apache doris的一些重点笔记,参数实践调优
参数调优:
FE参数:

这里设置为: 3-5s
bdbje_replica_ack_timeout_second
这里设置为:20
==================================================
1,命令
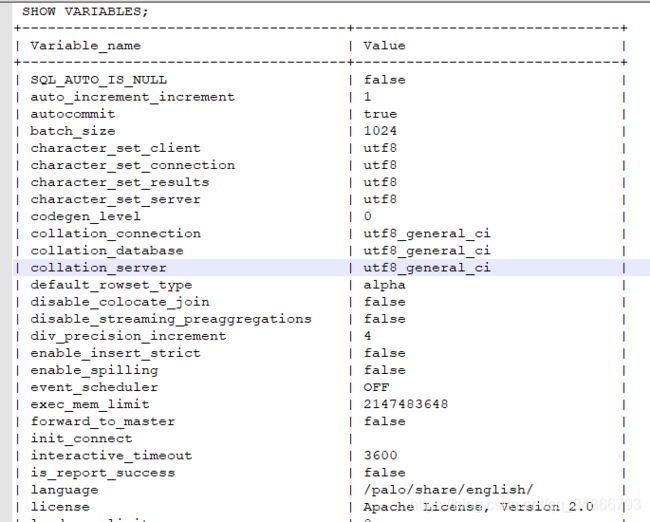
SHOW VARIABLES;
show routine load;
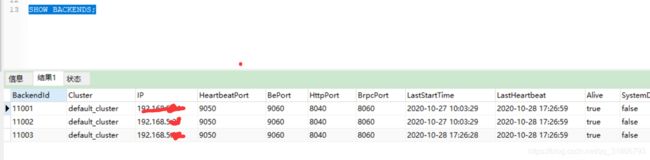
SHOW BACKENDS;
HELP ALTER TABLE;
Name: 'ALTER TABLE'
Description:
该语句用于对已有的 table 进行修改。如果没有指定 rollup index,默认操作 base index。
该语句分为三种操作类型: schema change 、rollup 、partition
这三种操作类型不能同时出现在一条 ALTER TABLE 语句中。
其中 schema change 和 rollup 是异步操作,任务提交成功则返回。之后可使用 SHOW ALTER 命令查看进度。
partition 是同步操作,命令返回表示执行完毕。
语法:
ALTER TABLE [database.]table
alter_clause1[, alter_clause2, ...];
alter_clause 分为 partition 、rollup、schema change、rename 和index五种。
partition 支持如下几种修改方式
1. 增加分区
语法:
ADD PARTITION [IF NOT EXISTS] partition_name
partition_desc ["key"="value"]
[DISTRIBUTED BY HASH (k1[,k2 ...]) [BUCKETS num]]
注意:
1) partition_desc 支持一下两种写法:
* VALUES LESS THAN [MAXVALUE|("value1", ...)]
* VALUES [("value1", ...), ("value1", ...))
1) 分区为左闭右开区间,如果用户仅指定右边界,系统会自动确定左边界
2) 如果没有指定分桶方式,则自动使用建表使用的分桶方式
3) 如指定分桶方式,只能修改分桶数,不可修改分桶方式或分桶列
4) ["key"="value"] 部分可以设置分区的一些属性,具体说明见 CREATE TABLE
2. 删除分区
语法:
DROP PARTITION [IF EXISTS] partition_name
注意:
1) 使用分区方式的表至少要保留一个分区。
2) 执行 DROP PARTITION 一段时间内,可以通过 RECOVER 语句恢复被删除的 partition。详见 RECOVER 语句
3. 修改分区属性
语法:
MODIFY PARTITION partition_name SET ("key" = "value", ...)
说明:
1) 当前支持修改分区的下列属性:
- storage_medium
- storage_cooldown_time
- replication_num
— in_memory
2) 对于单分区表,partition_name 同表名。
rollup 支持如下几种创建方式:
1. 创建 rollup index
语法:
ADD ROLLUP rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)]
properties: 支持设置超时时间,默认超时时间为1天。
例子:
ADD ROLLUP r1(col1,col2) from r0
1.2 批量创建 rollup index
语法:
ADD ROLLUP [rollup_name (column_name1, column_name2, ...)
[FROM from_index_name]
[PROPERTIES ("key"="value", ...)],...]
例子:
ADD ROLLUP r1(col1,col2) from r0, r2(col3,col4) from r0
1.3 注意:
1) 如果没有指定 from_index_name,则默认从 base index 创建
2) rollup 表中的列必须是 from_index 中已有的列
3) 在 properties 中,可以指定存储格式。具体请参阅 CREATE TABLE
2. 删除 rollup index
语法:
DROP ROLLUP rollup_name [PROPERTIES ("key"="value", ...)]
例子:
DROP ROLLUP r1
2.1 批量删除 rollup index
语法:DROP ROLLUP [rollup_name [PROPERTIES ("key"="value", ...)],...]
例子:DROP ROLLUP r1,r2
2.2 注意:
1) 不能删除 base index
2) 执行 DROP ROLLUP 一段时间内,可以通过 RECOVER 语句恢复被删除的 rollup index。详见 RECOVER 语句
schema change 支持如下几种修改方式:
1. 向指定 index 的指定位置添加一列
语法:
ADD COLUMN column_name column_type [KEY | agg_type] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
注意:
1) 聚合模型如果增加 value 列,需要指定 agg_type
2) 非聚合模型(如 DUPLICATE KEY)如果增加key列,需要指定KEY关键字
3) 不能在 rollup index 中增加 base index 中已经存在的列
如有需要,可以重新创建一个 rollup index)
2. 向指定 index 添加多列
语法:
ADD COLUMN (column_name1 column_type [KEY | agg_type] DEFAULT "default_value", ...)
[TO rollup_index_name]
[PROPERTIES ("key"="value", ...)]
注意:
1) 聚合模型如果增加 value 列,需要指定agg_type
2) 非聚合模型如果增加key列,需要指定KEY关键字
3) 不能在 rollup index 中增加 base index 中已经存在的列
(如有需要,可以重新创建一个 rollup index)
3. 从指定 index 中删除一列
语法:
DROP COLUMN column_name
[FROM rollup_index_name]
注意:
1) 不能删除分区列
2) 如果是从 base index 中删除列,则如果 rollup index 中包含该列,也会被删除
4. 修改指定 index 的列类型以及列位置
语法:
MODIFY COLUMN column_name column_type [KEY | agg_type] [NULL | NOT NULL] [DEFAULT "default_value"]
[AFTER column_name|FIRST]
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]
注意:
1) 聚合模型如果修改 value 列,需要指定 agg_type
2) 非聚合类型如果修改key列,需要指定KEY关键字
3) 只能修改列的类型,列的其他属性维持原样(即其他属性需在语句中按照原属性显式的写出,参见 example 8)
4) 分区列不能做任何修改
5) 目前支持以下类型的转换(精度损失由用户保证)
TINYINT/SMALLINT/INT/BIGINT 转换成 TINYINT/SMALLINT/INT/BIGINT/DOUBLE。
TINTINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE/DECIMAL 转换成 VARCHAR
VARCHAR 支持修改最大长度
VARCHAR 转换成 TINTINT/SMALLINT/INT/BIGINT/LARGEINT/FLOAT/DOUBLE
VARCHAR 转换成 DATE (目前支持"%Y-%m-%d", "%y-%m-%d", "%Y%m%d", "%y%m%d", "%Y/%m/%d, "%y/%m/%d"六种格式化格式)
DATETIME 转换成 DATE(仅保留年-月-日信息, 例如: `2019-12-09 21:47:05` <--> `2019-12-09`)
DATE 转换成 DATETIME(时分秒自动补零, 例如: `2019-12-09` <--> `2019-12-09 00:00:00`)
FLOAT 转换成 DOUBLE
INT 转换成 DATE (如果INT类型数据不合法则转换失败,原始数据不变)
6) 不支持从NULL转为NOT NULL
5. 对指定 index 的列进行重新排序
语法:
ORDER BY (column_name1, column_name2, ...)
[FROM rollup_index_name]
[PROPERTIES ("key"="value", ...)]
注意:
1) index 中的所有列都要写出来
2) value 列在 key 列之后
6. 修改table的属性,目前支持修改bloom filter列, colocate_with 属性和dynamic_partition属性,replication_num和default.replication_num属性
语法:
PROPERTIES ("key"="value")
注意:
也可以合并到上面的schema change操作中来修改,见下面例子
rename 支持对以下名称进行修改:
1. 修改表名
语法:
RENAME new_table_name;
2. 修改 rollup index 名称
语法:
RENAME ROLLUP old_rollup_name new_rollup_name;
3. 修改 partition 名称
语法:
RENAME PARTITION old_partition_name new_partition_name;
bitmap index 支持如下几种修改方式
1. 创建bitmap 索引
语法:
ADD INDEX index_name (column [, ...],) [USING BITMAP] [COMMENT 'balabala'];
注意:
1. 目前仅支持bitmap 索引
1. BITMAP 索引仅在单列上创建
2. 删除索引
语法:
DROP INDEX index_name;
Examples:
[table]
1. 修改表的默认副本数量, 新建分区副本数量默认使用此值
ATLER TABLE example_db.my_table
SET ("default.replication_num" = "2");
2. 修改单分区表的实际副本数量(只限单分区表)
ALTER TABLE example_db.my_table
SET ("replication_num" = "3");
[partition]
1. 增加分区, 现有分区 [MIN, 2013-01-01),增加分区 [2013-01-01, 2014-01-01),使用默认分桶方式
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2014-01-01");
2. 增加分区,使用新的分桶数
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
DISTRIBUTED BY HASH(k1) BUCKETS 20;
3. 增加分区,使用新的副本数
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES LESS THAN ("2015-01-01")
("replication_num"="1");
4. 修改分区副本数
ALTER TABLE example_db.my_table
MODIFY PARTITION p1 SET("replication_num"="1");
5. 删除分区
ALTER TABLE example_db.my_table
DROP PARTITION p1;
6. 增加一个指定上下界的分区
ALTER TABLE example_db.my_table
ADD PARTITION p1 VALUES [("2014-01-01"), ("2014-02-01"));
[rollup]
1. 创建 index: example_rollup_index,基于 base index(k1,k2,k3,v1,v2)。列式存储。
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index(k1, k3, v1, v2)
PROPERTIES("storage_type"="column");
2. 创建 index: example_rollup_index2,基于 example_rollup_index(k1,k3,v1,v2)
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index2 (k1, v1)
FROM example_rollup_index;
3. 创建 index: example_rollup_index3, 基于 base index (k1,k2,k3,v1), 自定义 rollup 超时时间一小时。
ALTER TABLE example_db.my_table
ADD ROLLUP example_rollup_index(k1, k3, v1)
PROPERTIES("storage_type"="column", "timeout" = "3600");
4. 删除 index: example_rollup_index2
ALTER TABLE example_db.my_table
DROP ROLLUP example_rollup_index2;
[schema change]
1. 向 example_rollup_index 的 col1 后添加一个key列 new_col(非聚合模型)
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT KEY DEFAULT "0" AFTER col1
TO example_rollup_index;
2. 向example_rollup_index的col1后添加一个value列new_col(非聚合模型)
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;
3. 向example_rollup_index的col1后添加一个key列new_col(聚合模型)
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT DEFAULT "0" AFTER col1
TO example_rollup_index;
4. 向example_rollup_index的col1后添加一个value列new_col SUM聚合类型(聚合模型)
ALTER TABLE example_db.my_table
ADD COLUMN new_col INT SUM DEFAULT "0" AFTER col1
TO example_rollup_index;
5. 向 example_rollup_index 添加多列(聚合模型)
ALTER TABLE example_db.my_table
ADD COLUMN (col1 INT DEFAULT "1", col2 FLOAT SUM DEFAULT "2.3")
TO example_rollup_index;
6. 从 example_rollup_index 删除一列
ALTER TABLE example_db.my_table
DROP COLUMN col2
FROM example_rollup_index;
7. 修改 base index 的 col1 列的类型为 BIGINT,并移动到 col2 列后面
ALTER TABLE example_db.my_table
MODIFY COLUMN col1 BIGINT DEFAULT "1" AFTER col2;
8. 修改 base index 的 val1 列最大长度。原 val1 为 (val1 VARCHAR(32) REPLACE DEFAULT "abc")
ALTER TABLE example_db.my_table
MODIFY COLUMN val1 VARCHAR(64) REPLACE DEFAULT "abc";
9. 重新排序 example_rollup_index 中的列(设原列顺序为:k1,k2,k3,v1,v2)
ALTER TABLE example_db.my_table
ORDER BY (k3,k1,k2,v2,v1)
FROM example_rollup_index;
10. 同时执行两种操作
ALTER TABLE example_db.my_table
ADD COLUMN v2 INT MAX DEFAULT "0" AFTER k2 TO example_rollup_index,
ORDER BY (k3,k1,k2,v2,v1) FROM example_rollup_index;
11. 修改表的 bloom filter 列
ALTER TABLE example_db.my_table SET ("bloom_filter_columns"="k1,k2,k3");
也可以合并到上面的 schema change 操作中(注意多子句的语法有少许区别)
ALTER TABLE example_db.my_table
DROP COLUMN col2
PROPERTIES ("bloom_filter_columns"="k1,k2,k3");
12. 修改表的Colocate 属性
ALTER TABLE example_db.my_table set ("colocate_with" = "t1");
13. 将表的分桶方式由 Random Distribution 改为 Hash Distribution
ALTER TABLE example_db.my_table set ("distribution_type" = "hash");
14. 修改表的动态分区属性(支持未添加动态分区属性的表添加动态分区属性)
ALTER TABLE example_db.my_table set ("dynamic_partition_enable" = "false");
如果需要在未添加动态分区属性的表中添加动态分区属性,则需要指定所有的动态分区属性
ALTER TABLE example_db.my_table set ("dynamic_partition.enable" = "true", dynamic_partition.time_unit" = "DAY", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "32");
15. 修改表的 in_memory 属性
ALTER TABLE example_db.my_table set ("in_memory" = "true");
[rename]
1. 将名为 table1 的表修改为 table2
ALTER TABLE table1 RENAME table2;
2. 将表 example_table 中名为 rollup1 的 rollup index 修改为 rollup2
ALTER TABLE example_table RENAME ROLLUP rollup1 rollup2;
3. 将表 example_table 中名为 p1 的 partition 修改为 p2
ALTER TABLE example_table RENAME PARTITION p1 p2;
[index]
1. 在table1 上为siteid 创建bitmap 索引
ALTER TABLE table1 ADD INDEX index_name (siteid) [USING BITMAP] COMMENT 'balabala';
2. 删除table1 上的siteid列的bitmap 索引
ALTER TABLE table1 DROP INDEX index_name;
系统变量参考:

命令执行参考:
show routine load;
SELECT count(1) from order_detail2;
SELECT a.id,b.id FROM order_detail a JOIN order_detail2 b WHERE a.order_id = b.order_id where a.order_price < 10000;
SET GLOBAL parallel_fragment_exec_instance_num = 6
SHOW VARIABLES;
SET GLOBAL parallel_exchange_instance_num = -1
SET GLOBAL exec_mem_limit = 4 * 1024 * 1024 * 1024;
doris 的join测试 问题
1)当我2个表join的时候一直没有结果
select count(1) FROM (SELECT a.id FROM order_detail a JOIN [shuffle] order_detail2 b WHERE a.id = b.id) AS bb;
2)换了个表
select count(1) FROM (SELECT a.id FROM order_detail a JOIN [shuffle] order_info b WHERE a.id = b.id) AS bb;
计算在2s左右。

3)原因:了解得知,第一个join,虽然是2个表,但是表数据结构跟数据都是一样的(我为了图省事,复制的部分数据)
4) 全量join 基本 OOM或者超时,或者卡死。
SELECT a.id FROM order_detail a JOIN [shuffle] order_info b WHERE a.id = b.id