TensorFlow与Flask结合打造手写体数字识别
此篇博客记录一下使用Tensorflow进行手写体数字识别的经历。
- 在慕课网进行课程学习:传送门
- 使用minist进行input数据,
- 建立线性(regression)和卷积(convolutional)模型训练参数
- 在main文件夹中使用restore方法取用模型,加载模型。
| TensorFlow是什么 |
|---|
| TensorFlow是谷歌基于distbelief进行研发的第二代人工智能系统 |
| 常用于语音识别或图像识别等机器学习领域 |
| 将复杂的数据结构传输至人工智能神经网络进行分析和处理 |
| 支持CNN、RNN和LSTM算法 |
| MNIST数据集是什么 |
|---|
| 由Google和纽约大学克朗研究所共建的手写数字数据库 |
| 共有70000张训练图像(60000张训练图像和10000张测试图像) |
| 所有图像均是0~9的手写数字 |
整合步骤
训练并生成模型→暴露接口→前端调用→验证并返回结果
遇到的问题
1. numpy版本问题

解决方法:
这种问题是因为TensorFlow和numpy的版本不匹配,我们需要对numpy降版本,现在我的numpy是1.17.0。
所以在cmd中执行以下命令:
pip uninstall numpy #卸载现在的版本
pip install numpy==1.16.0 #指定版本装numpy
如果装了1.16.0仍然报错,那么就继续降版本。安装后就OK。
2. h5py新版本对numpy的兼容问题
FutureWarning: Conversion of the second argument of issubdtype from
floattonp.floatingis deprecated. In future, it will be treated
asnp.float64 == np.dtype(float).type. from ._conv import
register_converters as _register_converters
解决方法:
对h5py进行更新升级,使用如下方法完美解决!
pip install h5py==2.8.0rc1
3. 语句缩进问题
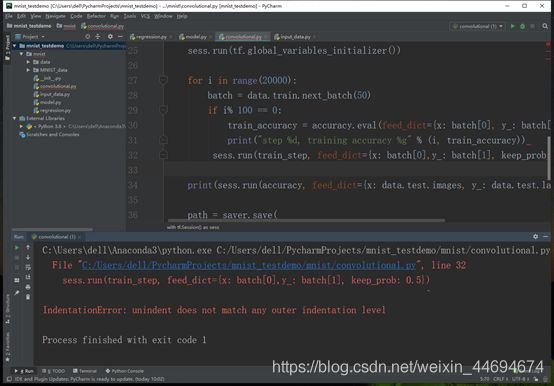
语句缩进数的空格数不一致,会导致运行错误:
IndentationError: unindent does not match any outer indentation level
解决方法:将报错位置的代码段严格按照逻辑结构进行缩进
4.参数设置错误
错误 TypeError: Value passed to parameter ‘input’ has DataType int32 not
in list of allowed values: float16, bfloat16, float32, float64
解决方法:
model.py conv2d那个文件改一下下面这行把:
return tf.nn.conv2d([1, 1, 1, 1], padding='SAME')
改成:
return tf.nn.conv2d(x, W, [1, 1, 1, 1], padding='SAME')
没有传入参数当然出错喽!
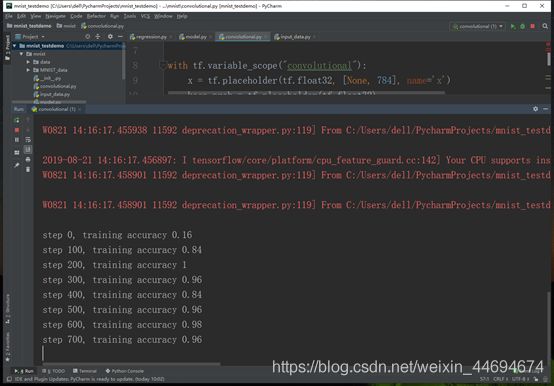
训练了20000轮之后,卷积模型的准确率达到了99.21%。模型自动保存在如下路径:
C:\Users\dell\PycharmProjects\mnist_testdemo\mnist\data
5. TensorFlow版本问题
问题链接:https://github.com/keras-team/keras/issues/13004
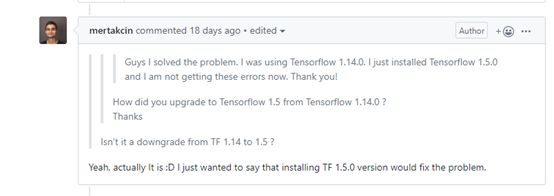
将tensorflow版本由1.14.0降为1.5.0后,问题解决。
成功生成前端页面。识别效果如下:
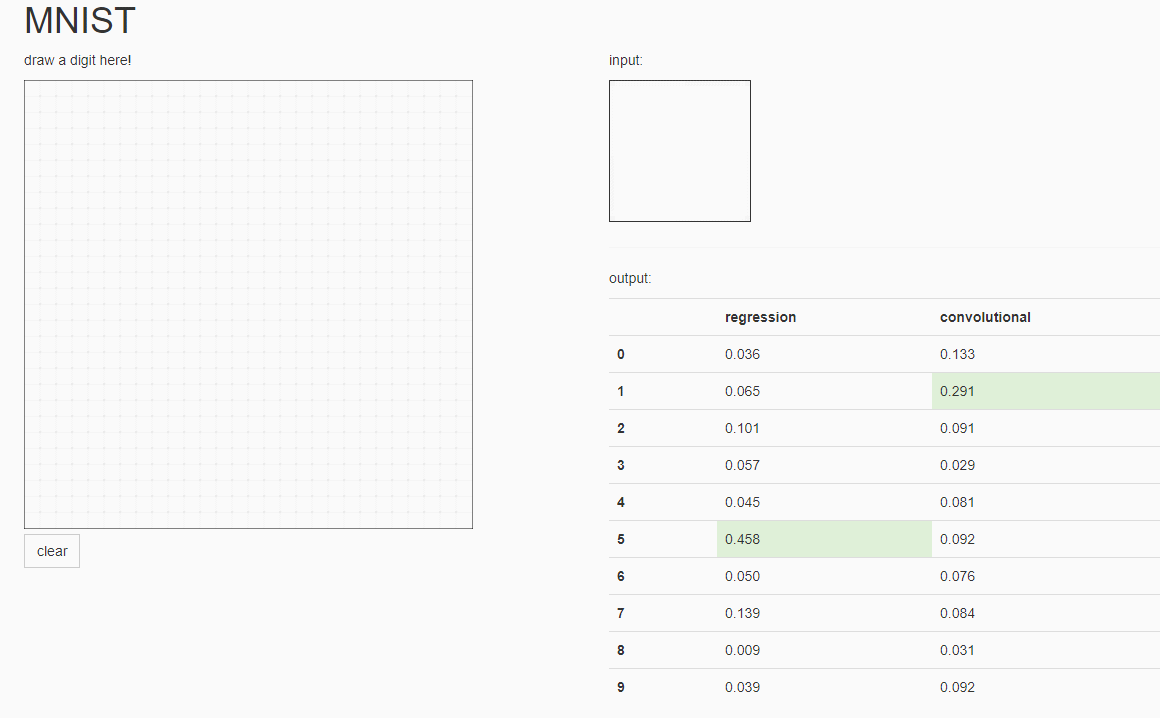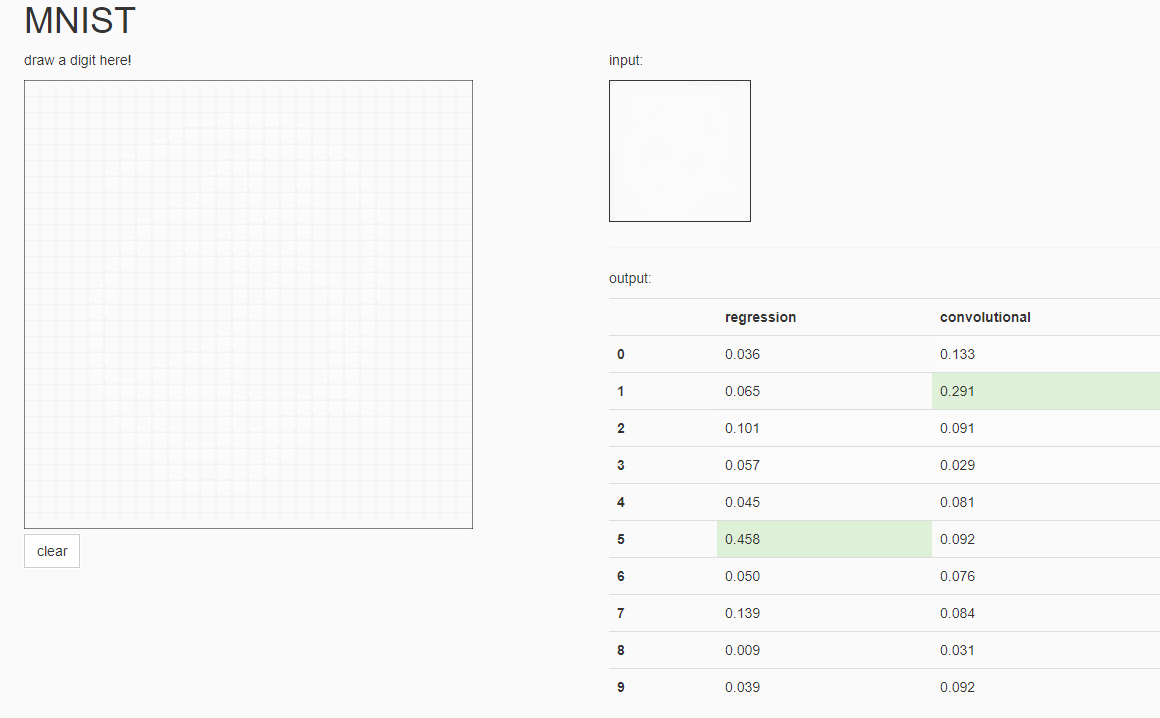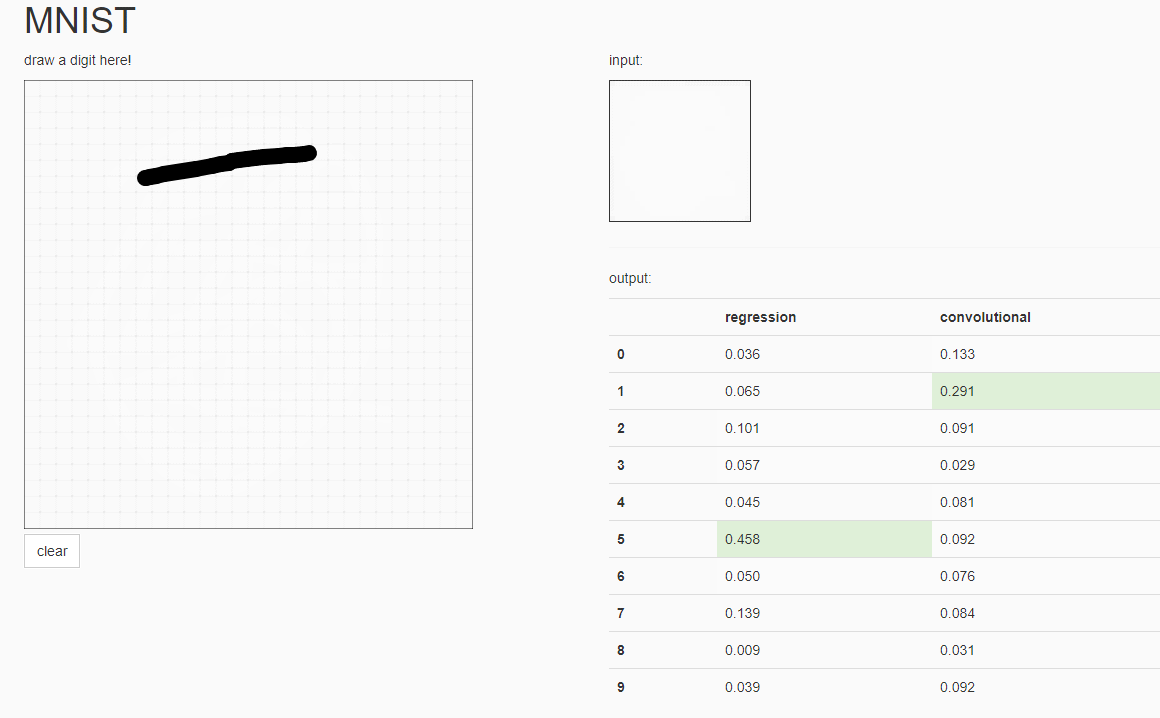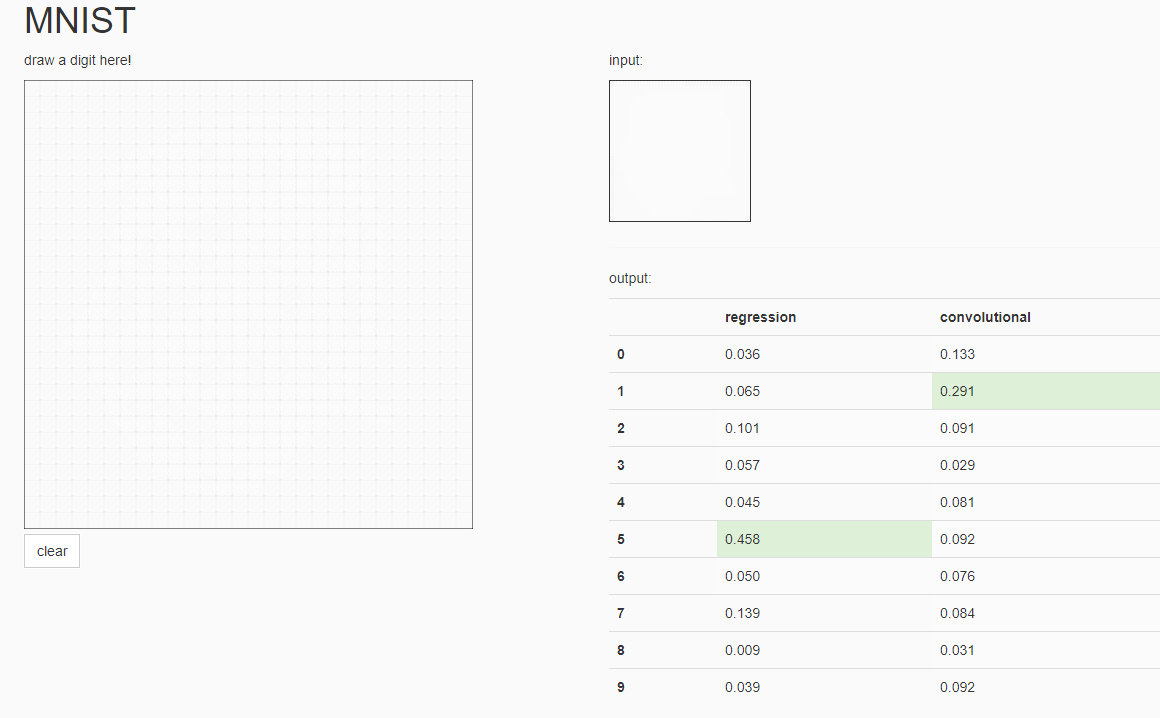
总体来说卷积模型识别精确度高于线性模型,个别数字的识别率两种模型准确率都较低,模型还有待改进。
后记
在将本地项目push到GitHub远程仓库时出现报错:
hint: Updates were rejected because the tip of your current branch is
behind hint: its remote counte
报错原因是:新建远程仓库时,选择新建了README.md文件,但是本地代码初次提交时无该文件,提交时,git认为两者是完全不相干的分支。
解决方案一:
git push -f -u origin master
强推至远程服务器。(强制删除远程仓库中冲突代码,即删除创建的README.md文件,不推荐。)
解决方案二:
git pull origin master --allow-unrelated-histories
此种方式表示可将两个完全不相干的分支合并,出现上述问题时,可通过此种方式解决。
本项目部分参考代码:
https://github.com/hanzhenyu2018/mnist_testdemo