Hadoop 全分布安装部署
Hadoop 全分布安装部署:
目录
Hadoop 全分布安装部署:
一: 安装前准备
二: 配置jdk
三: 部署hadoop集群
四: 启动hadoop集群
五: 总结
VMWare上安装liunx系统: 装虚拟机及linux系统
hadoop伪分布安装请移步:hadoop伪分布安装
一: 安装前准备
安装工具准备: 都已经在hadoop伪分布中准备齐全,自取
hadoop伪分布安装
1. 确保已经安装好三台虚拟机及linux系统
2. 确定那一台为主节点,剩余两台为从节点
3. 都需要关闭防火墙
systemctl status firewalld.service 【查看状态】
systemctl start firewalld.service 【开启】
systemctl stop firewalld.service 【关闭】
systemctl disable firewalld.service 【关闭开机自启】
4. 设置主机名【我的三台演示主机名分别设置为: bigdata1(主节点) , bigdata2,bigdata3】
5. 配置host
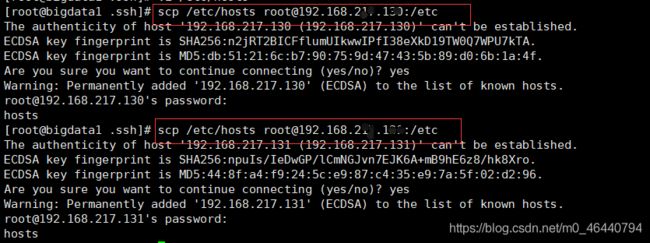
5.1 主节点输入配置 hosts 文件: vi /etc/hosts
5.2 把三台机器的ip地址和主机名添加进去
5.3 将主节点hosts文件拷贝到其他子节点

6. 配置免密登录【方便后续远程拷贝数据,快速操作集群】
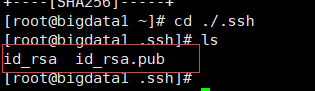
1. 每台机器上输入: ssh-keygen -t rsa,生成两个文件,一个公钥(id_rsa.pub),一个私钥(id_rsa)
2. 将公匙上传到目标机器
注意:在每台机器上都要输入:【分别将各自的公匙上传到另外两台机器】
ssh-copy-id 上传到的机器主机名
3. 测试无密码登录挑转到其他机器: ssh 主机名
二: 配置jdk
主节点进行以下配置: 【实质三台机器都要进行配置jdk,但是只用在主节点配置,后拷贝到其他节点即可】
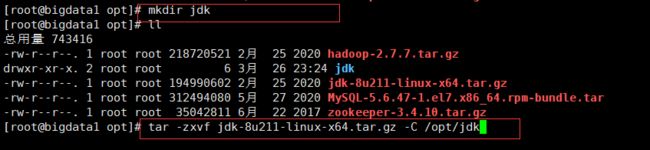
1. 在/opt下创建目录jdk,将jdk解压在该文件下
2. 在/etc/profile目录下配置环境变量和启动程序,输入:vi /etc/profile 【按 i 进入编辑模式,编辑完后先按esc 再输入 :wq 保存并退出】
#JAVA ENV
export JAVA_HOME=/jdk解压目录
export PATH=$JAVA_HOME/bin:$PATH

3. 刷新使得编辑文件生效,输入: source /etc/profile
4. 输入查看java环境是否安装成功: java -version

三: 部署hadoop集群
1. 只配置主节点,最后将配置好的jdk,hadoop数据拷贝到子节点即可。
2. hadoop全分布环境需要配置8个配置文件
hadoop-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
core-site.xml //用于指定namenode节点的位置,Hadoop运行时产生文件所存储的mulu
hdfs-site.xml //指定hdfs的副本数和secondarynamenode的位置
slaves //用于指定组成机器的主机名
yarn-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
yarn-site.xml //用于指定reducer获取数据的方式、指定resourcemanager的位置
mapred-env.sh //用于修改JAVA_HOME后的目录,改成实际本机jdk所在目录位置
mapred-site.xml //指定mr在yarn上运行
3. 配置hadoop环境变量
配置hadoop环境【在 /etc/profile 目录下配置,输入:vi /etc/profile,按 i 进入编辑模式,编辑完后先按esc 再输入 :wq 保存并退出】
#HADOOP ENV
export HADOOP_HOME=/hadoop解压目录
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

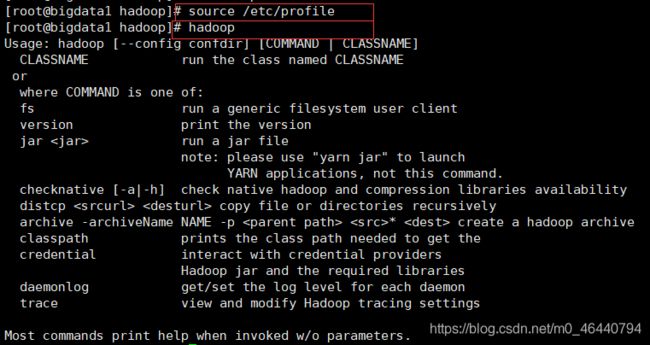
刷新使得文件生效,并查看环境是否配置成功【刷新:source /etc/profile ; 查看是否配置成功:hadoop】
4. 进入hadoop解压目录下的 /etc/hadoop 中

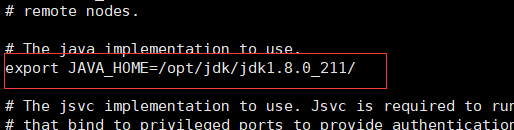
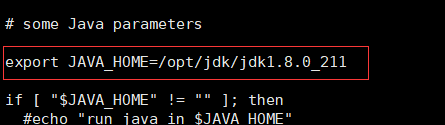
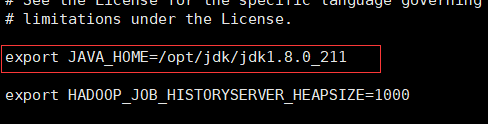
5. 修改以下三个配置文件中对应的jdk安装位置:
- hadoop-env.sh
- yarn-env.sh 【将前面的注释去掉】
- mapred-env.sh 【将前面的注释去掉】
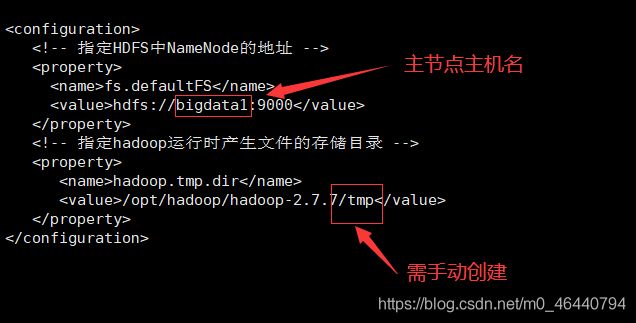
6. 配置core-site.xml文件
fs.defaultFS
hdfs://bigdata1:9000
hadoop.tmp.dir
/opt/hadoop/hadoop-2.7.7/tmp
7. 配置hdfs-site.xml文件
dfs.replication
3
dfs.namenode.secondary.http-address
bigdata1:50090
dfs.permissions
false
8. 配置slave文件
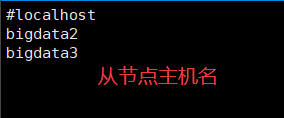
9。 配置mapred-site.xml 【先通过mapred-site.xml.template复制: cp mapred-site.xml.template mapred-site.xml】
mapreduce.framwork.name
yarn

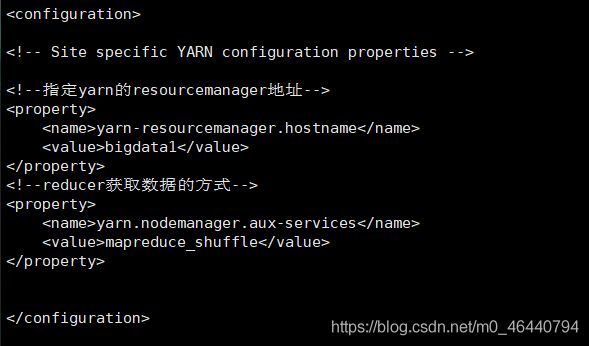
10. 配置yarn-site.xml文件
yarn-resourcemanager.hostname
bigdata1
yarn.nodemanager.aux-services
mapreduce_shuffle
11. 拷贝hadoop安装文件,jdk安装文件,profile文件到从节点
scp -r /要拷贝的目录 root@主机名:/拷贝到的目录
12. 在从节点执行命令使profile文件生效
source /etc/profile
13. 格式化主节点的namenode
- 进入hadoop目录下的bin目录
- 执行: ./hadoop namenode -format
- 成功格式化提示如下:

四: 启动hadoop集群
1. 进入sbin目录下输入启动:
- 执行启动: ./start-all.sh
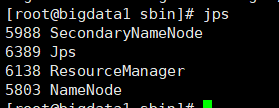
2. 启动成功主节点进程如下:
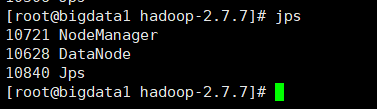
两个从节点进程如下:
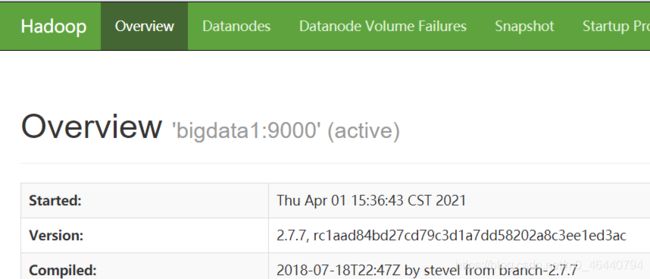
3. 浏览器查看hadoop页面:【切记先关闭防火墙,且在windows端配置ip映射】
主节点:50070
五: 总结
以上就是hadoop的全分布安装部署。
整个过程: 安装三台虚拟机------配置hosts-----配置免密登录-------配置jdk-----配置hadoop(8个配置文件)------格式化namenode------启动hadoop集群
后续将继续给出有关hadoop更多的学习文章。