【Transformers】第 6 章:用于标记分类的微调语言模型
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
代币分类介绍
了解NER
理解词性标注
了解质量保证
微调 NER 的语言模型
使用令牌分类回答问题
概括
在本章中,我们将学习用于标记分类的微调语言模型。本章探讨了命名实体识别( NER )、词性( POS ) 标记和问答( QA )等任务。我们将学习如何在此类任务上微调特定的语言模型。我们将比其他语言模型更关注 BERT。您将学习如何使用 BERT 应用 POS、NER 和 QA。您将熟悉这些任务的理论细节,例如它们各自的数据集以及如何执行它们。完成本章后,您将能够使用 Transformers 执行任何令牌分类。
在本章中,我们将针对以下任务微调 BERT:针对 NER 和 POS 等令牌分类问题微调 BERT,针对 NER 问题微调语言模型,以及将 QA 问题视为开始/停止令牌分类。
本章将涵盖以下主题:
- 代币分类介绍
- 微调 NER 的语言模型
- 使用令牌分类回答问题
技术要求
我们将使用 Jupyter Notebook 来运行我们的编码练习和 Python 3.6+,并且需要安装以下包:
- sklearn
- transformers 4.0+
- Datasets
- seqeval
代币分类介绍
的任务对令牌序列中的每个令牌进行分类称为令牌分类。该任务表示特定模型必须能够将每个令牌分类到一个类中。POS 和 NER 是该标准中最著名的两个任务。然而,QA 也是属于这一类别的另一项主要 NLP 任务。我们将在以下部分讨论这三个任务的基础知识。
了解NER
知名人士之一令牌分类类别中的任务是 NER - 将每个令牌识别为实体与否,并识别每个检测到的实体的类型。例如,一个文本可以同时包含多个实体——人名、位置、组织和其他类型的实体。以下文本是 NER 的一个明显示例:
乔治华盛顿是美利坚合众国的总统之一。
乔治华盛顿是人名,而美利坚 合众国是地名。序列标记模型期望以标签的形式标记每个单词,每个单词都包含有关标签的信息。BIO 的标签是普遍用于标准NER任务的那些。
下表是标签及其描述的列表:
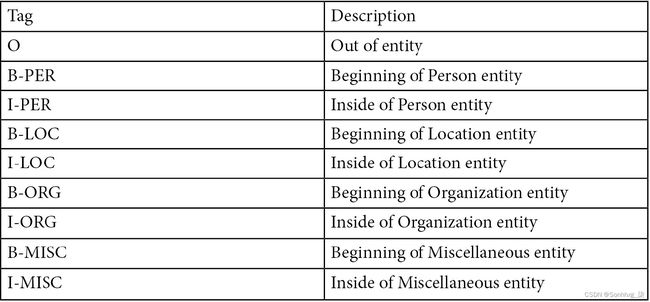
表 1 – BIOS 标签及其描述表
从该表中,B表示标记的开头,I表示标记的内部,而O表示实体的外部。这就是这种类型的注释被称为BIO的原因。例如,前面显示的句子可以使用 BIO 进行注释:
[B-PER|George] [I-PER|Washington] [O|is] [O|one] [O|the] [O|presidents] [O|of] [B-LOC|United] [I-LOC|States] [I-LOC|of] [I-LOC|America] [O|.]因此,序列必须以 BIO 格式标记。样本数据集可以采用如下所示的格式:
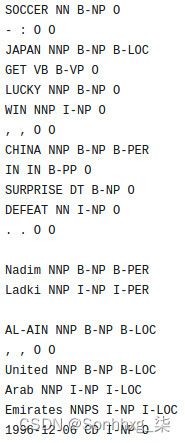
图 6.1 – CONLL2003 数据集
除了我们看到的 NER 标签之外,这个数据集中还有可用的 POS 标签
理解词性标注
POS 标记,或语法标记,是根据其各自的词性对给定文本中的单词进行注释。举个简单的例子,在给定的文本中,识别每个单词在名词、形容词、副词和动词类别中的作用被认为是 POS。然而,从语言的角度来看,除了这四个角色之外,还有很多角色。
就 POS 标签而言,存在变体,但 Penn Treebank POS 标签集是最著名的标签集之一。以下屏幕截图显示了这些角色的摘要和各自的描述:
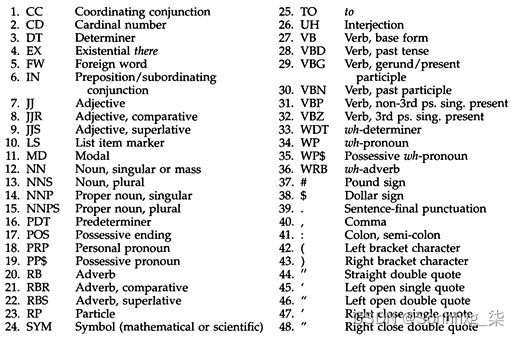
图 6.2 – Penn Treebank POS 标签
POS 任务的数据集注释与图 6.1中所示的示例类似。
这些标签的注释在特定的 NLP 应用程序中非常有用,并且是许多其他方法的构建块之一。变形金刚和许多高级模型可以以某种方式理解其复杂架构中单词的关系。
了解质量保证
质量保证或阅读理解任务包括一组阅读理解文本,上面有各自的问题。来自此的示例性数据集范围是SQUAD或斯坦福问答数据集。该数据集由 Wikipedia 文本和有关它们的相应问题组成。答案是原始维基百科文本的片段形式。
以下屏幕截图显示了此数据集的示例:

图 6.3 – SQUAD 数据集示例
突出显示的红色部分是答案,每个问题的重要部分以蓝色突出显示。好的 NLP 模型需要根据问题对文本进行分割,而这种分割可以以序列标注的形式进行。该模型将段的开始和结束标记为答案开始和结束段。
到目前为止,您已经了解了现代 NLP 序列标记任务的基础知识,例如 QA、NER 和 POS。在下一节中,您将了解如何针对这些特定任务微调 BERT 并使用数据集库中的相关数据集。
微调 NER 的语言模型
在本节中,我们将学习如何为 NER 任务微调 BERT。我们首先从数据集库开始,然后加载conll2003数据集。
数据集卡可在conll2003 · Datasets at Hugging Face访问。以下屏幕截图显示了 HuggingFace 网站上的这张模型卡:
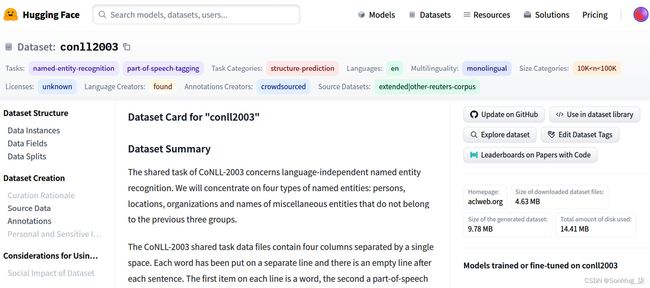
图 6.4 – HuggingFace 的 CONLL2003 数据集卡
从这个截图可以看出可以看出模型是在这个数据集上训练的,并且当前可用并列在右侧面板中。但是,也有数据集的描述,例如它的大小和特征:
- 要加载数据集,使用以下命令:
import datasets conll2003 = datasets.load_dataset("conll2003")将出现一个下载进度条,完成下载和缓存后,数据集就可以使用了。以下屏幕截图显示了进度条:

图 6.5 – 下载和准备数据集
- 您可以轻松通过访问仔细检查数据集使用以下命令训练样本:
conll2003["train"][0]以下屏幕截图显示了结果:

图 6.6 – 来自数据集库的 CONLL2003 训练样本
- POS 和 NER 的相应标签显示在前面的屏幕截图中。这部分我们将只使用 NER 标签。您可以使用以下命令获取此数据集中可用的 NER 标签:
conll2003["train"].features["ner_tags"] - 结果也是如图6.7所示。所有的 BIO 标签都是显示,总共有九个标签:
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None) - 下一步是加载 BERT 标记器:
from transformers import BertTokenizerFast tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased") - 标记器类也可以处理空格标记的句子。我们需要启用我们的标记器来处理空白标记化的句子,因为 NER 任务对每个标记都有一个基于标记的标签。此任务中的标记通常是空格标记化的单词,而不是 BPE 或任何其他标记器标记。根据上面的说法,让我们看看tokenizer可以如何与空格标记化的句子一起使用:
tokenizer(["Oh","this","sentence","is","tokenized","and", "splitted","by","spaces"], is_split_into_words=True)如您所见,只需将is_split_into_words设置为True,问题就解决了。
- 它需要在使用数据之前对其进行预处理训练。为此,我们必须使用以下函数并映射到整个数据集:
def tokenize_and_align_labels(examples): tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True) labels = [] for i, label in enumerate(examples["ner_tags"]): word_ids = \ tokenized_inputs.word_ids(batch_index=i) previous_word_idx = None label_ids = [] for word_idx in word_ids: if word_idx is None: label_ids.append(-100) elif word_idx != previous_word_idx: label_ids.append(label[word_idx]) else: label_ids.append(label[word_idx] if label_all_tokens else -100) previous_word_idx = word_idx labels.append(label_ids) tokenized_inputs["labels"] = labels return tokenized_inputs - 此功能将确保我们的标记和标签正确对齐。这种对齐方式是需要,因为令牌是分块标记,但单词必须是一体的。要测试并查看此函数的工作原理,您可以通过给它一个样本来运行它:
q = tokenize_and_align_labels(conll2003['train'][4:5]) print(q)结果如下所示:
>>> {'input_ids': [[101, 2762, 1005, 1055, 4387, 2000, 1996, 2647, 2586, 1005, 1055, 15651, 2837, 14121, 1062, 9328, 5804, 2056, 2006, 10390, 2323, 4965, 8351, 4168, 4017, 2013, 3032, 2060, 2084, 3725, 2127, 1996, 4045, 6040, 2001, 24509, 1012, 102]], [0, 'token_type_id' 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], '标签': [[-100, 5, 0, -100, 0, 0, 0, 3, 4, 0, -100, 0, 0, 1, 2 , -100, -100, 0, 0, 0, 0, 0, 0, 0, -100, -100, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0 , -100]]}
- 但是这个结果是不可读的,所以你可以运行下面的代码来得到一个可读的版本:
for token, label in zip(tokenizer.convert_ids_to_tokens(q["input_ids"][0]),q["labels"][0]): print(f"{token:_<40} {label}")结果如下所示:
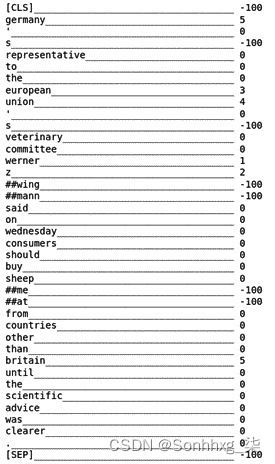
图 6.7 – tokenize 和 align 函数的结果
- 这个映射数据集的功能可以完成通过使用数据集库的地图功能:
tokenized_datasets = conll2003.map(tokenize_and_align_labels, batched=True) - 在下一步中,需要加载具有相应标签数量的 BERT 模型:
from transformers import AutoModelForTokenClassification model = AutoModelForTokenClassification.from_pretrained("bert-base-uncased", num_labels=9) - 该模型将是加载并准备好接受培训。下一个步骤,我们必须准备训练器和训练参数:
from transformers import TrainingArguments, Trainer args = TrainingArguments( "test-ner", evaluation_strategy = "epoch", learning_rate=2e-5, per_device_train_batch_size=16, per_device_eval_batch_size=16, num_train_epochs=3, weight_decay=0.01, ) - 需要准备数据收集器。它将在训练数据集上应用批处理操作以使用更少的内存并更快地执行。你可以这样做:
from transformers import DataCollatorForTokenClassification data_collator = DataCollatorForTokenClassification(tokenizer) - 为了能够评估模型性能,HuggingFace 的数据集库中有许多可用于许多任务的指标。我们将使用 NER 的序列评估指标。seqeval 是一个很好的 Python 框架,用于评估序列标记算法和模型。需要安装seqeval库:
pip install seqeval - 之后,你可以加载指标:
metric = datasets.load_metric("seqeval") - 这很容易使用以下代码查看指标如何工作:
example = conll2003['train'][0] label_list = conll2003["train"].features["ner_tags"].feature.names labels = [label_list[i] for i in example["ner_tags"]] metric.compute(predictions=[labels], references=[labels])结果如下:

图 6.8 – seqeval 度量的输出
为样本输入计算各种指标,例如准确度、F1 分数、精度和召回率。
- 以下函数用于计算指标:
import numpy as np def compute_metrics(p): predictions, labels = p predictions = np.argmax(predictions, axis=2) true_predictions = [ [label_list[p] for (p, l) in zip(prediction, label) if l != -100] for prediction, label in zip(predictions, labels) ] true_labels = [ [label_list[l] for (p, l) in zip(prediction, label) if l != -100] for prediction, label in zip(predictions, labels) ] results = \ metric.compute(predictions=true_predictions, references=true_labels) return { "precision": results["overall_precision"], "recall": results["overall_recall"], "f1": results["overall_f1"], "accuracy": results["overall_accuracy"], } - 最后步骤是制作培训师并对其进行培训因此:
trainer = Trainer( model, args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"], data_collator=data_collator, tokenizer=tokenizer, compute_metrics=compute_metrics ) trainer.train() - 后运行trainer的train函数结果如下:

图 6.9 – 训练后的训练结果
- 训练后需要保存模型和分词器:
model.save_pretrained("ner_model") tokenizer.save_pretrained("tokenizer") - 如果您希望将模型与管道一起使用,您必须阅读配置文件并根据您在label_list对象中使用的标签正确分配label2id和id2label:
id2label = { str(i): label for i,label in enumerate(label_list) } label2id = { label: str(i) for i,label in enumerate(label_list) } import json config = json.load(open("ner_model/config.json")) config["id2label"] = id2label config["label2id"] = label2id json.dump(config, open("ner_model/config.json","w")) - 之后就是易于使用的模型如下例子:
from transformers import pipeline model = AutoModelForTokenClassification.from_pretrained("ner_model") nlp = pipeline("ner", model=mmodel, tokenizer=tokenizer) example = "I live in Istanbul" ner_results = nlp(example) print(ner_results)结果将如下所示:
[{'entity': 'B-LOC', 'score': 0.9983942, 'index': 4, 'word': 'istanbul', 'start': 10, 'end': 18}]
至此,您已经学习了如何使用 BERT 应用 POS。您学习了如何使用 Transformers 训练您自己的 POS 标记模型,并且还测试了该模型。在下一节中,我们将重点介绍 QA。
使用令牌分类回答问题
QA问题是通常定义为具有给定文本和 AI 问题的 NLP 问题,并得到答案。通常,这个答案可以在原文中找到,但有不同的方法来解决这个问题。在视觉问答( VQA ) 的情况下,问题是关于视觉实体或视觉概念而不是文本,但问题本身是文本形式的。
VQA的一些例子如下:

图 6.10 – VQA 示例
大多数型号旨在用于 VQA 的多模态模型可以理解视觉上下文以及问题并正确生成答案。但是,单峰全文本 QA 或仅 QA 是基于文本上下文和具有相应文本答案的文本问题:
- 小队是最知名的之一QA 领域的数据集。要查看 SQUAD 的示例并检查它们,您可以使用以下代码:
from pprint import pprint from datasets import load_dataset squad = load_dataset("squad") for item in squad["train"][1].items(): print(item[0]) pprint(item[1]) print("="*20)结果如下:
answers {'answer_start': [188], 'text': ['a copper statue of Christ']} ==================== Context ('Architecturally, the school has a Catholic character. Atop the Main ' "Building's gold dome is a golden statue of the Virgin Mary. Immediately in " 'front of the Main Building and facing it, is a copper statue of Christ with ' 'arms upraised with the legend "Venite Ad Me Omnes". Next to the Main ' 'Building is the Basilica of the Sacred Heart. Immediately behind the ' 'basilica is the Grotto, a Marian place of prayer and reflection. It is a ' 'replica of the grotto at Lourdes, France where the Virgin Mary reputedly ' 'appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ' '(and in a direct line that connects through 3 statues and the Gold Dome), is ' 'a simple, modern stone statue of Mary.') ==================== Id '5733be284776f4190066117f' ==================== Question 'What is in front of the Notre Dame Main Building?' ==================== Title 'University_of_Notre_Dame' ====================然而,有是SQUAD数据集的第2版,训练样本较多,强烈推荐使用。为了全面了解如何为 QA 问题训练模型,我们将关注这个问题的当前部分。
- 首先,使用以下代码加载 SQUAD 版本 2:
from datasets import load_dataset squad = load_dataset("squad_v2") - 加载 SQUAD 数据集后,您可以使用以下代码查看该数据集的详细信息:
squad结果如下:

图 6.11 – SQUAD 数据集(版本 2)详细信息
SQUAD 数据集的详细信息将如图 6.11 所示。如您所见,有超过 130,000 个训练样本和超过 11,000 个验证样本。
- 正如我们所做的那样对于 NER,我们必须对数据进行预处理,以获得模型使用的正确形式。为此,您必须首先加载分词器,只要您使用的是预训练模型并希望针对 QA 问题对其进行微调,它就是一个预训练的分词器:
from transformers import AutoTokenizer model = "distilbert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model)如您所见,我们将使用distillBERT模型。
根据我们的 SQUAD 示例,我们需要为模型提供多个文本,一个用于问题,一个用于上下文。因此,我们需要我们的标记器将这两个并排放置,并用特殊的[SEP]标记将它们分开,因为distillBERT是基于 BERT 的模型。
QA 的范围还有一个问题,就是上下文的大小。上下文大小可以长于模型输入大小,但我们不能将其减小到模型接受的大小。对于一些问题,我们可以这样做,但在 QA 中,答案可能在截断部分。我们将向您展示一个使用文档步幅解决此问题的示例。
- 以下是一个例子来展示它是如何使用tokenizer工作的:
max_length = 384 doc_stride = 128 example = squad["train"][173] tokenized_example = tokenizer( example["question"], example["context"], max_length=max_length, truncation="only_second", return_overflowing_tokens=True, stride=doc_stride ) - 步幅是用于返回第二部分的步幅的文档步幅,如窗口,而return_overflowing_tokens标志为模型提供有关是否应返回额外标记的信息。tokenized_example的结果不仅仅是一个标记化的输出,而是有两个输入 ID。在下面,您可以看到结果:
len(tokenized_example['input_ids'])2
- 因此,您可以通过运行以下for循环来查看完整结果:
for input_ids in tokenized_example["input_ids"][:2]: print(tokenizer.decode(input_ids)) print("-"*50)结果是如下:
[CLS] beyonce got married in 2008 to whom? [SEP] on april 4, 2008, beyonce married jay z. she publicly revealed their marriage in a video montage at the listening party for her third studio album, i am... sasha fierce, in manhattan's sony club on october 22, 2008. i am... sasha fierce was released on november 18, 2008 in the united states. the album formally introduces beyonce's alter ego sasha fierce, conceived during the making of her 2003 single " crazy in love ", selling 482, 000 copies in its first week, debuting atop the billboard 200, and giving beyonce her third consecutive number - one album in the us. the album featured the number - one song " single ladies ( put a ring on it ) " and the top - five songs " if i were a boy " and " halo ". achieving the accomplishment of becoming her longest - running hot 100 single in her career, " halo "'s success in the us helped beyonce attain more top - ten singles on the list than any other woman during the 2000s. it also included the successful " sweet dreams ", and singles " diva ", " ego ", " broken - hearted girl " and " video phone ". the music video for " single ladies " has been parodied and imitated around the world, spawning the " first major dance craze " of the internet age according to the toronto star. the video has won several awards, including best video at the 2009 mtv europe music awards, the 2009 scottish mobo awards, and the 2009 bet awards. at the 2009 mtv video music awards, the video was nominated for nine awards, ultimately winning three including video of the year. its failure to win the best female video category, which went to american country pop singer taylor swift's " you belong with me ", led to kanye west interrupting the ceremony and beyonce [SEP] -------------------------------------------------- [CLS] beyonce got married in 2008 to whom? [SEP] single ladies " has been parodied and imitated around the world, spawning the " first major dance craze " of the internet age according to the toronto star. the video has won several awards, including best video at the 2009 mtv europe music awards, the 2009 scottish mobo awards, and the 2009 bet awards. at the 2009 mtv video music awards, the video was nominated for nine awards, ultimately winning three including video of the year. its failure to win the best female video category, which went to american country pop singer taylor swift's " you belong with me ", led to kanye west interrupting the ceremony and beyonce improvising a re - presentation of swift's award during her own acceptance speech. in march 2009, beyonce embarked on the i am... world tour, her second headlining worldwide concert tour, consisting of 108 shows, grossing $ 119. 5 million. [SEP] --------------------------------------------------正如您从前面的输出中看到的那样,在 128 个标记的窗口中,上下文的其余部分在输入 ID 的第二个输出中再次复制。
其他问题是结束跨度,它在数据集中不可用,而是给出了答案的开始跨度或开始字符。很容易找到答案的长度并将其添加到开始跨度,这将自动产生结束跨度。
- 现在我们知道了这个数据集的所有细节以及如何处理它们,我们可以很容易地把它们放在一起做一个预处理函数(链接:https ://github.com/huggingface/transformers/blob/master/examples/pytorch /question-answering/run_qa.py ):
def prepare_train_features(examples): # 标记示例 tokenized_examples = tokenizer( examples["question" if pad_on_right else "context"], examples["context" if pad_on_right else "question"], truncation="only_second" if pad_on_right else "only_first", max_length=max_length, stride=doc_stride, return_overflowing_tokens=True, return_offsets_mapping=True, padding="max_length", ) # 从一个特征映射到它的例子 sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping") offset_mapping = tokenized_examples.pop("offset_mapping") tokenized_examples["start_positions"] = [] tokenized_examples["end_positions"] = [] # 用 CLS 标记不可能的答案 # start 和 end token 是每一个的答案 for i, offsets in enumerate(offset_mapping): input_ids = tokenized_examples["input_ids"][i] cls_index = input_ids.index(tokenizer.cls_token_id) sequence_ids = tokenized_examples.sequence_ids(i) sample_index = sample_mapping[i] answers = examples["answers"][sample_index] if len(answers["answer_start"]) == 0: tokenized_examples["start_positions"].\ append(cls_index) tokenized_examples["end_positions"].\ append(cls_index) else: start_char = answers["answer_start"][0] end_char = start_char + len(answers["text"][0]) token_start_index = 0 while sequence_ids[token_start_index] != / (1 if pad_on_right else 0): token_start_index += 1 token_end_index = len(input_ids) - 1 while sequence_ids[token_end_index] != (1 if pad_on_right else 0): token_end_index -= 1 if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char): tokenized_examples["start_positions"].append(cls_index) tokenized_examples["end_positions"].append(cls_index) else: while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char: token_start_index += 1 tokenized_examples["start_positions"].append(token_start_index - 1) while offsets[token_end_index][1] >= end_char: token_end_index -= 1 tokenized_examples["end_positions"].append(token_end_index + 1) return tokenized_examples - 将此函数映射到数据集将应用所有必需的更改:
tokenized_datasets = squad.map(prepare_train_features, batched=True, remove_columns=squad["train"].column_names) - 就像其他示例一样,您现在可以加载预训练模型进行微调:
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer model = AutoModelForQuestionAnswering.from_pretrained(model) - 下一个步骤是创建训练参数:
args = TrainingArguments( "test-squad", evaluation_strategy = "epoch", learning_rate=2e-5, per_device_train_batch_size=16, per_device_eval_batch_size=16, num_train_epochs=3, weight_decay=0.01, ) - 如果我们不打算使用数据整理器,我们将为模型训练器提供一个默认的数据整理器:
from transformers import default_data_collator data_collator = default_data_collator - 现在,一切准备制作培训师:
trainer = Trainer( model, args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"], data_collator=data_collator, tokenizer=tokenizer, ) - 并且训练器可以与训练功能一起使用:
trainer.train()结果将如下所示:
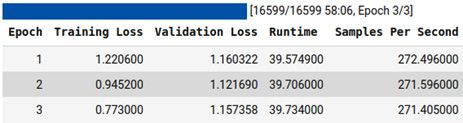
图 6.12 – 训练结果
如您所见,该模型使用三个 epoch 进行训练,并报告了验证和训练损失的输出。
- 与任何其他模型一样,您可以使用以下函数轻松保存此模型:
trainer.save_model("distillBERT_SQUAD")如果你想使用您保存的模型或任何其他经过 QA 训练的模型,transformers库提供了一个易于使用和实施的管道,无需额外的努力。
- 通过使用此管道功能,您可以使用任何模型。以下是使用 QA 管道的模型的示例:
from transformers import pipeline qa_model = pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='distilbert-base-cased')管道只需要两个输入来使模型准备好使用,即模型和标记器。虽然,您还需要为其提供管道类型,在给定示例中为 QA。
- 下一步是为其提供所需的输入、上下文和问题:
question = squad["validation"][0]["question"] context = squad["validation"][0]["context"]The question and the context can be seen by using following code:
print("Question:") print(question) print("Context:") print(context)Question: In what country is Normandy located? Context: ('The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the ' 'people who in the 10th and 11th centuries gave their name to Normandy, a ' 'region in France. They were descended from Norse ("Norman" comes from ' '"Norseman") raiders and pirates from Denmark, Iceland and Norway who, under ' 'their leader Rollo, agreed to swear fealty to King Charles III of West ' 'Francia. Through generations of assimilation and mixing with the native ' 'Frankish and Roman-Gaulish populations, their descendants would gradually ' 'merge with the Carolingian-based cultures of West Francia. The distinct ' 'cultural and ethnic identity of the Normans emerged initially in the first ' 'half of the 10th century, and it continued to evolve over the succeeding ' 'centuries.') - 该模型可以是以下示例使用:
qa_model(question=question, context=context)结果如下:
{'answer': 'France', 'score': 0.9889379143714905, 'start': 159, 'end': 165,}
到目前为止,您已经了解了如何在所需的数据集上进行训练。您还了解了如何使用管道使用经过训练的模型。
概括
在本章中,我们讨论了如何微调预训练模型以适应任何标记分类任务。探索了关于 NER 和 QA 问题的微调模型。通过示例详细说明了在具有管道的特定任务上使用预训练和微调模型。我们还了解了这两个任务的各种预处理步骤。保存针对特定任务进行微调的预训练模型是本章的另一个主要学习点。我们还看到了如何在序列大小比模型输入长的 QA 等任务上训练具有有限输入大小的模型。更有效地使用分词器以文档跨度进行文档拆分也是本章中的另一个重要内容。
在下一章中,我们将讨论使用 Transformer 的文本表示方法。通过学习本章,您将学习如何执行零样本/少样本学习和语义文本聚类。