Tensorflow图像识别 Tensorflow手写体识别(一)
MNIST数据集

任务目标

网络结构
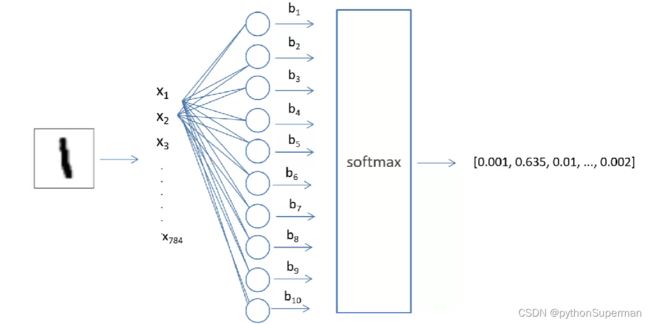
这个案例是图像识别的一个入门级的案例。
我们把这个28×28的这个单通道的图像,每一个像素拿出来做一个特征,原始的图像是28×28。它是灰度图像,所以只有一个通道。其中的每一个像素拿出来做一个特征,所以一共是28×28=784的特征。我们使用x1,x2......x784用来表示这784个特征。这一列x就是我们的输入层。
后面是一个全连接模型,这个全连接模型要输出10个类别的数字,所以它有10个神经元(图中用一列圆圈表示),每一个输入和每一个神经元相连,比如说x1要与全连接层的十个中的每一个神经元相连。每一条相邻的边都有一个权重值,比如x1和第一个神经元相连有一个权重,x2与第二个神经元相连有一个权重。一共有784个特征,所以一共有784个权重。
这里要产生10个输出,我们在每一个输出上加一个偏置b,所以这里偏置的数量是10。产生10路输出,在softmax的挤压下产生10个概率,这10个概率都是位于0到1之间的。比如这个数字,经过计算,在softmax函数的作用下产生了10个概率,第一个概率是0.001,第二个概率是0.635......这10个概率代表这个输入的数字它属于这10个数字的概率,我们取其中最大的概率。比如这一行概率中0.635是最大的,我们就用这个作为我们预测的结果。
这就是我们的图像识别原理,后面我们的图像分类,图像识别也基本上是这个原理,将图像输入到我们的网络当中,在网络的计算下产生一组概率,我们看哪个概率最大,哪个就作为我们的预测结果。这就是这个示例的网络模型。
相关API

matmul()是用来做矩阵相乘的,我们的权重s和输入w要做一个相乘,实际这个地方就是矩阵的相乘。
softmax()在神经网络计算完以后产生十路输出,在softmax的挤压下转换成10个相对的概率,这些概率加起来的总和为1。
reduce_sum()是用来求和的,我们计算总体样本的误差就会用到。
train.GradientDescentOptimize()优化器会把损失函数优化到最小,找到损失函数的最小值,也就找到了最优的参数。
argmax()求数组中值最大的下标
关键代码

x:
对于全连接网络模型来说,只能接受一维的数据,我们的图片是一个二维的矩阵,直接把二维的矩阵喂给全连接模型时不行的,如果前面加一个卷积层就可以,我们下一个示例就是用到的卷积神经网络,这个里面是没有卷积层的,所以这个全连接模型是不能接收二维数据的,怎么办呢,把它拉伸成为一维的。把28×28的值拉伸成一个行向量,比如说:

每一次可能会使用n个样本执行训练,所以这里就是n行784列,

所以这里的输入就是n行784列,表示n个图像,每个图像有784个特征。
y:
每一个样本都对应一个真实的类别,比如说第一个样本,它的真实类别为1,那么1的话我们可以用独热编码的方式把它表示出来:

比如第二个样本它的数字是2
![]()
w:
为了和矩阵x相乘,所以是[784,10]
b:
偏置我们将初始值全部设置为0
搭建模型
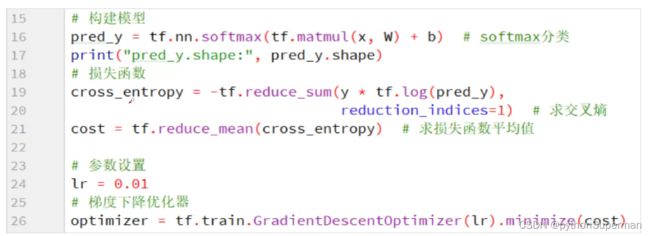
pred_y 使我们预测的结果,将值交给sortmax函数,将其挤压,转换成0到1之间的相对概率。
cross_entroy是总体样本的误差,预测出来的结果和真实结果构建一个交叉熵作为损失函数,这里是分类问题,所以选择交叉熵作为损失函数。根据交叉熵的公式,使用真实的y值×预测的y值求对数,然后求和。(合适根据交叉熵的公式来的)
cost:再求均值,我们就求到了这次训练中每个样本的平均误差,作为我们最后的损失函数cost。
然后将损失函数交给梯度下降优化器,梯度下降优化器(lr为学习率,学习率是一个非常敏感的参数,它主要根据经验来,不能太大也不能太小,太大可能会出现不收敛的情况,太小收敛的太慢)
梯度下降器定义好了之后,我们调用梯度下降器的minimize方法,把损失函数的值优化到最小。
W和b都会不停地进行调整,找到了损失函数的最小值,也就找到了最优的W和b
执行训练:
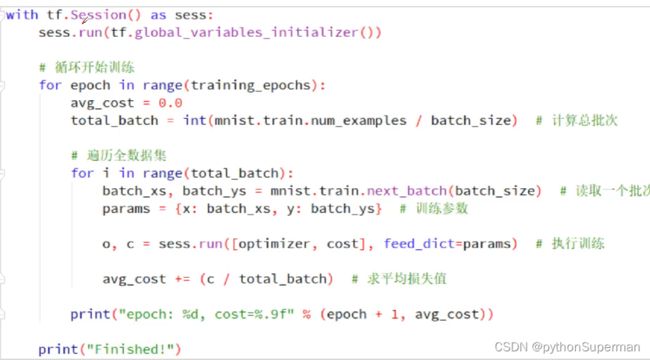
执行训练我们首先定义一个session,在session下面我们执行一个初始化。因为在这个里面,用到了变量,使用变量必须提前进行变量的初始化。
循环开始训练:
total_batch我们算了一个总的批次的数量,一共是60000个样本,每个批次是100个样本。所以这里执行600次训练(每一轮下面执行600次训练)。让每一个样本都能参与到训练当中,每一个样本都不重复进行训练。
每一轮训练:
mnist定义的对象,train表示的是读取训练集下面的数据,next_batch表示读取一个批次的样本。这个样本包含两个数据,第一个图像数据,第二个是图像所属类别,所以我们用两个变量来接手它。
然后我们构建一个字典,把参数放到字典当中,下面训练的时候,要把字典作为参数传进去。
下面就是调用session的run方法。feed_dict来接收params参数。
每一次训练完成之后,我们就求一次损失值的平均数。
每一轮训练完之后,就打印这一轮的损失值。
最外层for循环结束以后,我们训练也就完成了。
模型评估

equal比较,会返回一个布尔类型的数组,如果两个值当中最大的索引值相等就返回true,不相等就返回false。

cast数据类型的转换
reduce_mean求平均值
测试集下的样本以及每个样本所对应的标签。
模型测试
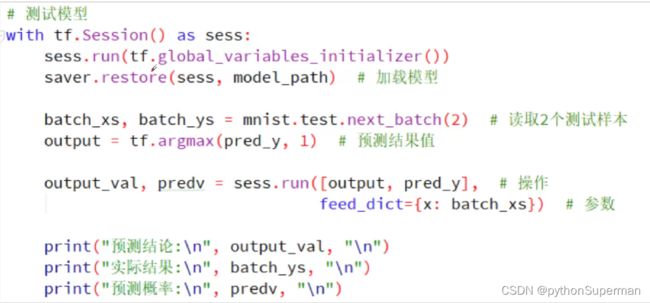
创建一个新的session
图像部分的数据放在xs里,标签部分的数据放在ys里
output打印出最终结果,pred_y把所有预测的值包含的概率,每个数字包含的概率是多少
都打印出来。