DL-Paper精读:Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
https://arxiv.org/abs/2103.14030
Transformer在Vision领域的各项任务上已经占据了sota的地位,目前精度最高的模型便是Swin Transformer,一个针对于图像任务的实体分辨率问题进行优化的工作,今天对其进行详细的研究。
Current works and Limitation
ViT及Deit等工作成功地将Transformer结构引入了CV领域,通过先切片拉直再Embedding的操作,将2维CV图像转化为了类似于NLP的序列输入。然后将切片作为token序列输入Transformer结构中,通过不断地在各个patch之间进行交叉融合实现self-attention。目前在ImageNet的分类任务中取得了较好的结果。
但是对于ViT来说,有一个非常不鲁棒的因素,就是patch_size的大小设置,一般设置为16在ImageNet数据集上取得了较好的效果,但是对于更加广泛的CV任务来说,这样的做法存在两个巨大的问题:
1. “large variations in the scale of visual entities”,即目标实体的大小。在NLP任务中,每个token就是一个词,可以非常方便地分割词组句子。但是对于2维图像来说,其中的目标实体的大小是不可控的,有的目标较大,横跨了多个patch,也有的目标很小,就包含在某一个patch中。这时给定size为16的patch则无法有效地处理不同大小的目标。尤其是对于目标检测及分割等任务中的较小目标,无法实现像素级别的检测。
2. “high resolution of pixels”,无法直接将Transformer及MLP适用于CV任务的一个主要问题,就是如果按照像素进行处理的话计算量过大。ViT中虽然通过分patch的操作,实现了计算量上的压缩,但Attention的计算过程,关于图像size的大小成二次方增长。因此虽然ViT等工作在ImageNet数据集上给出了较好结果,但面对更大的图像,则无法实现有效地处理。

Motivation
针对以上问题,本文希望能够提出一种基于Transformer的模型。它拥有像ResNet等网络的层级架构,能够有效处理不同大小的目标,同时能够直接使用CNN中的FPN,U-Net等技术。同时计算复杂度关于图像大小线性增长,从而可以处理更大分辨率的图像。作为CV领域新的backbone模型,能够对分类,检测,分割等任务都实现较高的精度。
Method
想法说来简单,但文章的具体方法实现非常复杂,因此这一部分需要结合代码(https://github.com/microsoft/Swin-Transformer)来进行说明。

总的结构如上图所示,整体结构还是与ViT类似,图片切片作为输入,重复N个Encoder结构,然后接输出头。但核心区别在于,ViT中N个Encoder模块的参数量是一样的,输出输出大小也一样。但是在Swin T中,这N个模块被分为了多个stage,每个stage内部模块的尺寸不变,但不同stage相接的地方,实现了分辨率的减半和通道的翻倍,该操作与CNN网络中是类似的。以下具体针对每一个细节进行解释。
1. Input
按照论文所说,Swin-T将图像切分为4x4的patch,然后通过linear embedding layer来将其映射到任意维度。话是这么说,然而看代码:
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)嗯,只能说懂得都懂。。。然后与position_embed相加,输入到Transformer块中。
2. Transformer Blocks
Transformer Blocks的结构如图所示,与ViT中基本一致,MSA+ MLP的计算单元,再加上LN正则及残差连接等。区别在于将普通的multi-head self-attention模块改为了一种基于局部窗的MSA操作(shifted windows based MSA, W-MSA)。该设计主要有两个方面的改进:a. windows,基于窗口的自适应;b. shift, 窗口偏移。

a. Windows划分,该操作是降低计算复杂度的一步。在ViT中,MSA的计算是global的,假如一张图像被划分为h x w个patch,则在MSA中需要对这hw个patch都进行交叉计算,则计算量为(hw)2的级数。W-MSA将整个图再次划分若干个windows,假设每个windows中包含M x M个patch(默认M=7),则单个windows中MSA的计算复杂度为 (MXM)2,考虑到整张图被划分为了 (h/M)*(w/M)个windows,则总的计算量为(M2 hw)。这样原本关于图像尺寸成2次方增长的复杂度就被降低到了线性。
Windows的切分代码如下,将图像按照预设的窗口大小进行切分后,堆积在batch维,则后续self-attention的计算与原来一致。
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)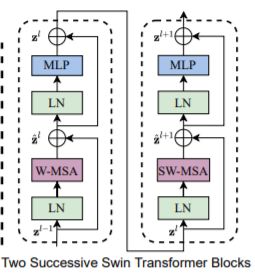
b. Shift操作,划分windows的操作虽然能够有效降低计算复杂度,但它本质上是将全局的信息操作局限在了局部,各个划分的windows之间被隔断。为了实现各个windows之间的信息交叉,本文又提出了shift windows的操作,在两个相继的Transformer Block中,在W-MSA操作时对windows进行偏移(默认选择windows大小一半的偏移量)。
*这里需要注意,在实际操作中,其实windows划分是与shift操作分开的。也就是说windows的划分对于所有的layer都是一样的,而windows的偏移,代码中其实是借助mask来实现的(吐槽mask,实在是喜欢不起来),同时提出了一种cyclic shift操作。该操作有利于解决shift windows的碎片化问题,减少计算量,同时有效实现不同windows之间的信息融合。但说实话这一部分看的不是很明了,包括图示和代码实现都有些一头雾水,,,

# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))3. Patch merge
为实现层次化的网络结构,实现图像分辨率的降级,文中提出采用patch的融合来实现这一目的。具体实现在论文里貌似没有描述,查看代码,发现其实现方式是一种类似于YOLO中的Reorge操作,对2D图像进行像素级的抽取,然后堆积在Channel维度,接着采用一个linear将channel变为原来的2倍,这样就实现了分辨率减半,channel翻倍的结果。代码如下,但是这里让人不禁怀疑,Reorge的操作是否会破坏原图形的position信息。
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) #self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)4. Relative position bias
此外,在attention的计算中,本文还采用了相对位置偏置项,并证明了其对精度的有效提升,代码如下:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view( self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)Experiments
实验部分无需赘述,Swin-T最为人所称道的就是它的结果,在分类(86.4 on ImageNet),检测(58.7 box AP and 51.1 mask AP on COCO test-dev)和分割(53.5 mIoU on ADE20K val)等任务上都展示了非常好的结果,证明了其作为CV领域backbone网络的潜力。同时还有较充分的消融实验,证明了文中所提到的Shifted windows, Relative position bias, cyclic shift等操作对于精度及latency的影响。
Thoughts
Swin-T作为Transformer在CV领域的探索开拓之作无疑是成功的,针对ViT所提出的关于patch的尺寸及图像size的问题非常精准,同时提出hierarchical网络架构作为CV领域的backbone的思路也是值得去研究的。但在具体的执行层面,首先是减小feature map所采用的reorge操作是否合理需要商榷;同时在降低计算量级的时候所采用的windows MSA,将全局问题转为了局部问题,虽然又设计了shift操作来消除windows局部信息隔离的问题,但带来了更多繁琐且不好解释的操作。目前业界关于Vision Transformer不知是否已经采取了Swin-T来作为backbone,但从个人角度来说,相比于ResNet的清晰明了,Swin-T显得过于繁琐了一些,还是希望看到一个更直观更优秀的网络架构。