CS224W 13 Community Detection in Networks
目录
13.1 Community Detection in Networks ——直观解释
信息如何在网络中流动(以社交网络为例)
社区如何形成?
Edge Overlap
13.2 Network Communities
定义
Modularity
13.3 Louvain Algorithm
13.4 Detecting Overlapping Communities
Community- Affiliation Graph Model(AGM)
使用AGM检测社区
思路
Graph Likelihood P(G|F)——计算F生成G的可能性
"Relaxing" AGM: Towards P(u,v)——扩展AGM以说明成员优势
BigCLAM Model
13.1 Community Detection in Networks ——直观解释
Community Detection本质上是对图中的一组节点进行集群(基于网络结构)。社区内边比社区间边多。
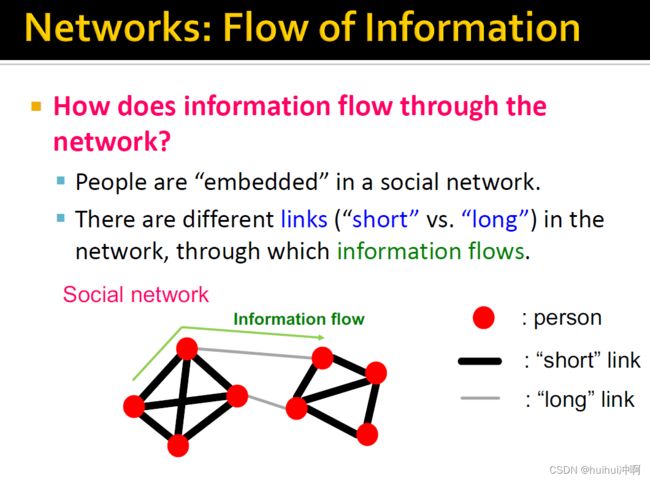
信息如何在网络中流动(以社交网络为例)
1.人被嵌到网络中的节点上。信息通过不同的边流动(short:两个人联系很紧密 long:两人联系很弱)
 2.有研究表明找工作时,是通过weak连接的熟人找到的,而不是那些强连接的亲密朋友,为什么?
2.有研究表明找工作时,是通过weak连接的熟人找到的,而不是那些强连接的亲密朋友,为什么?
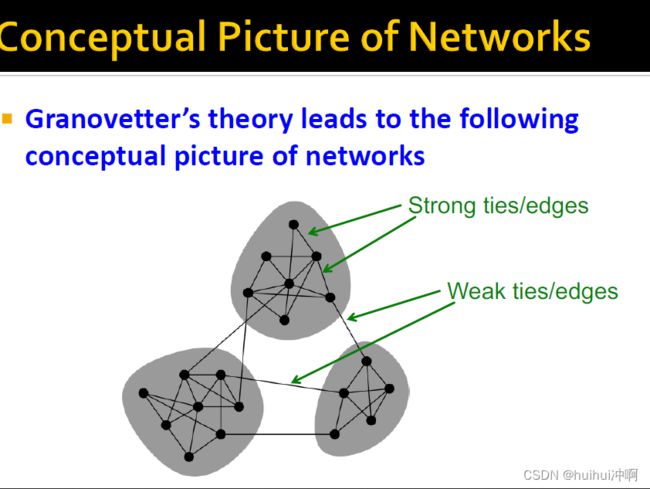
Granovetter's Answer
- 对友谊(链接)的两种观点:
边的Structural结构性作用。社区间边连接网络不同部分。社区内边很好的嵌入在网络内部,拥有共同好友建立非常紧密的关系。
interpersonal(人际关系)。两个人之间的关系是strong还是weak
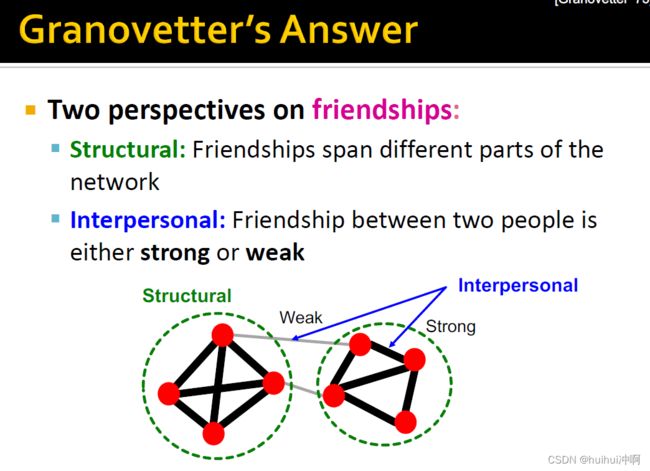
- Granovetter建立了边的social 和 structural作用的联系
- 第一种观点Structure
- structural embedded(紧密连接)的边socially strong,有很多紧密联系的人,结构性很强。
- 连接不同部分的远程边socially weak
- 第二种观点Information
- 远程边可以让你聚集网络不同部分的信息
- structural embedded 边则在信息获取上有很重的冗余(你朋友都和你有直接联系的边,谁知道工作可以直接告诉你,那这个工作信息在通过其他朋友的其他边传播就没用了)
社区如何形成?
社区倾向于使用Triadic Closure(三重闭合)来形成:因为如果网络中的两个人有个共同好友,那么他们二人也很可能成为朋友。
1.Triadic Closure
Triadic Closure的度量通过聚类系数度量。
Edge Overlap
边在结构上的weak strong可以用Edge Overlap的概念来量化。描述边的端点共有多少邻居。
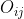 是边的两个端点i和j除了自身外 共有的邻居节点数➗两者邻居节点数之和。越高,连接越强
是边的两个端点i和j除了自身外 共有的邻居节点数➗两者邻居节点数之和。越高,连接越强
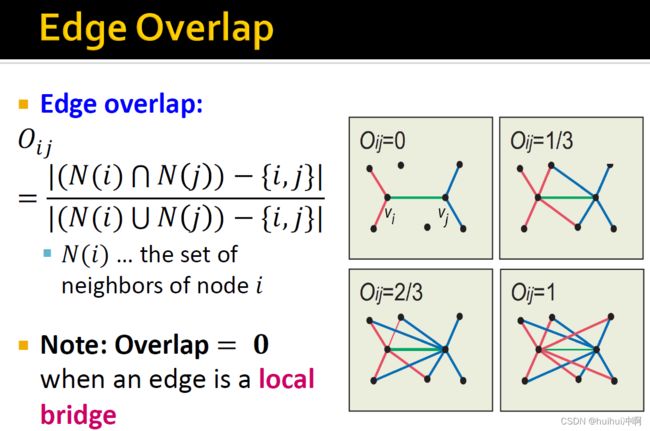
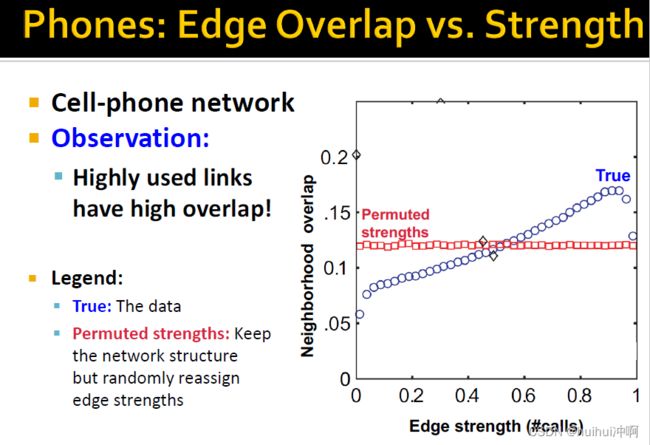
从图中看出,越高的overlap,边使用的频率越高,电话数量会越多。
基于strength移除边。如果移除weak边(连接网络不同部分),断开网络连接的速度很快;如果移除strong边(嵌入网络集群中,使用频率会很高),也不一定会断开网络连接,因此速度慢。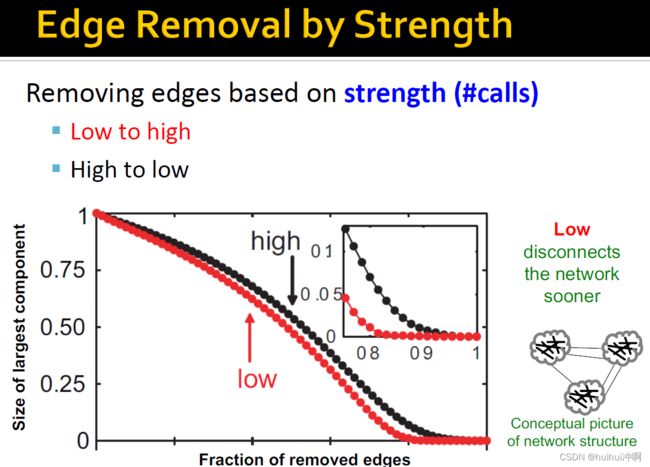
基于edge overlap移除边。如果移除低overlap的边,断开网络连接的速度很快
interpersonal strength 是高overlap,embedding在网络中,有很强的联系;低或者零overlap的边,连接网络不同部分,往往weak
13.2 Network Communities
定义
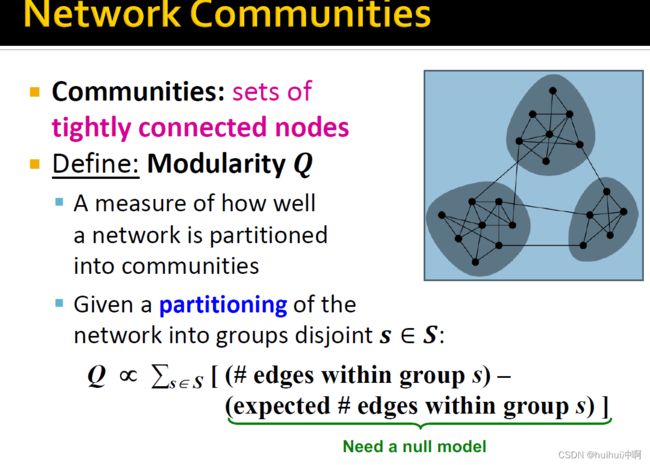
网络是由紧密连接的多个节点集构成的。
网络社区的概念:节点集具有大量内部连接和少量的外部连接(和网络其他部分的连接)
如何自动找到紧密连接的节点组?理想上紧密连接的节点组和真实的节点组相对应。
Modularity
1.定义
模块化衡量网络被多好的划分为社区。
目标:找到一组分区是模块化程度尽可能高。
Q = 每个小组s内边的个数和期望的null model的小组s内边个数的差,再对所有小组求和。
2.null modlel 构建
在给定的有n个节点和m条边的真实图G,构造rewired network G'
- 有相同的degree 分布,但是随机的连接
- 考虑G'中节点之间可能有多重边
- 节点i与j之间期待的边数
 (因为对每一个节点i,练到j的概率为
(因为对每一个节点i,练到j的概率为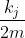 ,i的度数为
,i的度数为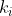 )
)
 图G'中期望的边的数目为2m,因此 在零模型下,度分布和边缘的总数都被保留下来。
图G'中期望的边的数目为2m,因此 在零模型下,度分布和边缘的总数都被保留下来。
这个模型适用于加权或未加权网络。

3.模块度总结
模块度是对所有组 组内所有节点对之间真实边数与构造的空模型边数的差的和 求和,再归一化。模块度的值在[-1,1]之间,如果组内的边数超过预期的边数,那么为正值。
在实践中如果Q值大于0.3-0.7表明图有我们确定的很强的社区结构。

可以通过最大程度地提高模块性得分确定社区
13.3 Louvain Algorithm
1.简介
- 是一种利用模块度检测社区的贪婪算法(Greedy algorithm)。
- 时间复杂度为O(nlogn)
- 支持加权网络
- 提供分层社区
- 可以很好的用于大型网络——因为快速、快速收敛、输出高模块度
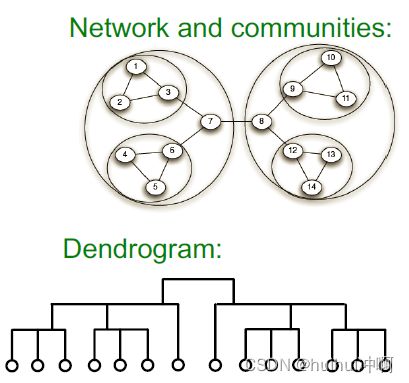
2.Louvain算法
(1)步骤
- step1:模块度优化阶段——只允许社区的局部变化
-
初始时将每个顶点当作一个社区,社区个数与顶点个数相同
-
对每一个节点i
-
依次将每个顶点与邻居顶点合并在一起,计算它模块度增益,找到模块化增益最大的方案
-
如果该最大的模块化增益>0,将该节点放入模块度增量最大的邻居节点j所在社区
-
- 迭代第二步,直至算法稳定,即所有顶点所属社区不再变化(任何一个节点的移动不会增加模块度)
-
- step2:网络凝聚阶段——凝聚所发现的社区,以便构建新的社区网络
- 如果相应社区的节点之间至少有一个边,则连接超级节点
- 将各个社区所有节点压缩成为一个节点,社区内节点的权重转化为新节点环的权重,社区间权重转化为新节点边的权重。

- 将step1和step2和称一个pass,不断迭代pass,直到模块度不可能增加
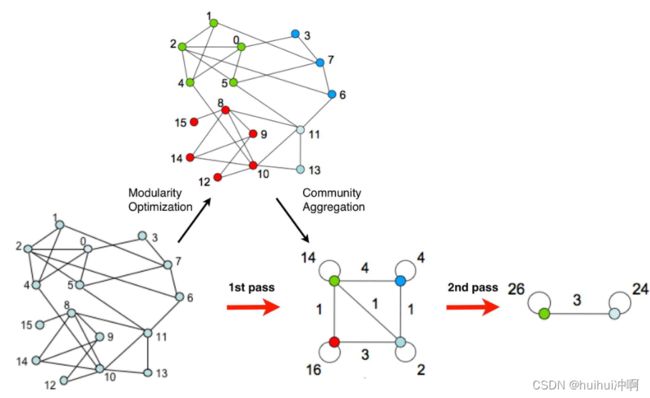
(2)算法问题
在step1中注意到算法输出依赖于考虑的节点的顺序,但研究表明节点顺序对结果有显著的影响。
(3)算法细节
- step1中模块度变化量ΔQ的计算
ΔQ 的变化 = 将节点i先从原来社区移除的Q的变化+再将节点i移入新社区C的Q的变化 ,即
![]()
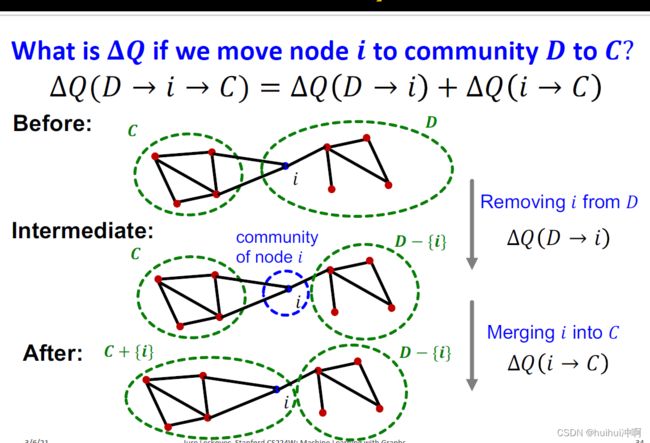
以将节点i移到社区C的ΔQ为例
定义社区C内节点间连接的权重的和;C内所有节点的连接的权重和;计算出社区C的Q如下图所示,当Q(C)大时,表示大多数连接都在社区内。

进一步定义:节点i和社区C内节点的连接权重之和;节点i的所有连接的权重和
可以计算出合并前Q(C)+Q({i}) 合并后Q(C)+Q({i})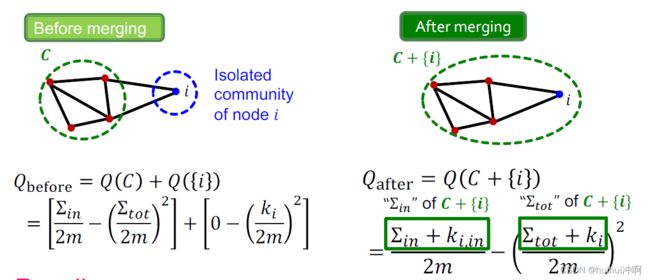
最后计算出![]() ,之后
,之后![]() 可以类似计算出
可以类似计算出
- step1总结

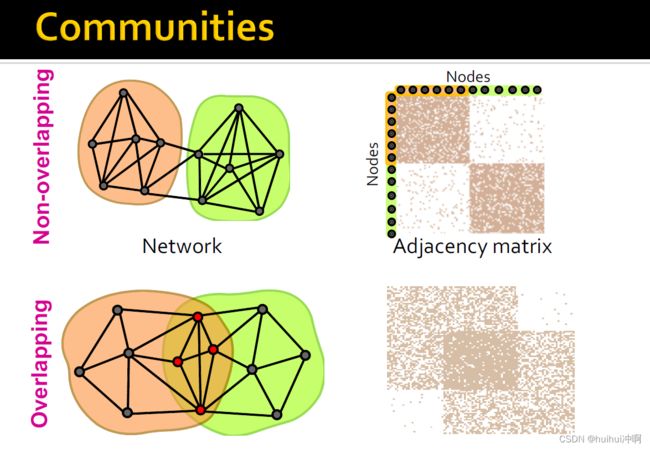
13.4 Detecting Overlapping Communities
一个节点可能属于不同社区。
下图是非重叠社区与重叠社区的邻接矩阵对比
如何检测社区结构?
步骤:
step1:为基于节点社区隶属关系的图定义生成模型(AGM)。
step2:定义一个优化问题。给定一个图G,假设图是由AGM产生的,找到最可能产生给定图的AGM

Community- Affiliation Graph Model(AGM)
- AGM:将节点分配给社区,如何产生网络的边 (根据社区隶属度——即给定参数,一个网络怎么生成边)。
- 给定参数(V,C,M,{
 }),V为节点,C是社区,M是成员关系,每一个社区有一个单独的概率
}),V为节点,C是社区,M是成员关系,每一个社区有一个单独的概率
- 社区c内节点抛硬币以的概率相互连接(抛硬币是的话则连接)
- 共属于多个社区间的顶点有多次抛硬币的机会连接(如果第一次机会不行,还有来自下一个社区的机会)
- 两个节点u与v之间连接的概率,为1减去在任何情况下都无法生成边的概率。
- 若两者都属于社区c那么无法生成边的概率为1-,生成边的概率为
- 若两者属于不同的社区,则无法生成边的概率为1,生成边的概率为0
- 若两者共同属于社区c1、社区c2 那么生成边的概率为(1-
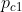 )(1-
)(1-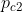 ) 第一次机会没成功第二次机会也没成功 ,生成边的概率为 1-(1-)(1-)
) 第一次机会没成功第二次机会也没成功 ,生成边的概率为 1-(1-)(1-)
- 若两者都属于社区c那么无法生成边的概率为1-
- 社区c内节点抛硬币以
可以定义为:
![]()
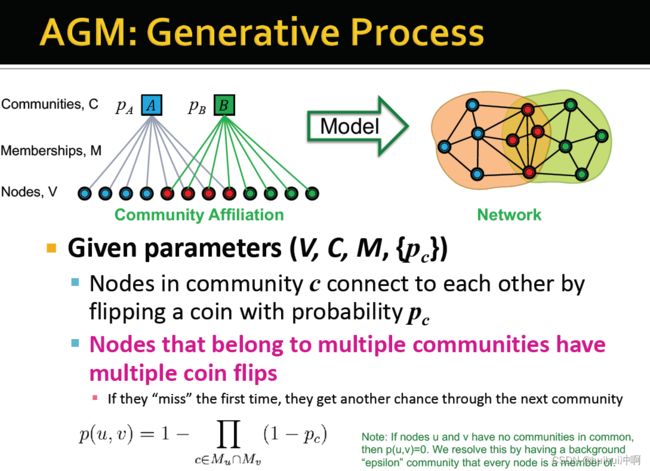
AGM模型:给定参数(V,C,M,{}),知道如何生成模型
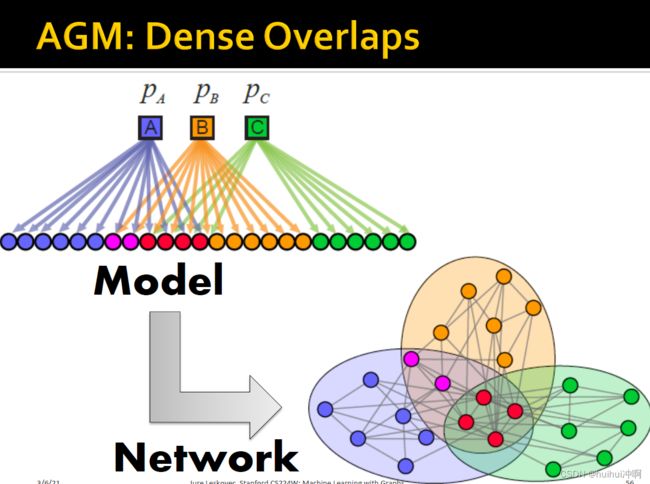
AGM非常灵活,可以表达各种各项的社区结构:非重叠社区、重叠社区、分层社区。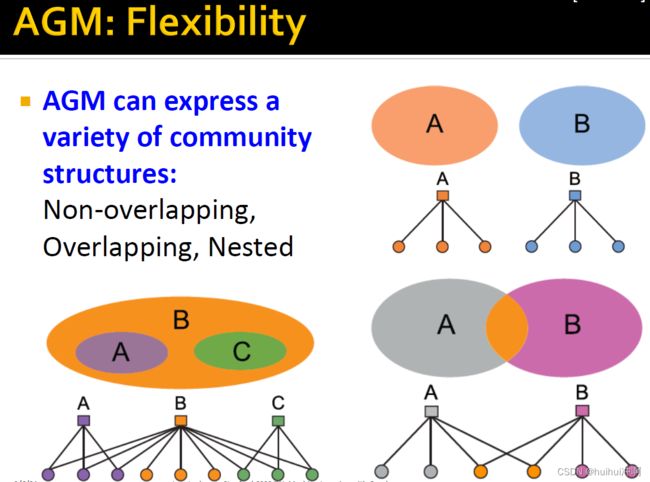
使用AGM检测社区
思路
1.做相反操作:给定一个图G,找到生成这个图的最可能的AGM的参数(model F),即需要决定参数的值:
1)M:节点如何隶属于社区
2)社区的数量C
3)参数
2.使用最大似然估计——根据给定图G估计模型F参数
- 给定图G最大化模型F生成真实图G的过程
- 为了解决问题需要有效的计算P(G|F),然后优化

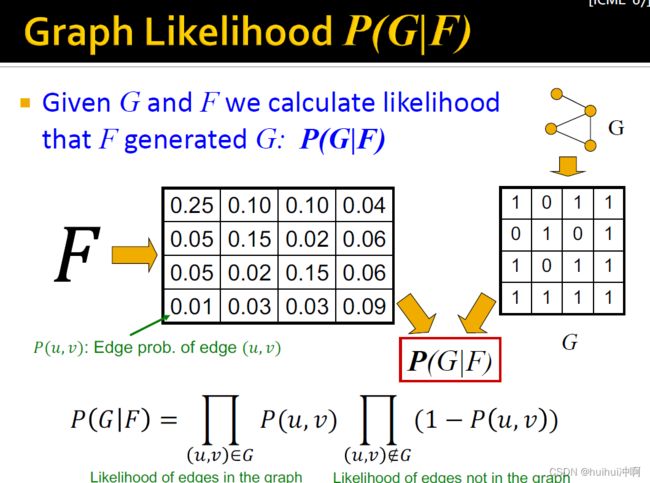
Graph Likelihood P(G|F)——计算F生成G的可能性
给定G和F计算似然函数F产生G:P(G|F)。给定模型G和为每一条边分配概率的F,计算F生成图G的可能性。
给定图G,G的邻接矩阵作为输入,模型F为每个边分配一个可能发生的概率,计算概率邻接聚沉可以生成G的可能性。遍历所有G的邻接矩阵中元素1的位置(出现边),在F产生的概率邻接矩阵中对应位置的概率值希望尽可能大,即![]() 尽可能大;遍历所有G的邻接矩阵中元素0的位置(无边),在F产生的概率邻接矩阵中对应位置的概率值希望尽可能小,即
尽可能大;遍历所有G的邻接矩阵中元素0的位置(无边),在F产生的概率邻接矩阵中对应位置的概率值希望尽可能小,即![]() 尽可能大。
尽可能大。
"Relaxing" AGM: Towards P(u,v)——扩展AGM以说明成员优势
1.基本
和原来每个社区有参数不同,这里改变为,为每一个节点分配:节点的membership strength节点加入某社区的实力。如果strength=0说明节点不属于这个社区。

2.如何写出两个节点的连接概率
1)两者通过一个共同社区相连的概率
其中membership strength是非负的。如果两个节点对社区C的membership strength都很高,那么两者连接的可能性很高;反之则很低。如果至少一个节点对C的membership strength为0,则两个节点无法通过C连接。

2)两者通过多个共同社区相连的概率
节点u和v通过任一个社区连接的概率 = 1 - 两者不通过任一个社区连接的概率
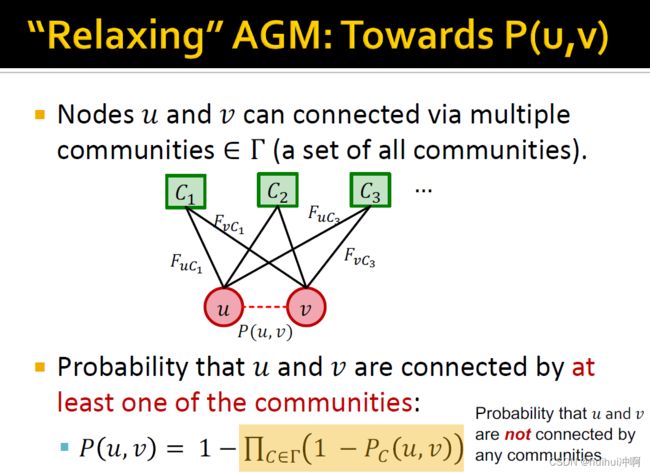
可以进一步扩展,很优雅,因为利用了节点u和v的membership strength向量的内积。
BigCLAM Model
1.在进行AGM的扩展后,基于membership strength定义的节点u与v连接概率,给定图G后,最大化该模型F下生成图G的似然概率。
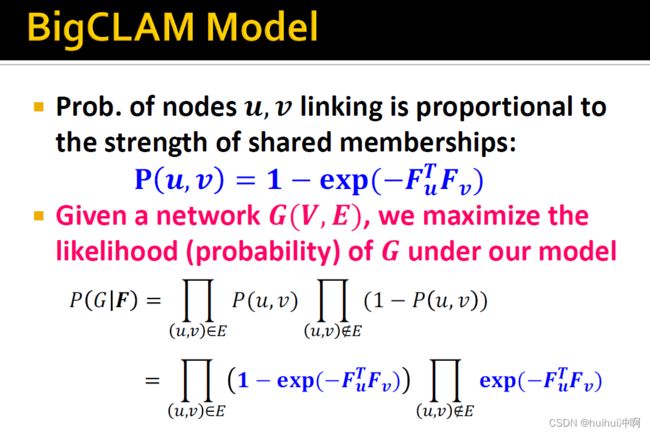
2.但是上图的似然函数计算,涉及到很多小概率的数值相乘,容易造成数据不稳定,因此考虑取对数(对数和原函数在相同的地方取极值,不改变单调性,将相乘变为相加,同时解决数据不稳定问题),得到了我们的目标函数L(F)。

3.优化目标函数。
- 初始化,从随机menbership F开始
- 不断迭代,直到收敛
- 对于任意一个节点
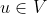
- 固定其他节点的membership,更新节点u的membership
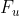
- 做梯度上升,对做小的改变增大对数似然函数。
- 固定其他节点的membership,更新节点u的membership
- 对于任意一个节点

4.对梯度的改进
注意到,梯度计算时设计涉及到节点u的邻居节点与非邻居节点,由于一个节点的邻居节点数很少,但非邻居节点数很多,计算复杂度都在遍历非邻居节点,那能否改进?
将非邻居节点的遍历改为:所有节点 - 节点u本身 - 节点u的邻居节点
由于所有节点只需要计算一次,节点u的邻居节点数少,很好的简化了节点u的非邻居节点的遍历。

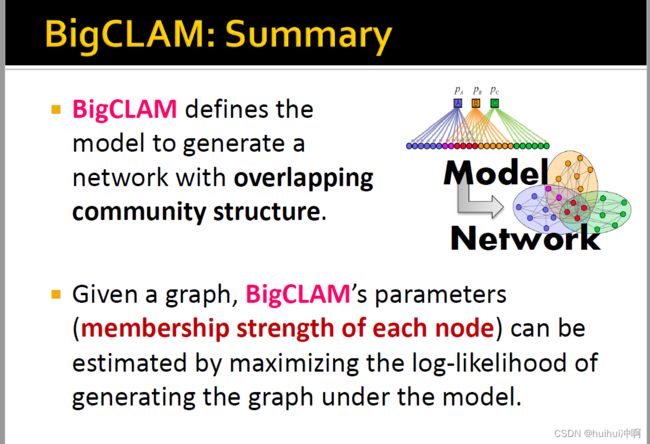
5.总结
- BigCLAM基于membership stength 定义了一个模型,这个模型可用于生成重叠社区结构。
- 给定一个图G如何找到BigCLAM的参数(每个节点的membership strength)?可以最大化模型F生成给定图的对数似然函数来求解。