对话系统-口语理解-意图检测和槽填充:A Co-interactive Transformer for joint Slot Filling and Intent Detection
论文题目:A Co-interactive Transformer for joint Slot Filling and Intent Detection

原论文地址
PyTorch代码
论文精简版-PPT
1.背景
意图检测和槽填充是构建口语理解(SLU)系统的两个主要任务。
以前的研究要么用 多 任 务 框 架 隐 式 地 对 两 个 任 务 进 行 建 模 {\color{Red}多任务框架隐式地对两个任务进行建模} 多任务框架隐式地对两个任务进行建模,要么 只 考 虑 从 意 图 到 槽 的 单 个 信 息 流 {\color{Red}只考虑从意图到槽的单个信息流} 只考虑从意图到槽的单个信息流。
先前的方法都没有在统一框架中同时对两个任务之间的双向连接进行建模。
针对以上问题,作者提出了 Co-Interactive Transformer,考虑了两个任务之间的交叉影响。 作者没有采用vanilla Transformer中的self-attention机制,而是提出了一个协同交互模块,通过在两个相关任务之间建立双向连接来考虑交叉影响,其中slot和intent可以参与到相应的任务中。
2.方法论
现有的联合模型可以分为两大类:
1. 采 用 具 有 共 享 编 码 器 的 多 任 务 框 架 解 决 槽 填 充 和 意 图 识 别 \color{Red}采用具有共享编码器的多任务框架解决槽填充和意图识别 采用具有共享编码器的多任务框架解决槽填充和意图识别
虽然这些模型通过相互增强优于管道模型,但它们只是通过共享参数隐式地建模槽填充和意图识别两任务的关系
2. 明 确 应 用 意 图 信 息 指 导 槽 填 充 任 务 \color{Red}明确应用意图信息指导槽填充任务 明确应用意图信息指导槽填充任务
缺点是只考虑了从意图到槽的单一信息流,并没有考虑槽到意图的信息流。
与普通的 Transformer 不同,本文框架中的核心组件是一个协同交互模块,用于对两个任务之间的关系进行建模,旨在考虑两个任务的交叉影响并提高两个任务。具体来说,在每个协同交互模块中,首先在意图和槽标签上应用 标 签 注 意 力 机 制 \color{Red}标签注意力机制 标签注意力机制来捕获初始显式意图和槽表示,从而提取意图和槽语义信息。其次,意图和槽表示被输入到一个协同交互的注意力层中以进行交互。显式意图表示被视为查询,槽表示被视为获得槽感知意图表示的键和值。同时,显式槽表示被用作查询,意图表示被视为键和值以获得意图感知槽表示。以上这些操作可以建立跨intent和slots的双向连接。潜在的直觉是插槽和意图可以通过协同交互注意力机制关注相应的互信息。
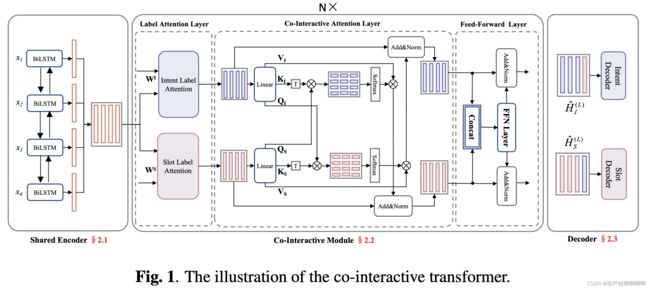
2.1. Shared Encoder共享编码器
共享 E n c o d e r Encoder Encoder: B i L S T M BiLSTM BiLSTM,旨在利用词序中时间特征的优势
输入序列: { x 1 , x 2 , . . . , x n } , n 是 t o k e n \{x_1, x_2, . . . , x_n\},n是 token {x1,x2,...,xn},n是token的数量
B i L S T M BiLSTM BiLSTM 前向和后向读取输入序列,以产生一系列上下文敏感的隐藏状态 H = { h 1 , h 2 , . . . , h n } H=\{h_1, h_2,...,h_n\} H={h1,h2,...,hn} ,通过重复应用递归 h i = B i L S T M ( ϕ e m b ( x i ) , h i − 1 , h i + 1 ) h_i = BiLSTM (\phi^{emb}(x_i), h_{i−1},h_{i+1}) hi=BiLSTM(ϕemb(xi),hi−1,hi+1),其中 ϕ e m b ( ⋅ ) \phi^{emb}(·) ϕemb(⋅)表示嵌入函数。
2.2. Co-Interactive Module协同交互模块
Co-Interactive 模块是框架的核心组件,旨在建立意图检测和槽填充之间的双向连接。
在 vanilla Transformer 的Encoder中,每个子层包括self-attention(自注意力) 和 a feed-forward network (前馈神经网络FFN)组成。 (这里只需关注Encoder部分,Decoder部分是有三个子层,橙色和蓝色的部分)
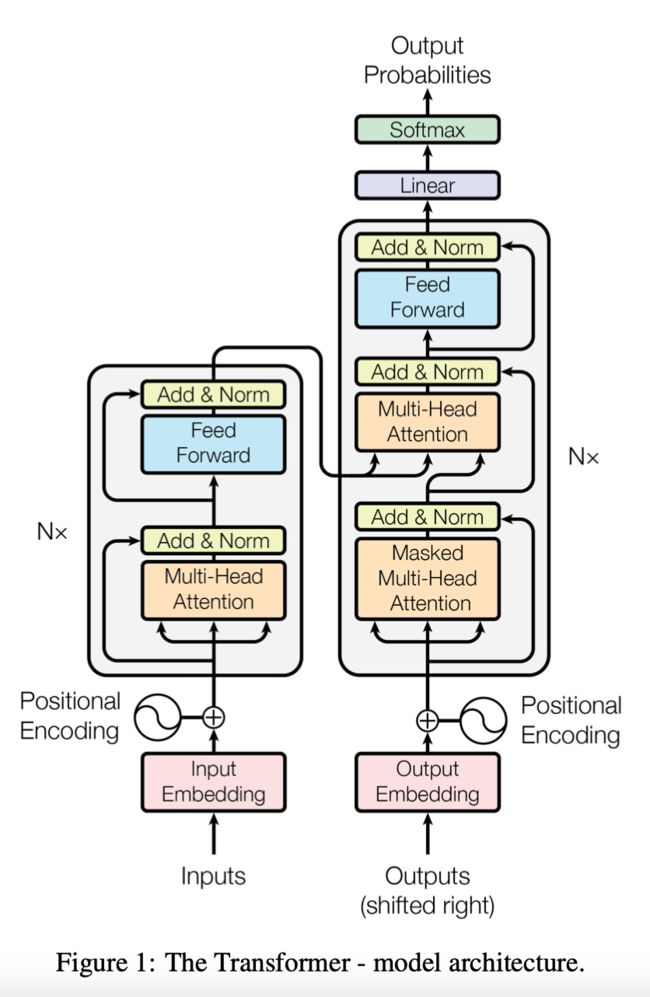
图片来源Attention Is All You Need
协同交互模块包含三部分,分别为:
1.意图和槽标签注意力层来获得明确的意图和槽表示。
2.利用协同交互注意力层而不是自注意力层来显式地对交互进行建模。
3.扩展了基本 FFN,以在隐式方法中进一步融合意图和槽信息。
2.2.1. Intent and Slot Label Attention Layer
用槽填充和意图检测解码层的参数作为槽嵌入矩阵和意图嵌入矩阵。
槽嵌入矩阵: W S ∈ R d × ∣ S l a b e l ∣ \pmb{W}^S\in\mathbb{R}^{d\times|S^{label}|} WWWS∈Rd×∣Slabel∣
意图嵌入矩阵: W I ∈ R d × ∣ I l a b e l ∣ \pmb W^I\in\mathbb{R}^{d\times|I^{label}|} WWWI∈Rd×∣Ilabel∣
其中, d d d表示隐藏层维度, ∣ S l a b e l ∣ , ∣ I l a b e l ∣ |S^{label}|,|I^{label}| ∣Slabel∣,∣Ilabel∣分别表示槽标签和意图标签的数量,
在某种意义上可以看作是标签的分布。
意图和槽表示:
H ∈ R n × d \pmb{H}\in\mathbb{R}^{n\times d} HHH∈Rn×d为 Q ( q u e r y ) Q(query) Q(query), W v ∈ R d × ∣ v l a b e l ∣ ( v ∈ { I o r S } } ) \pmb{W}^v\in\mathbb{R}^{d\times|v^{label}|}(\pmb{v}\in\{I\ or S\}\}) WWWv∈Rd×∣vlabel∣(vvv∈{I orS}})为 K ( k e y ) K(key) K(key)和 V ( v a l u e ) V(value) V(value)
利用上述信息获得带有意图标签注意力的意图表示 H v \pmb{H}_{{v}} HHHv
A = s o f t m a x ( H W v ) (1) \pmb{A}=softmax(\pmb{H}\pmb{W^v})\tag{1} AAA=softmax(HHHWvWvWv)(1)
H v = H + A W v T = H + A t t e n t i o n ( H , W v , W v ) (2) \pmb{H_v}=\pmb{H}+\pmb{AW^v}^{\color{Green}\mathrm T}\\ =\pmb{H}+Attention(\pmb{H},\pmb{W^v},\pmb{W^v})\tag{2} HvHvHv=HHH+AWvAWvAWvT=HHH+Attention(HHH,WvWvWv,WvWvWv)(2)
H I ∈ R n × d \color{Red}\pmb{H_I}\in\mathbb{R}^{n\times d} HIHIHI∈Rn×d, H S ∈ R n × d \color{Red}\pmb{H_S}\in\mathbb{R}^{n\times d} HSHSHS∈Rn×d是 显 式 \color{Red}显式 显式意图表示和槽表示,分别捕获意图和槽语义信息。
2.2.2. Co-Interactive Attention Layer
H S \pmb{H_S} HSHSHS 和 H I \pmb{H_I} HIHIHI 进一步用于下一个协同交互注意层,以建模两个任务之间的交互。 这使得槽表示在关联意图的指导下更新,意图表示在关联槽的指导下更新,实现了与两个任务的双向连接。
- Intent-Aware Slot Representation
与 vanilla Transformer 相同,使用不同的线性投影将矩阵将 H S \pmb{H_S} HSHSHS 和 H I \pmb{H_I} HIHIHI 映射到查询 ( Q S , Q I ) \pmb{(Q_S,Q_I)} (QS,QI)(QS,QI)(QS,QI)、键 ( K S , K I ) \pmb{(K_S,K_I)} (KS,KI)(KS,KI)(KS,KI)和值 ( V S , V I ) \pmb{(V_S,V_I)} (VS,VI)(VS,VI)(VS,VI)矩阵。 为 了 获 得 包 含 相 应 意 图 信 息 的 槽 表 示 , 将 槽 和 其 密 切 相 关 的 意 图 对 齐 \color{Red}为了获得包含相应意图信息的槽表示,将槽和其密切相关的意图对齐 为了获得包含相应意图信息的槽表示,将槽和其密切相关的意图对齐。 将 Q S \pmb{Q_S} QSQSQS 视为查询,将 K I \pmb{K_I} KIKIKI视为键,将 V I \pmb{V_I} VIVIVI 视为值。 输出是值的加权总和:
C S = s o f t m a x ( Q S K I T d k ) V I (3) \pmb{C_S}=softmax(\frac{\pmb{Q_S}\pmb{K_I^\mathrm T}}{\sqrt{d_k}})\pmb{V_I}\tag{3} CSCSCS=softmax(dkQSQSQSKITKITKIT)VIVIVI(3)
H S ′ = L N ( H S + C S ) (4) \pmb{H}^\prime_S=LN(\pmb{H_S+\pmb{C_S}})\tag{4} HHHS′=LN(HS+CSCSCSHS+CSCSCSHS+CSCSCS)(4)
其中, L N LN LN表示层归一化函数。
- Slot-Aware Intent Representation
同上,将 Q I \pmb{Q_I} QIQIQI 视为查询,将 K S \pmb{K_S} KSKSKS视为键,将 V S \pmb{V_S} VSVSVS 视为值求得 H I ′ \pmb{H}^\prime_{\pmb{I}} HHHIII′。
H S ′ ∈ R n × d \color{Red}\pmb{H}^\prime_S\in\mathbb{R}^{n\times d} HHHS′∈Rn×d和 H I ′ ∈ R n × d \color{Red}\pmb{H}^\prime_I\in\mathbb{R}^{n\times d} HHHI′∈Rn×d分别利用了相应的槽和意图信息。
残差连接,可以有效的改善深层模型中梯度消失的问题。
Layer Normalization,可以加速模型的收敛速度。当我们使用梯度下降法做优化时,随着网络深度的增加,数据的分布会不断发生变化,为了保证数据特征分布的稳定性,加入层归一化。
2.2.3. Feed-forward Network Layer
扩展前馈网络层以 隐 式 \color{Red}隐式 隐式融合意图和槽信息。 首先连接 H I ′ \pmb{H}^\prime_I HHHI′ 和 H S ′ \pmb{H}^\prime_S HHHS′以联合槽和意图信息:
H I S = H I ′ ⊕ H S ′ (5) \pmb{H_{IS}}=\pmb{H}^\prime_I\oplus\pmb{H}^\prime_S\tag{5} HISHISHIS=HHHI′⊕HHHS′(5)
其中, H I S = { h I S 1 , h I S 2 , . . . , h I S n } \pmb{H_{IS}}=\{\pmb{h}^1_{ IS},\pmb{h}^2_{IS},...,\pmb{h}^n_{IS}\} HISHISHIS={hhhIS1,hhhIS2,...,hhhISn}
每个token用词特征:
h ( f , t ) t = h I S t − 1 ⊕ h I S t ⊕ h I S t + 1 (6) \pmb{h}_{(f,t)}^t=\pmb{h}^{t-1}_{IS}\oplus\pmb{h}^t_{IS}\oplus\pmb{h}^{t+1}_{IS}\tag{6} hhh(f,t)t=hhhISt−1⊕hhhISt⊕hhhISt+1(6)
前馈网络层 ( F N N ) (FNN) (FNN)融合意图和槽信息:
F F N ( H ( f , t ) ) = m a x ( 0 , H ( f , t ) W 1 + b 1 ) W 2 + b 2 (7) FFN(\pmb{H}_{(f,t)})=max(0,\pmb{H}_{(f,t)}\pmb{W}_1+b_1)\pmb{W}_2+b_2\tag{7} FFN(HHH(f,t))=max(0,HHH(f,t)WWW1+b1)WWW2+b2(7)
H I ^ = L N ( H I ′ + F F N ( H ( f , t ) ) ) (8) \hat{\pmb H_I}=LN(\pmb{H}^\prime_I+FFN(\pmb{H}_{(f,t)}))\tag{8} HHHI^=LN(HHHI′+FFN(HHH(f,t)))(8)
H S ^ = L N ( H S ′ + F F N ( H ( f , t ) ) ) (9) \hat{\pmb H_S}=LN(\pmb{H}^\prime_S+FFN(\pmb{H}_{(f,t)}))\tag{9} HHHS^=LN(HHHS′+FFN(HHH(f,t)))(9)
其中, H ( f , t ) = ( h ( f , t ) 1 , h ( f , t ) 2 , . . . , h ( f , t ) t ) \pmb{H}_{(f,t)}=(\pmb{h}_{(f,t)}^1,\pmb{h}_{(f,t)}^2,...,\pmb{h}_{(f,t)}^t) HHH(f,t)=(hhh(f,t)1,hhh(f,t)2,...,hhh(f,t)t), H I ^ \color{Red}\hat{\pmb H_I} HHHI^ 和 H S ^ \color{Red}\hat{\pmb H_S} HHHS^是获得的更新的意图和槽信息,分别对齐相应的槽和意图特征。
2.3. Decoder for Slot Filling and Intent Detection
为了在两个任务之间进行充分的交互,应用了一个具有多层的堆叠式协同交互注意网络。
堆叠L层后,得到最终更新的槽和意图表示 H ^ I ( L ) = ( h ^ ( I , 1 ) ( L ) , H ^ ( I , 2 ) ( L ) , . . . , H ^ ( I , n ) ( L ) ) \hat{\pmb H}_I^{(L)}=(\hat{\pmb h}_{(I,1)}^{(L)},\hat{\pmb H}_{(I,2)}^{(L)},...,\hat{\pmb H}_{(I,n)}^{(L)}) HHH^I(L)=(hhh^(I,1)(L),HHH^(I,2)(L),...,HHH^(I,n)(L)),
H ^ S ( L ) = ( h ^ ( S , 1 ) ( L ) , H ^ ( S , 2 ) ( L ) , . . . , H ^ ( S , n ) ( L ) ) \hat{\pmb H}_S^{(L)}=(\hat{\pmb h}_{(S,1)}^{(L)},\hat{\pmb H}_{(S,2)}^{(L)},...,\hat{\pmb H}_{(S,n)}^{(L)}) HHH^S(L)=(hhh^(S,1)(L),HHH^(S,2)(L),...,HHH^(S,n)(L))
意图检测:
因为前面输出的 H ^ I ( L ) , H ^ S ( L ) \hat{\pmb H}_I^{(L)},\hat{\pmb H}_S^{(L)} HHH^I(L),HHH^S(L)都是矩阵,但是意图检测需要的是一个向量经过softmax,所以要想办法把矩阵转换成向量。作者这里用的是CNN里面的maxpooling。
在 H ^ I ( L ) \hat{\pmb H}_I^{(L)} HHH^I(L)上应用 m a x p o o l i n g \color{Red}maxpooling maxpooling 操作来获得句子表示 c \pmb c ccc, c \pmb c ccc作为意图检测输入:
y ^ I = s o f t m a x ( W I c + b S ) (10) \hat{\pmb y}^I=softmax(\pmb {W^Ic}+\pmb{b_S})\tag{10} yyy^I=softmax(WIcWIcWIc+bSbSbS)(10)
o I = a r g m a x ( y ^ I ) (11) o^I=argmax(\hat{\pmb y}^I)\tag{11} oI=argmax(yyy^I)(11)
针对上面所说举个例子,结果是二分类,所以最后的块只有两种颜色。图中token数量为7,维度为5,3种不同尺寸的卷积核,每种尺寸有两个卷积核,经过一层卷积之后再经过maxpooling层,最后将6个拼接得到一个向量,对向量求softmax。
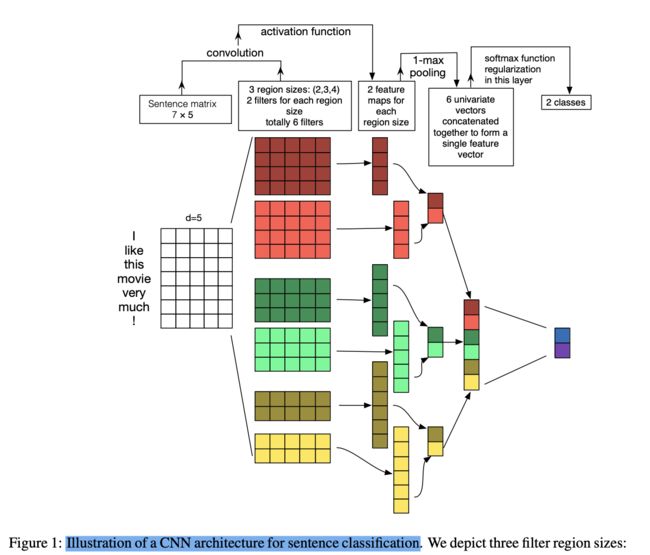
图片来源A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
槽填充:
用标准CRF层建模标签之间的依赖:
O S = W S H ^ S ( L ) + b S (12) \pmb O_S=\pmb W^S\hat{\pmb H}_S^{(L)}+\pmb b_S\tag{12} OOOS=WWWSHHH^S(L)+bbbS(12)
P ( y ^ ∣ O S ) = ∑ i = 1 e x p f ( y i − 1 , y i , O S ) ∑ y ′ ∑ i = 1 e x p f ( y i − 1 ′ , y i ′ , O S ) (13) P(\hat{\pmb y}|\pmb O_S)=\frac{\sum_{i=1}expf(y_{i-1},y_i,\pmb O_S)}{\sum_{y^\prime}\sum_{i=1}expf(y^\prime_{i-1},y^\prime_i,\pmb O_S)}\tag{13} P(yyy^∣OOOS)=∑y′∑i=1expf(yi−1′,yi′,OOOS)∑i=1expf(yi−1,yi,OOOS)(13)
其中, f ( y i − 1 , y i , O S ) f(y_{i-1},y_i,\pmb O_S) f(yi−1,yi,OOOS)计算 y i − 1 y_{i-1} yi−1到 y i y_i yi的转移分数, y ^ \hat{\pmb y} yyy^表示预测的槽标签序列。
3.实验
3.1. 数据集和参数设置
∙ \bullet ∙ 数据集: A T I S {\color{Red}ATIS} ATIS 和 S N I P S {\color{Red}SNIPS} SNIPS
∙ \bullet ∙ 共享编码器和协同交互模块的隐藏神经元个数: 128 {\color{Red}128} 128
∙ \bullet ∙ 数据集: A T I S {\color{Red}ATIS} ATIS 和 S N I P S {\color{Red}SNIPS} SNIPS用 300d GloVe 预训练向量作为初始化嵌入
∙ \bullet ∙ 协同交互模块的数量为 2 {\color{Red}2} 2。
∙ \bullet ∙ L2 正则化为 1 × 1 0 − 6 {\color{Red}1\times10^{−6}} 1×10−6,协同交互模块的丢弃率设置为 0.1 {\color{Red}0.1} 0.1。
∙ \bullet ∙ 使用 A d a m {\color{Red}Adam} Adam优化模型的参数。
∙ \bullet ∙ 使用 F 1 {\color{Red}F1} F1 分数评估槽填充的性能,使用 A c c u r a c y {\color{Red}Accuracy} Accuracy评估意图预测,使用 整 体 准 确 性 {\color{Red}整体准确性} 整体准确性评估句子级语义框架解析。
3.2. 实验结果分析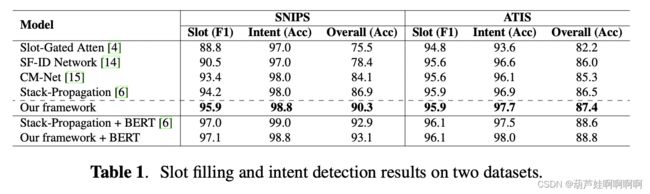
1.与仅利用意图信息来指导槽填充的基线 Slot-Gated 和 Stack-Propagation 相比,作者提出的模型获得了很大的改进。原因是考虑了两个任务之间的交叉影响,其中槽信息可用于改进意图检测。值得注意的是,该模型和 Stack-Propagation 之间的参数大小相同,这进一步验证了该模型的贡献来自双向交互而不是参数因素。
2.SF-ID Network 和 CM-Net 也可以看作是考虑了两个任务之间的相互交互。然而,他们的模型不能同时对交叉影响进行建模,这限制了他们的性能。本文在 SNIPS 和 ATIS 数据集的总体acc 上分别比 CM-Net 高 6.2% 和 2.1%。作者认为原因是作者的框架在一个统一的网络中同时实现了双向连接。
3.本文框架+BERT优于Stack-Propagation+BERT,这验证了作者提出的模型是否基于BERT的有效性。
3.3. 消融实验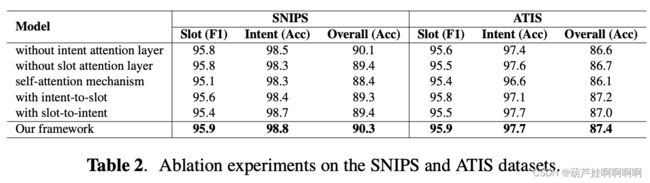
- 显式表示的影响
作者删除了意图注意层并用 H H H 替换 H I H_I HI。这意味着只显式地获得槽表示,没有意图语义信息,将其命名为无意图注意力层。 同样,执行无槽注意力层实验。 结果如表 2 所示,可以观察到槽填充和意图检测性能下降,这表明初始显式意图和槽表示对于两个任务之间的协同交互层至关重要。
也可以观察到作者所提出的框架优于自注意力机制。 原因是自注意力机制仅隐式地对交互进行建模,而作者的协同交互层可以显式地考虑两个任务之间的交叉影响。
- 协同交互注意力 vs. 自注意力机制
通过使用 vanilla Transformer 中的 self-attention 层而不是该框架中的协同交互层,这可以看作是两个任务之间没有显式交互。具体来说,将来自标签注意层的 H S H_S HS 和 H I H_I HI 输出连接为输入,将其输入到自我注意模块中。结果如表 2 所示,可以看到本文的框架优于自注意力机制。原因是自注意力机制仅隐式地对交互进行建模,而协同交互层可以明确地考虑两个任务之间的交叉影响。
- 双向连接 vs. 单向连接
只保留从意图到槽或槽到意图的信息流的一个方向。 通过仅使用一种类型的信息表示表示作为查询来参与另一种信息表示来实现这一点,将其命名为“intent-to-slot”和“slot-to-intent”。 从表 2 中的结果来看,作者的框架在意图到插槽和插槽到意图方面的表现都更好。 可将其归因于对槽填充和意图检测之间的相互交互进行建模可以以相互的方式增强这两个任务的原因。 相比之下,他们的模型只考虑了信息流单一方向的交互。
4.总结
提出了一种用于联合模型槽填充和意图检测的协同交互Transformer,它能够充分利用相互交互的知识。 在两个数据集上的实验表明了所提出模型的有效性,我们的框架达到了最先进的性能。