Nltk——语料库
NLTK使用方法总结
NLTK(natural language toolkit)是一套基于python的自然语言处理工具集。
安装与功能描述
首先,打开终端安装nltk。
pip install nltk
打开Python终端并输入以下内容来安装 NLTK 包
import nltk
nltk.download()
语言处理功能以及相应NLTK模块以及功能描述。

自带的语料库
在nltk.corpus包下,提供了几类标注好的语料库。见下表:

from nltk.corpus import brown
print(brown.categories()) #输出brown语料库的类别
print(len(brown.sents())) #输出brown语料库的句子数量
print(len(brown.words())) #输出brown语料库的词数量
'''
结果为:
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies',
'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance',
'science_fiction']
57340
1161192
'''
NLTk词频统计
NLTK 中的FreqDist( ) 类主要记录了每个词出现的次数,根据统计数据生成表格或绘图。其结构简单,用一个有序词典进行实现。
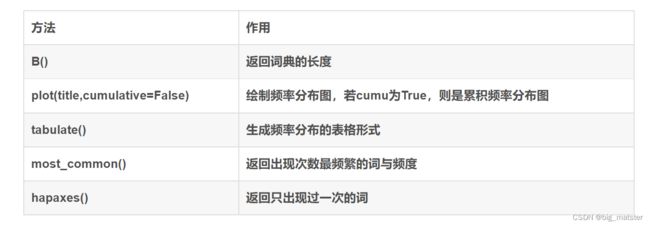
词频统计功能实现:
import nltk
tokens=[ 'my','dog','has','flea','problems','help','please',
'maybe','not','take','him','to','dog','park','stupid',
'my','dalmation','is','so','cute','I','love','him' ]
#统计词频
freq = nltk.FreqDist(tokens)
#输出词和相应的频率
for key,val in freq.items():
print (str(key) + ':' + str(val))
#可以把最常用的5个单词拿出来
standard_freq=freq.most_common(5)
print(standard_freq)
#绘图函数为这些词频绘制一个图形
freq.plot(20, cumulative=False)
去除停用词
from nltk.corpus import stopwords
tokens=[ 'my','dog','has','flea','problems','help','please',
'maybe','not','take','him','to','dog','park','stupid',
'my','dalmation','is','so','cute','I','love','him' ]
clean_tokens=tokens[:]
stwords=stopwords.words('english')
for token in tokens:
if token in stwords:
clean_tokens.remove(token)
print(clean_tokens)
分句与分词
分句
from nltk.tokenize import sent_tokenize
mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(sent_tokenize(mytext))
分词
from nltk.tokenize import word_tokenize
mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude."
print(word_tokenize(mytext))
nltk标记非英语语言文本
from nltk.tokenize import sent_tokenize
mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour."
print(sent_tokenize(mytext,"french"))
NLTK词干提取
单词词干提取就是从单词中去除词缀并返回词根。(比方说 working 的词干是 work。)搜索引擎在索引页面的时候使用这种技术,所以很多人通过同一个单词的不同形式进行搜索,返回的都是相同的,有关这个词干的页面。
词干提取的算法有很多,但最常用的算法是 **Porter 提取算法。NLTK 有一个 PorterStemmer 类,**使用的就是 Porter 提取算法。
from nltk.stem import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('working'))
#结果为:work
LancasterStemmer
from nltk.stem import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem('working'))
#结果为:work
SnowballStemmer 提取非英语单词词干
SnowballStemmer 类,除了英语外,还可以适用于其他 13 种语言。支持的语言如下:
from nltk.stem import SnowballStemmer
print(SnowballStemmer.languages)
#结果为:
('danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish')
NLTK词形还原
(1)词形还原与词干提取类似, 但不同之处在于词干提取经常可能创造出不存在的词汇,词形还原的结果是一个真正的词汇。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('increases'))
#结果为:increase
(2) 结果可能是同义词或具有相同含义的不同词语。有时,如果你试图还原一个词,比如 playing,还原的结果还是 playing。这是因为默认还原的结果是名词,如果你想得到动词,可以通过以下的方式指定。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
#结果为:play
(3)实际上,这是一个非常好的文本压缩水平。最终压缩到原文本的 50% 到 60% 左右。结果可能是动词,名词,形容词或副词:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))
'''
结果为:
play
playing
playing
playing
'''
词性标注(POS Tag)
(1)词性标注是把一个句子中的单词标注为名词,形容词,动词等。
import nltk
text=nltk.word_tokenize('what does the fox say')
print(text)
print(nltk.pos_tag(text))
'''
结果为:
['what', 'does', 'the', 'fox', 'say']
输出是元组列表,元组中的第一个元素是单词,第二个元素是词性标签
[('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('fox', 'NNS'), ('say', 'VBP')]
'''
### 简化的词性标集记列表
简化的词性标记集列表
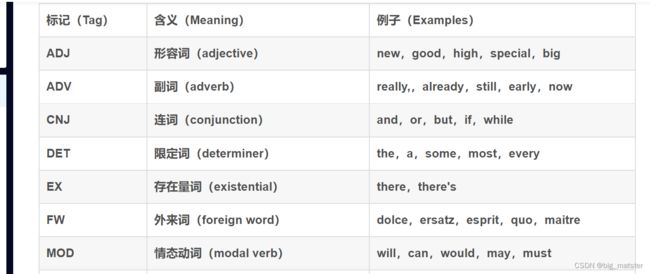
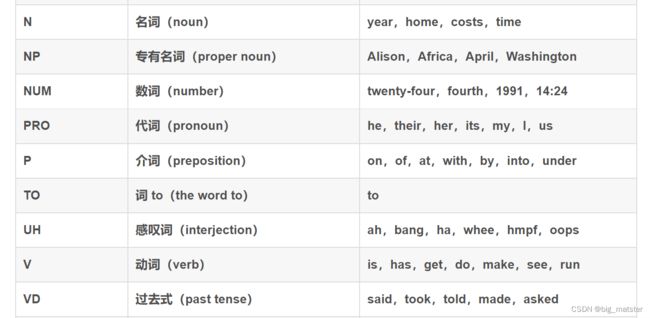

NLTK中的wordnet
wordnet 是为自然语言处理构建的数据库。它包括部分词语的一个同义词组和一个简短的定义。
通过 wordnet可以得到给定词的定义和例句:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain") #获取“pain”的同义词集
print(syn[0].definition())
print(syn[0].examples())
'''
结果为:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
'''
使用 wordnet来获得同义词
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
'''
结果为:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
'''
学习心得
复现论文,不要满足于就把代码给跑通,
要学会将各种函数啥都尝试一遍,全部将其跑通都行啦,
以及利用语料库,把该学习的模型都尝试一遍。
坚持把一两种框架都学透彻都行啦的样子与打算的,全部都将其搞定都行啦的回事与样子。
NLTK主要功能

- 词频统计
- 去除停用词
- 分句和分词
- 词干提取
- 词干还原
- 词性标注
- wordnet