位置蒸馏:针对目标检测提高定位精度的知识蒸馏
今日分享一篇最近新出的目标检测论文『Localization Distillation for Object Detection』

论文链接:https://arxiv.org/abs/2102.12252
项目链接:https://github.com/HikariTJU/LD
论文作者来自天津大学、哈尔滨工业大学。
01
动机
定位的准确性对目标检测算法的性能有很大的影响,而在数据集或者实际应用场景中,位置模糊性(localization ambiguity)是广泛存在的,如下图所示:

上面左图中大象的下边框和右图中冲浪板的右边框是模糊的,很难被检测器检测到,尤其是轻量级的目标检测网络。
在Gaussian yolov3中使用高斯分布对目标边框的不确定性进行建模,GFocal使用一般的离散分布表示目标边框的不确定性,将目标的边框表示为没有任何先验知识限制的离散概率分布。
与上述方法不同,作者将蒸馏学习引入到目标检测网络的定位分支中,提出使用位置蒸馏(简称为LD,Localization Distillation)的方法提高目标框的质量:使用能够解决位置模糊性问题的高性能教师网络,通过蒸馏学习得到学生网络,使得学生网络能像教师网络一样解决位置模糊问题;此外,对于高性能的检测网络使用Self-LD,能够进一步增强网络预测框的精确度。
另外,作者还将Teacher Assistant Strategy引入到LD中,降低使用LD时对教师网络选取的敏感性。
02
知识蒸馏基础
知识蒸馏(KD,Knowledge Distillation)使得轻量级的学生网络能够模仿高性能的教师网络,提高学生网络的性能。
使用 表示教师网络, 表示学生网络, 和 分别表示 和 中最后一个FC层的输出,对 和 进行softmax操作得到 和 。
在KD中, 是高性能网络, 是轻量级网络,将 应用到 的训练过程中,使得 同时学习ground-truth 和 的输出 ,损失函数为:
上式中的 表示交叉熵损失, 表示KL散度损失, 表示蒸馏温度, 和 的定义为:
在蒸馏学习过程中,只更新 的权重 , 的权重 保持不变。KD通常用于模型压缩中,利用大的模型 得到轻量级的模型 ,以减少模型推理时的计算需求。
03
Localization Distillation
位置蒸馏
3.1 使用概率分布表示目标框
使用 表示目标框, 中的4个元素分别表示目标框上边沿、下边沿、左边沿和右边沿到采样点的距离,按照论文《Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection》中的内容,对于 ,有:
上式中的 表示区间 内的回归坐标, 表示该坐标对应的概率。即用在不同坐标值处的概率描述回归框中各边框位置的概率分布,用数学期望表示网络预测的最终位置。
为便于将上述表示应用于CNN检测器中,对上式进行离散化。将区间 进行 等分,即:
, , ,
, ,
对于回归框 中的任一边框,网络的回归分支输出 个元素的向量 ,对 使用softmax操作,得到该边框在 个位置上的概率分布,即 。则可以使用下式计算该边框的最终结果:
则网络预测的回归框可以表示为 。在训练时,可以通过 和 计算Smooth-l1损失、GIoU损失或者CIoU损失。
显然,可以使用目标框中4个边框的概率分布来衡量预测框的不确定性。
3.2 位置蒸馏
在LD中,同样有教师模型 和学生模型 。为预测目标框中某个边框 ,教师网络 和学生网络 分别输出 和 ,对它们进行softmax操作,得到概率分布 和 ,可以用下面的公式表示边框 的蒸馏损失:
回归框中4个边框的蒸馏损失表示为:
上述关于位置蒸馏的表述可以用下图表示:

上图中的 表示温度为 的softmax函数。
位置蒸馏和普通的蒸馏在形式上是一样的,而且不依赖于特定的架构,具有很强的通用性。若有一个能解决边界模糊的高性能教师网络,通过使用位置蒸馏将这种能力迁移至学生模型中,学生模型也具有解决边界模糊性的能力。
对于学生网络 ,总体的损失函数可以表示为:
上式中的 表示回归损失, 表示distribution focal loss, 表示位置蒸馏损失。在实际使用时,上式中的 , 。
3.3 Self-LD
蒸馏学习使得轻量化学生网络拥有高性能教师网络的性能,而对教师网络本身使用蒸馏方法,即自蒸馏,也能提高教师网络本身的性能。
同样地,也可以在自蒸馏方法中引入位置蒸馏,即Self-LD,来增强教师网络解决边界模糊性的能力。
04
Teacher Assistant Strategy
作者通过实验表明,在蒸馏学习时,若选择的教师网络与学生网络的规模差距比较大,反而会降低学生网络的性能。为解决此问题,作者参考论文《Improved Knowledge Distillation via Teacher Assistant》中的方法,引入了Teacher Assistant(简称为TA)方法,以保证蒸馏学习的效果。
对于一个比较大的教师网络 和一个比较小的学生网络 ,指定 个Teacher Assistant网络,记作 ,按照下标从1到 ,模型的规模逐渐递减。如下图所示:

若不使用Teacher Assistant,即学生网络 直接学习教师网络 ,对应于上图中最上面的一条路径,这种方法得到的学生网络 性能会差一些,训练时间最短;
若使用 个Teacher Assistant,即 学习教师网络 ,后面的Teacher Assistant依次学习前面的Teacher Assistant,学生网络 学习 ,对应于上图中最下面的一条路径,这种方法得到的学生网络 性能最好,训练时间最长;
也可以介于上述2种极端情况之间,使用 个Teacher Assistant,对应于上图中间的某条路径,这种方法得到的学生网络 性能和训练时间位于上述2种情况之间。
05
实验
5.1 使用LD提升学生网络性能
在PASCAL VOC和COCO这2个数据集上验证LD对于学生网络的性能提升。在实现过程中, 中的 值为10。
分别使用ResNet-101和ResNet-101-DCN作为教师网络,使用ResNet-18、ResNet-34和ResNet-50作为学生网络。
PASCAL VOC
使用VOC2007 trainval和VOC2012 trainval训练,使用VOC2007 test测试,训练过程、数据增强等策略遵循mmdetection框架中GFocal模型的配置。结果如下表所示:
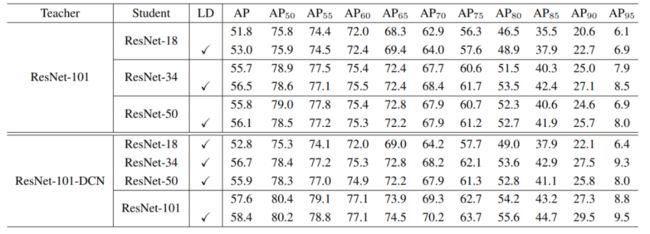
COCO
分别使用train2017和val2017作为训练集和验证集,使用COCO2017 test-dev进行评估。结果如下表所示:

从上面2个表格中可以看出,使用LD能使得学生网络有更高的性能。
5.2 Self-LD对baseline检测器的性能提升
在COCO数据集上使用ResNet-18、ResNet-50和ResNeXt-101-32x4d-DCN这3个模型进行评估,评估它们使用Self-LD后的性能提升情况。在COCO val2017上的测试结果如下表所示:

从上表中可以看出,Self-LD能够提升baseline检测器的性能。
5.3 使用Teacher Assistant提升LD效果
在实验过程中,发现对于同样的学生网络,使用性能更好的教师网络反而会降低学生网络的性能。比如对于学生网络ResNet-50,使用ResNet-101-DCN作为教师网络,性能提升要小于使用ResNet-101作为教师网络,尽管ResNet-101-DCN的性能要优于ResNet-101。
使用Teacher Assistant方法可以解决这一问题。在实现时,使用ResNet-101-DCN作为教师网络,使用ResNet-101和ResNet-34作为Teacher Assistant,ResNet-18作为学生网络。在COCO数据集上训练,在COCO val2017上的测试结果如下图所示:

从上图中最后4行可以看出,使用 方式训练学生网络,得到的学生网络性能要高于传统的 方式,说明使用ResNet-101和ResNet-34作为Teacher Assistant确实能提高学生网络的性能。
06
总结
提出了位置蒸馏(LD)方法,使得学生网络能够学习到高性能教师网络中处理模糊边界的能力;
将LD应用于自蒸馏中,即Self-LD,以提高baseline检测器的性能;
将Teacher Assistant方法应用到LD中,进一步提高学生网络的性能。
仅用于学习交流!

备注:目标检测

目标检测交流群
2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 