医学图像语义分割--Unet
自从FCN打开了图像语义分割的新世界大门,各种优秀的分割算法迅速发展。在医学图像方面Unet展现出了期强大的性能,是小规模数据集的医学图像也能分割出较好的效果。
论文地址 http://www.arxiv.org/pdf/1505.04597.pdf
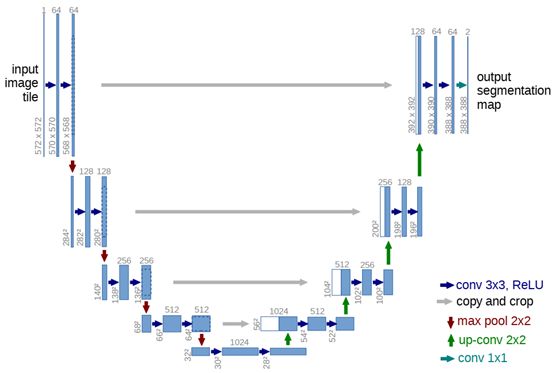
在FCN的基础上,Unet修改并扩大了这个网络框架,使其能够使用很少的训练图像就得到很 精确的分割结果。添加上采样阶段,并且添加了很多的特征通道,允许更多的原图像纹理的信息在高分辨率的layers中进行传播。U-net去掉FC层,且全程使用valid来进行卷积,这样的话可以保证分割的结果都是基于没有缺失的上下文特征得到的,因此输入输出的图像尺寸不太一样(但是在keras上代码做的都是same convolution),对于图像很大的输入,可以使用overlap-strategy来进行无缝的图像输出。细胞分割的另外一个难点在于将相同类别且互相接触的细胞分开,因此作者提出了weighted loss,也就是赋予相互接触的两个细胞之间的background标签更高的权重。trnsorflow2.0代码谁先如下。数据集下载,下载后,在项目中创建dataset目录,里面再分别创建train和test,train和test中在创建images和labels,放好图片即可。
模型 model.py
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Conv2D, Input, MaxPooling2D, Dropout, concatenate, UpSampling2D
def Unet(num_class, image_size):
inputs = Input(shape=[image_size, image_size, 1])
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same')(inputs)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same')(pool1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same')(pool2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same')(UpSampling2D(size = (2,2))(drop5))
merge6 = concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same')(UpSampling2D(size = (2,2))(conv6))
merge7 = concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same')(UpSampling2D(size = (2,2))(conv7))
merge8 = concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same')(UpSampling2D(size = (2,2))(conv8))
merge9 = concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same')(conv9)
conv10 = Conv2D(num_class, 1, activation = 'sigmoid')(conv9)
model = Model(inputs = inputs, outputs = conv10)
#这里的lr根据自己的数据集调整,选取不当容易导致预测结果全黑的情况
model.compile(optimizer = Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy'])
return model
train.py代码
import os
import cv2
import numpy as np
from Unet import Unet
os.environ["CUDA_VISIBLE_DEVICES"]="-1"#禁用GPU
from tensorflow.keras.preprocessing.image import ImageDataGenerator
def DataGenerator(file_path, batch_size):
"""
generate image and mask at the same time
use the same seed for image_datagen and mask_datagen
to ensure the transformation for image and mask is the same
"""
aug_dict = dict(rotation_range=0.2,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
horizontal_flip=True,
fill_mode='nearest')
aug_dict = dict(horizontal_flip=True,
fill_mode='nearest')
image_datagen = ImageDataGenerator(**aug_dict)
mask_datagen = ImageDataGenerator(**aug_dict)
image_generator = image_datagen.flow_from_directory(
file_path,
classes=["images"],
color_mode = "grayscale",
target_size = (256, 256),
class_mode = None,
batch_size = batch_size, seed=1)
mask_generator = mask_datagen.flow_from_directory(
file_path,
classes=["labels"],
color_mode = "grayscale",
target_size = (256, 256),
class_mode = None,
batch_size = batch_size, seed=1)
train_generator = zip(image_generator, mask_generator)
for (img,mask) in train_generator:
img = img / 255.
mask = mask / 255.
mask[mask > 0.5] = 1
mask[mask <= 0.5] = 0
yield (img,mask)
model = Unet(1, image_size=256)
trainset = DataGenerator("dataset/train", batch_size=2)
model.fit_generator(trainset,steps_per_epoch=180,epochs=1)
model.save_weights("model.h5")
testSet = DataGenerator("dataset/test", batch_size=1)
alpha = 0.3
model.load_weights("model.h5")
if not os.path.exists("./results"): os.mkdir("./results")
for idx, (img, mask) in enumerate(testSet):
oring_img = img[0]
#开始用模型进行预测
pred_mask = model.predict(img)[0]
pred_mask[pred_mask > 0.5] = 1
pred_mask[pred_mask <= 0.5] = 0
#如果这里展示的预测结果一片黑,请调整lr,同时注意图片的深度是否为8
cv2.imshow('pred_mask', pred_mask)
cv2.waitKey()
img = cv2.cvtColor(img[0], cv2.COLOR_GRAY2RGB)
H, W, C = img.shape
for i in range(H):
for j in range(W):
if pred_mask[i][j][0] <= 0.5:
img[i][j] = (1-alpha)*img[i][j]*255 + alpha*np.array([0, 0, 255])
else:
img[i][j] = img[i][j]*255
image_accuracy = np.mean(mask == pred_mask)
image_path = "./results/pred_"+str(idx)+".png"
print("=> accuracy: %.4f, saving %s" %(image_accuracy, image_path))
cv2.imwrite(image_path, img)
cv2.imwrite("./results/origin_%d.png" %idx, oring_img*255)
if idx == 29: break