多传感器融合新思路!CRAFT:一种基于空间-语义信息互补的RV融合3D检测方法
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!
论文链接:https://arxiv.org/abs/2209.06535v1
摘要
为了解决late-fusion无法充分发挥两种模态互补性的缺点,作者提出了一种proposal-level的毫米波与相机融合方法,首先为了解决毫米波角分辨率低导致的难以区分径向物体以及多径干扰造成的假阳性幽灵点的问题,对毫米波数据使用图像数据进行增强生成带有语义特征的雷达特征,随后通过图像模态的预测框转换到极坐标系中自适应地融合增强后的雷达特征,完成了spatial-contextual两个层面的融合,融合结构采用了传统的transformer的encoder结构,完美地兼容了两个模态之间的数据结构上的差异,最后作者在nuScenes数据集上达到了mAP:41.1%和NDS:52.3%,相比Baseline(CenterNet)提升了很大幅度,同时作者做了大量的实验,与camera-based、lidar-based等很多方法进行了对比,证明了融合方法的有效性。
动机&贡献
 image-20221029114758263
image-20221029114758263
如图所示,作者在八个维度上对比了目前主流的传感器,通过融合各个传感器的优势,可以在理想条件下达到一种“八边形战士”能力,实际上目前的主流融合方式仍然不能够有效融合毫米波雷达和相机,传感器本身的发展现状是一个原因,融合的方式是另一个主要的限制条件,作者基于这种假设,提出了CRAFT。
动机:
基于proposal-level的融合方法,例如MV3D\AVOD等,其假设都是建立在稠密且准确的lidar点云上,例如MV3D使用lidar的BEV map生成提议框。因此对于radar本身的缺点:
一是low accuracy即角度和径向距离分辨率较低(lidar的cm级误差和radar的m级别的误差;
二是measurement ambiguities即雷达这种电磁波存在的多种反射形式形成许多假阳性噪声。
综上使得radar不能像lidar一样考虑如何融合,而是转变成如何robust & efficient地进行融合的问题。
主要贡献:
一、Soft Polar Association,减弱proposal也就是图像质量对最终检测结果的影响:
"soft"一词,不同于以往将生成的proposal直接投影,对于毫米波点云来说,直接投影关联会导致本不属于目标的点云被错误关联,受到NIPS一篇论文(What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?)的启发,对深度的不确定性进行建模,以此进一步扩大空间关联范围,以提供proposal更多地选择。
二、Spatio-Contextual Fusion Transformer,完成模态间语义信息的对齐与融合:
soft polar association完成空间上地鲁棒性关联,但是会引入相当多的非目标反射点,同时毫米波本身并不具有较好的可供于分类的特征,为了方便毫米波与图像特征更好地对齐与融合,作者使用transformer的encoder结构对两个模态之间的语义关系进行建模,分别使用Image-to-Radar Feature Encoder和Radar-to-Image Feature Encoder增强毫米波特征和refine图像的proposal。
Method
模型结构
 image-20221029170535044
image-20221029170535044
分别使用PointNet++的SA模块和FP模块,CenterNet的backbone和head生成点云特征、图像提议(这里对于backbone等部分不做过多介绍,可以看下我的文章:centernet和一位大佬写的pointnet++),然后在极坐标系下通过作者提出的基于transformer的空间和语义融合模块完成两种特征的融合,然后送入改进的key-point based的预测头进行位置大小微调与其他属性的预测,包括预测每个proposal的fusion score, location offsets, center-ness, velocity等。
Soft Polar Association
 image-20221029171904401
image-20221029171904401
作者在极坐标系下关联image proposal和radar points,具体动机没有详细给出,我个人猜测,其本质并不是两个坐标系,而是通过xy这种相对位置更明确的坐标系,还是rθ这种深度角度信息明显的描述方式,来表示位置,为后面的关联方式服务。
细节上来说,毫米波在远处的径向距离误差较大(在50m左右能达到4m左右的误差),在径向上不具有太大的关联价值,但是在径向距离上误差小更具有关联价值。
从模态互补性来说,图像在本文作为一种主要的模态,在图像在角分辨率上的识别能力较强,但是在深度上的预测能力是一个ill-posed的问题,通过在深度上引入不确定性的估计,更能发挥图像模态的优势,并且弥补其缺点,极坐标系通过r与θ能更加直接地描述目标的深度位置。
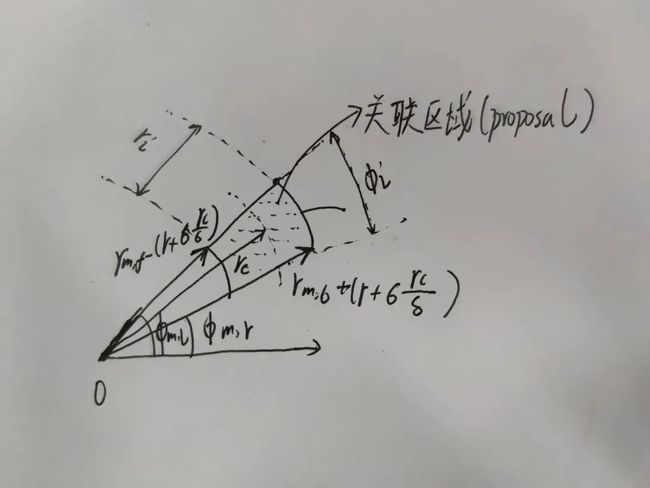
Image-to-Radar Feature Encoder:解决毫米波点云的多径干扰(measurement ambiguities)与角度分辨率误差问题(low accuracy)
这里将每个雷达点(经过pointnet++)通过transformer建模其与对应的投影特征区域(ROI)的关系,自适应地进行特征融合,减弱了毫米波雷达点的位置误差带来的差异,相比futr3d,这里的融合方式更加灵活。
 image-20221029174522993
image-20221029174522993
作者将image patches下采样到固定大小wxw,根据深度d投影的roi,在wxw的固定区域进行双线形插值提取特征,具体方法如下图,其中τ(d)是采样窗口的patch大小,里面的超参数是固定的,这里的image patches加入了2D的位置编码。
 image-20221029174921562
image-20221029174921562
Radar-to-Image Feature Encoder:对齐并融合两模态特征用于image proposals的微调
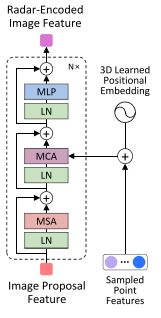 image-20221029175039552
image-20221029175039552
这里比较简单,将每个image proposal的八个角点,转换到极坐标系下,并关联对应的点云,前面的soft assiciation就是用于这里的关联过程。这里的采样毫米波特征经过了3D可学习位置编码的加入。
Head
基于cornernet的head做了一些改进,主要是参考它引入了中心度
预测的是offset用于refine一开始centernet的proposals
fusion score用于每个proposal的融合得分,用于查看每个proposal的最终得分共有多少来自radar的贡献
velocity在最后head中预测
一开始centernet的初始预测proposal不进行NMS,并为了保持较高的召回率,centernet的置信度阈值设置为0.05,在最后的head中进行NMS
由此,完成了整个模型关键部分的讲解。
实验
可视化
 image-20221029171553092
image-20221029171553092
如上图,作者可视化毫米波点云(左边红点)与image patches(右边的点)之间的注意力关系,并可视化不同层之间的注意力变化图,可以看到,随着层数加深,点云逐渐收敛到汽车中心。
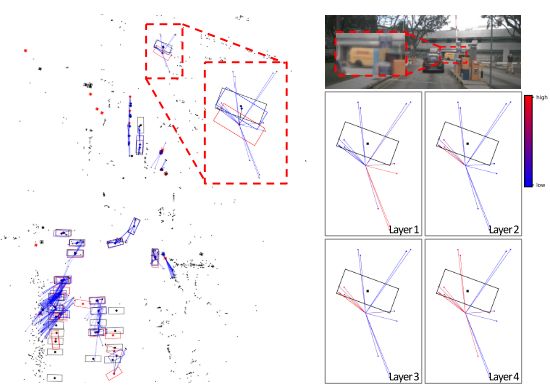 image-20221029171618040
image-20221029171618040
如上图,作者可视化了image proposals和对应的radar points之间的注意力权重,红色为centernet预测的proposal,经过radar points的修正,蓝色框为修正后的proposal,而黑色是GT,经过修正后proposal的深度得到进一步提升。另一方面,如上图右边所示,随着层数加深,image proposal的中心点逐渐从关联外部点到内部的点,能够逐渐找到对应的正确雷达点。
结果对比
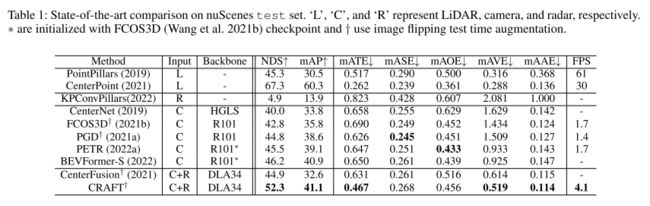 image-20221029171334255
image-20221029171334255
这是作者的实验结果,超越了主流的单模态检测方法(只对比了BEVFormer-S),但是距离lidar based的方法相差仍然不少。
这里主要对比centerfusion和CRAFT,可以看到,同样使用centernet作为baseline,CRAFT比Centerfusion提升相当大,主要体现在位置、方向和mAP中,两者不同之处在于,centerfusion对深度估计上是固定的超参数,而CRAFT采用自适应的深度估计方式,另一方面centerfusion并没有解决角分辨率误差的问题,直接使用frustum的方法关联点云,而CRAFT通过transformer渲染点云起到筛选的作用,最后,centerfusion直接将所有的点云投影到FOV并concate融合两个模态,而CRAFT采用soft association与transformer的方法更加灵活地融合两种模态,使用了可学习的融合方法。
消融实验
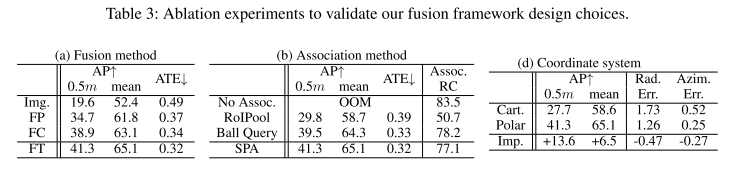 image-20221029171354468
image-20221029171354468  image-20221029182301174
image-20221029182301174
作者的自适应融合方法-FT领跑其他方法,看了这么多融合的工作,发现concatenation作为一种简单有效的方法,在你不知道如何融合的时候,永远是第一选择。
关联方法,Ball query(r < 6m)和作者的proposal-based的方法相差不大。
极坐标系在作者的方法里,有着不可替代的作用,具体原因可看上面。
距离与雷达点个数对结构影响
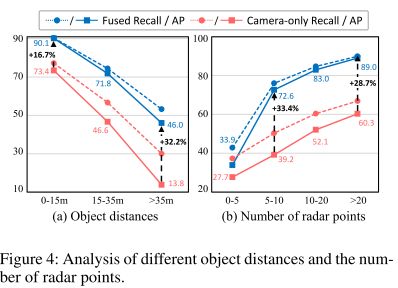 image-20221029171406984
image-20221029171406984
融合后对距离的鲁棒性有所提升,在一定范围内,proposal内部的点越多,性能一般越好。
总结
作者在一个几年前的baseline上证明了融合的有效性,并且相比前期的RV融合方法,目前是提点最多的一个,之前最好的是mAP和NDS分别是+7.3和+9.4,这里是8.7和10.8。
在效率上,与近期工作RCBEV相比,这里仅推测,前者是基于BEVDet-STTiny做改良,这里使用的是CenterNet,前者单模态下fps在3.7左右,加上引入radar的额外参数,肯定会小于3.7,但是CRAFT的full-model的fps在4.1,所以效率和性能大概上是都优于RCBEV的。相信引入更强大baseline,CRAFT会有进一步的提升。
通过消融实验,可以基本判断出,作者模型带来的主要收益,还是对应的关联方法(SPA)和极坐标系的组合带来的组合收益,对于融合问题,在笛卡尔坐标系下日益内卷的情况下,转到极坐标系下去发现一些关联方法也不失为一个新路子。
美中不足的是,源码没放出来,只能暂且相信,但是作者没有详细透露如何在笛卡尔坐标系下进行检测的方法,只是说转换到极坐标系下的方法是"s similar to applying Principal Component Analysis (PCA) since"
如果有人了解详细的转化过程,欢迎评论区讨论,也可访问我的知乎Naca yu,交流关于极坐标系的一些新方法和思路
参考
[1 ] CRAFT: Camera-Radar 3D Object Detection with Spatio-Contextual Fusion Transformer
[2 ] What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
[3] Bridging the View Disparity of Radar and Camera Features for Multi-modal Fusion 3D Object Detection
[4] Deep Ordinal Regression Network for Monocular Depth Estimation
[5] https://zhuanlan.zhihu.com/p/266324173
往期回顾
NVRadarNet:基于纯Radar的障碍物和可行驶区域检测(英伟达最新)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
