Learning Visual Commonsense for Robust Scene Graph Generation论文笔记
原论文地址:https://link.springer.com/content/pdf/10.1007/978-3-030-58592-1_38.pdf
目录
总体结构:
感知模型GLAT:
融合感知和常识模型
Conclusion
附件:论文翻译(绝大部分机翻)
Abstract
Introduction
Reference
Related Work
2.1 Commonsense in Computer Vision(常识在计算机视觉中)
2.2 Commonsense in Scene Graph Generation[李8] (常识在场景图生成)
2.3 Transformers and Graph-Based Neural Networks[李9]
3 Method
3.1 Global-Local Attention Transformers(常识模块)
3.2 Fusing Perception and Commonsense
4、实验
5 Conclusion
总体结构:
-
感知模型,它采用输入图像I并生成感知驱动的场景图 GP
-
常识模型,它以 G P 作为输入,并产生一个常识驱动的场景图 G C
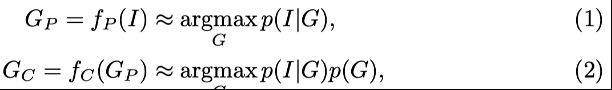
感知模型GLAT:
输入G_p,带有masked node。经过一个Global-Local多头注意力机制,
具体实现:
-
G=(Ne,Np,Es,Eo)Ne:实体节点 Np:谓词节点 Es:谓词指向主语 Eo:谓词指向宾语
-
输入:多个节点x_i^(0),封装成矩阵X(0)
-
每一层layer:
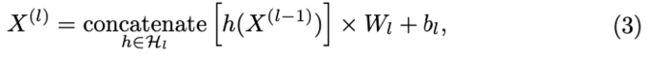
-
Decoder:用一个全连接层分类节点(实体节点、谓词节点),另一个全连接层分类边(subject、object、无边)
其中 H_l是layer l的Attention head。包含三部分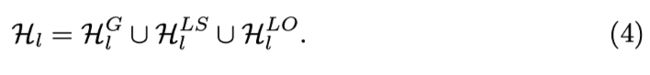 global 、 local Subject、 local Object。
global 、 local Subject、 local Object。
每个h_G、h_LS、h_LO都是一个self-attention 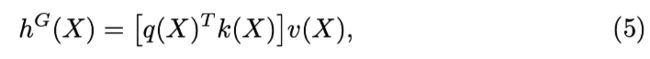
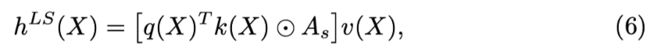 (A s 是主语边缘的邻接矩阵,从每个谓词到它的主语之间为 1,反之亦然,其他地方为 0。我们类似地定义宾语边缘的 Ao 和 h LO)
(A s 是主语边缘的邻接矩阵,从每个谓词到它的主语之间为 1,反之亦然,其他地方为 0。我们类似地定义宾语边缘的 Ao 和 h LO)
训练方法:将噪声随机添加到带注释的场景图(数据来自Visual Genome,比如使其产生masked node),然后传入GLAT,重建节点和边,并在添加噪声之前和原始场景图进行对比。
融合感知和常识模型
感知和常识模型使用softmax计算每一类的可能性,选择概率最大的那个,并根据softmax值分配相应的置信度。融合模块根据两个模型的置信度,给出最终预测。
具体:同一节点i
-
在G_p有一个L_i^P向量(有实体节点、谓词节点之分)
-
在G_c也有一个L_i^C
-
置信度:
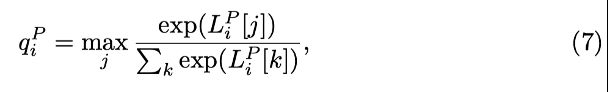 q_i^C类似
q_i^C类似 -
融合机制:
 softmax
softmax
Conclusion
主要创新点:
- 提出GLAT 学习Commonsense效果更好。
- 提出场景图生成架构:由感知和常识模型组成。
- 提出融合机制,决定何时信任感知或者常识。
附件:论文翻译(绝大部分机翻)
Abstract
场景图生成模型通过对象和谓词识别来理解场景,但由于野外感知的挑战,容易出错。感知错误往往会导致输出场景图中无意义的构图,这些构图不遵循现实世界的规则和模式,可以使用常识性知识进行纠正。我们提出了第一个从数据中自动获取启示和直观物理等视觉常识的方法,并用它来提高场景理解的鲁棒性。为此,我们扩展了Transformer模型,以纳入场景图的结构,并在场景图语料库上培训我们的全局-本地注意力Transformer。一旦经过培训,我们的模型可以应用于任何场景图生成模型,并纠正其明显的错误,从而产生语义上更合理的场景图。通过广泛的实验,我们展示了我们的模型比任何替代方案都能更好地学习常识,并提高了最先进的场景图生成方法的准确性。
Introduction
在最近的计算机视觉文献中,人们越来越有兴趣将常识推理和背景知识纳入视觉识别和场景理解的过程[8,9,13,31,33]。例如,在场景图生成(SGG)中,外部知识库[7]和数据集统计[2,34]已用于提高实体(对象)和谓词(关系)识别的准确性。这些技术的效果通常是纠正明显的感知错误,并代之以更合理的替代方案。例如,图1(上图)显示,SGG模型错误地将鸟类归类为熊,这可能是由于光线昏暗和物体尺寸小。然而,常识模型[李1] 可以正确预测鸟类,因为熊在树枝上是一种不太常见的情况,与直觉物理不太一致,或者与动物行为相反。
图1. 方法概述:我们提出了一个常识模型,该模型采用感知模型生成的场景图,并对其进行细化,使其更合理。然后,融合模块比较感知和常识输出,并生成最终图,将这两个信号都包含在一起。
将常识纳入视觉识别过程的现有方法有两个主要局限性。首先,它们依赖于外部常识来源,例如众包或自动挖掘的常识规则,这些规则往往不完整和不准确[7],或直接从训练数据中收集的统计数据,这些统计数据仅限于简单的启发式方法,如共发生频率[2]。本文提出了从场景图语料库中自动学习图形常识的第一种方法,该语料库不需要外部知识,并通过学习简单启发式方法之外的复杂、结构化模式来获得常识。
其次,大多数现有方法都非常容易受到数据偏见的影响,因为它们将数据驱动的常识知识集成到数据驱动的神经网络中。比如图1中的常识模型,为了避免大象画图的奇葩三叉大象,而大象在视觉上相当清晰,感知模型已经正确识别了大象。现有的将场景理解与常识相结合的努力都没有研究过是信任感知还是常识的基本问题,即你看到的与你期望的。本文提出了一种将感知[李2] 和常识[李3] 分离为两个单独训练的模型的方法,并引入了一种利用这两种模型之间的分歧来实现两全其一的方法。
为此,我们首先提出了视觉常识的数学形式化,作为自动编码摄动场景图的问题。基于新形式主义,我们提出了一种从附加注释的场景图中学习视觉常识的新方法。我们扩展了最近成功的变压器[23]通过添加局部注意力头,使他们能够编码场景图的结构,并在注释场景图的语料库上训练他们,通过类似于BERT的掩码框架预测场景缺失的元素[5]。如图2所示,考虑到给定场景图的结构和上下文,我们的常识模型学会了利用其经验来想象哪个实体或谓词可以取代掩码。一旦训练好,它可以堆叠在任何感知(即SGG)模型上,以纠正生成的场景图中的荒谬错误。
感知模型和常识模型的输出可以看作两个生成的场景图,并存在潜在分歧。我们设计了一个融合模块,该模块将这两个图及其分类置信值一起,并预测一个反映感知和常识知识的最终场景图。我们的融合模块信任每个输入的程度因图像而异,并根据每个模型的估计置信度确定。这样,如果感知模型因黑暗而不确定鸟类,融合模块更依赖常识,如果感知模型因其清晰度而对大象有信心,则融合模块信任其眼睛。
我们对视觉基因组数据集进行广泛的实验[12] , 显示(1)提出的GLAT模型在常识性采集任务中优于现有的变压器和基于图的模型 ; (2)我们的模型学习了 SGG 模型中不存在的各种类型的常识,如对象启示和直观物理 ; (3)该模型对数据集偏置鲁棒,即使在罕见和零射击的场景中也表现出常识行为 ; ( 4) 提出的 GLAT 和融合机制可以应用于任何 SGG 方法,以纠正其错误并提高其准确性。本文的主要贡献如下:
——我们提出了学习结构化视觉常识的第一种方法,全局局部注意力变压器(GLAT),它不需要任何外部知识,并且优于常规变压器和基于图形的网络。
——我们为场景图生成提出了一个级联融合架构,该架构将常识推理与视觉感知区分开,并以对每个组件失败的鲁棒方式集成它们。
——我们报告了展示我们模型在不发现数据集偏差的情况下学习常识的独特能力的实验,以及它在下游场景理解中的效用。
Reference
- 视觉识别和场景理解中的常识推理和背景知识(commonsense reasoning and background knowledge into the process of visual recognition and scene understanding)
(8)Hybrid knowledge routed modules for large-scale object detection
(9) Compositional learning for human object interaction(人物交互中的组合学习)
(31) Visual relationship detection with internal and external linguistic knowledge distillation(内部和外部语言知识蒸馏的视觉关系检测)
理解两个对象之间的视觉关系涉及识别主语、对象和与之相关的谓词。我们利用谓词和hsubj之间的强相关性;obji对(在语义和空间上)来预测以主语和宾语为条件的谓词。与独立建模相比,三个实体的联合建模更准确地反映了它们之间的关系,但由于视觉关系的语义空间巨大,训练数据有限,特别是对于实例很少的长尾关系,因此学习变得复杂。为了克服这一点,我们使用语言统计学知识来规范可视化模型学习。我们通过从训练注释(内部知识)和公开文本(例如维基百科(外部知识)中挖掘)来获取语言知识,计算给定(subj,obj)对谓词的条件概率分布。当我们训练视觉模型时,我们将这些知识提炼成深度模型,以实现更好的推广。我们在视觉关系检测(VRD)和视觉基因组数据集上的实验结果表明,通过这种语言知识蒸馏,我们的模型明显优于最先进的方法,特别是在预测看不见的关系时(例如,VRD零拍测试集的召回率从8.45%提高到19.17%)
(33) From Recognition to Cognition: Visual Commonsense Reasoning.(从识别到认知:视觉常识推理)
对于人类来说,随便瞥一眼就能获取到很多图片信息,这些信息不仅仅是像素点显示的,还有图像之外隐藏的知识类信息,但是这个任务对机器来说很难,这里作者将这个任务定义为视觉常识推理,要求机器不仅回答出正确答案,还要对这个答案给出证明。
作者提出一个新的数据集VCR,包含290k个多选QA,这些问题来源于110k个电影场景。生成大量的有意义并且高质量的问题的关键是对抗性匹配,这是一种通过将丰富的注释转换为偏差极小的多选问题的方法。VCR数据集对人类来说比较简单,准确率可以超过90%,但是对于机器来说比较困难,准确率约为45%。
为了使机器能够达到认知的层面,作者提出一个新的方法,叫做Recognition to Cognition Networks (R2C),为基础、情景化、推理建立了必要的分层模型,缩小了人类和机器在识别VCR上的差距。
Related Work
2.1 Commonsense in Computer Vision(常识在计算机视觉中)
在各种计算机视觉任务中探索了将常识知识纳入对象识别[3,14,28],对象检测[13],语义分割[19],行动识别[9],视觉关系检测[31],场景图生成[2,7,34],和视觉问题回答[18,22]。关于这些方法,有两个方面需要研究:它们的常识来自哪里[李4] ,以及它们如何使用常识[李5] 。
大多数方法要么采用外部精选知识库,如ConceptNet [7,14,18,19,21,28],或通过收集经常注释的语料库上的统计数据,自动获得常识[2,3,13,22,31,34]。然而,前者仅限于不完整的外部知识,后者基于特设、硬编码的启发式方法,如类别的共发生频率。我们的方法首先将视觉常识作为机器学习任务来表述,并训练基于图的神经网络来解决这个问题。第三组作品通过设计专门模型,如直觉物理学[6],或客体启示[4]。[李6] 我们通过利用场景图作为多功能语义表示,提出了一个更通用的框架,包括但不限于物理和启示。与我们的工作最相似的是[26】,它只对对象共现模式进行建模,同时我们还结合了对象关系和场景图结构。
当谈到使用常识时,现有方法将其集成到推理管道中,要么从知识库中检索一组相关事实,要么作为模型的附加功能[7,18,22],或通过使用基于图的消息传播过程将知识图的结构嵌入模型的中间表示[2,3,9,14,28]。其他一些方法通过辅助目标提炼训练期间的知识,使推理简单且不含外部知识[19,31]。然而,在所有这些方法中,常识都无缝地注入到模型中,无法解开。这使得很难分别研究和评估常识和感知,或控制其影响。[李7] 很少有方法将常识建模为一个独立的模块,该模块被后期融合到感知模型的预测中[13,34]。然而,我们是第一个设计单独的感知和常识模型,并根据他们的置信度来自适应地权衡它们的重要性,然后再融合他们的预测。
Reference
- commonsense knowledge in object recognition常识知识在目标识别
(3)Iterative visual reasoning beyond convolutions 超越卷积的迭代视觉推理
(14)Multi-label zero-shot learning with structured knowledge graphs 具有结构化知识图的多标签零样本学习
(28)Zero-shot recognition via semantic embeddings and knowledge graphs 通过语义嵌入和知识图进行零样本识别
- commonsense knowledge in object detection 目标检测
(13)DOCK: detecting objects by transferring common-sense knowledge DOCK:通过转移常识知识来检测对象
- semantic segmentation语义分割
(19)KE-GAN: knowledge embedded generative adversarial networks for semi-supervised scene parsing KE-GAN:用于半监督场景解析的知识嵌入生成对抗网络
- action recognition行动识别
(9)Compositional learning for human object interaction 人物交互的组合学习
- visual relation detection 视觉关系检测
(31)Visual relationship detection with internal and external linguistic knowledge distillation. 具有内部和外部语言知识蒸馏的视觉关系检测。
- scene graph generation(SGG)场景图生成
(2)Knowledge-embedded routing network for scene graph generation 用于场景图生成的知识嵌入路由网络
(7)Scene graph generation with external knowledge and image reconstruction 使用外部知识和图像重建生成场景图
(34)Neural motifs: scene graph parsing with global context 神经图案:场景图解析与全局上下文
2.2 Commonsense in Scene Graph Generation[李8] (常识在场景图生成)
【34】是第一个将常识明确纳入场景图生成过程的人。他们使用预先计算的频率来偏向谓词分类日志,该频率之前是静态分布,给定每个实体类对。虽然这大大提高了它们的整体准确性,但改善的主要原因是,他们更喜欢频繁的三胞胎,而不是其他三胞胎,这在统计学上是值得的。即使他们的模型将一个人和帽子之间的关系归类为持有者,他们的频率偏差也极有可能改变为佩戴,佩戴频率更高。
【2】采用不那么明确的方式将频率纳入实体和谓词分类过程。他们将频率嵌入推理图的边缘权重中,并在消息传播过程中利用这些权重。这改善了结果,特别是在不太频繁的谓词上,因为它不太严格地执行关于最终决定的统计数据。然而,这种方法常识隐含地集成到SGG模型中,不能孤立地探索或研究。我们消除了统计偏差的负面影响,同时保持常识模型与感知的纠缠。
【7]利用ConceptNet [21]而不是数据集统计,这是一个包含概念相关事实的大规模知识图,例如狗是动物或叉子用于进食。给定每个检测到的对象,他们检索涉及该对象类的概念网事实,并在对对象和谓词进行分类之前,使用循环神经网络和注意力机制将这些事实编码为对象特征。然而,ConceptNet并非详尽无遗,因为汇编所有常识性事实极其困难。我们的方法不依赖于有限的外部知识来源,并通过可推广的神经网络自动获得常识。
2.3 Transformers and Graph-Based Neural Networks[李9]
变压器最初被提议通过堆叠几层多头注意力来取代机器翻译的循环神经网络[23]。从那时起,变压器成功地完成了各种视觉和语言任务[5,16,27]。特别是,BERT[5] 随机将给定句子中的一些单词替换为特殊的 MASK 令牌,并尝试重建这些单词。通过这种自我监督的游戏,BERT获得了自然语言,并可以转移自己的语言知识,以在其他NLP任务中表现良好。我们使用类似的自我监督策略来学习完成场景图缺失的部分。我们的模型不是语言,而是获得了以结构化、语义方式想象场景的能力,这是人类常识的标志。
变压器将输入视为一组令牌,并丢弃其中任何形式的结构。为了保持句子中令牌的顺序,BERT在输入变压器之前通过位置嵌入来增强每个令牌的初始嵌入。另一方面,场景图的结构更复杂,无法以如此琐碎的方式嵌入。最近,基于图形的神经网络(GNN)通过应用几层邻域聚合,成功地将图形结构编码为节点表示形式。更具体地说,GNN的每一层都通过一个可训练函数表示每个节点,该函数将节点及其邻居作为输入。图卷积网[11],门控图神经网络[15],和图表注意力网[24] 所有这些都使用不同的邻域聚合计算模型来实现这个想法。GNN通过结合上下文[29,30,32],但我们是第一个利用GNN来学习视觉常识的人。
我们采用图形注意力网,因为它们在使用注意力方面与变压器相似。图注意力网与变压器的主要区别在于,它们不通过对所有其他节点的注意力来表示每个节点,而只计算对相邻邻居的注意力。受此启发,我们使用类BERT的变压器网络,但只需将非邻居节点之间的注意力强制为零,即可将其一半的注意力头替换为局部注意力。通过第4节的烧蚀实验,我们展示了拟议的全局局部注意力变压器(GLAT)优w于常规变压器,以及广泛使用的基于图的模型,如图卷积网和图注意力网。
3 Method
我们将场景图定义为G=(Ne,Np,Es,Eo)。
Ne是一组实体节点Np是一组谓词节点,Es是从每个谓词到其主语(实体节点)的一组边缘,以及Eo是从每个谓词到其宾语(也是实体节点)的一组边缘。
每个实体节点Ne用实体类e∈Ce和一个边界框b∈[0,1]4表示。
每个谓词节点Np都用谓词类cp∈Cp表示并被连接到一个主语和一个宾语连接。
请注意,这种场景图的表述与传统[29]不同,我们将谓词表述为节点而不是边缘。这种调整不会引起任何限制,因为每个场景图都可以从常规表示转换为我们的表示。然而,这种表述允许在同一对实体之间设置多个谓词,它还使我们能够定义统一的attention,无论实体节点还是谓词节点。
给定一个包含许多图像I∈[0, 1] h×w×c的训练数据集与真实场景图 GT 配对[李10] ,我们的目标是训练一个模型,该模型采用新图像并预测一个场景图最大化 p(G |I)。这相当于最大化 p(I | G)p(G),将问题分解为我们所说的感知和常识。在我们提出的直觉中,常识是人类预测哪些情况是可能的,哪些情况是不可能的,或者换句话说,判断感知是不是正确。这可以看作是在场景图中,世界上所有可能情况的先验分布 p(G)。另一方面,感知是从原始感官数据形成符号信念的能力,在我们的例子中分别是 G 和 I。尽管计算机视觉的目标是解决最大后验 (MAP) 问题(最大化 p(G | I)),但神经网络通常无法估计后验,除非在模型定义中明确强制执行先验 [17]。这是在计算机视觉中,先验经常被忽视,或者被错误地认为是均匀分布,使得MAP 等效于最大似然 (ML),i,e,即找到最大化 p(I | G) [20] 的 G。
我们提出了第一种通过设计显式先验模型(常识)来显式近似 MAP 推理的方法。 由于后验推理难以处理,我们提出了一个两阶段框架作为近似:我们首先采用任何现成的 SGG 模型作为感知模型,它采用输入图像I并生成感知驱动的场景图 GP,即 近似最大化可能性。 然后我们提出了一个常识模型,它以 G P 作为输入,并产生一个常识驱动的场景图 G C ,以近似最大化后验,即,
其中 f P 和 f C 是感知和常识模型。 常识模型可以看作是去噪自编码器 [25] 的基于图的扩展,它显然可以学习数据的生成分布 [10, 1],在我们的例子中是 p(G)。 因此,f C 可以将任何场景图作为输入,只需稍微改变输入即可生成更合理的图。 这里的一个关键设计选择是 f C 不将图像作为输入。 否则,很难确保它纯粹是在学习常识而不是感知。
理想情况下,GC 是最好的决定,因为它最大化后验分布[李11] 。 然而,在实践中,自动编码器往往不能充分代表长尾分布,只捕获模式。 这意味着常识模型可能无法预测不太常见的结构,而支持更具统计价值的替代方案。 为了缓解这个问题,我们提出了一个融合模块,它以 G P 和 G C 作为输入,并输出一个融合的场景图 G F ,这是我们系统的最终输出。 这可以看作是一个决策代理,它必须根据每个模型的信心程度来决定对每个模型的信任程度。
图 1 说明了所提议架构的概述。 在本节的其余部分,我们将详细阐述每个模块。
3.1 Global-Local Attention Transformers(常识模块)
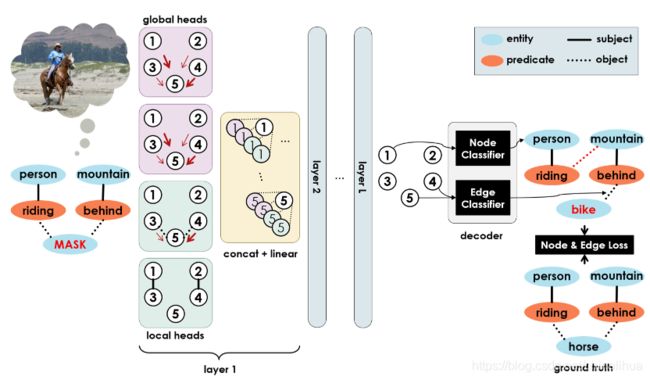
我们提出了第一个基于图的视觉常识模型,该模型通过去噪自动编码器框架学习现实世界场景语义结构的生成分布。 受BERT [5] 的启发,它通过多头注意力的堆叠层重建句子中的掩码标记,我们提出了全局局部注意变换器 (GLAT),它以带有掩码节点的图作为输入,并重建丢失的节点。 图 2 说明了 GLAT 的工作原理。 给定一个输入场景图 G P ,我们将节点 i 表示为 one-hot 向量 x i(0) ,其中包括实体和谓词类别,以及一个特殊的 MASK 类。 出于符号目的,我们将节点表示堆叠为矩阵X (0) 的行。
图2 提议的全局局部注意力变换器 (GLAT) 及其训练框架:我们用局部注意力头增强变换器,以帮助它们在节点嵌入中编码场景图的结构。 解码器获取忐忑的场景图的嵌入,并在无法访问图像的情况下重建正确的场景图。 请注意,此图仅显示了图 1 中所示的整体管道的常识块
GLAT 将 X(0) 作为输入,通过对结构和上下文进行编码来表示每个节点。 为此,它在输入节点上应用了 L 层多头注意力。 每层 l 通过在该层注意力头的连接输出上应用线性层来创建新的节点表示 X (l) 。 更具体地说,
其中 H l 是第 l 层的注意力头集[李12] ,W l 和 b l 是该层的可训练融合权重和偏差,并且串联沿列操作。
我们使用两种类型的注意力头,即全局和局部。每个节点可以通过全局注意力来关注所有其他节点,而通过局部注意力只能关注它的邻居。我们根据它们使用的边缘类型进一步划分局部头部,以区分主语和宾语与谓词交互的方式,反之亦然。因此,我们可以这样写:
每个子集中的所有头部都是相同的,除了它们具有独立初始化和训练的不同参数。每个全局头 h G 都作为一个典型的自注意力运行:
其中 q、k、v 是查询、键和值头,每个都是完全连接的网络,通常(但不一定)具有单个线性层。局部注意力是相同的,除了查询只能与其直接邻居节点的键进行交互。例如在主语头部中,
其中 A s 是主语边缘的邻接矩阵,从每个谓词到它的主语之间为 1,反之亦然,其他地方为 0。我们类似地定义对象边缘的 Ao 和 h LO。
一旦我们获得了每个节点 i 的上下文化、结构感知表示 xi(L),我们设计了一个简单的解码器来生成输出场景图 GC,使用一个将每个节点分类为实体或谓词类的全连接网络,以及另一个完全连接的网络。将每对节点分类为边类型(主体、对象或无边)的连接网络。我们端到端地训练编码器和解码器,方法是将噪声随机添加到来自 Visual Genome[李13] 的带注释的场景图,将噪声图提供给 GLAT,重建节点和边,并在扰动前将每个与原始场景图进行比较。我们在节点和边分类器上使用两个交叉熵损失项来训练网络。包括扰动过程[李14] 在内的训练细节在 4.1 节中进行了解释。
3.2 Fusing Perception and Commonsense
感知和常识模型均使用分类器预测输出节点类别,该分类器通过对其 logits 应用 softmax 来计算所有类别的概率分布。 选择概率最高的类别并为其分配与 softmax 概率相等的置信度分数。 更具体地说,来自 G P 的节点 i 有一个logit[李15] 向量 L i P 具有 | Ce | 或 | Cp | 维度取决于它是实体节点还是谓词节点。 类似地,来自G C 的节点 i 有一个对数向量 Li C 。 请注意,这两个节点对应于图像中的同一实体或谓词,因为 GLAT 不会更改节点的顺序。 那么每个节点的置信度可以写为 并且类似地 q i C 被定义为给定 L i C 。
融合模块采用每个 G P节点和 G C 的对应节点,并为该节点计算一个新的对数向量,作为 Li P 和 Li C 的加权平均值。 权重决定了每个模型在最终预测中的贡献,因此必须与每个模型的置信度成正比。 因此,我们计算融合 logits 为:
最后,在 L i F 上应用 softmax 来计算节点 i 的最终分类分布。
4、实验
5 Conclusion
我们提出了第一个从场景图语料库中自动学习视觉常识的方法。我们的方法通过新颖的自我监督培训策略学习结构化常识模式,而不是简单的共发生统计。我们独特的局部注意头增强变压器的方法明显优于变压器,以及广泛使用的基于图形的模型,如图卷积网。此外,我们提出了一种新的场景图生成架构,该架构由感知和常识两个单独的模型组成,它们有不同的训练,可以在不确定的情况下相互补充,提高了整体鲁棒性。为此,我们提出了一种融合机制,根据这两个模型的自信心将它们的输出结合起来,并表明我们的模型正确地决定了何时信任其感知,何时依靠其常识。实验显示了我们生成场景图的方法的有效性,并鼓励今后的工作在其他计算机视觉任务中应用相同的方法。[李16]