【AI视野·今日CV 计算机视觉论文速览 第245期】Wed, 20 Apr 2022
AI视野·今日CS.CV 计算机视觉论文速览
Wed, 20 Apr 2022
Totally 80 papers
上期速览✈更多精彩请移步主页

Interesting:
*****TokenFusion, 多模态融合的transformer(from 清华大学)

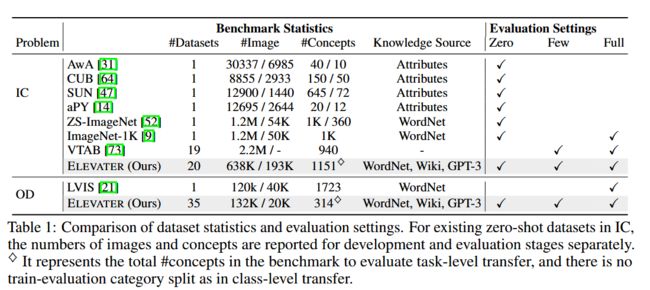
ELEVATER,基于语言增强的视觉方法评测工具 (from 微软)

Dress Code, 高分辨率虚拟试装(from University of Modena and Reggio Emilia )

数据集:


https://github.com/aimagelab/dress-code
GroupNet,基于多尺度超图的轨迹预测(from 上海交大 )

https://github.com/MediaBrain-SJTU/GroupNet
深度学习中图的图像数据增强综述, (from 南京大学)

深度学习可视化进展, (from Meta)

CBUnet,暗光图像中生成恢复颜色和强度的结果 (from 南京大学)

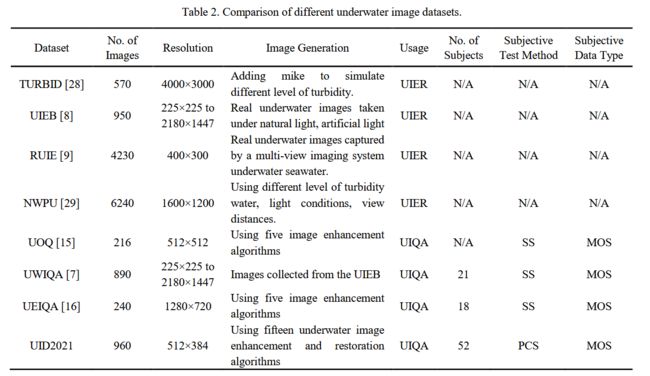
水下数据集UID2021, (from 青岛大学)
水下数据集对比:
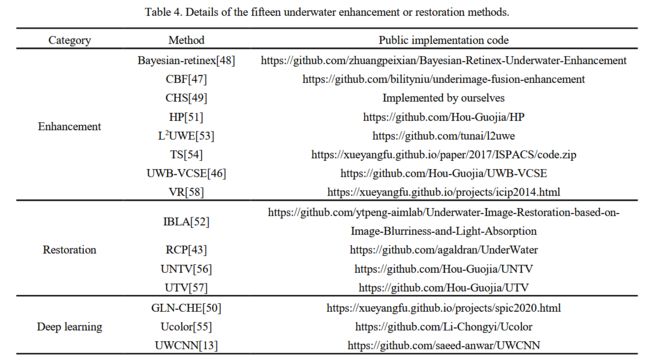
水下图像重建方法汇总:
https://github.com/Hou-Guojia/UID2021
Daily Computer Vision Papers
| Unsupervised detection of ash dieback disease (Hymenoscyphus fraxineus) using diffusion-based hyperspectral image clustering Authors Sam L. Polk, Aland H. Y. Chan, Kangning Cui, Robert J. Plemmons, David A. Coomes, James M. Murphy 白蜡树枯死 Hymenoscyphus fraxineus 是一种引入的真菌病,导致欧洲白蜡树的广泛死亡。遥感高光谱图像编码丰富的结构,已被用于使用监督机器学习技术检测白蜡树中的枯萎病。然而,要了解景观尺度的森林健康状况,需要准确的无监督方法。本文研究了使用无监督扩散和 VCA 辅助图像分割 D VIS 聚类算法检测英国剑桥附近森林中的灰枯病。这项工作中提出的无监督聚类与之前在该场景整体准确度上的工作的监督分类有很高的重叠 71。 |
| Dual-Domain Image Synthesis using Segmentation-Guided GAN Authors Dena Bazazian, Andrew Calway, Dima Damen 我们引入了一种分割引导方法来合成图像,该方法整合了来自两个不同领域的特征。我们的双域模型合成的图像属于语义掩码中的一个域,而在图像的其余部分中则属于另一个域。我们建立在少镜头 StyleGAN 和单镜头语义分割的成功之上,以最大限度地减少利用两个域所需的训练量。该方法将几个镜头跨域 StyleGAN 与潜在优化器相结合,以实现包含两个不同域特征的图像。我们使用分割引导的感知损失,比较域特定和双域合成图像之间的像素级别和激活。结果定性和定量地证明,我们的模型能够在各种对象面部、马、猫、汽车、自然领域、漫画、草图和基于部分的面具眼睛、鼻子、嘴巴、头发、汽车引擎盖上合成双域图像。 |
| Real-Time Face Recognition System Authors Adarsh Ghimire, Naoufel Werghi, Sajid Javed, Jorge Dias 在过去的几十年里,人们对人脸识别算法的兴趣迅速增长,甚至超过了人类水平的表现。尽管取得了成就,但由于计算成本高,它们与实时性能要求高的系统的实际集成是不可行的。 |
| A comparison of different atmospheric turbulence simulation methods for image restoration Authors Nithin Gopalakrishnan Nair, Kangfu Mei, Vishal M. Patel 大气湍流通过向捕获的场景引入模糊和几何失真,降低了远程成像系统捕获的图像质量。当在这些图像上执行对象面部识别和检测等计算机视觉算法时,这会导致性能急剧下降。近年来,文献中提出了各种基于深度学习的大气湍流缓解方法。这些方法通常使用合成生成的图像进行训练,并在真实世界的图像上进行测试。因此,这些恢复方法的性能取决于用于训练网络的模拟类型。在本文中,我们系统地评估了各种湍流模拟方法对图像恢复的有效性。特别是,我们使用六种模拟方法在由湍流退化的面部图像组成的真实世界 LRFID 数据集上评估两个状态或最先进的恢复网络的性能。本文将为在该领域工作的研究人员和从业者提供指导,以选择合适的数据生成模型来训练用于湍流缓解的深度模型。 |
| Shallow camera pipeline for night photography rendering Authors Simone Zini, Claudio Rota, Marco Buzzelli, Simone Bianco, Raimondo Schettini 作为 NTIRE2022 夜间摄影渲染挑战的一部分,我们引入了一个相机管道,用于在低光照条件下渲染视觉上令人愉悦的照片。鉴于任务的性质,其中目标由专业摄影师口头定义,而不是依赖于明确的地面实况图像,我们设计了一个手工制作的解决方案,其特点是结构浅且参数计数低。我们的管道利用局部光增强器作为高动态范围校正的一种形式,然后对图像直方图进行全局调整以防止结果褪色。我们将图像去噪按比例应用于更容易感知的较暗区域,而不会丢失较亮区域的细节。基于深度卷积神经网络,该解决方案在比赛中排名第五,其偏好投票数与其他参赛作品相当。 |
| Rendering Nighttime Image Via Cascaded Color and Brightness Compensation Authors Zhihao Li, Si Yi, Zhan Ma 图像信号处理 ISP 对相机成像至关重要,神经网络 NN 解决方案广泛用于白天场景。缺乏足够的夜间图像数据集和对夜间照明特征的深入了解,对使用现有 NN ISP 进行高质量渲染提出了巨大挑战。为了解决这个问题,我们首先构建了一个高分辨率夜间 RAW RGB NR2R 数据集,其中包含由专业人士注释的白平衡和色调映射。同时,为了最好地捕捉夜间照明光源的特性,我们开发了 CBUnet,这是一个两级 NN ISP,用于级联颜色和亮度属性的补偿。实验表明,与传统的 ISP 管道相比,我们的方法具有更好的视觉质量,并且在 NTIRE 2022 夜间摄影渲染挑战赛的两个轨道上分别由人民和专业摄影师的选择排名第二。 |
| MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment Authors Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao Yuan Gong, Mingdeng Cao, Jiahao Wang, Yujiu Yang 无参考图像质量评估 NR IQA 旨在根据人类主观感知来评估图像的感知质量。不幸的是,现有的 NR IQA 方法远不能满足在基于 GAN 的失真图像上预测准确质量分数的需求。为此,我们提出了用于无参考图像质量评估 MANIQA 的多维注意力网络,以提高基于 GAN 的失真的性能。我们首先通过 ViT 提取特征,然后为了加强全局和局部交互,我们提出了 Transposed Attention Block TAB 和 Scale Swin Transformer Block SSTB。这两个模块分别在通道和空间维度上应用注意力机制。在这种多维度的方式下,模块在全局和局部地协同增加图像不同区域之间的交互。最后,应用补丁加权质量预测的双分支结构来根据每个补丁分数的权重预测最终分数。实验结果表明,MANIQA 在四个标准数据集 LIVE、TID2013、CSIQ 和 KADID 10K 上的性能大大优于最先进的方法。此外,我们的方法在 NTIRE 2022 感知图像质量评估挑战赛 Track 2 No Reference 的最终测试阶段排名第一。 |
| Missingness Bias in Model Debugging Authors Saachi Jain, Hadi Salman, Eric Wong, Pengchuan Zhang, Vibhav Vineet, Sai Vemprala, Aleksander Madry 缺失或输入中缺少特征是许多模型调试工具的基本概念。然而,在计算机视觉中,不能简单地从图像中移除像素。因此,人们倾向于诉诸启发式方法,例如将像素涂黑,这反过来可能会在调试过程中引入偏差。我们研究了这些偏差,特别是展示了基于转换器的架构如何能够更自然地实现缺失,从而解决这些问题并提高实践中模型调试的可靠性。 |
| Learning to Imagine: Diversify Memory for Incremental Learning using Unlabeled Data Authors Yu Ming Tang, Yi Xing Peng, Wei Shi Zheng 深度神经网络 DNN 在增量学习时会遭受灾难性遗忘,这极大地限制了其应用。虽然维护每个任务的少量样本(称为样本)可以在一定程度上减轻遗忘,但现有方法仍然受到样本数量少的限制,因为这些样本太少而无法承载足够的任务特定知识,因此遗忘仍然存在。为了克服这个问题,我们建议想象给定示例的不同对应物,指的是来自未标记数据的丰富的语义无关信息。具体来说,我们开发了一个可学习的特征生成器,通过基于来自示例的语义信息和来自未标记数据的语义无关信息自适应地生成示例的不同对应物来使示例多样化。我们引入语义对比学习以强制生成的样本与示例语义一致,并执行语义解耦对比学习以鼓励生成样本的多样性。多样化的生成样本可以有效防止 DNN 在学习新任务时遗忘。 |
| Global-and-Local Collaborative Learning for Co-Salient Object Detection Authors Runmin Cong, Ning Yang, Chongyi Li, Huazhu Fu, Yao Zhao, Qingming Huang, Sam Kwong 共显着对象检测 CoSOD 的目标是发现通常出现在包含两个或多个相关图像的查询组中的显着对象。因此,如何有效地提取图像间对应关系对于 CoSOD 任务至关重要。在本文中,我们提出了一种全局和局部协同学习架构,包括全局对应模型 GCM 和局部对应模型 LCM,以从全局和局部角度捕捉不同图像之间的综合图像间对应关系。首先,我们将不同的图像视为不同的时间片,并使用 3D 卷积直观地整合所有内部特征,这样可以更充分地提取全局组语义。其次,我们设计了一个成对相关变换PCT来探索成对图像之间的相似性对应关系,并结合多个局部成对对应关系来生成局部图像间关系。第三,通过全局和局部对应聚合 GLA 模块整合 GCM 和 LCM 的图像间关系,以探索更全面的图像间协作线索。最后,通过帧内和帧间加权融合AEWF模块自适应地集成帧内和帧间特征,以学习共显着特征并预测共显着图。 |
| Self-Calibrated Efficient Transformer for Lightweight Super-Resolution Authors Wenbin Zou, Tian Ye, Weixin Zheng, Yunchen Zhang, Liang Chen, Yi Wu 最近,深度学习已成功应用于单幅图像超分辨率 SISR,性能显着。然而,大多数现有方法都侧重于构建具有大量层的更复杂的网络,这可能需要大量的计算成本和内存存储。为了解决这个问题,我们提出了一个轻量级的自校准高效变压器 SCET 网络来解决这个问题。 SCET的架构主要由自标定模块和高效transformer模块组成,其中自标定模块采用像素注意机制有效提取图像特征。为了进一步利用特征中的上下文信息,我们使用了一个高效的转换器来帮助网络在长距离上获得相似的特征,从而恢复足够的纹理细节。我们提供了关于整个网络的不同设置的综合结果。我们提出的方法比基线方法取得了更显着的性能。 |
| Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing Authors Thiemo Alldieck, Mihai Zanfir, Cristian Sminchisescu 我们提出了 PHORHUM,一种新颖的、端到端可训练的深度神经网络方法,用于仅给定单目 RGB 图像的逼真的 3D 人体重建。我们的像素对齐方法估计了详细的 3D 几何形状,并且首次估计了未着色的表面颜色和场景照明。观察到仅 3D 监督不足以进行高保真颜色重建,我们引入了基于补丁的渲染损失,可以对人类的可见部分进行可靠的颜色重建,并对不可见部分进行详细和合理的颜色估计。此外,我们的方法特别解决了先前工作在表示几何、反照率和照明效果方面的方法学和实际限制,在一个端到端模型中,因素可以被有效地解开。在广泛的实验中,我们证明了我们方法的多功能性和稳健性。 |
| Towards Efficient Single Image Dehazing and Desnowing Authors Tian Ye, Sixiang Chen, Yun Liu, Erkang Chen, Yuche Li 从图像中去除雨、雾和雪等不利天气条件是一个具有挑战性的问题。尽管当前针对特定条件的恢复算法取得了令人瞩目的进展,但它还不够灵活,无法处理各种退化类型。我们提出了一种高效且紧凑的图像恢复网络,名为 DAN Net Degradation Adaptive Neural Network 来解决这个问题,该网络由多个紧凑的专家网络和一个自适应门控神经网络组成。依靠紧凑的架构和三个新颖的组件,单个专家网络有效地解决了恶劣的冬季场景中的特定退化问题。基于专家混合策略,DAN Net 从每个输入图像中捕获退化信息,以自适应地调制特定任务专家网络的输出,以消除各种不利的冬季天气条件。具体来说,它采用轻量级的自适应门控神经网络来估计输入图像的门控注意力图,同时联合调度具有相同拓扑的不同任务特定专家来处理退化图像。这种新颖的图像恢复管道有效且高效地处理不同类型的恶劣天气场景。 |
| Invertible Mask Network for Face Privacy-Preserving Authors Yang Yang, Yiyang Huang, Ming Shi, Kejiang Chen, Weiming Zhang, Nenghai Yu 面部隐私保护是引起极大研究兴趣的热点之一。然而,现有的人脸隐私保护方法旨在造成人脸语义信息的缺失,无法保持原始人脸信息的可重用性。为实现处理后人脸的自然性和原始受保护人脸的可恢复性,提出基于Invertible Mask Network IMN的人脸隐私保护方法。在 IMN 中,我们首先引入了一个 Mask 网络来生成 Mask 人脸。然后,将Mask face放在被保护的脸上,生成masked face,其中mask face与Mask face没有区别。最后,可以将蒙面人脸从蒙面人脸中取出,并将恢复的人脸提供给授权用户,其中恢复的人脸与受保护的人脸在视觉上无法区分。 |
| Less than Few: Self-Shot Video Instance Segmentation Authors Pengwan Yang, Yuki M. Asano, Pascal Mettes, Cees G. M. Snoek 本文的目标是在运行时绕过对少数镜头视频理解的标记示例的需要。虽然被证明是有效的,但在许多实际视频设置中,即使标记几个示例似乎也不现实。随着时空视频理解中的细节水平以及注释的复杂性不断增加,这一点尤其正确。我们建议自动学习在给定查询的情况下找到合适的支持视频,而不是使用人类神谕执行少量镜头学习以提供一些密集标记的支持视频。我们称这种学习为自我学习,我们概述了一种简单的自我监督学习方法来生成一个非常适合相关样本的无监督检索的嵌入空间。为了展示这种新颖的设置,我们首次解决了自拍和少量镜头设置中的视频实例分割问题,其目标是在空间和时间域的像素级别上分割实例。我们提供了强大的基线性能,这些性能利用了一种新颖的基于变压器的模型,并表明自我学习甚至可以超越少数镜头,并且可以积极地结合起来以进一步提高性能。 |
| OpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching Authors Ostap Viniavskyi, Mariia Dobko, Dmytro Mishkin, Oles Dobosevych 我们展示了 OpenGlue 一个免费的开源图像匹配框架,它使用基于图神经网络的匹配器,灵感来自 SuperGlue 引用 sarlin20superglue。我们展示了包括额外的几何信息,例如局部特征尺度、方向和仿射几何(如果可用),例如对于 SIFT 特征,显着提高了 OpenGlue 匹配器的性能。我们研究了各种注意机制对准确性和速度的影响。我们还通过将本地描述符与上下文感知描述符相结合,提出了一个简单的架构改进。 |
| Core Box Image Recognition and its Improvement with a New Augmentation Technique Authors E.E. Baraboshkin, A.E. Demidov, D.M. Orlov, D.A. Koroteev 大多数用于自动全孔岩心图像分析描述、颜色、性质分布等的方法都是基于单独的岩心柱分析。岩心通常在一个盒子中成像,因为为每个岩心柱获取图像需要大量时间。这项工作提出了一种从芯盒中提取芯柱的创新方法和算法。芯盒成像的条件可能有很大不同。这种差异对于需要描述所有可能数据变化的大型数据集的机器学习算法来说是灾难性的。尽管如此,此类图像仍具有一些标准功能,例如盒子和核心。因此,我们可以使用本工作中描述的独特增强来模拟不同的环境。它被称为模板,如扩充 TLA 。该方法在各种环境中进行了描述和测试,并在传统数据以及传统数据和 TLA 数据混合训练的算法上比较了结果。与在没有 TLA 的数据上训练的算法不同,使用 TLA 数据训练的算法提供了更好的指标,并且可以在大多数新图像上检测核心。 |
| Unsupervised Learning of Efficient Geometry-Aware Neural Articulated Representations Authors Atsuhiro Noguchi, Xiao Sun, Stephen Lin, Tatsuya Harada 我们提出了一种无监督方法,用于关节物体的 3D 几何感知表示学习。尽管可以通过现有的 3D 神经表示使用显式姿态控制来渲染关节物体的逼真图像,但这些方法需要地面真实 3D 姿态和前景蒙版进行训练,而这些方法的获取成本很高。我们通过学习 GAN 训练的表示来消除这种需求。从随机姿势和潜在向量中,生成器被训练为通过对抗训练生成关节物体的逼真图像。为了避免 GAN 训练的大量计算成本,我们提出了一种基于三平面的铰接对象的有效神经表示,然后提出了一个基于 GAN 的无监督训练框架。 |
| Detect-and-describe: Joint learning framework for detection and description of objects Authors Addel Zafar, Umar Khalid 传统的对象检测回答了两个问题,即对象是什么以及对象在哪里。对象检测的哪些部分可以进一步细化,即什么类型、什么形状和什么材料等。这导致对象检测任务转移到对象描述范式。描述一个对象提供了额外的细节,使我们能够了解对象的特征和属性塑料船不仅仅是船,玻璃瓶不仅仅是瓶子。这些附加信息可以隐含地用于深入了解看不见的对象,例如未知物体是金属的,有轮子,这在传统的物体检测中是不可能的。在本文中,我们提出了一种同时检测对象并推断其属性的新方法,我们称之为检测和描述 DaD 框架。 DaD 是一种基于深度学习的方法,它也将对象检测扩展到对象属性预测。我们在 aPascal 训练集上训练我们的模型,并在 aPascal 测试集上评估我们的方法。我们在 aPascal 测试集上进行对象属性预测的接收器操作特征曲线 AUC 下面积达到 97.0。 |
| Semi-supervised 3D shape segmentation with multilevel consistency and part substitution Authors Chun Yu Sun, Yu Qi Yang, Hao Xiang Guo, Peng Shuai Wang, Xin Tong, Yang Liu, Heung Yeung Shum 缺乏细粒度的 3D 形状分割数据是开发基于学习的 3D 分割技术的主要障碍。我们提出了一种有效的半监督方法,用于从少数标记的 3D 形状和大量未标记的 3D 数据中学习 3D 分割。对于未标记的数据,我们提出了一种新的 emph 多级一致性损失,以在多级点级、部分级和分层级的 3D 形状的受扰动副本之间强制网络预测的一致性。对于标记的数据,我们开发了一种简单而有效的零件替换方案,以增加标记的 3D 形状,增加更多的结构变化以增强训练。我们的方法已在 PartNet 和 ShapeNetPart 上的 3D 对象语义分割任务以及 ScanNet 上的室内场景语义分割任务上得到广泛验证。它表现出优于现有半监督和无监督预训练 3D 方法的性能。 |
| An Efficient Domain-Incremental Learning Approach to Drive in All Weather Conditions Authors M. Jehanzeb Mirza, Marc Masana, Horst Possegger, Horst Bischof 尽管深度神经网络为自动驾驶提供了令人印象深刻的视觉感知性能,但它们对不同天气条件的鲁棒性仍然需要关注。在使这些模型适应变化的环境(例如不同的天气条件)时,它们很容易忘记先前学习的信息。这种灾难性的遗忘通常通过增量学习方法来解决,这些方法通常通过保留训练样本的内存库或为每个场景保留整个模型或模型参数的副本来重新训练模型。尽管这些方法显示出令人印象深刻的结果,但它们可能容易出现可扩展性问题,并且尚未显示它们在所有天气条件下对自动驾驶的适用性。在本文中,我们提出了 DISC Domain Incremental through Statistical Correction 一种简单的在线零遗忘方法,该方法可以增量学习新任务,即天气条件,而无需重新训练或昂贵的记忆库。我们为每个任务存储的唯一信息是统计参数,因为我们通过一阶和二阶统计的变化对每个域进行分类。因此,当每个任务到达时,我们只需将相应任务的统计向量插入并播放到模型中,它就会立即开始在该任务上表现良好。 |
| UID2021: An Underwater Image Dataset for Evaluation of No-reference Quality Assessment Metrics Authors Guojia Hou, Yuxuan Li, Huan Yang, Kunqian Li, Zhenkuan Pan 实现水下图像的主客观质量评价,对于水下视觉感知和图像视频处理具有重要意义。然而,由于缺乏具有公开可用数据集和可靠客观 UIQA 指标的全面人类主观用户研究,水下图像质量评估 UIQA 的发展受到限制。为了解决这个问题,我们建立了一个名为 UID2021 的大规模水下图像数据集,用于评估无参考 UIQA 指标。构建的数据集包含从各种来源收集的 60 幅多重降级水下图像,涵盖了 6 种常见的水下场景,即蓝景、蓝绿景、绿景、朦胧景、弱光景和浑浊景,以及相应的 900 个质量改进版本。采用十五种最先进的水下图像增强和恢复算法。 UID2021 的平均意见分数 MOS 也是通过对 52 个观察者使用配对比较排序方法获得的。在我们构建的数据集上测试了空中 NR IQA 和水下特定算法,以公平地比较性能并分析它们的优缺点。我们提出的 UID2021 数据集使人们能够全面评估 NR UIQA 算法,并为进一步研究 UIQA 铺平道路。 |
| SePiCo: Semantic-Guided Pixel Contrast for Domain Adaptive Semantic Segmentation Authors Binhui Xie, Shuang Li, Mingjia Li, Chi Harold Liu, Gao Huang, Guoren Wang 域自适应语义分割试图通过利用在标记的源域上训练的模型对未标记的目标域做出令人满意的密集预测。一种解决方案是自我训练,它使用目标伪标签重新训练模型。许多方法倾向于减轻噪声伪标签,但是,它们忽略了具有相似语义概念的跨域像素之间的内在联系。因此,他们将难以处理跨领域的语义变化,从而导致歧视减少和泛化能力差。在这项工作中,我们提出了语义引导像素对比度 SePiCo,这是一种新颖的单阶段适应框架,它突出了单个像素的语义概念,以促进跨域的类判别和类平衡像素嵌入空间的学习。具体来说,为了探索正确的语义概念,我们首先研究了一个质心感知像素对比度,它使用整个源域或单个源图像的类别质心来指导判别特征的学习。考虑到语义概念可能缺乏类别多样性,然后我们开辟了一条分布视角的道路,以涉及足够数量的实例,即分布感知像素对比,其中我们从标记源的统计信息中近似每个语义类别的真实分布数据。此外,这样的优化目标可以通过隐含地包含无限数量的不相似对来推导出封闭形式的上限。大量实验表明,SePiCo 不仅有助于稳定训练,还可以产生判别特征,在白天和夜间场景中都取得了显着进步。 |
| An Energy-Based Prior for Generative Saliency Authors Jing Zhang, Jianwen Xie, Nick Barnes, Ping Li 我们提出了一种新的基于能量的先验,用于生成显着性预测,其中潜在变量遵循基于信息的能量先验。显着性生成器和基于能量的先验都是通过基于马尔可夫链蒙特卡罗的最大似然估计联合训练的,其中潜变量的棘手后验和先验分布的采样由朗之万动力学执行。使用生成显着性模型,我们可以从图像中获得像素级的不确定性图,表明模型对显着性预测的置信度。与将潜在变量的先验分布定义为简单的各向同性高斯分布的现有生成模型不同,我们的模型使用基于能量的信息先验,它可以在捕获数据的潜在空间方面更具表现力。借助基于信息的能量先验,我们扩展了生成模型的高斯分布假设,以实现潜在空间的更具代表性的分布,从而实现更可靠的不确定性估计。我们将提出的框架应用于具有变换器和卷积神经网络主干的 RGB 和 RGB D 显着对象检测任务。 |
| A qualitative investigation of optical flow algorithms for video denoising Authors Hannes Fassold 良好的光流估计对于媒体行业、工业检测和汽车等应用领域中采用的许多视频分析和恢复算法至关重要。在这项工作中,我们研究了光流算法在集成到最先进的视频去噪算法时的定性性能。两种经典的光流算法,例如TV L1 以及最近基于深度学习的算法,如 RAFT 或 BMBC 将被考虑在内。 |
| ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models Authors Chunyuan Li, Haotian Liu, Liunian Harold Li, Pengchuan Zhang, Jyoti Aneja, Jianwei Yang, Ping Jin, Yong Jae Lee, Houdong Hu, Zicheng Liu, Jianfeng Gao 从自然语言监督中学习视觉表示最近在许多开创性的工作中显示出巨大的希望。一般来说,这些语言增强的视觉模型展示了对各种数据集任务的强大可迁移性。然而,由于缺乏用于公平基准测试的易于使用的工具包,评估这些基础模型的可转移性仍然是一个挑战。为了解决这个问题,我们构建了语言增强视觉任务级别迁移的 ELEVATER 评估,这是第一个比较和评估预训练语言增强视觉模型的基准。几个亮点包括 i 数据集。作为下游评估套件,它由 20 个图像分类数据集和 35 个对象检测数据集组成,每个数据集都增加了外部知识。 ii 工具包。开发了一个自动超参数调整工具包,以确保模型适应的公平性。为了充分利用语言增强视觉模型的全部功能,提出了新颖的语言感知初始化方法来显着提高适应性能。 iii 指标。使用了多种评估指标,包括样本效率零镜头和少镜头以及参数效率线性探测和全模型微调。 |
| Sensor Data Fusion in Top-View Grid Maps using Evidential Reasoning with Advanced Conflict Resolution Authors Sven Richter, Frank Bieder, Sascha Wirges, Christoph Stiller 我们提出了一种新方法来组合基于异构传感器源估计的证据顶视图网格图。通常在这种情况下应用的 Dempster 组合规则会提供不希望的结果和高度冲突的输入。因此,我们使用更先进的证据推理技术,并通过对证据来源的可靠性建模来改进冲突解决。我们提出了一种数据驱动的可靠性估计,以使用 Kitti 360 数据集优化融合质量。我们将所提出的方法应用于激光雷达和立体相机数据的融合,并定性和定量地评估结果。 |
| GroupNet: Multiscale Hypergraph Neural Networks for Trajectory Prediction with Relational Reasoning Authors Chenxin Xu, Maosen Li, Zhenyang Ni, Ya Zhang, Siheng Chen 从过去的轨迹中揭开多个智能体之间的相互作用的神秘面纱是精确和可解释的轨迹预测的基础。然而,以前的工作只考虑具有有限关系推理的成对交互。为了促进更全面的关系推理交互建模,我们提出了 GroupNet,一种多尺度超图神经网络,它在交互捕获和表示学习方面都是新颖的。从交互捕获的角度来看,我们提出了一个可训练的多尺度超图来捕获多个组大小的成对和分组交互。从交互表示学习的角度来看,我们提出了一种可以端到端学习的三元素格式,并明确地推理一些关系因素,包括交互强度和类别。我们将 GroupNet 应用到基于 CVAE 的预测系统和先前最先进的预测系统中,用于通过关系推理来预测社会上似是而非的轨迹。为了验证关系推理的能力,我们用合成物理模拟进行实验,以反映捕捉群体行为、推理交互强度和交互类别的能力。为了验证预测的有效性,我们对三个真实世界的轨迹预测数据集进行了广泛的实验,包括 NBA、SDD 和 ETH UCY,并且我们表明,使用 GroupNet,基于 CVAE 的预测系统优于最先进的方法。 |
| Binary Multi Channel Morphological Neural Network Authors Theodore Aouad, Hugues Talbot 从理论的角度来看,神经网络,尤其是深度学习的研究相对较少。相反,数学形态学是一门具有扎实理论基础的学科。我们将这些领域结合起来,提出一种理论上更易于解释的新型神经架构。我们介绍了一个基于卷积神经网络的二元形态神经网络 BiMoNN。我们将其设计用于学习具有二进制输入和输出的形态网络。我们证明了 BiMoNN 和形态算子之间的等价性,我们可以用它来对整个网络进行二值化。 |
| Modeling Missing Annotations for Incremental Learning in Object Detection Authors Fabio Cermelli, Antonino Geraci, Dario Fontanel, Barbara Caputo 尽管最近在对象检测领域取得了进展,但常见的架构仍然不适合随着时间的推移增量检测新类别。他们很容易发生灾难性的遗忘,在没有原始训练数据的情况下更新参数时忘记了已经学过的内容。以前的工作在目标检测任务中扩展了标准分类方法,主要采用知识蒸馏框架。然而,我们认为目标检测引入了一个被忽视的额外问题。虽然属于新类的对象是通过注释来学习的,但如果没有为输入中可能仍然存在的其他对象提供监督,则模型会学习将它们与背景区域相关联。我们建议通过重新访问标准知识蒸馏框架来处理这些缺失的注释。我们的方法在 Pascal VOC 数据集的每个设置中都优于当前最先进的方法。我们进一步提出了实例分割的扩展,优于其他基线。在这项工作中,我们建议通过重新访问标准知识蒸馏框架来处理缺失的注释。我们表明,我们的方法在 Pascal VOC 2007 数据集的每个设置中都优于当前最先进的方法。 |
| Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment Authors Yue Cao, Zhaolin Wan, Dongwei Ren, Zifei Yan, Wangmeng Zuo 全参考 FR 图像质量评估 IQA 通过测量其与原始质量参考的感知差异来评估失真图像的视觉质量,并已广泛用于低级视觉任务。训练 FR IQA 模型需要具有平均意见得分 MOS 的成对标记数据,但收集起来既费时又麻烦。相比之下,未标记的数据可以很容易地从图像退化或恢复过程中收集,从而鼓励利用未标记的训练数据来提高 FR IQA 性能。此外,由于标记数据和未标记数据之间的分布不一致,未标记数据中可能会出现异常值,进一步增加了训练难度。在本文中,我们建议结合半监督和积极的未标记 PU 学习,以利用未标记数据,同时减轻异常值的不利影响。特别是,通过将所有标记数据视为正样本,PU 学习被用来识别负样本,即来自未标记数据的异常值。半监督学习 SSL 被进一步部署以通过动态生成伪 MOS 来利用未标记的正数据。我们采用包括参考和失真分支的双分支网络。此外,在参考分支中引入了空间注意力以更多地关注信息区域,切片 Wasserstein 距离用于稳健的差异图计算,以解决由 GAN 模型恢复的图像引起的错位问题。 |
| Edge-enhanced Feature Distillation Network for Efficient Super-Resolution Authors Yan Wang 随着最近卷积神经网络的大规模发展,已经提出了许多基于 CNN 的轻量级图像超分辨率方法,用于在边缘设备上进行实际部署。然而,大多数现有方法都集中在一个特定的方面网络或损失设计,这导致难以最小化模型大小。为了解决这个问题,我们总结了块设计、架构搜索和损失设计,以获得更有效的 SR 结构。在本文中,我们提出了一种名为 EFDN 的边缘增强特征蒸馏网络,以在资源受限的情况下保留高频信息。具体来说,我们基于现有的重新参数化方法构建了一个边缘增强卷积块。同时,我们提出边缘增强梯度损失来校准重新参数化的路径训练。实验结果表明,我们的边缘增强策略保留了边缘并显着提高了最终恢复质量。 |
| Dynamic Point Cloud Denoising via Gradient Fields Authors Qianjiang Hu, Wei Hu 3D动态点云提供现实世界物体或运动场景的离散表示,已广泛应用于沉浸式远程呈现、自动驾驶、监控等。但是,从传感器获取的点云通常会受到噪声的干扰,从而影响下游任务例如表面重建和分析。尽管已经为静态点云去噪做出了很多努力,但动态点云去噪仍在探索中。在本文中,我们提出了一种新的基于梯度场的动态点云去噪方法,通过估计梯度场来利用时间对应关系,这是动态点云处理和分析中的一个基本问题。梯度场是噪声点云的对数概率函数的梯度,我们在此基础上进行梯度上升,使每个点收敛到下面的干净表面。我们估计每个表面补丁的梯度并利用时间对应关系,其中利用经典力学中的刚性运动搜索时间对应的补丁。特别是,我们将每个补丁视为一个刚体,它通过力在相邻帧的梯度场中移动,直到达到平衡状态,即当补丁上的梯度总和达到 0 时。由于梯度会更小该点更靠近下垫面,平衡的补丁将很好地拟合下垫面,从而导致时间对应。最后,补丁中每个点的位置沿着从相邻帧中相应补丁平均的梯度方向更新。 |
| Multi-View Spatial-Temporal Network for Continuous Sign Language Recognition Authors Ronghui Li, Lu Meng 手语是一种美丽的视觉语言,也是口语和听力障碍者使用的主要语言。然而,手语有很多复杂的表达方式,公众难以理解和掌握。手语识别算法将极大地促进听力受损者和正常人之间的交流。传统的连续手语识别往往采用基于卷积神经网络 CNN 和长短期记忆网络 LSTM 的序列学习方法。这些方法只能分别学习时空特征,无法学习手语复杂的时空特征。 LSTM 也很难学习长期依赖。为了缓解这些问题,本文提出了一种多视图时空连续手语识别网络。该网络由三部分组成。第一部分是 Multi View Spatial Temporal Feature Extractor Network MSTN ,可以直接提取 RGB 和骨架数据的时空特征 第二部分是基于 Transformer 的手语编码器网络,可以学习长期依赖关系 第三部分是 Connectionist时间分类 CTC 解码器网络,用于预测连续手语的整体含义。我们的算法在两个公共手语数据集 SLR 100 和 PHOENIX Weather 2014T RWTH 上进行了测试。因此,我们的方法在两个数据集上都取得了出色的性能。 |
| Augmentation of Atmospheric Turbulence Effects on Thermal Adapted Object Detection Models Authors Engin Uzun, Ahmet Anil Dursun, Erdem Akagunduz 大气湍流对远程观测系统的图像质量有降低的影响。由于温度、风速、湿度等各种因素的影响,湍流的特征是大气折射率的随机波动。这是一种可能出现在各种成像光谱中的现象,例如可见光或红外波段。在本文中,我们分析了大气湍流对热成像中目标检测性能的影响。我们使用几何湍流模型来模拟中等尺度热图像集(即 FLIR ADAS v2)上的湍流效应。我们将热域适应应用于最先进的对象检测器,并提出了一种数据增强策略来提高对象检测器的性能,该策略利用不同严重程度的湍流图像作为训练数据。 |
| Proposal-free Lidar Panoptic Segmentation with Pillar-level Affinity Authors Qi Chen, Sourabh Vora 我们为激光雷达全景分割提出了一个简单而有效的无提案架构。我们使用基于支柱的鸟瞰图表示在单个网络中联合优化语义分割和类不可知实例分类。实例分类头学习柱子之间的成对亲和力,以确定柱子是否属于同一个实例。我们进一步提出了一种局部聚类算法,通过合并语义分割和亲和力预测来传播实例 ID。 |
| Multimodal Token Fusion for Vision Transformers Authors Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, Yunhe Wang 为了解决单模态视觉任务,已经出现了许多变形器的改编,其中自我注意模块被堆叠以处理图像等输入源。直观地说,将多种模式的数据提供给视觉转换器可以提高性能,但内部模式的注意力权重也可能会被稀释,从而破坏最终的性能。在本文中,我们提出了一种多模态令牌融合方法 TokenFusion ,专为基于转换器的视觉任务量身定制。为了有效融合多种模态,TokenFusion 动态检测无信息标记,并用投影和聚合的模态间特征替换这些标记。还采用了剩余位置对齐,以便在融合后明确利用模态间对齐。 TokenFusion 的设计允许转换器学习多模态特征之间的相关性,而单模态转换器架构基本保持不变。 |
| Shape-Aware Monocular 3D Object Detection Authors Wei Chen, Jie Zhao, Wan Lei Zhao, Song Yuan Wu 通过单透视相机检测 3D 对象是一个具有挑战性的问题。由于其有效性和简单性,无锚和基于关键点的模型最近受到越来越多的关注。但是,这些方法中的大多数都容易受到遮挡和截断对象的影响。在本文中,提出了一种单级单目 3D 对象检测模型。实例分割头集成到模型训练中,使模型能够了解目标对象的可见形状。检测在很大程度上避免了来自目标对象周围无关区域的干扰。此外,我们还揭示了流行的基于 IoU 的评估指标,最初是为评估基于立体或 LiDAR 的检测方法而设计的,对单目 3D 对象检测算法的改进不敏感。针对单目 3D 目标检测模型提出了一种新的评估指标,即平均深度相似度 ADS。 |
| NAFSSR: Stereo Image Super-Resolution Using NAFNet Authors Xiaojie Chu, Liangyu Chen, Wenqing Yu 立体图像超分辨率旨在通过利用双目系统提供的互补信息来提高超分辨率结果的质量。为了获得合理的性能,大多数方法侧重于精细设计模块、损失函数等,从另一个角度利用信息。这具有增加系统复杂性的副作用,使研究人员难以评估新想法和比较方法。本文继承了一个强大而简单的图像恢复模型 NAFNet,用于单视图特征提取,并通过添加交叉注意力模块来融合视图之间的特征以适应双目场景。提出的立体图像超分辨率基线标记为 NAFSSR。此外,提出了训练测试策略以充分利用 NAFSSR 的性能。大量实验证明了我们方法的有效性。特别是,NAFSSR 在 KITTI 2012、KITTI 2015、Middlebury 和 Flickr1024 数据集上优于最先进的方法。凭借 NAFSSR,我们在 NTIRE 2022 立体图像超分辨率挑战赛中获得第一名。 |
| Unsupervised Contrastive Hashing for Cross-Modal Retrieval in Remote Sensing Authors Georgii Mikriukov, Mahdyar Ravanbakhsh, Beg m Demir 跨模态检索系统的开发可以基于任何模态的查询跨不同模态搜索和检索语义相关数据,在遥感遥感领域引起了极大的关注。在本文中,我们将注意力集中在跨模态文本图像检索上,其中来自一种模态(例如文本)的查询可以匹配到来自另一种模态(例如图像)的存档条目。 RS中大多数现有的跨模态文本图像检索系统需要大量标记的训练样本,并且也不允许快速和内存有效的检索。这些问题限制了现有跨模态检索系统在 RS 中大规模应用的适用性。为了解决这个问题,在本文中,我们介绍了一种新的无监督跨模态对比散列 DUCH 方法,用于 RS 中的文本图像检索。为此,所提出的 DUCH 由两个主要模块组成 1 特征提取模块,它提取两种模态的深度表示 2 散列模块,该模块学习从提取的表示中生成跨模态二进制散列码。我们引入了一种新颖的多目标损失函数,包括 i 对比目标,可以在模式内和模式间相似性中保持相似性 ii 跨模式表示一致性的两种模式强制执行的对抗性目标和 iii 生成哈希码的二值化目标。实验结果表明,所提出的 DUCH 优于最先进的方法。 |
| CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution Authors Guangwei Gao, Zixiang Xu, Juncheng Li, Jian Yang, Tieyong Zeng, Guo Jun Qi 最近,深度卷积神经网络 CNN 引导的人脸超分辨率方法通过与人脸先验联合训练,在恢复退化的人脸细节方面取得了很大进展。然而,这些方法有一些明显的局限性。一方面,多任务联合学习需要对数据集进行额外的标记,引入的先验网络会显着增加模型的计算成本。另一方面,CNN有限的感受野会降低重建人脸图像的保真度和自然度,导致重建图像不理想。在这项工作中,我们提出了一个高效的 CNN Transformer Cooperation Network CTCNet,用于人脸超分辨率任务,它使用多尺度连接的编码器解码器架构作为主干。具体来说,我们首先设计了一种新颖的局部全局特征协作模块 LGCM,该模块由面部结构注意单元 FSAU 和 Transformer 块组成,以同时促进局部面部细节和全局面部结构恢复的一致性。然后,我们设计了一个高效的局部特征细化模块LFRM来增强局部面部结构信息。最后,为了进一步改善面部细节的恢复,我们提出了一个多尺度特征融合单元 MFFU,以自适应地融合编码器过程中不同阶段的特征。 |
| Not All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer Authors Wang Zeng, Sheng Jin, Wentao Liu, Chen Qian, Ping Luo, Ouyang Wanli, Xiaogang Wang 视觉转换器在许多计算机视觉任务中取得了巨大的成功。大多数方法通过将图像分割成规则和固定的网格并将每个单元视为一个标记来生成视觉标记。然而,在以人为中心的视觉任务中,并非所有区域都同等重要,例如,人体需要具有许多标记的精细表示,而图像背景可以由几个标记建模。为了解决这个问题,我们提出了一种新颖的 Vision Transformer,称为 Token Clustering Transformer TCFormer,它通过渐进式聚类合并令牌,其中令牌可以从不同位置以灵活的形状和大小合并。 TCFormer中的token不仅可以聚焦重要区域,还可以调整token形状以适应语义概念,并对包含关键细节的区域采用精细的分辨率,有利于捕获详细信息。大量实验表明,TCFormer 在不同的具有挑战性的以人为中心的任务和数据集上始终优于其同行,包括 COCO WholeBody 上的全身姿势估计和 3DPW 上的 3D 人体网格重建。 |
| ActAR: Actor-Driven Pose Embeddings for Video Action Recognition Authors Soufiane Lamghari, Guillaume Alexandre Bilodeau, Nicolas Saunier 视频中的人体动作识别 HAR 是视频理解的核心任务之一。基于视频序列,目标是识别人类执行的动作。虽然 HAR 在可见光谱中受到了很多关注,但对红外视频中的动作识别的研究却很少。由于序列中存在冗余且无法区分的纹理特征,因此在红外域中准确识别人类动作是一项极具挑战性的任务。此外,在某些情况下,挑战来自多个活跃人员的存在所引发的不相关信息,这些信息对实际感兴趣的行动没有贡献。因此,大多数现有方法都考虑了一个没有考虑这些挑战的标准范式,这在一定程度上是由于在某些情况下识别任务的模糊定义。在本文中,我们提出了一种新方法,该方法可以同时学习有效识别红外光谱中的人类动作,同时自动识别执行动作的关键参与者,而无需使用任何先验知识或显式注释。我们的方法由三个阶段组成。在第一阶段,执行基于光流的关键角色识别。然后对于每个关键演员,我们估计将指导帧选择过程的关键姿势。为了提高动作表示的质量,执行了尺度不变的编码过程以及嵌入式姿势过滤。 |
| Quaternion Optimized Model with Sparse Regularization for Color Image Recovery Authors Liqiao Yang, Yang Liu, Kit Ian Kou 本文根据在变换域中以稀疏正则化为特征的低秩四元数矩阵优化来解决彩色图像补全问题。这项研究的灵感来自对不同信号类型(包括音频格式和图像)的认识,这些信号类型在各自的基础上具有固有的稀疏结构。由于彩色图像可以在四元数域中作为一个整体进行处理,我们在四元数离散余弦变换 QDCT 域中描述了彩色图像的稀疏性。此外,彩色图像固有的低秩结构的表示是四元数矩阵完成问题中的一个重要问题。为了实现更优越的低秩近似,在所提出的模型中采用了基于四元数的截断核范数 QTNN。此外,该模型通过基于该算法的乘法器 ADMM 的有效交替方向方法得到促进。 |
| Self-Supervised Equivariant Learning for Oriented Keypoint Detection Authors Jongmin Lee, Byungjin Kim, Minsu Cho 从图像中检测鲁棒的关键点是许多计算机视觉问题的一个组成部分,关键点的特征方向和尺度对于关键点的描述和匹配起着重要的作用。现有的基于学习的关键点检测方法依赖于标准平移等变 CNN,但通常无法针对几何变化检测可靠的关键点。为了学习检测稳健的面向关键点,我们引入了一个使用旋转等变 CNN 的自我监督学习框架。我们通过合成变换生成的图像对提出了密集的方向对齐损失,用于训练基于直方图的方向图。 |
| Metamorphic Testing-based Adversarial Attack to Fool Deepfake Detectors Authors Nyee Thoang Lim, Meng Yi Kuan, Muxin Pu, Mei Kuan Lim, Chun Yong Chong Deepfakes 利用人工智能 AI 技术创建合成媒体,其中一个人的肖像被另一个人取代。越来越多的人担心 deepfakes 可能被恶意用于创建误导性和有害的数字内容。随着深度伪造变得越来越普遍,迫切需要深度伪造检测技术来帮助发现深度伪造媒体。目前的 deepfake 检测模型能够达到出色的准确度 90 。但是,它们中的大多数仅限于数据集场景,其中相同的数据集用于训练和测试。大多数模型在跨数据集场景中的泛化能力不够好,其中模型在来自其他来源的看不见的数据集上进行测试。此外,最先进的深度伪造检测模型依赖于基于神经网络的分类模型,这些模型已知容易受到对抗性攻击。出于对强大的 deepfake 检测模型的需求,本研究采用变质测试 MT 原则来帮助识别可能影响所检查模型的稳健性的潜在因素,同时克服该领域的测试预言问题。变形测试被特别选择作为测试技术,因为它符合我们的需求,即基于潜在的大输入域,使用来自主要黑盒组件的概率结果来解决基于学习的系统测试。我们对 MesoInception 4 和 TwoStreamNet 模型进行了评估,它们是最先进的 deepfake 检测模型。这项研究将化妆应用程序确定为可以欺骗深度伪造检测器的对抗性攻击。 |
| Image Data Augmentation for Deep Learning: A Survey Authors Suorong Yang, Weikang Xiao, Mengcheng Zhang, Suhan Guo, Jian Zhao, Furao Shen 深度学习在许多计算机视觉任务中取得了显著成果。深度神经网络通常依赖大量的训练数据来避免过度拟合。但是,现实世界应用程序的标记数据可能是有限的。 |
| A Tour of Visualization Techniques for Computer Vision Datasets Authors Bilal Alsallakh, Pamela Bhattacharya, Vanessa Feng, Narine Kokhlikyan, Orion Reblitz Richardson, Rahul Rajan, David Yan 我们调查了许多用于分析计算机视觉 CV 数据集的数据可视化技术。这些技术通过应用数据集级别的分析,帮助我们了解此类数据中的属性和潜在模式。我们提供了各种示例,说明此类分析如何帮助预测数据集属性对 CV 模型的潜在影响,并为适当缓解其缺点提供信息。 |
| A Region-Based Deep Learning Approach to Automated Retail Checkout Authors Maged Shoman, Armstrong Aboah, Alex Morehead, Ye Duan, Abdulateef Daud, Yaw Adu Gyamfi 一般而言,在传统零售店实现产品结账流程自动化是一项将对社会产生重大影响的任务。为此,可靠的深度学习模型能够实现自动产品计数以快速客户结账,可以使这一目标成为现实。在这项工作中,我们提出了一种新颖的、基于区域的深度学习方法,使用定制的 YOLOv5 对象检测管道和 DeepSORT 算法来自动化产品计数。我们对具有挑战性的真实世界测试视频的结果表明,我们的方法可以将其预测推广到足够准确的水平,并且运行时间足够快,以保证部署到真实世界的商业环境中。 |
| VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance Authors Katherine Crowson, Stella Biderman, Daniel Kornis, Dashiell Stander, Eric Hallahan, Louis Castricato, Edward Raff 从开放域文本提示生成和编辑图像是一项具有挑战性的任务,迄今为止需要昂贵且经过特殊训练的模型。我们为这两个任务展示了一种新颖的方法,该方法能够通过使用多模态编码器来指导图像生成,无需任何训练即可从具有显着语义复杂性的文本提示中生成高视觉质量的图像。我们在各种任务中演示了如何使用 CLIP 37 来引导 VQGAN 11 产生比先前不太灵活的方法(如 DALL E 38、GLIDE 33 和 Open Edit 24)更高的视觉质量输出,尽管没有针对所提出的任务进行培训。 |
| A Novel Region Duplication Detection Algorithm Based on Hybrid Approach Authors Kshipra Tatkare, Manoj Devare 由于高带宽互联网的容易获得,来自各种来源的数字图像无处不在。数字图像很容易被善意或恶意篡改。数字图像中预嵌入信息的不可用性使得在数字取证的情况下篡改检测过程更加困难。因此,被动图像篡改难以检测。有多种算法可用于检测图像篡改。然而,这些算法有一些缺点,因此无法检测到所有类型的篡改。在本文中,研究人员打算通过基于示例的方法来介绍图像篡改的类型及其检测技术。 |
| Dress Code: High-Resolution Multi-Category Virtual Try-On Authors Davide Morelli, Matteo Fincato, Marcella Cornia, Federico Landi, Fabio Cesari, Rita Cucchiara 基于图像的虚拟试穿力求将服装项目的外观转移到目标人物的图像上。之前的工作主要集中在上身衣服上,例如T 恤、衬衫和上衣,忽略全身或下半身物品。这一缺点源于一个主要因素,当前用于基于图像的虚拟试穿的公开可用数据集没有考虑到这种多样性,从而限制了该领域的进展。为了解决这个缺陷,我们引入了着装规范,其中包含多类别服装的图像。 Dress Code 比基于图像的虚拟试穿的公开可用数据集大 3 倍以上,并且具有 1024 x 768 的高分辨率配对图像和前视图、全身参考模型。为了生成具有高视觉质量和丰富细节的高清试图像,我们建议学习细粒度的判别特征。具体来说,我们利用语义感知鉴别器在像素级别而不是图像或补丁级别进行预测。广泛的实验评估表明,所提出的方法在视觉质量和定量结果方面超过了基线和最先进的竞争对手。 |
| Spot the Difference: A Novel Task for Embodied Agents in Changing Environments Authors Federico Landi, Roberto Bigazzi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara 具身人工智能是最近的一个研究领域,旨在创建可以在环境中移动和操作的智能代理。该领域的现有方法要求智能体在全新和未探索的场景中行动。但是,此设置与需要在同一环境中执行多个任务的实际用例相去甚远。即使环境随时间发生变化,代理仍然可以依靠其关于场景的全局知识,同时尝试使其内部表示适应环境的当前状态。为了朝着这个设置迈出一步,我们提出了 Spot the Difference 一项针对具体 AI 的新任务,其中代理可以访问过时的环境地图,并且需要在固定的时间预算内恢复正确的布局。为此,我们从现有的 3D 空间数据集开始收集一个新的占用地图数据集,并为单个环境生成许多可能的布局。该数据集可以在流行的 Habitat 模拟器中使用,并且完全符合在导航期间使用重建的占用地图的现有方法。此外,我们提出了一种探索策略,可以利用先前的环境知识,比现有代理更快、更有效地识别场景中的变化。 |
| Inductive Biases for Object-Centric Representations of Complex Textures Authors Samuele Papa, Ole Winther, Andrea Dittadi 了解哪些归纳偏差可能对自然场景的以对象为中心的表示的无监督学习有用是具有挑战性的。在这里,我们使用神经风格迁移来生成数据集,其中对象具有复杂的纹理,同时仍保留地面实况注释。 |
| Simultaneous Multiple-Prompt Guided Generation Using Differentiable Optimal Transport Authors Yingtao Tian, Marco Cuturi, David Ha 深度学习的最新进展,例如强大的生成模型和联合文本图像嵌入,为计算创造力社区提供了新工具,为艺术追求开辟了新视角。通过从文本提示生成图像来操作的文本到图像合成方法提供了一个很好的例子。这些图像是使用一个潜在向量生成的,该向量被逐渐细化以与文本提示一致。为此,在生成的图像中对补丁进行采样,并与公共文本图像嵌入空间中的文本提示进行比较,然后使用梯度下降更新潜在向量,以减少这些补丁和文本提示之间的平均距离。虽然这种方法为艺术家提供了足够的自由来定制图像的整体外观,但通过他们在生成模型中的选择,对距离的简单标准平均值的依赖通常会导致模式崩溃整个图像被绘制到所有文本提示的平均值,从而失去他们的多样性。为了解决这个问题,我们建议使用最佳运输 OT 文献中的匹配技术,从而生成能够忠实反映各种提示的图像。 |
| Hand Geometry Based Recognition with a MLP Classifier Authors Marcos Faundez Zanuy, Miguel A. Ferrer Ballester, Carlos M. Travieso Gonz lez, Virginia Espinosa Duro 本文提出了一种基于手几何的生物特征识别系统。我们描述了一个专门为研究目的而收集的数据库,其中包括 50 个人和 10 次不同的右手采集。这个数据库可以免费下载。此外,我们描述了一个特征提取过程,并使用基于多层感知器 MLP 的不同分类策略获得了实验结果。我们已经评估了验证应用程序的识别率和检测成本函数 DCF 值。 |
| Face recognition with small and large size databases Authors Josep roure Alcob , Marcos Faundez Zanuy 本文介绍了使用 ORL 40 人和 FERET 994 人数据库的实验结果。 ORL 数据库可用于保护预期很少有用户尝试访问的应用程序。例如,PDA 或 PC 就是这种情况,其中密码是用户的脸。 |
| Machine Learning-Based Automated Thermal Comfort Prediction: Integration of Low-Cost Thermal and Visual Cameras for Higher Accuracy Authors Roshanak Ashrafi, Mona Azarbayjani, Hamed Tabkhi 最近的研究试图利用建筑控制回路中的居住者需求来考虑个人福祉和建筑节能。为此,需要一个实时反馈系统来提供有关居住者舒适状况的数据,这些数据可用于控制建筑物的供暖、制冷和空调 HVAC 系统。热成像技术的出现为非接触式数据收集提供了绝佳的机会,而不会中断居住者的条件和活动。由于红外热像仪在读取人体皮肤温度方面的非侵入性质量,人们越来越关注公共建筑中红外热像仪的使用。然而,最先进的方法需要额外的修改才能变得更可靠。为了充分利用潜力并解决一些现有限制,需要新的解决方案通过利用机器学习和图像处理的优势,为非侵入式热扫描带来更全面的视角。这项研究实施了一种自动化方法来收集和注册同时的热图像和视觉图像,并读取不同区域的面部温度。本文还提出了两项额外的调查。首先,通过在额头区域使用 IButton 可穿戴热传感器,我们研究了昂贵的热像仪 FLIR Lepton 在读取皮肤温度方面的可靠性。其次,通过研究热图像的假彩色版本,我们研究了非辐射热图像预测个性化热舒适度的可能性。结果显示了随机森林和 K 最近邻预测算法在预测个性化热舒适度方面的强大性能。 |
| Investigating Temporal Convolutional Neural Networks for Satellite Image Time Series Classification Authors James Brock, Zahraa S. Abdallah 地球表面的卫星图像时间序列 SITS 提供了详细的土地覆盖图,其空间和时间维度的质量不断提高。这些图像时间序列对于开发旨在生成准确、最新的地球表面土地覆盖图的系统是不可或缺的。应用范围很广,著名的例子包括生态系统测绘、植被过程监测和人为土地利用变化跟踪。最近提出的 SITS 分类方法已显示出可观的优点,但这些方法往往缺乏利用数据时间维度的本地机制,这通常会导致大量数据预处理过长的训练时间。为了克服这些缺点,本文试图从文献中研究和增强新提出的 SITS 分类方法,即时间 CNN。在两个基准 SITS 数据集上进行了综合实验,结果表明 Temporal CNN 对两个数据集的基准算法都表现出优越或具有竞争力的性能。 |
| 3D Convolutional Networks for Action Recognition: Application to Sport Gesture Recognition Authors Pierre Etienne Martin LaBRI, MPI EVA, UB , J Benois Pineau, R P teri, A Zemmari, J Morlier 3D 卷积网络是执行任务的好方法,例如将视频分割成连贯的时空块并根据目标分类对它们进行分类。在本章中,我们对具有可重复动作的连续视频镜头的分类感兴趣,例如乒乓球的击球动作。这些视频是在无标记的生态环境中拍摄的,从分割和分类的角度来看都是一个挑战。 |
| SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix Data Augmentation Authors Karim Hammoudi, Adnane Cabani, Bouthaina Slika, Halim Benhabiles, Fadi Dornaika, Mahmoud Melkemi 提出了一种基于不规则超像素分解的数据增强新方法。这种称为 SuperpixelGridMasks 的方法允许扩展机器学习相关分析架构的训练阶段所需的原始图像数据集,以提高其性能。提出了三个变体,名为 SuperpixelGridCut、SuperpixelGridMean 和 SuperpixelGridMix。这些基于网格的方法使用信息的丢弃和融合产生了一种新的图像转换样式。使用各种图像分类模型和数据集的大量实验表明,使用我们的方法可以显着优于基线性能。比较研究还表明,我们的方法可以超越其他数据增强的性能。在不同性质的图像识别数据集上获得的实验结果表明了这些新方法的有效性。 |
| Efficient Deep Learning-based Estimation of the Vital Signs on Smartphones Authors Taha Samavati, Mahdi Farvardin 如今,由于智能手机在日常生活中的广泛使用以及这些设备计算能力的提高,现在可以在它们上部署许多复杂的任务。关于持续监测生命体征的需求,特别是对于老年人或患有某些类型疾病的人,可以使用智能手机估计生命体征的算法的开发吸引了全世界的研究人员。此类算法通过处理输入 PPG 信号来估计生命体征心率和氧饱和度水平。这些方法通常在预测步骤之前对输入信号应用多个预处理步骤。这会增加这些方法的计算复杂性,这意味着只有有限数量的移动设备可以运行它们。此外,多个预处理步骤还需要设计几个手工制作的阶段才能获得最佳结果。本研究提出了一种新颖的端到端解决方案,用于通过深度学习进行基于移动的生命体征估计。所提出的方法不需要任何预处理。由于使用了全卷积架构,我们提出的模型的参数数量平均是使用全连接层作为预测头的普通架构的四分之一。因此,所提出的模型具有较少的过拟合机会和计算复杂度。还提供了一个用于生命体征估计的公共数据集,包括从 35 名男性和 27 名女性收集的 62 个视频。 |
| Revisiting Vicinal Risk Minimization for Partially Supervised Multi-Label Classification Under Data Scarcity Authors Nanqing Dong, Jiayi Wang, Irina Voiculescu 由于注释的人力成本很高,因此管理一个针对所有感兴趣的类别完全标记的大规模医疗数据集并非易事。相反,从不同的匹配源收集多个部分标记的小数据集会很方便,其中医学图像可能只针对感兴趣类别的子集进行了注释。本文提供了对一个正在探索的问题的经验理解,即部分监督的多标签分类 PSMLC,其中多标签分类器仅使用部分标记的医学图像进行训练。与完全监督的对应物相比,由医疗数据稀缺引起的部分监督对模型性能有不小的负面影响。一种潜在的补救措施可能是增加部分标签。尽管邻域风险最小化 VRM 已成为提高模型泛化能力的有前途的解决方案,但其在 PSMLC 中的应用仍然是一个悬而未决的问题。为了弥补方法上的差距,我们为 PSMLC 提供了第一个基于 VRM 的解决方案。 |
| Deep learning-based surrogate model for 3-D patient-specific computational fluid dynamics Authors Pan Du, Xiaozhi Zhu, Jian Xun Wang 优化和不确定性量化在计算血流动力学中发挥着越来越重要的作用。然而,基于原则建模和经典数值技术的现有方法面临着重大挑战,尤其是在现实世界中复杂的 3D 患者特定形状方面。首先,参数化任意复杂的 3D 几何图形的输入空间是出了名的具有挑战性。其次,该过程通常涉及大量的前向模拟,这对计算的要求非常高,甚至是不可行的。我们提出了一种新颖的深度学习替代建模解决方案来应对这些挑战并实现快速的血流动力学预测。具体而言,基于一小组基线患者特定几何形状开发了 3D 患者特定形状的统计生成模型。无监督的形状对应解决方案用于在统计上实现几何变形和可扩展的形状合成。此外,还开发了一个模拟程序,用于通过自动网格划分、边界设置、模拟和后处理来自动生成数据。提出了一种有效的监督学习解决方案,将几何输入映射到潜在空间中的血流动力学预测。 |
| Two-Stream Graph Convolutional Network for Intra-oral Scanner Image Segmentation Authors Yue Zhao, Lingming Zhang, Yang Liu, Deyu Meng, Zhiming Cui, Chenqiang Gao, Xinbo Gao, Chunfeng Lian, Dinggang Shen 从口腔内扫描仪图像中精确分割牙齿是计算机辅助正畸手术计划中的一项重要任务。最先进的基于深度学习的方法通常简单地连接原始几何属性,即网格单元的坐标和法线向量,以训练用于自动口腔扫描仪图像分割的单流网络。然而,由于不同的原始属性揭示了完全不同的几何信息,在低级输入阶段不同原始属性的朴素连接可能会在描述和区分网格单元时带来不必要的混淆,从而阻碍分割任务的高级几何表示的学习.为了解决这个问题,我们设计了一个双流图卷积网络,即 TSGCN,它可以有效地处理不同原始属性之间的视图混淆,从而更有效地融合它们的互补信息并学习有区别的多视图几何表示。具体来说,我们的 TSGCN 采用两个输入特定的图学习流来分别从坐标和法线向量中提取互补的高级几何表示。然后,这些单视图表示进一步由自我关注模块融合,以自适应地平衡不同视图在学习更具区分性的多视图表示中的贡献,以实现准确和全自动的牙齿分割。我们已经在由 3D 口内扫描仪获取的牙科网格模型的真实患者数据集上评估了我们的 TSGCN。实验结果表明,我们的 TSGCN 在 3D 牙齿表面分割方面明显优于最先进的方法。 |
| Jacobian Ensembles Improve Robustness Trade-offs to Adversarial Attacks Authors Kenneth T. Co, David Martinez Rego, Zhongyuan Hau, Emil C. Lupu 深度神经网络已成为我们软件基础设施不可或缺的一部分,并被部署在许多广泛使用的安全关键应用程序中。然而,它们与许多系统的集成也带来了以 Universal Adversarial Perturbations UAP 的形式测试时间攻击的漏洞。 UAP 是一类扰动,当应用于任何输入时会导致模型错误分类。尽管一直在努力保护模型免受这些对抗性攻击,但通常很难在模型准确性和对抗性攻击的鲁棒性之间进行权衡。雅可比正则化已被证明可以提高模型对 UAP 的鲁棒性,而模型集成已被广泛用于提高预测性能和模型鲁棒性。在这项工作中,我们提出了一种新颖的方法,Jacobian Ensembles,它结合了 Jacobian 正则化和模型集成,以显着提高针对 UAP 的鲁棒性,同时保持或提高模型的准确性。 |
| Software Engineering Approaches for TinyML based IoT Embedded Vision: A Systematic Literature Review Authors Shashank Bangalore Lakshman, Nasir U. Eisty 物联网物联网通过无处不在的传感、通信、计算和驱动,提升了人类控制环境的能力。在过去的几年里,物联网与机器学习 ML 联手在远端嵌入深度智能。 TinyML Tiny Machine Learning 支持在极其精简的边缘硬件上部署用于嵌入式视觉的 ML 模型,将 IoT 和 ML 的力量结合在一起。然而,TinyML 支持的嵌入式视觉应用仍处于初期阶段,它们刚刚开始扩展到广泛的现实世界物联网部署。为了发挥 IoT 和 ML 的真正潜力,有必要为产品开发人员提供强大、易于使用的软件工程 SE 框架和最佳实践,这些框架和最佳实践针对 TinyML 工程面临的独特挑战进行了定制。通过这个系统的文献回顾,我们汇总了 TinyML 开发人员报告的关键挑战,并确定了大规模计算机视觉、机器学习和嵌入式系统中最先进的 SE 方法,这些方法可以帮助解决基于 TinyML 的物联网嵌入式视觉中的关键挑战。 |
| A Thin Format Vision-Based Tactile Sensor with A Micro Lens Array (MLA) Authors Xia Chen, Guanlan Zhang, Michael Yu Wang, Hongyu Yu 基于视觉的触觉传感器已在机器人领域得到广泛研究,以实现高空间分辨率和与机器学习算法的兼容性。然而,目前采用的传感器成像系统体积庞大,限制了其进一步的应用。在这里,我们提出了一种基于微透镜阵列 MLA 的视觉系统,以实现具有高触觉传感性能的传感器封装的低厚度格式。多个微加工微透镜单元覆盖整个弹性触摸层,提供缝合清晰的触觉图像,实现高空间分辨率,厚度仅为 5 毫米。热回流和软光刻方法确保了微透镜的均匀球面轮廓和光滑表面。 |
| Interaction-Aware Labeled Multi-Bernoulli Filter Authors Nida Ishtiaq, Amirali Khodadadian Gostar, Alireza Bab Hadiashar, Reza Hoseinnezhad 通过时间跟踪多个对象是智能交通系统的重要组成部分。基于随机有限集 RFS 的滤波器是用于跟踪多个对象的新兴技术之一。在多目标跟踪 MOT 中,一个常见的假设是每个目标都独立于其周围环境移动。但在许多现实世界的应用程序中,目标对象与彼此和环境交互。当考虑进行跟踪时,此类交互通常由特定于应用程序的交互式运动模型建模。在本文中,我们提出了一种在基于 RFS 的多目标滤波器(即标记为多伯努利 LMB 滤波器)的预测步骤中结合目标交互的新方法。该方法已被开发用于跟踪协调的群体和车辆的两个实际应用。该方法已经针对复杂的车辆跟踪数据集进行了测试,并通过 OSPA 和 OSPA 2 指标与 LMB 过滤器进行了比较。 |
| Topology and geometry of data manifold in deep learning Authors German Magai, Anton Ayzenberg 尽管深度学习领域在各个领域的应用取得了重大进展,但解释深度学习模型的内部过程仍然是一个重要且悬而未决的问题。本文的目的是描述和证实神经网络学习过程的几何和拓扑视图。我们的注意力集中在神经网络的内部表示以及不同层上数据流形的拓扑和几何形状变化的动力学上。我们还提出了一种基于拓扑描述符评估神经网络泛化能力的方法。在本文中,我们使用拓扑数据分析和内在维度的概念,并对不同数据集和卷积神经网络架构的不同配置进行了广泛的实验。此外,我们还考虑了分类任务中对抗性攻击的几何问题和对人脸识别系统的欺骗攻击。 |
| CorrGAN: Input Transformation Technique Against Natural Corruptions Authors Mirazul Haque, Christof J. Budnik, Wei Yang 由于深度神经网络 DNN 在不同任务上的准确性不断提高,许多实时系统都在使用 DNN。这些 DNN 容易受到对抗性扰动和破坏。具体来说,雾、模糊、对比度等自然损坏会影响自动驾驶汽车中 DNN 的预测。需要实时检测这些损坏,并且还需要对损坏的输入进行去噪以正确预测。在这项工作中,我们提出了 CorrGAN 方法,该方法可以在提供损坏的输入时生成良性输入。在这个框架中,我们用新颖的基于中间输出的损失函数来训练生成对抗网络 GAN。 GAN 可以对损坏的输入进行去噪并生成良性输入。 |
| DeepCore: A Comprehensive Library for Coreset Selection in Deep Learning Authors Chengcheng Guo, Bo Zhao, Yanbing Bai Coreset selection 旨在选择信息量最大的训练样本的子集,是一个长期存在的学习问题,可以使许多下游任务受益,例如数据高效学习、持续学习、神经架构搜索、主动学习等。然而,许多现有的核心集选择方法不是为深度学习设计的,它可能具有高复杂性和对看不见的表示的泛化能力差。此外,最近提出的方法在不同复杂度的模型、数据集和设置上进行了评估。为了推进深度学习中核心集选择的研究,我们贡献了一个综合代码库,即 DeepCore,并对 CIFAR10 和 ImageNet 数据集上流行的核心集选择方法进行了实证研究。 |
| Active Learning Helps Pretrained Models Learn the Intended Task Authors Alex Tamkin, Dat Nguyen, Salil Deshpande, Jesse Mu, Noah Goodman 当多种行为与提供的训练数据一致时,由于任务模糊性,模型可能会在部署过程中以不可预知的方式失败。一个例子是在遇到蓝色方块时在红色方块和蓝色圆圈上训练的对象分类器,预期的行为是未定义的。我们调查预训练模型是否是更好的主动学习者,能够消除用户可能试图指定的可能任务之间的歧义。有趣的是,我们发现更好的主动学习是预训练过程的一个新兴属性,当使用基于不确定性的主动学习时,预训练模型需要的标签数量减少多达 5 倍,而非预训练模型则看不到甚至是负面的好处。我们发现这些收益来自于选择具有消除预期行为歧义的属性的示例的能力,例如稀有产品类别或非典型背景。 |
| Enhancing Non-mass Breast Ultrasound Cancer Classification With Knowledge Transfer Authors Yangrun Hu, Yuanfan Guo, Fan Zhang, Mingda Wang, Tiancheng Lin, Rong Wu, Yi Xu 基于深度神经网络 DNN 的乳腺超声 BUS 图像诊断肿块病变取得了很大进展。然而,由于数据有限,对非肿块病变的研究较少。基于海量数据就足够并且与基于超声图像识别病变恶性程度的非海量数据共享相同知识结构的见解,我们提出了一种新的迁移学习框架,以增强非海量 DNN 模型的泛化性。 BUS借助大众BUS。具体来说,我们训练了一个包含非海量和海量数据的共享 DNN。由于输入和输出空间中不同边际分布的先验,我们在提出的迁移学习框架中采用了两种域对齐策略,具有捕获域特定分布的洞察力来解决域偏移问题。此外,我们提出了一个名为 CrossMix 的跨域语义保留数据生成模块,以恢复训练数据中未呈现的非海量数据和海量数据之间的缺失分布。 |
| Self Supervised Lesion Recognition For Breast Ultrasound Diagnosis Authors Yuanfan Guo, Canqian Yang, Tiancheng Lin, Chunxiao Li, Rui Zhang, Yi Xu 以前基于深度学习的计算机辅助诊断 CAD 系统将同一病变的多个视图视为独立图像。由于超声图像仅描述了 3D 病变的部分 2D 投影,因此这种范式忽略了病变不同视图之间的语义关系,这与超声医师从至少两个视图分析病变的传统诊断不一致。在本文中,我们提出了一个多任务框架,用病变识别 LR 补充良性恶性分类任务,这有助于利用单个病变的多个视图之间的关系来学习病变的完整表示。具体来说,LR 任务采用对比学习来鼓励表示,该表示可以提取同一病变的多个视图并排斥不同病变的视图。因此,该任务有助于表示不仅对病变的视图变化保持不变,而且还捕获细粒度特征以区分不同的病变。 |
| U-Net and its variants for Medical Image Segmentation : A short review Authors Vinay Ummadi 这篇论文是对使用 U Net 及其变体进行医学图像分割的简短回顾。据我们了解,对于放射科医生或病理学家的任何临床医生来说,浏览医学图像都不是一件容易的事。分析医学图像是进行无创诊断的唯一方法。分割出感兴趣的区域在医学图像中具有重要意义,并且是诊断的关键。本文还概述了医学图像分割是如何演变的。还讨论了深度神经架构的挑战和成功。跟随不同的混合架构如何建立在视觉识别任务的强大技术之上。 |
| IOP-FL: Inside-Outside Personalization for Federated Medical Image Segmentation Authors Meirui Jiang, Hongzheng Yang, Chen Cheng, Qi Dou 联邦学习 FL 允许多个医疗机构协作学习全球模型,而无需集中所有客户数据。由于来自各种扫描仪和患者人口统计数据的医疗数据的异质性,这种全局模型很难(如果可能的话)通常为每个客户实现最佳性能。当将全局模型部署到 FL 之外的看不见的客户端时,这个问题变得更加严重,并且在联邦训练期间没有提供新的分布。为了优化每个客户对关键医疗任务的预测准确性,我们提出了一个新颖的统一框架,用于 FL IOP FL 中的内部和外部模型个性化。我们的内部个性化是通过一种基于轻量级梯度的方法来实现的,该方法利用每个客户端的局部适应模型,通过累积全局梯度以获取常识和局部梯度以进行特定于客户端的优化。此外,重要的是,获得的局部个性化模型和全局模型可以形成一个多样化和信息丰富的路由空间,为外部 FL 客户个性化一个新模型。因此,在给定测试数据传达的分布信息的情况下,我们设计了一种新的测试时间路由方案,其灵感来自具有形状约束的一致性损失来动态合并模型。我们在两个医学图像分割任务上的广泛实验结果在内部和外部个性化方面都比 SOTA 方法有显着改进,证明了我们的 IOP FL 方案在临床实践中的巨大潜力。 |
| Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography Authors Binjie Qin, Haohao Mao, Yiming Liu, Jun Zhao, Yisong Lv, Yueqi Zhu, Song Ding, Xu Chen 尽管稳健的 PCA 已越来越多地用于从 X 射线冠状动脉造影 XCA 图像中提取血管,但诸如血管稀疏建模效率低下、噪声和动态背景伪影以及高计算成本等具有挑战性的问题仍未解决。因此,我们提出了一种具有稀疏特征选择的新型鲁棒 PCA 展开网络,用于超分辨率 XCA 血管成像。嵌入在基于池化层和卷积长期短期记忆网络的补丁明智时空超分辨率框架中,所提出的网络不仅可以在网络训练期间逐渐修剪复杂的血管,如 XCA 中的伪影和嘈杂的背景,而且还可以迭代学习并选择在 XCA 成像血管中流动的运动造影剂的高级时空语义信息。 |
| CapillaryX: A Software Design Pattern for Analyzing Medical Images in Real-time using Deep Learning Authors Maged Abdalla Helmy Abdou, Paulo Ferreira, Eric Jul, Tuyen Trung Truong 数字成像的最新进展,例如,捕获的像素数量增加,意味着要从这些图像中处理和分析的数据量也增加了。深度学习算法是分析此类图像的最新技术,因为它们在使用大量数据进行训练时具有很高的准确性。然而,这样的分析需要相当大的计算能力,使得这样的算法需要时间和资源。使用第三方云服务提供商可以满足如此高的要求。然而,使用此类服务分析医学图像会带来一些法律和隐私方面的挑战,并且不一定能提供实时结果。本文提供了一种计算架构,可以在本地并行地使用深度学习实时分析医学图像,从而避免将数据上传到第三方云提供商所带来的法律和隐私挑战。为了在现代多核处理器上提高本地图像处理效率,我们利用并行执行来抵消深度神经网络的资源密集型需求。我们专注于一个特定的医疗行业案例研究,即我们开发了一个工作系统的微循环图像中的血管量化。它目前作为电子健康应用程序的一部分用于工业、临床研究环境中。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com