机器学习 —— 朴素贝叶斯
朴素贝叶斯
贝叶斯公式: P(A|B) = P(A) * P(B|A) / P(B)
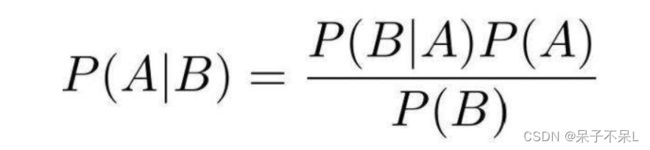
一个例子,现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,
在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,
且是红球,问这个红球是来自容器 A 的概率是多少?
假设已经抽出红球为事件 B,选中容器 A 为事件 A,则有:
P(B) = 8/20,P(A) = 1/2,P(B|A) = 7/10,
按照公式,则有:
P(A|B) = (7/10)*(1/2) / (8/20) = 0.875
例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次
,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,
P(A) = 3/7,P(B) = 2/(20*365) = 2/7300,P(A|B) = 0.9,
按照公式很容易得出结果:
P(B|A) = 0.9*(2/7300) / (3/7) = 0.00058
优点:
- 朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率;
- 对小规模的数据表现很好;
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类
缺点:
- 只能用于分类问题
- 需要计算先验概率;
一、朴素贝叶斯原理
朴素贝叶斯算法是一个典型的统计学习方法,主要理论基础就是一个贝叶斯公式,贝叶斯公式的基本定义如下:

这个公式虽然看上去简单,但它却能总结历史,预知未来:
- 公式的右边是总结历史
- 公式的左边是预知未来
如果把Y看成类别,X看成特征,P(Yk|X)就是在已知特征X的情况下求Yk类别的概率,而对P(Yk|X)的计算又全部转化到类别Yk的特征分布上来。
举个例子,大学的时候,某男生经常去图书室晚自习,发现他喜欢的那个女生也常去那个自习室,心中窃喜,于是每天买点好吃的在那个自习室蹲点等她来,可是人家女生不一定每天都来,眼看天气渐渐炎热,图书馆又不开空调,如果那个女生没有去自修室,该男生也就不去,每次男生鼓足勇气说:“嘿,你明天还来不?”,“啊,不知道,看情况”。
然后该男生每天就把她去自习室与否以及一些其他情况做一下记录,用Y表示该女生是否去自习室,即Y={去,不去},X是跟去自修室有关联的一系列条件,比如当天上了哪门主课,蹲点统计了一段时间后,该男生打算今天不再蹲点,而是先预测一下她会不会去,现在已经知道了今天上了常微分方程(Y=去|常微分方程)与P(Y=不去|常微分方程),看哪个概率大,如果P(Y=去|常微分方程) >P(Y=不去|常微分方程),那这个男生不管多热都屁颠屁颠去自习室了,否则不就去自习室受罪了。P(Y=去|常微分方程)的计算可以转为计算以前她去的情况下,那天主课是常微分的概率P(常微分方程|Y=去),注意公式右边的分母对每个类别(去/不去)都是一样的,所以计算的时候忽略掉分母,这样虽然得到的概率值已经不再是0~1之间,但是通过比较大小还是能选择类别。
后来他发现还有一些其他条件可以挖,比如当天星期几、当天的天气,以及上一次与她在自修室的气氛,统计了一段时间后,该男子一计算,发现不好算了,因为总结历史的公式:
 这里n=4,x(1)表示主课,x(2)表示天气,x(3)表示星期几,x(4)表示气氛,Y仍然是{去,不去},现在主课有8门,天气有晴、雨、阴三种、气氛有A+,A,B+,B,C五种,那么总共需要估计的参数有8×3×7×5×2=1680个,每天只能收集到一条数据,那么等凑齐1680条数据,大学都毕业了,男生大呼不妙,于是做了一个独立性假设,假设这些影响她去自习室的原因是独立互不相关的,于是:
这里n=4,x(1)表示主课,x(2)表示天气,x(3)表示星期几,x(4)表示气氛,Y仍然是{去,不去},现在主课有8门,天气有晴、雨、阴三种、气氛有A+,A,B+,B,C五种,那么总共需要估计的参数有8×3×7×5×2=1680个,每天只能收集到一条数据,那么等凑齐1680条数据,大学都毕业了,男生大呼不妙,于是做了一个独立性假设,假设这些影响她去自习室的原因是独立互不相关的,于是:
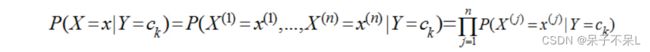 有了这个独立假设后,需要估计的参数就变为,(8+3+7+5)×2 = 46个了,而且每天收集的一条数据,可以提供4个参数,这样该男生就预测越来越准了。
有了这个独立假设后,需要估计的参数就变为,(8+3+7+5)×2 = 46个了,而且每天收集的一条数据,可以提供4个参数,这样该男生就预测越来越准了。
朴素的概念:独立性假设,假设各个特征之间是独立不相关的。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
data,target = load_iris(return_X_y=True)
pd.DataFrame(data).head()
朴素贝叶斯分类器
讲了上面的小故事,我们来朴素贝叶斯分类器的表示形式:
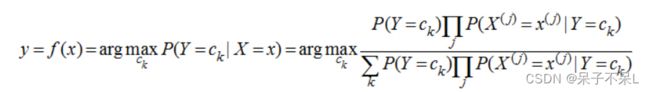
当特征为为x时,计算所有类别的条件概率,选取条件概率最大的类别作为待分类的类别。由于上公式的分母对每个类别都是一样的,因此计算时可以不考虑分母,即

朴素贝叶斯的朴素体现在其对各个条件的独立性假设上,加上独立假设后,大大减少了参数假设空间。
在文本分类上的应用
文本分类的应用很多,比如垃圾邮件和垃圾短信的过滤就是一个2分类问题,新闻分类、文本情感分析等都可以看成是文本分类问题,分类问题由两步组成:训练和预测,要建立一个分类模型,至少需要有一个训练数据集。贝叶斯模型可以很自然地应用到文本分类上:现在有一篇文档d(Document),判断它属于哪个类别ck,只需要计算文档d属于哪一个类别的概率最大:

在分类问题中,我们并不是把所有的特征都用上,对一篇文档d,我们只用其中的部分特征词项t1,t2,...,tnd(nd表示d中的总词条数目),因为很多词项对分类是没有价值的,比如一些停用词“的,是,在”在每个类别中都会出现,这个词项还会模糊分类的决策面,关于特征词的选取,我的这篇文章有介绍。用特征词项表示文档后,计算文档d的类别转化为:

注意P(Ck|d)只是正比于后面那部分公式,完整的计算还有一个分母,但我们前面讨论了,对每个类别而已分母都是一样的,于是在我们只需要计算分子就能够进行分类了。实际的计算过程中,多个概率值P(tj|ck)的连乘很容易下溢出为0,因此转化为对数计算,连乘就变成了累加:
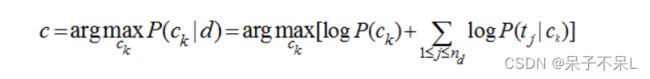
我们只需要从训练数据集中,计算 每一个类别的出现概率P(ck) 和 **每一个类别中各个特征词项的概率P(tj|ck)**, 而这些概率值的计算都采用最大似然估计,
说到底就是统计每个词在各个类别中出现的次数和各个类别的文档的数目:

# 每一个类别的出现概率P(ck) 和 每一个类别中各个特征词项的概率P(tj|ck)
# 每一个类别的出现概率P(ck)
# Nck : 在训练集中,每个类别的数量
# N; 类别的总数量
# 每一个类别中各个特征词项的概率P(tj|ck)
# Tjk : 每个特征词项数量
# ETjk: 所有特征词项的总数二、3种贝叶斯模型
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# naive_bayes: 朴素贝叶斯
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB1、高斯分布朴素贝叶斯
- 高斯分布就是正态分布
- 【用途】用于一般分类问题
- 一般处理连续的特征值,会对每个特征都做高斯分布的假设
使用自带的鸢尾花数据
data,target = load_iris(return_X_y=True)
target
'''
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
'''
# 去两列数据,方便画图
data2 = data[:,2:].copy()使用高斯分布贝叶斯模型
gs_nb = GaussianNB()
gs_nb.fit(data2,target)
gs_nb.score(data2,target)
# 0.96画边界图
def get_XY(data):
x = np.linspace(data[:,0].min(),data[:,0].max(),1000)
y = np.linspace(data[:,1].min(),data[:,1].max(),1000)
X, Y = np.meshgrid(x,y)
XY = np.c_[X.ravel(),Y.ravel()]
return X,Y,XY
X,Y,XY = get_XY(data2)
# 预测
y_pred = gs_nb.predict(XY)
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')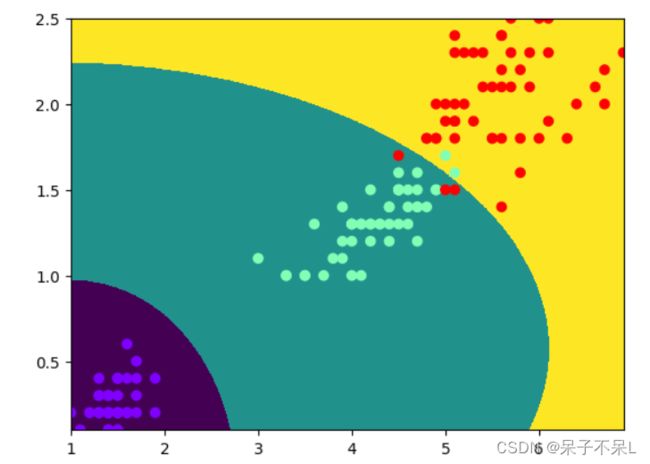
2、多项式分布朴素贝叶斯
- 【用途】适用于文本数据(特征表示的是次数,例如某个词语的出现次数)
- 当特征值是离散时,可以使用多项式分布
例:延续上面,使用鸢尾花数据
mu_nb = MultinomialNB()
mu_nb.fit(data2,target)
mu_nb.score(data2,target)
# 0.7933333333333333
# 预测
y_pred = mu_nb.predict(XY)
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')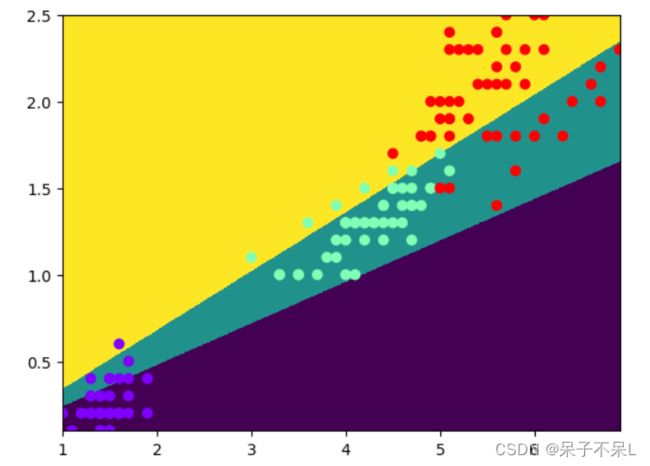
3、伯努利分布朴素贝叶斯
- 当特征值是离散时,可以使用多项式分布
- 【用途】适用于伯努利分布,也适用于文本数据(此时特征表示的是是否出现,例如某个词语的出现为1,不出现为0)
- 绝大多数情况下表现不如多项式分布,但有的时候伯努利分布表现得要比多项式分布要好,尤其是对于小数量级的文本数据
- 和多项式分布差不多的,主要区别是伯努利是二分类
- 主要处理离散型数据。
例:继续使用鸢尾花数据集
be_nb = BernoulliNB()
be_nb.fit(data2,target)
be_nb.score(data2,target)
# 0.3333333333333333
y_pred = be_nb.predict(XY)
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')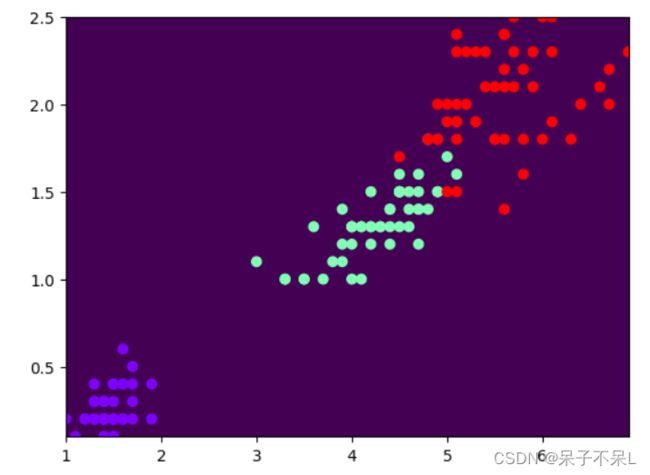
三、文本分类实战
对短信进行二分类,数据为SMSSpamCollection
# 判断短信是否为垃圾短信
# ham:正常短信
# spam:垃圾短信
sms = pd.read_table('../data/SMSSpamCollection',header=None)
sms.head()
sms.shape
# (5572, 2)
# target
target = sms[0].copy()
target.unique()
# array(['ham', 'spam'], dtype=object)
# data
data = sms[1].copy()
data[0]
# 'Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...'提取特征
导入 sklearn.feature_extraction.text.TfidfVectorizer 用于转换字符串
# feature_extraction :特征提取
# TfidfVectorizer : 特征词向量化
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer()
tf.fit(data)tf.fit(data) :训练
tf.transform(data)
- 参数必须是字符串的一维数组(比如列表或者Series)
- 返回的是一个稀疏矩阵类型的对象,行数为样本数,列数为所有出现的单词统计个数。
toarray()
- 得到数组
# transform : 转换 稀疏矩阵 sparse matrix
# tf.transform(data)
'''
<5572x8713 sparse matrix of type ''
with 74169 stored elements in Compressed Sparse Row format>
'''
tf_data = tf.transform(data).toarray()
tf_data
'''
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
'''
tf_data.sum()
# 18225.670694974182
tf_data.shape
# (5572, 8713) 高斯分布贝叶斯
gs_nb = GaussianNB()
gs_nb.fit(tf_data,target)
gs_nb.score(tf_data,target)
# 0.9414931801866475多项式分布贝叶斯
mu_nb = MultinomialNB()
mu_nb.fit(tf_data,target)
mu_nb.score(tf_data,target)
# 0.9761306532663316伯努利分布贝叶斯
be_nb = BernoulliNB()
be_nb.fit(tf_data,target)
be_nb.score(tf_data,target)
# 0.9881550610193827预测数据,使用tf.transform(['xx'])进行转换生成测试数据
# 提供几条短信
msg = [
"hello world how are you",
"Free lunch, pleace call 08002986030 £5 9am-11pm as a £1000 or £5000 prize",
"qianfeng encoding utf8",
"Please call our on 0808 145 4742 9am-11pm as a £1000 or £5000 prize!"
]
# 不能重新训练
# tf2 = TfidfVectorizer()
# tf2.fit(msg)
# tf2.transform(msg)
'''
<4x26 sparse matrix of type ''
with 34 stored elements in Compressed Sparse Row format>
'''
# 要使用之前训练好的 tf 对象
tf_data2 = tf.transform(msg).toarray()
tf_data2
'''
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
'''
# 高斯分布贝叶斯
gs_nb.predict(tf_data2)
# array(['spam', 'spam', 'spam', 'spam'], dtype='