目标检测--YOLO
YOLO v1
1. 论文思想:
1.1 将一幅图像分成S*S个网格,如果某个object的中心落在这个网格中,则这个网格就负责预测这个object
1.2 每个网格要预测B个bounding box,每个bounding box处理要预测位置之外,还要附带一个confidence值, 和C个类别的分数,共三十个参数
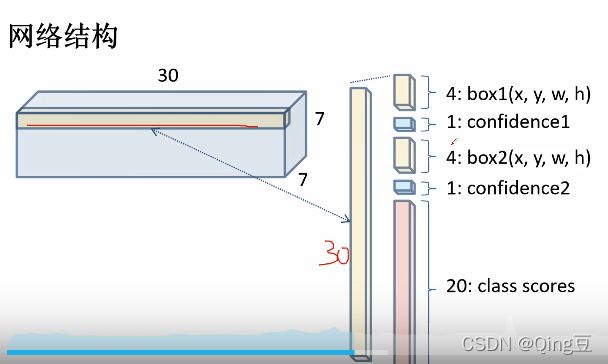
tips:confidence值![]()
Pr(Object)值为0或1,为0时表示网格中不存在目标,为1时表示网格中存在目标
测试时:
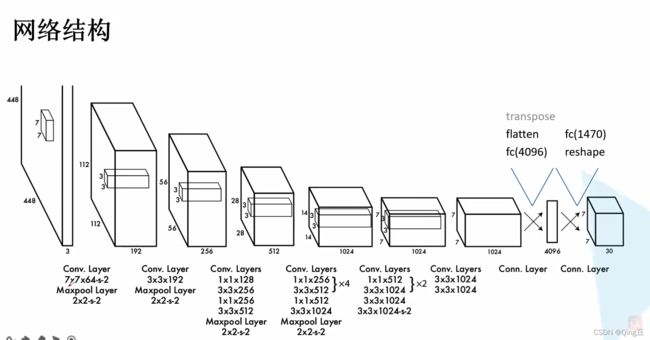
 网络结构:
网络结构:
2. 损失函数
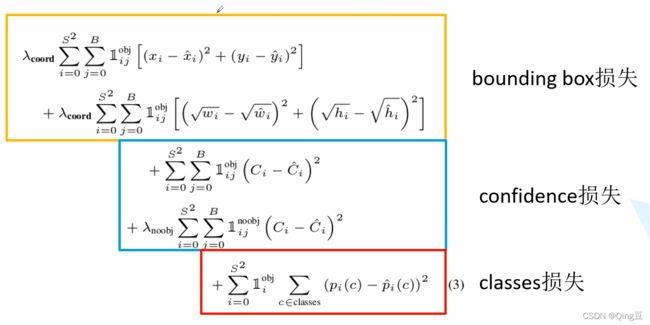
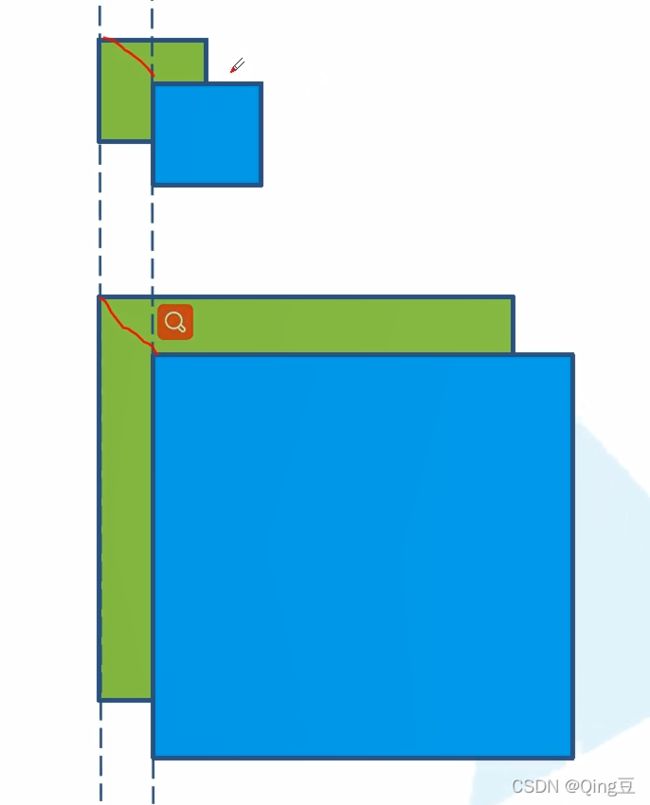
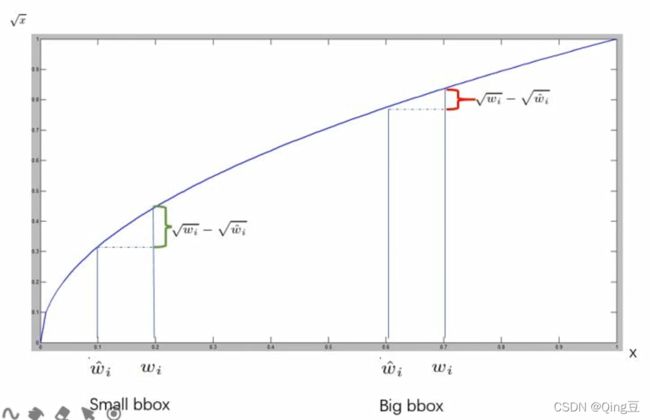
2.1 Q:为什么边界框损失中宽高的计算使用开方?
因为在预测边界框时,对于大目标和小目标来说,调整相同的宽高,其IoU是不同的,相同调整下,小目标的IoU改变小,大目标的IoU改变大,为了抑制这种现象,使用y=x^(1/2),即相同的Δx,x越大,Δy越小。
idea:类似的凸函数应该有会这种效果。
2.2 confidence损失中,前一部分是正样本损失,其真实值 为1,后一部分为负样本损失为0。
为1,后一部分为负样本损失为0。
3.YOLO v1的缺陷
3.1 对于群体小目标的检测效果很差,因为对于每个网格只预测两个bounding box并且只能有一个类。??
3.2 对于出现新的尺寸和配置时,效果很差。
3.3 定位不准确
YOLO v2
1. YOLOv2又称YOLO9000,因为在论文中给,作者使用YOLOv2最终检测的目标类别数超过9000
backbone为Darknet-19(19个卷积层)
2. 各种模型的FPS(每秒处理的帧数)和mAP比较

3.YOLOv2中的一系列尝试
3.1 BN
BN在mAP上提升了两个点,且去掉dropout之后也不会发生过拟合,也不需要其它的正则化。
3.2 更高分辨率的分类器
YOLOv1使用224 * 224的分类器,YOLOv2使用448 * 448的分类器,在mAP上有4个百分点的提升。
3.3 使用锚框
mAP有一点点下降,但是召回率提升了7个百分点。
3.4 尺度聚类(Dimension Clusters)
问题:YOLO中锚框的尺度是人为设定,虽然网络能够学习适应锚框的大小,如果能够在一开始就选择更好的锚框尺度,那在预测时会变得更加容易。
解决:不像之前手动设定锚框尺度,在训练集上使用K-聚类来自动生成锚框。
3.5 Direct location prediction
问题:Fast-RCNN中锚框不稳定,在调整时可能出现中心点A的锚框调整至距离很远的中心点B附近的区域。
解决:调整锚框时,候选框始终不能离开指定网格范围。即每个anchor负责预测目标中心落在某个grid cell 区域内的目标。
3.6 更多细节的特征
目的:为了更好的检测到小目标
Faster R-CNN和SSD都通过不同尺度的候选框来得到不同范围分辨率的特征
解决:使用passthrough layer 层将高分辨率的特征和低分辨率特征进行通道尺度上的融合
操作:
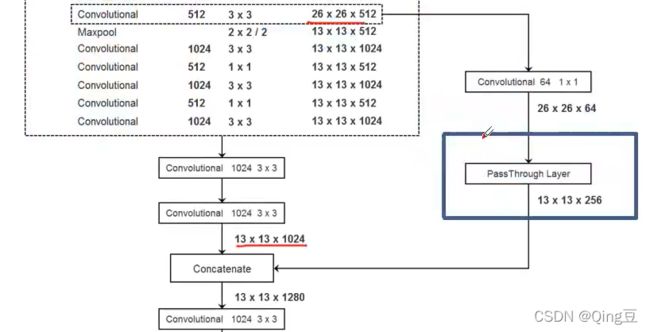
PassThrough Layer在整个网络中的位置
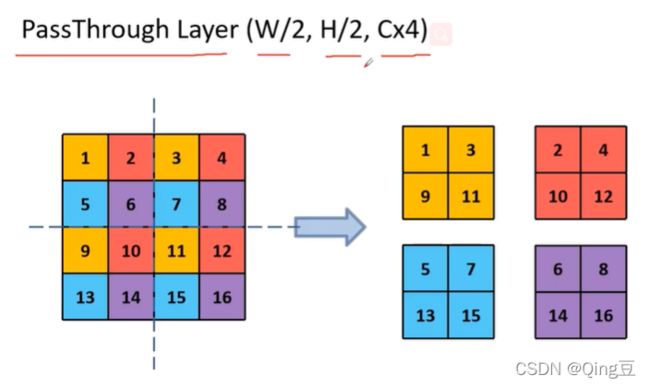
What does PassThrough Layer do?
将26 *26 * 64 的特征进行四等分,变为13 *13 * 256 的特征,分辨率缩小一般,通道数变为4倍,然后与13 *13 *1024 的特征的通道数叠加起来变为13 * 13 * 1280的特征
Q:26 * 26 * 64特征分割后的特征的位置信息和经过卷积的13 * 13 * 1024 特征的位置信息不同,为什么能够直接叠加通道?
是否类似于特征金字塔的思想?经过卷积的特征负责大目标的检测,经过分割的特征负责小目标的检测.
效果:表现提升了一个百分点
3.7 多尺度训练
目标:提升模型的鲁棒性

在训练时每迭代十个batches,随机改变一次输入图像的大小,图像的尺寸都是缩放因子的整数倍,缩放因子由最初的输入尺寸比上最终的输出尺寸得到。
Q:在网络结构不变的情况下,且符合缩放因子的输入尺寸改变怎么得到固定的输出尺寸?
4. YOLOv2模型框架(以DarkNet19作为BackBone)
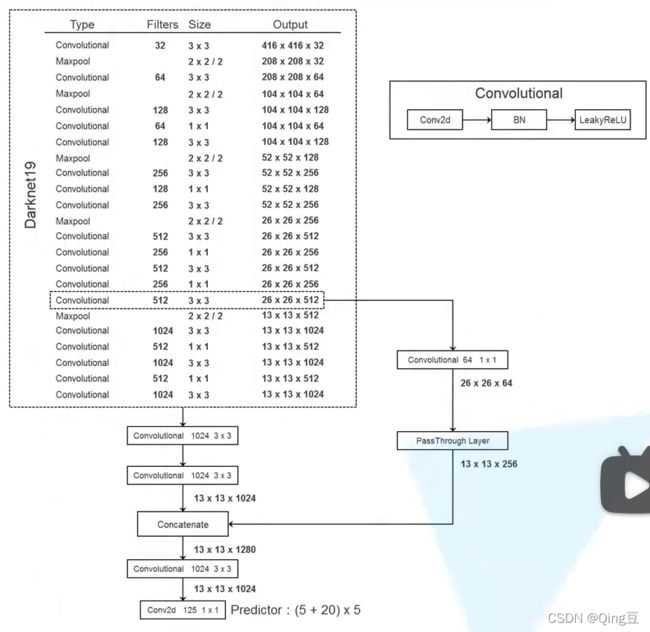
Convolutional层包含了Conv2d-> BN -> LeakyReLU 三层,在最后的Conv2d就是简单的卷积预测器(???卷积怎么预测)
DarkNet-19网络结构
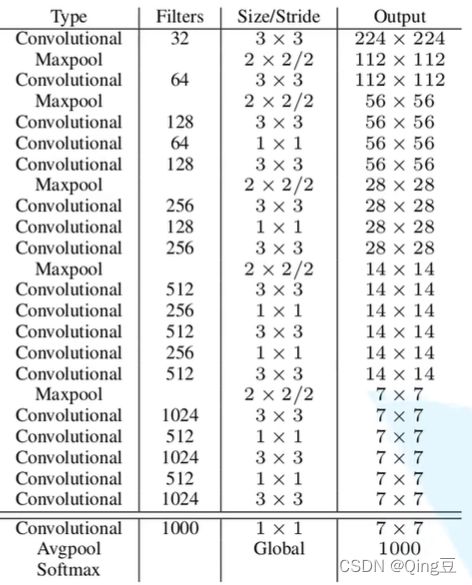
YOLOv2的改变:移除了最后的卷积层即1 * 1 * 1000的卷积层及其后的Avgpool和Softmax层,然后添加三个1024 * 3 * 3的卷积层,在接上一个1 * 1的卷积层,输出的个数就是所需检测的参数个数(125)
最后检测的参数个数为每个Bounding box(对于VOC每个目标共5个bounding box)的位置信息参数(4个参数,x,y,w,h,confidence)个数加上类别概率分数个数(20个类别)。总共 (5 + 20)* 5 = 125
Passthrough Layer来自最后一个3 * 3 * 512 的卷积层,融合到最后一个1024 * 1 *1 的卷积层