深入理解卡尔曼滤波算法
最近做卡尔曼滤波跟踪的项目,看原理花了一天,再网上查找并看懂别人的kalman c++代码花了我近三天的时间。卡尔曼滤波就是纸老虎,核心原理不难,核心公式就5个,2个状态预测更新公式,3个矫正公式。这里只讲解线性kalman滤波模型,非线性kalman滤波可以用扩散kalman滤波算法。
概述
卡尔曼滤波算法从名称上来看落脚点是一个滤波算法,一般的滤波算法都是频域滤波,而卡尔曼滤波算法是一个时域滤波,时域就是它的强大之处。卡尔曼滤波也是一种最优估计算法,常见的最优估计算法有“最小二乘法”等,卡尔曼滤波也是一个迭代器,根据以知的先验值,预测下一时刻的估计值。
再说说滤波这个名词,本质上就是给加权。既然是加权,那么卡尔曼滤波算法本质就是数据融合的操作(Data fusion),卡尔曼增益就是融合过程中的权重,融合的内容有两个:分别是满足一定分布的先验状态估计值和满足一定分布的观测值之间的融合(也就是你们可能在其他资料上看到的两个椭圆相乘,其实就是数据的融合),融合后得到后验状态估计值。
其实深度学习中的卷积操作也是加权求和,本质上也是滤波,本质上也是求导,比如边缘检测的离散微分算子sobel的计算过程,也是分别在x和y两个方向上求导,提取出边缘特征。(下面是我个人的思考)由点及面,我们就可以想像到一个大尺寸的卷积核,其实就相当于“变形求导”,通过卷积核内部权重数值大小给定求导曲线,卷积就是求解在这条曲线上的导数。 一个卷积核是提取特征,那么多个卷积核组合起来就有无限可能,提取到的就是高维特征(高维特征对应图片的纹理等深层次的语义信息),组合起来非常之强大,就能够实现深度学习中的分类、边框回归等功能。
直接上菜 - 牛逼哄哄的五大公式

下面来一个个详细剖析每个参数:
1.![]() 分别表示 k - 1 时刻和 k 时刻的后验状态估计值,是滤波的结果之一,即更新后的结果,也叫最优估计(估计的状态,根据理论,我们不可能知道每时刻状态的确切结果所以叫估计)。
分别表示 k - 1 时刻和 k 时刻的后验状态估计值,是滤波的结果之一,即更新后的结果,也叫最优估计(估计的状态,根据理论,我们不可能知道每时刻状态的确切结果所以叫估计)。
2,![]() : k 时刻的先验状态估计值,是滤波的中间计算结果,即根据上一时刻(k-1时刻)的最优估计预测的k时刻的结果,是预测方程的结果。
: k 时刻的先验状态估计值,是滤波的中间计算结果,即根据上一时刻(k-1时刻)的最优估计预测的k时刻的结果,是预测方程的结果。
3,![]() :分别表示 k - 1 时刻和 k 时刻的后验估计协方差(即的协方差,表示状态的不确定度),是滤波的结果之一。
:分别表示 k - 1 时刻和 k 时刻的后验估计协方差(即的协方差,表示状态的不确定度),是滤波的结果之一。
4,![]() :k 时刻的先验估计协方差(的协方差),是滤波的中间计算结果。
:k 时刻的先验估计协方差(的协方差),是滤波的中间计算结果。
5,H:是状态变量到测量(观测)的转换矩阵,表示将状态和观测连接起来的关系,卡尔曼滤波里为线性关系,它负责将 m 维的测量值转换到 n 维,使之符合状态变量的数学形式,是滤波的前提条件之一。
6,![]() :测量值(观测值),是滤波的输入。
:测量值(观测值),是滤波的输入。
7,![]() :滤波增益矩阵,是滤波的中间计算结果,卡尔曼增益,或卡尔曼系数。
:滤波增益矩阵,是滤波的中间计算结果,卡尔曼增益,或卡尔曼系数。
8,A:状态转移矩阵,实际上是对目标状态转换的一种猜想模型。例如在机动目标跟踪中, 状态转移矩阵常常用来对目标的运动建模,其模型可能为匀速直线运动或者匀加速运动。当状态转移矩阵不符合目标的状态转换模型时,滤波会很快发散。
9,Q:过程激励噪声协方差(系统过程的协方差)。该参数被用来表示状态转换矩阵与实际过程之间的误差。因为我们无法直接观测到过程信号, 所以 Q 的取值是很难确定的。是卡尔曼滤波器用于估计离散时间过程的状态变量,也叫预测模型本身带来的噪声。状态转移协方差矩阵
10:R: 测量噪声协方差。滤波器实际实现时,测量噪声协方差 R一般可以观测得到,是滤波器的已知条件。
11,B:是将输入转换为状态的矩阵
12,![]() :实际观测和预测观测的残差,和卡尔曼增益一起修正先验(预测),得到后验
:实际观测和预测观测的残差,和卡尔曼增益一起修正先验(预测),得到后验
插曲一下:我认为最伟大的公式当属麦克斯韦方程组,十分的美妙,像一个妙龄少女,闭月羞花,沉鱼落雁,爱了爱了,哈哈哈。。。。
但是卡尔曼滤波也十分了不起,同样牛逼哄哄。
说到这儿,摆上大餐,提提文章档次,微分形式的麦克斯韦方程组(核心是两个散度两个旋度):
![]()

![]()

言归正传,转到正台:
建模(这里讲的数据都是矩阵)
卡尔曼滤波算法是需要建模的,拿高中物理中典型的例子举例,在二维平面中,跟踪一个质量为m的小球,t0时刻有水平速度v0,只受到重力作用运动,让你找出小球接下来的真实轨迹。你很快想到,很简单,我拿一个相机拍下小球的运动轨迹就好了。理论上没错,事实上拿相机记录也存在一定误差,怎么样来描述这个误差了,我们想到高斯噪声是最常见的噪声类型,那么我们假定相机的观测误差vk满足期望为‘0’协方差矩阵为R的高斯噪声vk~N(0,R),协方差矩阵为R反应了测量噪声的分布情况,矩阵R的迹越大,说明误差越分散,进一步说明测量值置信度越低。
同时,我们建立一个理想模型来表述它或者叫预测它。假定系统的状态方程为(公式推导可以自己查阅资料):
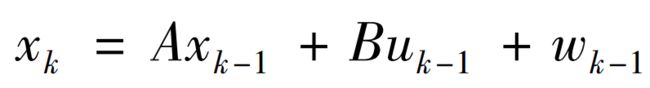
这个状态方程是根据上一时刻的状态(这里指的是上一时刻的后验估计状态值,嗯,这样说比较准确)和控制变量来推测此刻的状态,由于世界上没有理想的理论模型,wk-1是服从高斯分布的噪声,是预测过程的噪声,它对应了 xk 中每个分量的噪声,期望为 0,协方差为 Q 的高斯白噪声wk-1~N(0,Q),Q即过程激励噪声协方差矩阵Q。
首先我们需要确定预测的状态变量数量和观测值,比如我们跟踪的是上面的模型,要知道小球的位置,那么我们可以给定预测4个状态值(x,y,vx,vy),观测值就点的坐标(x,y)。我们可以通过k-1次的测量值,来估计第k次的先验估计值,再用卡尔曼增益值将第k次的测量值和第k次的先验估计值做融合,得到第k次的后验估计值,第k次的后验估计值就是我们求出的最优解。
OpenCV中关于Kalman滤波的结构和函数定义
Kalman 滤波器状态,具体如何使用请查看opencv官方给的kalman案例。
typedef struct CvKalman
{
int MP; /* 测量向量维数 */
int DP; /* 状态向量维数 */
int CP; /* 控制向量维数 */
/* 向后兼容字段 */
#if 1
float* PosterState; /* =state_pre->data.fl */
float* PriorState; /* =state_post->data.fl */
float* DynamMatr; /* =transition_matrix->data.fl */
float* MeasurementMatr; /* =measurement_matrix->data.fl */
float* MNCovariance; /* =measurement_noise_cov->data.fl */
float* PNCovariance; /* =process_noise_cov->data.fl */
float* KalmGainMatr; /* =gain->data.fl */
float* PriorErrorCovariance;/* =error_cov_pre->data.fl */
float* PosterErrorCovariance;/* =error_cov_post->data.fl */
float* Temp1; /* temp1->data.fl */
float* Temp2; /* temp2->data.fl */
#endif
CvMat* state_pre; /* 预测状态 (x'(k)):
x(k)=A*x(k-1)+B*u(k) */
CvMat* state_post; /* 矫正状态 (x(k)):
x(k)=x'(k)+K(k)*(z(k)-H*x'(k)) */
CvMat* transition_matrix; /* 状态传递矩阵 state transition matrix (A) */
CvMat* control_matrix; /* 控制矩阵 control matrix (B)
(如果没有控制,则不使用它)*/
CvMat* measurement_matrix; /* 测量矩阵 measurement matrix (H) */
CvMat* process_noise_cov; /* 过程噪声协方差矩阵
process noise covariance matrix (Q) */
CvMat* measurement_noise_cov; /* 测量噪声协方差矩阵
measurement noise covariance matrix (R) */
CvMat* error_cov_pre; /* 先验误差计协方差矩阵
priori error estimate covariance matrix (P'(k)):
P'(k)=A*P(k-1)*At + Q)*/
CvMat* gain; /* Kalman 增益矩阵 gain matrix (K(k)):
K(k)=P'(k)*Ht*inv(H*P'(k)*Ht+R)*/
CvMat* error_cov_post; /* 后验错误估计协方差矩阵
posteriori error estimate covariance matrix (P(k)):
P(k)=(I-K(k)*H)*P'(k) */
CvMat* temp1; /* 临时矩阵 temporary matrices */
CvMat* temp2;
CvMat* temp3;
CvMat* temp4;
CvMat* temp5;
}
CvKalman;
实践(C++)
目前经典的MOT多目标跟踪算法是sort、deepsort,其中sort算法是先经过Hungarian algorithm(匈牙利算法)进行最大匹配,再经过本文的kalman滤波进行预测。实际项目中我是先用常规(ssd或者yolo)等检测网络,检测出框,,再用最简单的IOU匹配跟踪,再用kalman进行预测。发现加了kalman滤波效果没提升,甚至框子抖动稍微大了一些(打印了kalman预测前后的数值,确认了kalman在工作):原因可能是因为自己使用的是kalman均速模型,而我们神经网络检测出的物体框存在误差(抖动),所以如果每次检测框不准确(抖动过大或者忽大忽小),会导致均速的kalman模型预测也跟着抖动,甚至抖动幅度更大了。切换到加速度kalman模型,发现乱框,加速度kalman模型不能用在目标检测框跟踪上。项目上参考的代码是:https://github.com/Smorodov/Multitarget-tracker
由于kalman滤波需要建模,所以它适用于跟踪目标符合一定的规律或者趋势,检测框的不确定性太大了,可以试试,一般效果不大,最终还是取决于检测效果的好坏。
最后收尾:每一个物理学家的必定都是数学家。