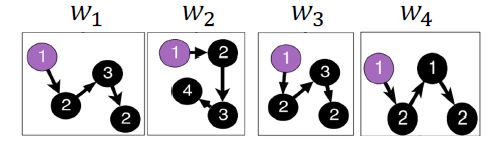
然后利用Node2Vec的思想,根据周围预测中间,然后训练得到图的表征,如果我们取窗口大小 Δ = 1 \Delta=1 Δ=1,那么就是要用 w 1 , w 3 w_1,w_3 w1,w3预测 w 2 w_2 w2