【目标检测】DetectoRS算法学习笔记

目标检测领域有个较新的方向:基于关键点进行目标物体检测。该策略的代表算法为:CornerNet和CenterNet
相关论文1
相关论文2
空洞卷积基础知识
空洞卷积引入了一个称为 “ 扩张率(dilation rate)”的超参数(hyper-parameter),该参数定义了卷积核处理数据时各值的间距。保证在卷积过程中,能够不通过下采样而增加感受野,经常被用在图像分割领域当中。
空洞卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于空洞卷积具有更大的感受野。
潜在问题 1:The Gridding Effect
潜在问题 2:Long-ranged information might be not relevant.

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7。
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。
Abstract
论文设计了一种新的Backbone网络,提出了递归特征金字塔,它将来自特征金字塔网络的额外反馈连接合并到自下而上的主网层中。在微观层面上,我们提出了可切换的空洞卷积,它以不同的扩张速率转换特征,并使用开关函数收集结果。结合它们可以得到DetectoRS,显著提高了目标检测的性能。在COCO测试测试中,DetectoRS实现了最先进的55.7%的Box AP, 48.5%的掩Mask AP以及 50.0%的PQ。
DetectoRS = HTC+RFP+SAC
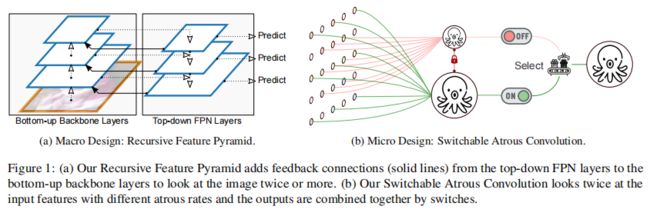
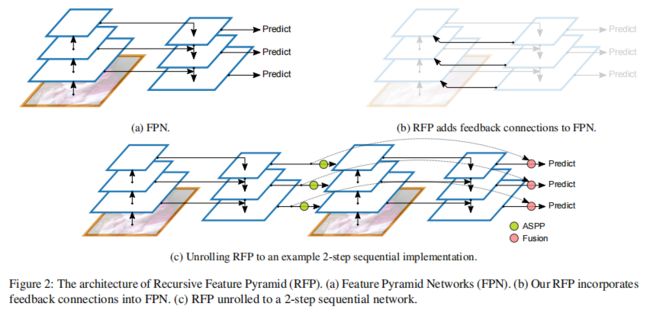
1、RFP
通过将FPN的输出,进一步反馈给主干网络,实现looking and thinking twice的目的,具体过程如下:
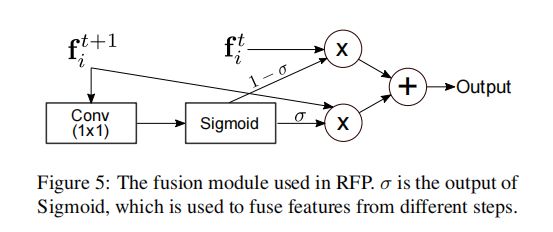
1、将RFP的输出 f i 1 f_{i}^{1} fi1反馈进同层骨干网络,得到 f i 2 f_{i}^{2} fi2,然后利用ASPP模块对 f i 1 f_{i}^{1} fi1进行转换,得到 R i R_{i} Ri,再反馈到骨干网络中;
2、最后将 f i 1 f_{i}^{1} fi1与 f i 2 f_{i}^{2} fi2利用 Fusion模块 融合,得到最终的特征图;

为了方便RFP反馈的特征信息作为backbone中stage的输入,论文中对ResNet进行修改从而允许x与R(f)同时作为输入,ResNet通常有四个stage,每个stage包含几个相似结构的blocks,论文中只对每个stage中的第一个block进行修改:

将反馈回来的特征信息RFP Features通过一个1x1卷积再与第一个block的输出进行add操作作为最终输出。值得注意的是,该1x1卷积层的权重初始化为0,以确保加载预训练权重时,它没有任何实际效果与影响。
2、SAC
空洞卷积是扩大滤波器在卷积层中的感受野的有效技术。空洞卷积将0添加在普通的卷积中间,等效地将k×k滤波器的核大小扩大到k=k(k-1)(r-1),而不增加参数的数量或计算量。同一种不同尺度的物体可以使用相同的卷积权值、设置不同的atrous rates来粗略的检测。

SAC模块有3个主要的组成部分:两个全局上下文模块和一个SAC组件,两个上下文模块分别添加在SAC组件的前后。这里先介绍SAC组件,使用y = Conv(x, w, r)表示权重为w,atrous rates为r,输入为x,y为输出的卷积操作,下图为普通卷积到SAC组件的转换:

论文中提出了一种锁定机制,将一个重量设置为w,另一个重量设置为w+∆w,主要原因为:目标检测算法大部分都采用预训练权重作为backbone的初始化,当将普通卷积转换为SAC模块时,有更大atrous rates那一层的卷积权重就会丢失。由于不同尺度的对象可以用相同的权重以不同的atrous rates的卷积层粗略地检测,所以很自然的想到用预训练模型中的权重初始化本应丢失的那一部分权重,也就是将普通卷积核的权重复制一份给SAC中有更大atrous rates的卷积核。 论文中的实现使用w+∆w来表示本应丢失的权重,其中w来自预训练模型的权重,∆w用0初始化。当固定∆w=0时,作者观察到0.1%AP的下降。 但是当没有锁定机制,仅有Δw的情况下,就会大大降低AP。
参考文章
3、Global Context
论文中在SAC组件的前后分别插入全局上下文模块,这里的全局上下文模块与SENet的相似,但是有两个不同:
1、只有一个卷积层,没有任何其他非线性层
2、全局上下文模块的输出是与主干路径相加,而不是经过sigmoid之后再相乘
4、Experiments

5、ASSP模块
在这个模块中有四个分支,其中三个分支为卷积层+ReLU,每个卷积层的输出通道都为input的1/4,最后一个分支是全局平均池化+1x1卷积层+ReLU,最后将其resize再与其他三个分支的输出进行concat操作。其中三个卷积分支的配置为:kernel_size[1,3,3],atrous rate[1,3,6],padding[0,3,6]。
#without bn version
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
self.mean = nn.AdaptiveAvgPool2d((1, 1)) #(1,1)means ouput_dim
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net
SENet
import torch.nn as nn
import torch
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# bxcx1x1 == bxc
y = self.avg_pool(x).view(b, c)
# bxcx1x1
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
input = torch.randn(2,224,224,224)
model = SELayer(224)
print(model)
output = model(input)
print(output.shape)
CBAM

class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)

class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
Global Context
import torch
from mmcv.cnn import constant_init, kaiming_init
from torch import nn
def last_zero_init(m):
if isinstance(m, nn.Sequential):
constant_init(m[-1], val=0)
else:
constant_init(m, val=0)
class ContextBlock(nn.Module):
def __init__(self,
inplanes,
ratio,
pooling_type='att',
fusion_types=('channel_add', )):
super(ContextBlock, self).__init__()
assert pooling_type in ['avg', 'att']
assert isinstance(fusion_types, (list, tuple))
valid_fusion_types = ['channel_add', 'channel_mul']
assert all([f in valid_fusion_types for f in fusion_types])
assert len(fusion_types) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.ratio = ratio
self.planes = int(inplanes * ratio)
self.pooling_type = pooling_type
self.fusion_types = fusion_types
if pooling_type == 'att':
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_add_conv = None
if 'channel_mul' in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_mul_conv = None
self.reset_parameters()
def reset_parameters(self):
if self.pooling_type == 'att':
kaiming_init(self.conv_mask, mode='fan_in')
self.conv_mask.inited = True
if self.channel_add_conv is not None:
last_zero_init(self.channel_add_conv)
if self.channel_mul_conv is not None:
last_zero_init(self.channel_mul_conv)
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pooling_type == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = out * channel_mul_term
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out