PyTorch搭建卷积神经网络(ResNet-50网络)进行图像分类实战(附源码和数据集)
需要数据集和源码请点赞关注收藏后评论区留言~~~
一、实验数据准备
我们使用的是MIT67数据集,这是一个标准的室内场景检测数据集,一个有67个室内场景,每类包括80张训练图片和20张测试图片 读者可通过以下网址下载
但是数据集较大,下载花费时间较长,所以建议私信我发给你们
数据集
将下载的数据集解压,主要使用Image文件夹,这个文件夹一共包含6700张图片,还有它们标签的txt文件
大体流程分为以下几步
二、数据预处理和准备
1:数据集的读取
2:重载data.Dataset类
3:transforms数据预处理
三、模型构建
1:ResNet-50网络
网络结构图如下
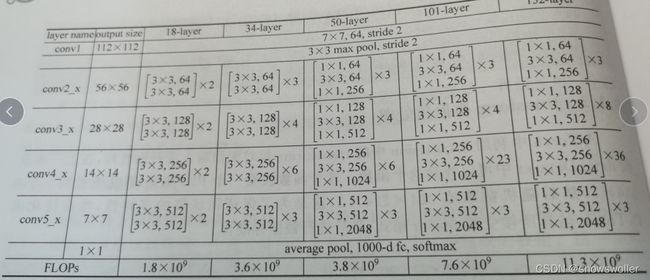
2:bottleneck的实现
结构图如下

3:ResNet-50卷积层定义
4:forward函数的实现
5:预训练参数装载
四、模型训练与结果评估
1:训练类的实现
2:优化器的定义
3:学习率衰减
4:训练
训练过程如下

最后 部分代码如下
1.py
import torch
from torch.autograd import Variable as V
import torchvision.models as models
from torchvision import transforms as trn
from torch.nn import functional as F
import os
import numpy as np
from mymodels import *
from PIL import Image
import torch.utils.data as data
from torch.utils.data import DataLoader
from utils import *
tmp_dir = '/home/yyh/tmpmit67'
import torch.optim as optim
import matplotlib.pyplot as plt
import time
import json
def get_im_list(im_dir, file_path):
im_list = []
im_labels = []
im_origin = []
with open(file_path, 'r') as fi:
for line in fi:
im_list.append(im_dir + line.split()[0])
im_labels.append(int(line.split()[-1]))
im_origin.append(line.split()[0])
array = line.split('/')
return im_list, im_labels, im_origin
ate(fi):
sname = line.strip()
sdict[sid] = sname
return sdict
_sdict = sun397_sdict()
arch = 'resnet50'
# load the pre-trained weights
model_file = '%s_places365.pth.tar' % arch
if not os.access(model_file, os.W_OK):
weight_url = 'http://places2.csail.mit.edu/models_places365/' + model_file
os.system('wget ' + weight_url)
model = resnet50(num_classes=365)
checkpoint = torch.load(model_file, map_location=lambda storage, loc: storage)
state_dict = {str.replace(k,'module.',''): v for k,v in checkpoint['state_dict'].items()}
model.load_state_dict(state_dict)
model.fc = torch.nn.Linear(2048,67)
model.eval()
"""
model = resnet50(num_classes=67)
pretrained = torch.load("/home/yyh/fineTune/mit67_place/model_epoch_30.pth").module
state_dict = pretrained.state_dict()
model.load_state_dict(state_dict)
model.eval()
"""
# load the image transformer
transform_train = trn.Compose([
trn.Scale(256),
trn.RandomSizedCrop(224),
trn.RandomHorizontalFlip(),
trn.ToTensor(),
trn.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
transform_test = trn.Compose([
trn.Scale(256),
trn.CenterCrop(224),
trn.ToTensor(),
trn.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# load the class label
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(data.Dataset):
def __init__(self, images, labels,loader=default_loader,transform=None):
self.images = images
self.labels = labels
self.loader = loader
self.transform = transform
def __getitem__(self, index):
img, target = self.images[index], self.labels[index]
#print(img)
img = self.loader(img)
if self.transform is not None:
img = self.transform(img)
#print(img)
return img, target
def __len__(self):
return len(self.images)
imdir = r'C:\Users\Admin\Desktop\MIT67\Images/'
train_file = 'C:\Users\Admin\Desktop\MIT67\TrainImages.label'
test_file = 'C:\Users\Admin\Desktop\MIT67\TestImages.label'
#train_file = test_file
train_list, train_labels,img_path= get_im_list(imdir, train_file)
test_list, test_labels ,img_path_2= get_im_list(imdir, test_file)
batch_size = 16
net = model
net.cuda()
#print(test_js)
for i in range(0, len(train_list)):
path = img_path[i]
save = []
print(path)
json_name = (path.replace("/", "_")).replace(".jpg", ".json")
f_train = open("C:\Users\Admin\Desktop\rgbd_data\annotated_area/" + json_name)
train_js = json.load(f_train)
if len(train_js) == 0:
train_js.append( {"classname":"unknown","bbox":[0,0,223,223],"score":1})
for j in range(0, len(train_js)):
data, target = train_list[i], train_labels[i]
data = Image.open(data).convert('RGB')
json_data = train_js[j]["bbox"]
data = data.resize((224, 224), Image.ANTIALIAS)
print(json_data)
data = data.crop([json_data[0], json_data[1], json_data[2], json_data[3]])
data = data.resize((224, 224), Image.ANTIALIAS)
data = transform_test(data)
newdata = torch.zeros(1, 3, 224, 224)
newdata[0] = data
data = Variable(newdata).cuda()
output, record = net(data)
data = record.cpu().detach().numpy()
save.append(data)
data = save[0]
for j in range(1, len(train_js)):
data += save[j]
data = data / len(train_js)
# print(data)
# target = Variable(target).cuda()
# print(output)
# print(output["avgpool"].cpu().shape)
root = "/home/yyh/PycharmProjects/feature_extractor/loc_224_npy/" + path.split("/")[0]
if not os.path.exists(root):
os.makedirs(root)
dir = "/home/yyh/PycharmProjects/feature_extractor/loc_224_npy/" + path.replace(".jpg",".npy")
np.save(dir, data)
print(i)
for i in range(0, len(test_list)):
path = img_path_2[i]
save = []
print(path)
json_name = (path.replace("/", "_")).replace(".jpg", ".json")
f_test = open("/home/yyh/rgbd_data/annotated_area/" + json_name)
test_js = json.load(f_test)
if len(test_js) == 0:
test_js.append( {"classname":"unknown","bbox":[0,0,223,223],"score":1})
for j in range(0, len(test_js)):
data, target = test_list[i], test_labels[i]
data = Image.open(data).convert('RGB')
json_data = test_js[j]["bbox"]
data = data.resize((224, 224), Image.ANTIALIAS)
print(json_data)
data = data.crop([json_data[0], json_data[1], json_data[2], json_data[3]])
data = data.resize((224, 224), Image.ANTIALIAS)
data = transform_test(data)
newdata = torch.zeros(1, 3, 224, 224)
tach().numpy()
save.append(data)
data = save[0]
for j in range(1, len(test_js)):
data += save[j]
data = data / len(test_js)
print(data)
root = "/home/yyh/PycharmProjects/feature_extractor/loc_224_npy/" + path.split("/")[0]
if not os.path.exists(root):
os.makedirs(root)
dir = "/home/yyh/PycharmProjects/feature_extractor/loc_224_npy/" + path.replace(".jpg",".npy")
np.save(dir, data)
print(i)
#time.sleep(10)
#print(net)
#train_net = torch.nn.DataParallel(net, device_ids=[0])
#optimizer = optim.SGD(params=train_net.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
#scheduler = StepLR(optimizer, 30, gamma=0.1)
#trainer = Trainer(train_net, optimizer, F.cross_entropy, save_dir="./mit67_imagenet_448")
#trainer.loop(130, train_loader, test_loader, scheduler)
2.py
from pathlib import Path
import torch
from torch.autograd import Variable
from torch.optim import Optimizer
from torch import nn
from tqdm import tqdm
import torch.nn.functional as F
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
record = dict()
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
record["maxpool"] = x
x = self.maxpool(x)
x = self.layer1(x)
record["layer1"] = x
x = self.layer2(x)
record["layer2"] = x
x = self.layer3(x)
record["layer3"] = x
x = self.layer4(x)
record["layer4"] = x
x = selpool"] = x
x = self.fc(x)
return x,record["avgpool"]
def rined=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
return model3.py
from pathlib import Path
import torch
from torch.autograd import Variable
from torch.optim import Optimizer
from torch import nn
from tqdm import tqdm
a.is_available()
torch.backends.cudnn.benchmark = True
def __init__(self, model, optimizer, loss_f, save_dir=None, save_freq=10):
self.model = model
if self.cuda:
model.cuda()
self.optimizer = optimizer
self= save_dir
self.save_freq = save_freq
def _iteration(self, data_loader, is_train=True):
loop_loss = []
accuracy = []
for data, target in tqdm(data_loader, ncols=80):
if self.cuda:
data, target = data.cuda(), target.cuda()
output = self.model(data)
loss = self.loss_f(output, target)
loop_loss.append(loss.data.item() / len(data_loader))
accuracy.append((output.data.max(1)[1] == target.data).sum().item())
if is_train:
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
mode = "train" if is_train else "test"
#print(">>>[{}] loss: {:.2f}/accuracy: {:.2%}").format(mode,sum(loop_loss),float(sum(accuracy)) / float(len(data_loader.dataset)))
print(mode)
print(sum(loop_loss))
print(float(sum(accuracy)) / float(len(data_loader.dataset)))
return loop_loss, accuracy
def train(self, data_loader):
self.model.train()
with torch.enable_grad():
loss, correct = self._iteration(data_loader)
def test(self, data_loader):
self.model.eval()
with torch.no_grad():
loss, correct = self._iteration(data_loader, is_train=False)
def loop(self, epochs, train_data, test_data, scheduler=None):
for ep in range(1, epochs + 1):
if scheduler is not None:
scheduler.step()
print("epochs: {}".format(ep))
self.train(train_data)
self.test(test_data)
if ep % self.save_freq == 0:
self.save(ep)
def save(self, epoch, **kwargs):
if self.save_dir is not None:
model_out_path = Path(self.save_dir)
state = self.model
if not model_out_path.exists():
model_out_path.mkdir()
print(self.save_dir+ "model_epoch_{}.pth".format(epoch))
torch.save(state, self.save_dir+ "/model_epoch_{}.pth".format(epoch))
class _LRScheduler(object):
def __init__(self, optimizer, last_epoch=-1):
if not isinstance(optimizer, Optimizer):
raise TypeError('{} is not an Optimizer'.format(
type(optimizer).__name__))
self.optimizer = optimizer
if last_epoch == -1:
for group in optimizer.param_groups:
group.setdefault('initial_lr', group['lr'])
else:
for i, group in enumerate(optimizer.param_groups):
if 'initial_lr' not in group:
raise KeyError("param 'initial_lr' is not specified "
"in param_groups[{}] when resuming an optimizer".format(i))
self.base_lrs = list(map(lambda group: group['initial_lr'], optimizer.param_groups))
self.step(last_epoch + 1)
self.last_epoch = last_epoch
def get_lr(self):
raise NotImplementedError
def step(self, epoch=None):
if epoch is None:
tep_size, gamma=0.1, last_epoch=-1):
self.step_size = step_size
self.gamma = gamma
super(StepLR, self).__init__(optimizer, last_epoch)
def get_lr(self):
return [base_lr * self.gamma ** (self.last_epoch // self.step_size)
for base_lr in self.base_lrs]
创作不易 觉得有帮助请点赞关注收藏~~~