BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Trans
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers论文笔记
原文链接:https://arxiv.org/pdf/2203.17270.pdf
1.引言
视觉感知是利用多个摄像机提供的图像来给出3D边界框或语义图。最直接的方法是基于单目框架和跨相机后处理。但这种方法单独处理每个视图,而不能捕捉跨相机的信息,导致性能和效率都很低。
另一框架是从多相机图像中提取整体表达。鸟瞰图(BEV)是一种合适的表达,但基于BEV的方法与其余3D检测方法相比没有明显优势。生成BEV的流行框架是基于深度估计,但误差较大,导致最终性能较差。
此外,现有的多相机3D检测方法很少关注时间信息,因为自动驾驶对算法时间要求很高,且物体在场景中变化迅速,引入多帧数据会带来额外的计算量。但时间信息对于估计物体运动状态、确定被遮挡物体而言很重要。
因此本文提出BEVFormer(如下图所示),从多相机图像和历史BEV特征中聚合时空信息,生成BEV特征。包含3个部分:BEV查询,空间注意力和时间注意力。
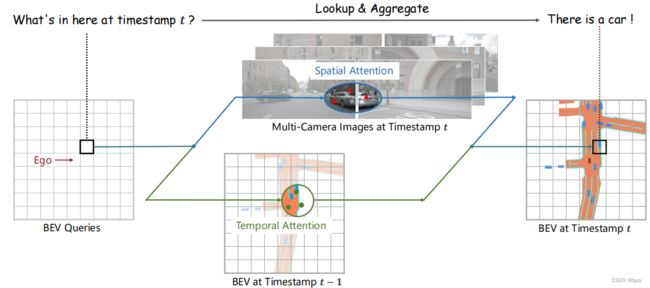
3.BEVFormer
3.1 整体结构
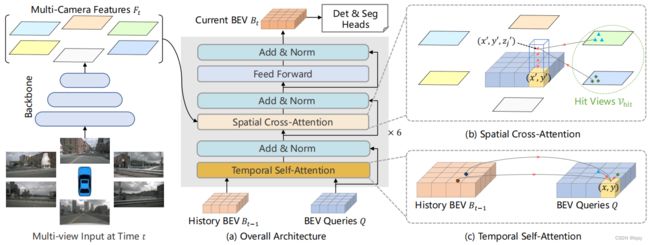
如上图所示,BEVFormer大体结构和传统的Transformer类似。BEV查询是网格化可学习参数,通过注意力机制从多相机视图中查询BEV特征;空间注意力中,每个BEV查询仅与感兴趣区中的图像特征交互。
3.2 BEV查询
预定义可学习参数![]() 作为查询,其中
作为查询,其中![]() 是BEV平面的长和宽。
是BEV平面的长和宽。![]() 是位于
是位于![]() 处的一个查询。
处的一个查询。
默认BEV平面的中心是自车位置。
在输入到BEVFormer前,向 中加入了可学习的位置嵌入。
中加入了可学习的位置嵌入。
3.3 空间交叉注意力
普通的多头自注意力的计算复杂度很高,考虑使用可变形注意力(deformable attention)。
其中
分别为参考点和输入特征,
为注意力头的数量,
是每个头采样key的数量。
是特征维度。
是预测的注意力权重,被归一化为
是相对参考点的预测偏移;
是位置
处的特征,通过双线性插值得到。
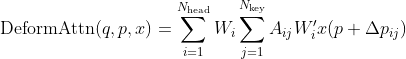
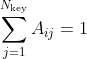
如图2(b)所示,首先将BEV平面的每个查询提升为柱状查询,并从其中采样![]() 个3D参考点,然后将这些点投影到2D视图。对一个查询而言,可能只有部分视图有投影点,这些视图集合为
个3D参考点,然后将这些点投影到2D视图。对一个查询而言,可能只有部分视图有投影点,这些视图集合为![]() 。将这些2D点视为
。将这些2D点视为![]() 的参考点,并从
的参考点,并从![]() 中的这些参考点附近采样特征。最后使用这些采样特征的加权求和作为空间交叉注意力(SCA)的输出,即:
中的这些参考点附近采样特征。最后使用这些采样特征的加权求和作为空间交叉注意力(SCA)的输出,即:
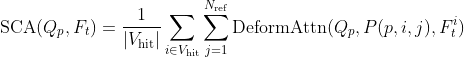
其中![]() 是当前时刻第
是当前时刻第 个相机视图的特征;
个相机视图的特征;![]() 为投影函数,得到
为投影函数,得到![]() 在视图上产生的第
在视图上产生的第 个参考点。
个参考点。
如何用投影函数 得到参考点:首先使用下式计算BEV平面
得到参考点:首先使用下式计算BEV平面![]() 处的真实坐标
处的真实坐标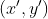 (以自车位置为原点):
(以自车位置为原点):
![]()
其中 是BEV网格的分辨率。
是BEV网格的分辨率。
由于BEV无高度信息,故在采样时需要预定义锚定高度![]() 。故3D参考点为
。故3D参考点为![]() 。
。
投影函数满足![P(p,i,j)=(x_{ij},y_{ij}),z_{ij}[x_{ij},y_{ij},1]^T=T_i[{x}',{y}',{z}'_j,1]^T](http://img.e-com-net.com/image/info8/cf8716533d6d4431a66394de1bfac4a6.gif) ,其中
,其中 是第个摄像机的投影矩阵。
是第个摄像机的投影矩阵。
3.4 时间自注意力
首先将当前时刻的查询与历史BEV特征![]() 对齐,使得对齐的网格对应真实世界中相同位置。将对齐后的历史BEV特征记为
对齐,使得对齐的网格对应真实世界中相同位置。将对齐后的历史BEV特征记为![]() 。使用时间自注意力(TSA)进行时间交互:
。使用时间自注意力(TSA)进行时间交互:
![]()
与普通的可变形注意力不同,时间自注意力中的偏移 由和
由和![]() 的拼接进行预测。
的拼接进行预测。
特别地,对于第一帧,使用![]() 替代
替代![]() 。
。
3.6 实施细节
训练:对每个时间点 ,随机采样2s以内的3帧数据,记为
,随机采样2s以内的3帧数据,记为![]() 。依次产生
。依次产生![]() (此过程无需梯度;对于
(此过程无需梯度;对于![]() ,由于无过去BEV特征,时间自注意力退化为自注意力)。最后根据
,由于无过去BEV特征,时间自注意力退化为自注意力)。最后根据![]() 生成
生成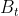 ,然后送入head中计算损失函数。
,然后送入head中计算损失函数。
推断:按照严格时间顺序,使用上一帧的BEV特征用于当前帧BEV特征的生成。
4 实验
4.3 3D目标检测结果
引入时间信息使得BEVFormer的速度估计更加精确,甚至接近基于激光雷达的方法。
4.4 多任务感知结果
多任务联合训练通过共享主干和BEV编码器模块,节省了计算和时间。甚至某些任务(目标检测、车辆分割)的联合训练会比单独训练有更好的性能。但道路检测等任务的性能会有下降,这是联合训练中的常见现象,被称为负迁移(negative transfer)。
4.5 消融研究
空间交叉注意力的影响:与全局注意力以及仅与参考点交互的注意力机制(对应模型称为BEVFormer (point))相比,使用可变形注意力与参考点附近的特征进行交互有更好的性能,且平衡了感受野和性能。
时间自注意力的影响:与不含时间自注意力的模型(称为BEVFormer-S)相比,含有时间自注意力的模型在速度估计、位置和朝向估计上有更高的精度,且对严重遮挡物体的检测有更高的召回率。
模型尺度和延迟:可以通过调节模型层数、BEV查询的尺度以及是否使用多尺度特征,来灵活地平衡模型复杂度和精度。
附录
A.实施细节
A.3 任务头
检测头:预测10个边界框参数,包含3维坐标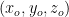 和尺寸
和尺寸![]() 、2维速度
、2维速度![]() 以及朝向角的正余弦对
以及朝向角的正余弦对![]() 。使用
。使用![]() 损失。推断时仅使用前300个置信度最高的检测结果。
损失。推断时仅使用前300个置信度最高的检测结果。
分割头:如下图所示。对于每一类,类似掩膜解码器(mask decoder),使用一个查询来代表该类,基于多头注意力模块生成的注意力图生成最终的分割掩膜。
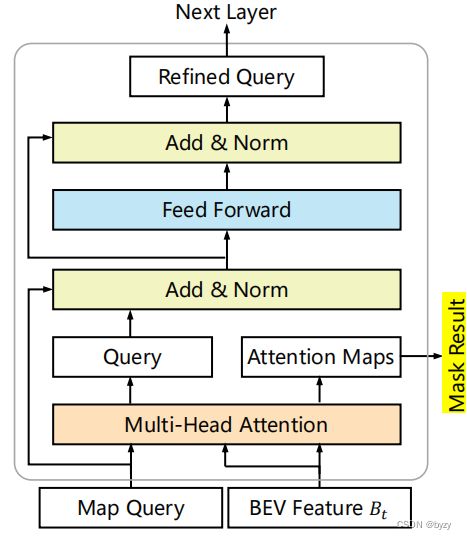
A.4 空间交叉注意力
全局注意力:本文的可变形卷积可以使用全局注意力进行替换,包含与所有视图均进行交互的全局注意力,以及使用相机内外参、仅与可视视图交互的注意力。前者比后者对相机的内外参更鲁棒(因其不依赖相机内外参),但计算复杂度不可接受。
B.对相机外参的鲁棒性
BEVFormer依赖相机内外参确定可变形注意力中的参考点。实施时,相机的外参可能由于校正误差和相机偏移而存在误差。实验表明,BEVFormer-S (point)对相机外参噪声的鲁棒性低于BEVFormer-S,而后者又低于BEVFormer,这说明时间信息的引入能提高对相机外参的鲁棒性。
若使用带噪声的外参进行训练,则在测试时对外参的鲁棒性会更强。
C.消融研究
还研究了训练时帧数的影响(性能随帧数增加先增加后趋于饱和)。
此外,将历史帧的BEV特征对齐到当前自车姿态对表达与当前BEV查询相同的几何场景是很重要的;随机在连续帧中采样若干帧是提高性能有效的数据增广策略;在时间自注意力模块中同时使用BEV查询和历史BEV特征能促进位置预测。