【Transformers】第 9 章 :处理很少或没有标签
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
构建 GitHub 问题标记器
获取数据
准备数据
创建训练集
创建训练切片
实现朴素贝叶斯线
使用无标签数据
使用几个标签
数据增强
使用嵌入作为查找表
微调Vanilla Transformer
带提示的上下文和小样本学习
利用未标记的数据
微调语言模型
微调分类器
高级方法
无监督数据增强
不确定性自我训练
结论
有一个问题在每个数据科学家的脑海中根深蒂固,以至于他们通常在新项目开始时问的第一件事是:是否有任何标记数据?通常情况下,答案是“不”或“有一点点”,然后客户期望您团队的精美机器学习模型仍然表现良好。由于在非常小的数据集上训练模型通常不会产生好的结果,一个明显的解决方案是注释更多的数据。但是,这需要时间并且可能非常昂贵,特别是如果每个注释都需要领域专业知识来 验证。
幸运的是,有几种方法非常适合处理很少或没有标签的情况!您可能已经熟悉其中的一些,例如零样本或少样本学习,正如 GPT-3 仅用几十个示例执行各种任务的令人印象深刻的能力所证明的那样。
一般来说,表现最好的方法将取决于任务、可用数据的数量以及该数据的哪一部分被标记。图 9-1所示的决策树可以帮助指导我们选择最合适的方法。

图 9-1。在没有大量标记数据的情况下可用于提高模型性能的几种技术
让我们一步一步地浏览这个决策树:
1.你有标签数据吗?
即使是少数标记的样本也可以决定哪种方法最有效。如果您根本没有标记数据,您可以从零样本学习方法开始,这通常会设置一个强大的基线来工作。
2. 有多少个标签?
如果有标签数据可用,决定因素是多少。如果您有大量可用的训练数据,您可以使用第 2 章中讨论的标准微调方法 。
3. 你有未标记的数据吗?
如果您只有少量标记的样本,那么如果您可以访问大量未标记的数据,那么它会很有帮助。如果您可以访问未标记的数据,您可以在训练分类器之前使用它来微调域上的语言模型,或者您可以使用更复杂的方法,例如无监督数据增强 (UDA) 或不确定性感知自我训练 (美国东部时间)。1如果您没有任何可用的未标记数据,则无法选择注释更多数据。在这种情况下,您可以使用小样本学习或使用来自预训练语言模型的嵌入来执行最近邻搜索的查找。
在本章中,我们将通过解决许多使用Jira或 GitHub等问题跟踪器 来帮助其用户的支持团队所面临的一个常见问题来处理这个决策树:根据问题的描述使用元数据标记问题。这些标签可能定义问题类型、导致问题的产品或负责处理报告问题的团队。自动化此过程可以对生产力产生重大影响,并使支持团队能够专注于帮助他们的用户。作为一个运行示例,我们将使用与流行的开源项目相关的 GitHub 问题: Transformers!现在让我们看看这些问题中包含了哪些信息,如何构建任务,以及如何获取数据。
笔记
本章介绍的方法适用于文本分类,但可能需要其他技术(如数据增强)来处理更复杂的任务,如命名实体识别、问答或摘要。
构建 GitHub 问题标记器
如果您导航到 Transformers 存储库的“ 问题” 选项卡,您会发现 如图 9-2所示的问题,其中包含标题、描述和一组表征问题的标签或标签。这提出了一种构建监督学习任务的自然方法:给定一个问题的标题和描述,预测一个或多个标签。由于可以为每个问题分配可变数量的标签,这意味着我们正在处理多标签文本分类问题。这通常比我们在第 2 章中遇到的多类问题更具挑战性,在 第 2 章中,每条推文只分配给一种情绪。
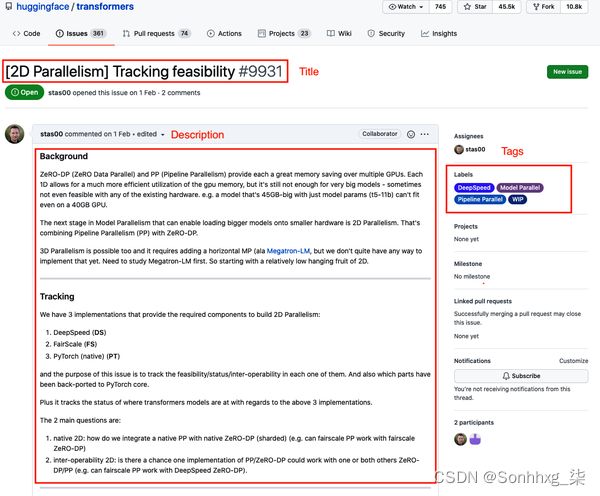
图 9-2。Transformers 存储库上的一个典型 GitHub 问题
现在我们已经看到了 GitHub 问题的样子,让我们看看如何下载它们来创建我们的数据集。
获取数据
为了获取存储库的所有问题,我们将使用GitHub REST API来轮询 Issues 端点。这个端点返回一个 JSON 对象列表,每个对象都包含大量关于手头问题的字段,包括其状态(打开或关闭)、谁打开了问题,以及我们在其中看到的标题、正文和标签图 9-2。
由于获取所有问题需要一段时间,我们在本书的 GitHub 存储库中包含了一个github-issues-transformers.jsonl文件,以及一个fetch_issues()您可以用来自己下载它们的函数。
笔记
GitHub REST API 将拉取请求视为问题,因此我们的数据集包含两者的混合。为简单起见,我们将为这两种类型的问题开发分类器,尽管在实践中您可能会考虑构建两个单独的分类器以对模型的性能进行更细粒度的控制。
现在我们知道如何获取数据,让我们来看看如何清理它。
准备数据
下载完所有问题后,我们可以使用 Pandas 加载它们:
import pandas as pd
dataset_url = "https://git.io/nlp-with-transformers"
df_issues = pd.read_json(dataset_url, lines=True)
print(f"DataFrame shape: {df_issues.shape}")DataFrame shape: (9930, 26)
我们的数据集中有近 10,000 个问题,通过查看一行我们可以看到从 GitHub API 检索到的信息包含许多字段,例如 URL、ID、日期、用户、标题、正文以及标签:
cols = ["url", "id", "title", "user", "labels", "state", "created_at", "body"]
df_issues.loc[2, cols].to_frame()| 2 | |
|---|---|
| url | https://api.github.com/repos/huggingface/trans... |
| ID | 849529761 |
| title | [DeepSpeed] ZeRO stage 3 integration: getting ... |
| user | {'login’: ’stas00', ‘id’: 10676103, ‘node_id’:... |
| labels | [{'id': 2659267025, 'node_id': 'MDU6TGFiZWwyNj... |
| state | open |
| created_at | 2021-04-02 23:40:42 |
| body | **[This is not yet alive, preparing for the re... |
该labels列是我们感兴趣的内容,每一行都包含一个 JSON 对象列表,其中包含有关每个标签的元数据:
[
{
"id":2659267025,
"node_id":"MDU6TGFiZWwyNjU5MjY3MDI1",
"url":"https://api.github.com/repos/huggingface...",
"name":"DeepSpeed",
"color":"4D34F7",
"default":false,
"description":""
}
]出于我们的目的,我们只对name每个标签对象的字段感兴趣,所以让我们只用标签名称覆盖该labels列:
df_issues["labels"] = (df_issues["labels"]
.apply(lambda x: [meta["name"] for meta in x]))
df_issues[["labels"]].head()| labels | |
|---|---|
| 0 | [] |
| 1 | [] |
| 2 | [DeepSpeed] |
| 3 | [] |
| 4 | [] |
现在列中的每一行labels都是 GitHub 标签列表,因此我们可以计算每行的长度以找到每个问题的标签数量:
df_issues["labels"].apply(lambda x : len(x)).value_counts().to_frame().T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| labels | 6440 | 3057 | 305 | 100 | 25 | 3 |
这表明大多数问题都有 0 个或 1 个标签,而具有多个标签的问题要少得多。接下来让我们看一下数据集中出现频率最高的 10 个标签。在 Pandas 中,我们可以通过“分解”labels列来做到这一点,以便列表中的每个标签变成一行,然后简单地计算每个标签的出现次数:
df_counts = df_issues["labels"].explode().value_counts()
print(f"Number of labels: {len(df_counts)}")
# Display the top-8 label categories
df_counts.to_frame().head(8).TNumber of labels: 65
| wontfix | model card | Core: Tokenization | New model | Core: Modeling | Help wanted | Good First Issue | Usage | |
|---|---|---|---|---|---|---|---|---|
| labels | 2284 | 649 | 106 | 98 | 64 | 52 | 50 | 46 |
我们可以看到数据集中有 65 个唯一标签,并且类别非常不平衡,wontfix并且model card是最常见的标签。为了使分类问题更易于处理,我们将专注于为标签的子集构建标注器。例如,某些标签(例如Good First Issue或Help Wanted)可能很难从问题的描述中预测,而其他标签(例如model card)可以使用检测模型卡何时添加到 Hugging Face Hub 的简单规则进行分类。
以下代码为我们将使用的标签子集过滤数据集,同时对名称进行标准化以使其更易于阅读:
label_map = {"Core: Tokenization": "tokenization",
"New model": "new model",
"Core: Modeling": "model training",
"Usage": "usage",
"Core: Pipeline": "pipeline",
"TensorFlow": "tensorflow or tf",
"PyTorch": "pytorch",
"Examples": "examples",
"Documentation": "documentation"}
def filter_labels(x):
return [label_map[label] for label in x if label in label_map]
df_issues["labels"] = df_issues["labels"].apply(filter_labels)
all_labels = list(label_map.values())现在让我们看看新标签的分布情况:
df_counts = df_issues["labels"].explode().value_counts()
df_counts.to_frame().T| tokenization | new model | model training | usage | pipeline | tensorflow or tf | pytorch | documentation | 例子 | |
|---|---|---|---|---|---|---|---|---|---|
| labels | 106 | 98 | 64 | 46 | 42 | 41 | 37 | 28 | 24 |
在本章的后面,我们会发现将未标记的问题视为单独的训练拆分很有用,因此让我们创建一个新列来指示问题是否未标记:
df_issues["split"] = "unlabeled"
mask = df_issues["labels"].apply(lambda x: len(x)) > 0
df_issues.loc[mask, "split"] = "labeled"
df_issues["split"].value_counts().to_frame()| split | |
|---|---|
| unlabeled | 9489 |
| labeled | 441 |
现在让我们看一个例子:
for column in ["title", "body", "labels"]:
print(f"{column}: {df_issues[column].iloc[26][:500]}\n")title: Add new CANINE model
body: # New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o
tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only
the title is exciting:
Pipelined NLP systems have largely been superseded by end-to-end neural
modeling, yet nearly all commonly-used models still require an explicit
tokenization step. While recent tokenization approaches based on data-derived
subword lexicons are less brittle than manually en
labels: ['new model']在这个例子中,提出了一个新的模型架构,所以new model 标签是有意义的。我们还可以看到title包含对我们的分类器有用的信息,所以让我们将它与body字段中的问题描述连接起来:
df_issues["text"] = (df_issues
.apply(lambda x: x["title"] + "\n\n" + x["body"], axis=1))在我们查看其余数据之前,让我们检查数据中的任何重复项并使用以下drop_duplicates() 方法删除它们:
len_before = len(df_issues)
df_issues = df_issues.drop_duplicates(subset="text")
print(f"Removed {(len_before-len(df_issues))/len_before:.2%} duplicates.")Removed 1.88% duplicates.
我们可以看到我们的数据集中有一些重复的问题,但它们只占一小部分。正如我们在其他章节中所做的那样,快速查看文本中的单词数量也是一个好主意,看看当我们截断到每个模型的上下文大小时是否会丢失很多信息:
import numpy as np
import matplotlib.pyplot as plt
(df_issues["text"].str.split().apply(len)
.hist(bins=np.linspace(0, 500, 50), grid=False, edgecolor="C0"))
plt.title("Words per issue")
plt.xlabel("Number of words")
plt.ylabel("Number of issues")
plt.show()
该分布具有许多文本数据集的长尾特征。大多数文本都很短,但也有超过 500 字的问题。有一些很长的问题是很常见的,尤其是当错误消息和代码片段与它们一起发布时。鉴于大多数 Transformer 模型的上下文大小为 512 个或更大,截断一些长问题不太可能影响整体性能。现在我们已经探索和清理了我们的数据集,最后要做的是定义我们的训练和验证集来对我们的分类器进行基准测试。让我们来看看如何做到这一点。
创建训练集
对于多标签问题,创建训练和验证集有点棘手,因为没有保证所有标签的平衡。但是,它可以近似,我们可以使用 专门为此目的设置的Scikit-multilearn 库。我们需要做的第一件事是将我们的标签集(例如pytorch和tokenization)转换为模型可以处理的格式。在这里,我们可以使用 Scikit-learn 的 MultiLabelBinarizer类,它采用标签名称列表并创建一个向量,其中零表示不存在的标签,而一表示存在标签。我们可以通过拟合来测试这一点,MultiLabelBinarizer以 all_labels学习从标签名称到 ID 的映射, 如下所示:
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
mlb.fit([all_labels])
mlb.transform([["tokenization", "new model"], ["pytorch"]])array([[0, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0]])
在这个简单的例子中,我们可以看到第一行有两个对应于tokenization和new model标签,而第二行只有一个命中pytorch。
要创建拆分,我们可以使用iterative_train_test_split() Scikit-multilearn 中的函数,它迭代地创建训练/测试拆分以实现平衡标签。我们将它包装在一个可以应用于 DataFrames 的函数中。由于该函数需要一个二维特征矩阵,因此我们需要在进行拆分之前为可能的索引添加一个维度:
from skmultilearn.model_selection import iterative_train_test_split
def balanced_split(df, test_size=0.5):
ind = np.expand_dims(np.arange(len(df)), axis=1)
labels = mlb.transform(df["labels"])
ind_train, _, ind_test, _ = iterative_train_test_split(ind, labels,
test_size)
return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:,0]]有了这个balanced_split()功能,我们可以将数据分成监督和非监督数据集,然后为监督部分创建平衡的训练、验证和测试集:
from sklearn.model_selection import train_test_split
df_clean = df_issues[["text", "labels", "split"]].reset_index(drop=True).copy()
df_unsup = df_clean.loc[df_clean["split"] == "unlabeled", ["text", "labels"]]
df_sup = df_clean.loc[df_clean["split"] == "labeled", ["text", "labels"]]
np.random.seed(0)
df_train, df_tmp = balanced_split(df_sup, test_size=0.5)
df_valid, df_test = balanced_split(df_tmp, test_size=0.5)最后,让我们创建一个DatasetDict包含所有拆分的 a,以便我们可以轻松地标记数据集并与 Trainer. 在这里,我们将使用漂亮的from_pandas()方法直接从相应的 Pandas 加载每个拆分DataFrame:
from datasets import Dataset, DatasetDict
ds = DatasetDict({
"train": Dataset.from_pandas(df_train.reset_index(drop=True)),
"valid": Dataset.from_pandas(df_valid.reset_index(drop=True)),
"test": Dataset.from_pandas(df_test.reset_index(drop=True)),
"unsup": Dataset.from_pandas(df_unsup.reset_index(drop=True))})这看起来不错,所以最后要做的是创建一些训练切片,以便我们可以根据训练集大小评估每个分类器的性能。
创建训练切片
数据集有两个我们想在本章中研究的特征:稀疏标记数据和多标签分类。训练集仅包含 220 个要训练的示例,即使使用迁移学习,这肯定也是一个挑战。为了深入了解本章中的每种方法如何使用少量标记数据执行,我们还将使用更少的样本创建训练数据的切片。然后,我们可以根据性能绘制样本数量并研究各种制度。我们将从每个标签仅 8 个样本开始,并使用以下函数进行构建,直到切片覆盖整个训练集iterative_train_test_split():
np.random.seed(0)
all_indices = np.expand_dims(list(range(len(ds["train"]))), axis=1)
indices_pool = all_indices
labels = mlb.transform(ds["train"]["labels"])
train_samples = [8, 16, 32, 64, 128]
train_slices, last_k = [], 0
for i, k in enumerate(train_samples):
# Split off samples necessary to fill the gap to the next split size
indices_pool, labels, new_slice, _ = iterative_train_test_split(
indices_pool, labels, (k-last_k)/len(labels))
last_k = k
if i==0: train_slices.append(new_slice)
else: train_slices.append(np.concatenate((train_slices[-1], new_slice)))
# Add full dataset as last slice
train_slices.append(all_indices), train_samples.append(len(ds["train"]))
train_slices = [np.squeeze(train_slice) for train_slice in train_slices]请注意,这种迭代方法仅将样本近似拆分为所需的大小,因为在给定的拆分大小下并不总是可以找到平衡的拆分:
print("Target split sizes:")
print(train_samples)
print("Actual split sizes:")
print([len(x) for x in train_slices])Target split sizes: [8, 16, 32, 64, 128, 223] Actual split sizes: [10, 19, 36, 68, 134, 223]
我们将使用指定的分割大小作为以下绘图的标签。太好了,我们终于将数据集准备好进行训练拆分——接下来让我们看看训练一个强大的基线模型!
实现朴素贝叶斯线
每当您开始一个新的 NLP 项目时,实施一组强大的基线总是一个好主意。这有两个主要原因:
-
基于正则表达式、手工规则或非常简单的模型的基线可能已经很好地解决了问题。在这些情况下,没有理由拿出像变压器这样的大炮,在生产环境中部署和维护通常更复杂。
-
当您探索更复杂的模型时,基线提供快速检查。例如,假设您训练 BERT-large 并在验证集上获得 80% 的准确度。你可以把它写成一个硬数据集,然后收工。但是,如果您知道像逻辑回归这样的简单分类器可以达到 95% 的准确率呢?这会引起您的怀疑并提示您调试模型。
因此,让我们通过训练基线模型开始我们的分析。对于文本分类,一个很好的基线是朴素贝叶斯分类器 ,因为它非常简单,训练快速,并且对输入中的扰动相当稳健。朴素贝叶斯的 Scikit-learn 实现不支持开箱即用的多标签分类,但幸运的是,我们可以再次使用 Scikit-multilearn 库将问题转换为一个一对一的分类任务,我们为 L 个训练L个 二元分类器标签。首先,让我们使用多标签二值化器在我们的训练集中创建一个新列label_ids。我们可以使用map()该功能一次性完成所有处理:
def prepare_labels(batch):
batch["label_ids"] = mlb.transform(batch["labels"])
return batch
ds = ds.map(prepare_labels, batched=True)为了衡量我们分类器的性能,我们将使用微观和宏观F 1 -scores,其中前者跟踪频繁标签上的性能,而后者跟踪所有标签上的性能,而不考虑频率。由于我们将在不同大小的训练拆分中评估每个模型,让我们创建 defaultdict一个列表来存储每个拆分的分数:
from collections import defaultdict
macro_scores, micro_scores = defaultdict(list), defaultdict(list)现在我们终于准备好训练我们的基线了!下面是训练模型并在不断增加的训练集大小上评估我们的分类器的代码:
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.feature_extraction.text import CountVectorizer
for train_slice in train_slices:
# Get training slice and test data
ds_train_sample = ds["train"].select(train_slice)
y_train = np.array(ds_train_sample["label_ids"])
y_test = np.array(ds["test"]["label_ids"])
# Use a simple count vectorizer to encode our texts as token counts
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(ds_train_sample["text"])
X_test_counts = count_vect.transform(ds["test"]["text"])
# Create and train our model!
classifier = BinaryRelevance(classifier=MultinomialNB())
classifier.fit(X_train_counts, y_train)
# Generate predictions and evaluate
y_pred_test = classifier.predict(X_test_counts)
clf_report = classification_report(
y_test, y_pred_test, target_names=mlb.classes_, zero_division=0,
output_dict=True)
# Store metrics
macro_scores["Naive Bayes"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Naive Bayes"].append(clf_report["micro avg"]["f1-score"])在这段代码中发生了很多事情,所以让我们解压缩它。首先,我们得到训练切片并对标签进行编码。然后我们使用计数向量器对文本进行编码,方法是简单地创建一个词汇量大小的向量,其中每个条目对应于一个标记在文本中出现的频率。这被称为词袋方法,因为所有关于单词顺序的信息都丢失了。然后我们训练分类器并使用测试集上的预测 通过分类报告得到微观和宏观F 1分数。
使用以下辅助函数,我们可以绘制该实验的结果:
import matplotlib.pyplot as plt
def plot_metrics(micro_scores, macro_scores, sample_sizes, current_model):
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 4), sharey=True)
for run in micro_scores.keys():
if run == current_model:
ax0.plot(sample_sizes, micro_scores[run], label=run, linewidth=2)
ax1.plot(sample_sizes, macro_scores[run], label=run, linewidth=2)
else:
ax0.plot(sample_sizes, micro_scores[run], label=run,
linestyle="dashed")
ax1.plot(sample_sizes, macro_scores[run], label=run,
linestyle="dashed")
ax0.set_title("Micro F1 scores")
ax1.set_title("Macro F1 scores")
ax0.set_ylabel("Test set F1 score")
ax0.legend(loc="lower right")
for ax in [ax0, ax1]:
ax.set_xlabel("Number of training samples")
ax.set_xscale("log")
ax.set_xticks(sample_sizes)
ax.set_xticklabels(sample_sizes)
ax.minorticks_off()
plt.tight_layout()
plt.show()plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes")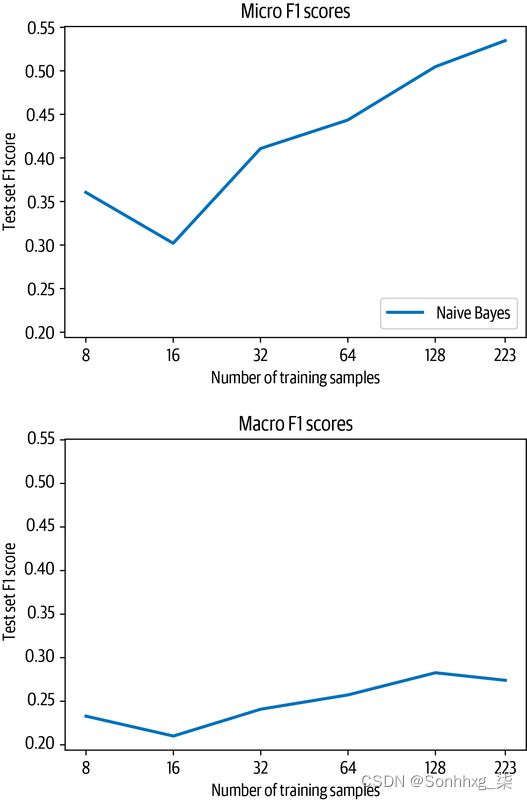
请注意,我们以对数标度绘制样本数量。从图中我们可以看到,随着训练样本数量的增加,微观和宏观F 1分数都提高了。由于要训练的样本太少,结果也有轻微的噪音,因为每个切片可以有不同的类分布。尽管如此,这里重要的是趋势,所以现在让我们看看这些结果如何与基于转换器的方法相比!
使用无标签数据
我们将考虑的第一个技术是零样本分类,它适用于根本没有标记数据的环境。这在工业中非常普遍,并且可能因为没有带有标签的历史数据或者因为获取数据的标签很困难而发生。在本节中我们会作弊,因为我们仍将使用测试数据来衡量性能,但我们不会使用任何数据来训练模型(否则与以下方法进行比较会很困难)。
零样本分类的目标是利用预训练模型,而不需要对特定任务的语料库进行任何额外的微调。为了更好地了解这是如何工作的,请回想一下,像 BERT 这样的语言模型经过预训练,可以预测数千本书和大型 Wikipedia 转储文本中的掩码标记。为了成功预测丢失的标记,模型需要了解上下文中的主题。我们可以尝试通过提供如下语句来欺骗模型为我们分类文档:
“This section was about the topic [MASK].”
然后模型应该对文档的主题给出合理的建议,因为这是出现在数据集中的自然文本。2
让我们用下面的玩具问题进一步说明这一点:假设你有两个孩子,其中一个更喜欢有汽车的电影,而另一个更喜欢有动物的电影。不幸的是,他们已经看过所有你知道的,所以你想构建一个函数来告诉你一部新电影的主题。自然地,你会求助于变形金刚来完成这项任务。首先要尝试的是在fill-mask管道中加载 BERT-base,它使用掩码语言模型来预测掩码标记的内容:
from transformers import pipeline
pipe = pipeline("fill-mask", model="bert-base-uncased") 接下来,让我们构建一个小电影描述,并在其中添加一个带有蒙面词的提示。提示的目的是引导模型帮助我们进行分类。fill-mask管道返回最有可能的标记来填充被屏蔽的位置:
movie_desc = "The main characters of the movie madacascar \
are a lion, a zebra, a giraffe, and a hippo. "
prompt = "The movie is about [MASK]."
output = pipe(movie_desc + prompt)
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")Token animals: 0.103% Token lions: 0.066% Token birds: 0.025% Token love: 0.015% Token hunting: 0.013%
显然,该模型仅预测与动物相关的标记。我们也可以扭转这种情况,我们可以查询管道以获取一些给定令牌的概率,而不是获取最可能的令牌。对于这个任务,我们可能会选择carsand animals,所以我们可以将它们作为目标传递给管道:
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")Token animals: 0.103% Token cars: 0.001%
不出所料,token 的预测概率cars远小于animals。让我们看看这是否也适用于更接近汽车的描述:
movie_desc = "In the movie transformers aliens \
can morph into a wide range of vehicles."
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%")Token cars: 0.139% Token animals: 0.006%
确实如此!这只是一个简单的例子,如果我们想确保它运行良好,我们应该彻底测试它,但它说明了本章讨论的许多方法的关键思想:找到一种方法,使预训练模型适应另一个任务而无需训练它。在这种情况下,我们设置了一个带有掩码的提示,以便我们可以直接使用掩码语言模型进行分类。让我们看看我们是否可以通过调整一个已经在更接近文本分类的任务上微调的模型做得更好:自然语言推理(NLI)。
使用掩码语言模型进行分类是一个不错的技巧,但我们可以通过使用已针对更接近分类的任务进行训练的模型做得更好。有一个简洁的代理任务,称为 文本蕴涵,符合要求。在文本蕴涵中,模型需要确定两个文本段落是否可能相互跟随或相互矛盾。模型通常经过训练以检测与多类型 NLI 语料库 (MNLI) 或跨语言 NLI 语料库 (XNLI) 等数据集的蕴涵和矛盾。3
这些数据集中的每个样本都由三部分组成:前提、假设和标签,标签可以是entailment、neutral或 中的一个contradiction。当entailment假设文本在前提下必然为真时,分配标签。contradiction当假设在前提下必然为假或不适当时,使用该 标签。如果这些情况都不适用,则neutral分配标签。有关每个示例,请参见表 9-1。
表 9-1。MLNI 数据集中的三个类
| Premise | Hypothesis | Label |
|---|---|---|
| His favourite color is blue. |
He is into heavy metal music. |
|
| She finds the joke hilarious. |
She thinks the joke is not funny at all. |
|
| The house was recently built. |
The house is new. |
|
现在,事实证明我们可以劫持在 MNLI 数据集上训练的模型来构建分类器,而根本不需要任何标签!关键思想是将我们希望分类的文本作为前提,然后将假设表述为:
“This example is about {label}.”
我们在其中插入标签的类名。然后,蕴涵分数告诉我们该前提与该主题有关的可能性有多大,我们可以按顺序对任意数量的类运行它。这种方法的缺点是我们需要为每个类执行前向传递,这使得它的效率低于标准分类器。另一个稍微棘手的方面是标签名称的选择会对准确性产生很大影响,而选择具有语义含义的标签通常是最好的方法。例如,如果标签是简单Class 1的,则模型没有暗示这可能意味着什么以及这是否构成矛盾或蕴涵。Transformers 内置了一个用于零样本分类的 MNLI 模型。我们可以通过管道对其进行初始化,如下所示:
from transformers import pipeline
pipe = pipeline("zero-shot-classification", device=0)该设置device=0可确保模型在 GPU 而不是默认 CPU 上运行以加快推理速度。要对文本进行分类,我们只需将其与标签名称一起传递给管道。此外,我们可以设置multi_label=True以确保返回所有分数,而不仅仅是单标签分类的最大值:
sample = ds["train"][0]
print(f"Labels: {sample['labels']}")
output = pipe(sample["text"], all_labels, multi_label=True)
print(output["sequence"][:400])
print("\nPredictions:")
for label, score in zip(output["labels"], output["scores"]):
print(f"{label}, {score:.2f}")Labels: ['new model']
Add new CANINE model
# New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o
tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the
title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural
modeling, yet nearly all commonly-used models still require an explicit tokeni
Predictions:
new model, 0.98
tensorflow or tf, 0.37
examples, 0.34
usage, 0.30
pytorch, 0.25
documentation, 0.25
model training, 0.24
tokenization, 0.17
pipeline, 0.16笔记
由于我们使用的是子词标记器,我们甚至可以将代码传递给模型!标记化可能不是很有效,因为零样本管道的预训练数据集只有一小部分由代码片段组成,但由于代码也由许多自然词组成,这不是一个大问题。此外,代码块可能包含重要信息,例如框架(PyTorch 或 TensorFlow)。
我们可以看到该模型非常有信心这篇文章是关于一个新模型的,但它也为其他标签产生了相对较高的分数。零样本分类的一个重要方面是我们正在操作的领域。我们在这里处理的文本非常技术性并且主要是关于编码的,这使得它们与 MNLI 数据集中的原始文本分布有很大不同。因此,这对模型来说是一项具有挑战性的任务也就不足为奇了。对于某些领域,它可能比其他领域效果更好,具体取决于它们与训练数据的接近程度。
让我们编写一个函数,通过零样本管道提供单个示例,然后通过运行将其扩展到整个验证集map():
def zero_shot_pipeline(example):
output = pipe(example["text"], all_labels, multi_label=True)
example["predicted_labels"] = output["labels"]
example["scores"] = output["scores"]
return example
ds_zero_shot = ds["valid"].map(zero_shot_pipeline)现在我们有了分数,下一步是确定应该为每个示例分配哪组标签。我们可以尝试几个选项:
-
定义一个阈值并选择阈值以上的所有标签。
-
选择得分最高的前k个标签。
为了帮助我们确定哪种方法最好,让我们编写一个 get_preds()函数,应用其中一种方法来检索预测:
def get_preds(example, threshold=None, topk=None):
preds = []
if threshold:
for label, score in zip(example["predicted_labels"], example["scores"]):
if score >= threshold:
preds.append(label)
elif topk:
for i in range(topk):
preds.append(example["predicted_labels"][i])
else:
raise ValueError("Set either `threshold` or `topk`.")
return {"pred_label_ids": list(np.squeeze(mlb.transform([preds])))}接下来,让我们编写第二个函数 ,get_clf_report()它从具有预测标签的数据集中返回 Scikit-learn 分类报告:
def get_clf_report(ds):
y_true = np.array(ds["label_ids"])
y_pred = np.array(ds["pred_label_ids"])
return classification_report(
y_true, y_pred, target_names=mlb.classes_, zero_division=0,
output_dict=True)有了这两个函数,让我们从top- k方法开始,将k增加几个值,然后在验证集上绘制微观和宏观F 1 -scores:
macros, micros = [], []
topks = [1, 2, 3, 4]
for topk in topks:
ds_zero_shot = ds_zero_shot.map(get_preds, batched=False,
fn_kwargs={'topk': topk})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report['micro avg']['f1-score'])
macros.append(clf_report['macro avg']['f1-score'])plt.plot(topks, micros, label='Micro F1')
plt.plot(topks, macros, label='Macro F1')
plt.xlabel("Top-k")
plt.ylabel("F1-score")
plt.legend(loc='best')
plt.show()
从图中我们可以看到,通过选择每个示例得分最高的标签(前 1 个)来获得最佳结果。考虑到我们数据集中的大多数示例只有一个标签,这可能并不令人惊讶。现在让我们将其与设置阈值进行比较,因此我们可以预测每个示例多个标签:
macros, micros = [], []
thresholds = np.linspace(0.01, 1, 100)
for threshold in thresholds:
ds_zero_shot = ds_zero_shot.map(get_preds,
fn_kwargs={"threshold": threshold})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report["micro avg"]["f1-score"])
macros.append(clf_report["macro avg"]["f1-score"])plt.plot(thresholds, micros, label="Micro F1")
plt.plot(thresholds, macros, label="Macro F1")
plt.xlabel("Threshold")
plt.ylabel("F1-score")
plt.legend(loc="best")
plt.show()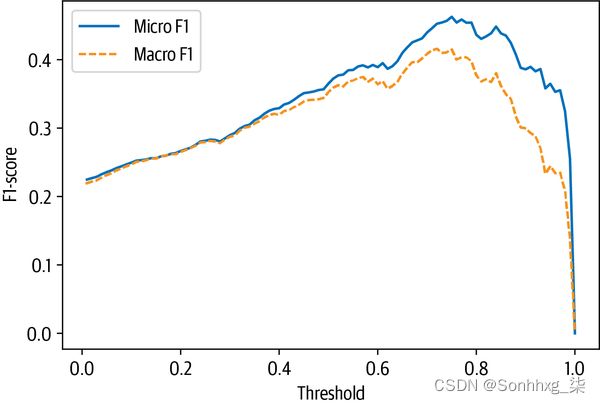
best_t, best_micro = thresholds[np.argmax(micros)], np.max(micros)
print(f'Best threshold (micro): {best_t} with F1-score {best_micro:.2f}.')
best_t, best_macro = thresholds[np.argmax(macros)], np.max(macros)
print(f'Best threshold (micro): {best_t} with F1-score {best_macro:.2f}.')Best threshold (micro): 0.75 with F1-score 0.46. Best threshold (micro): 0.72 with F1-score 0.42.
这种方法比前 1 的结果差一些,但我们可以在这张图中清楚地看到精度/召回率的权衡。如果我们将阈值设置得太低,那么预测太多,导致精度低。如果我们将阈值设置得太高,那么我们几乎不会做出任何预测,从而导致召回率低。从图中我们可以看出,0.8 左右的阈值是两者之间的最佳点。
由于 top-1 方法表现最好,让我们用它来比较测试集上的零样本分类和朴素贝叶斯:
ds_zero_shot = ds['test'].map(zero_shot_pipeline)
ds_zero_shot = ds_zero_shot.map(get_preds, fn_kwargs={'topk': 1})
clf_report = get_clf_report(ds_zero_shot)
for train_slice in train_slices:
macro_scores['Zero Shot'].append(clf_report['macro avg']['f1-score'])
micro_scores['Zero Shot'].append(clf_report['micro avg']['f1-score'])plot_metrics(micro_scores, macro_scores, train_samples, "Zero Shot")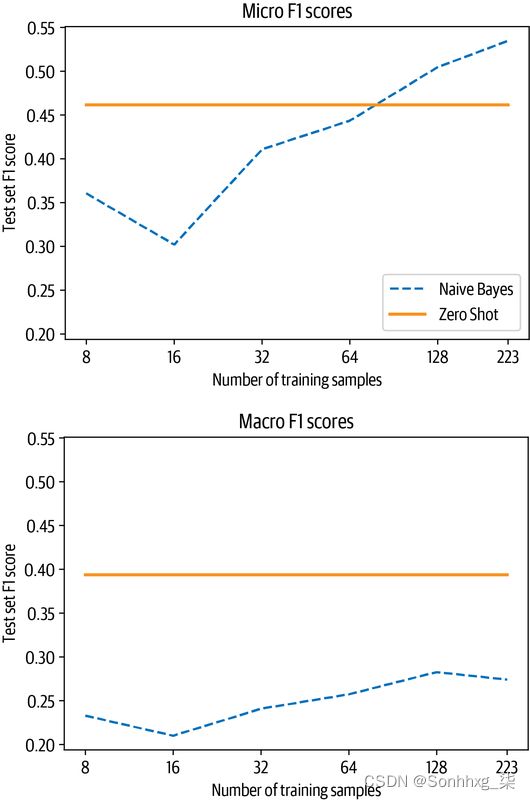
将零样本管道与基线进行比较,我们观察到两件事:
-
如果我们有少于 50 个标记样本,则零样本管道轻松优于基线。
-
即使超过 50 个样本,在同时考虑微观和宏观F 1分数时,零样本流水线的性能也更为出色。微 F 1分数的结果告诉我们,基线在频繁类上表现良好,而零样本管道在这些方面表现出色,因为它不需要任何示例来学习。
笔记
您可能会注意到本节中的一个小悖论:尽管我们谈论的是不处理标签,但我们仍然使用验证集和测试集。我们使用它们来展示不同的技术,并使它们之间的结果具有可比性。即使在实际用例中,收集少量标记示例来运行一些快速评估也是有意义的。重要的一点是我们没有根据数据调整模型的参数;相反,我们只是调整了一些超参数。
如果您发现很难在自己的数据集上获得好的结果,您可以采取以下措施来改进零样本管道:
-
管道的工作方式使其对标签的名称非常敏感。如果名称没有多大意义或不容易与文本联系起来,则管道可能会表现不佳。尝试使用不同的名称或并行使用多个名称并在额外的步骤中聚合它们。
-
您可以改进的另一件事是假设的形式。默认情况下它是
hypothesis="This is example is about {}",但您可以将任何其他文本传递给管道。根据用例,这可能会提高性能。
现在让我们转向我们有一些可以用来训练模型的标记示例的机制。
使用几个标签
在大多数 NLP 项目中,您至少可以访问一些带标签的示例。标签可能直接来自客户或跨公司团队,或者您可能决定坐下来自己注释一些示例。即使对于以前的方法,我们也需要一些带标签的示例来评估零样本方法的效果。在本节中,我们将看看如何最好地利用我们拥有的少数珍贵的标记示例。让我们从一种称为数据增强的技术开始,它可以帮助我们增加我们拥有的小标记数据。
数据增强
在小型数据集上提高文本分类器性能的一种简单但有效的方法是应用数据增强从现有示例中生成新训练示例的技术。这是计算机视觉中的一种常见策略,其中图像被随机扰动而不改变数据的含义(例如,稍微旋转的猫仍然是猫)。对于文本,数据增强有点棘手,因为扰乱单词或字符可以完全改变含义。例如,“大象比老鼠重吗?”这两个问题。和“老鼠比大象重吗?” 只是一个单词交换不同,但有相反的答案。但是,如果文本包含多个句子(就像我们的 GitHub 问题一样),那么这些类型的转换引入的噪音通常不会影响标签。在实践中,常用的数据增强技术有两种:
Back translation
获取源语言中的文本,使用机器翻译将其翻译成一种或多种目标语言,然后将其翻译回源语言。反向翻译往往最适用于资源丰富的语言或不包含太多特定领域单词的语料库。
Token perturbations
给定训练集中的文本,随机选择并执行简单的转换,如随机同义词替换、单词插入、交换或删除。4
这些转换的示例如表 9-2所示。有关 NLP 的其他数据增强技术的详细列表,我们建议阅读 Amit Chaudhary 的博客文章 “NLP 中数据增强的可视化调查”。
表 9-2。不同类型的文本数据增强技术
| Augmentation | Sentence |
|---|---|
| None |
Even if you defeat me Megatron, others will rise to defeat your tyranny |
| Synonym replace |
Even if you kill me Megatron, others will prove to defeat your tyranny |
| Random insert |
Even if you defeat me Megatron, others humanity will rise to defeat your tyranny |
| Random swap |
You even if defeat me Megatron, others will rise defeat to tyranny your |
| Random delete |
Even if you me Megatron, others to defeat tyranny |
| Back translate (German) |
Even if you defeat me, others will rise up to defeat your tyranny |
您可以使用M2M100等机器翻译模型实现反向翻译 ,而NlpAug和 TextAttack等库为令牌扰动提供了各种方法。在本节中,我们将专注于使用同义词替换,因为它很容易实现并且理解了数据增强背后的主要思想。
我们将使用 NlpAug 的ContextualWordEmbsAug增强器来利用 DistilBERT 的上下文词嵌入来进行同义词替换。让我们从一个简单的例子开始:
from transformers import set_seed
import nlpaug.augmenter.word as naw
set_seed(3)
aug = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased",
device="cpu", action="substitute")
text = "Transformers are the most popular toys"
print(f"Original text: {text}")
print(f"Augmented text: {aug.augment(text)}")Original text: Transformers are the most popular toys Augmented text: transformers'the most popular toys
在这里,我们可以看到“are”这个词是如何被一个撇号替换的,以生成一个新的合成训练示例。我们可以将这种扩充包装在一个简单的函数中,如下所示:
def augment_text(batch, transformations_per_example=1):
text_aug, label_ids = [], []
for text, labels in zip(batch["text"], batch["label_ids"]):
text_aug += [text]
label_ids += [labels]
for _ in range(transformations_per_example):
text_aug += [aug.augment(text)]
label_ids += [labels]
return {"text": text_aug, "label_ids": label_ids}现在,当我们将此函数传递给map()方法时,我们可以使用参数生成任意数量的新示例transformations_per_example 。我们可以在代码中使用这个函数来训练朴素贝叶斯分类器,只需在选择切片后添加一行:
ds_train_sample = ds_train_sample.map(augment_text, batched=True,
remove_columns=ds_train_sample.column_names).shuffle(seed=42)包括此内容并重新运行分析会生成此处显示的图:
plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes + Aug")
从图中我们可以看到,少量的数据增强将朴素贝叶斯分类器的F 1 -score 提高了大约 5 个百分点,并且一旦我们有大约 170 个训练样本,它就超过了宏观分数的 zero-shot 管道。现在让我们看一下基于使用大型语言 模型嵌入的方法。
使用嵌入作为查找表
GPT-3 等大型语言模型已被证明在解决数据有限的任务方面表现出色。原因是这些模型学习了有用的文本表示,这些表示可以跨多个维度对信息进行编码,例如情感、主题、文本结构等。因此,大型语言模型的嵌入可用于开发语义搜索引擎、查找相似文档或评论,甚至对文本进行分类。
在本节中,我们将创建一个以 OpenAI API 分类端点为模型的文本分类器。这个想法遵循三个步骤:
-
使用语言模型嵌入所有带标签的文本。
-
对存储的嵌入执行最近邻搜索。
-
聚合最近邻居的标签以获得预测。
该过程如图 9-3 所示,它显示了标记数据如何嵌入模型并与标签一起存储。当需要对新文本进行分类时,它也会被嵌入,并根据最近邻居的标签给出标签。校准要搜索的邻居数量很重要,因为太少可能会产生噪音,而太多可能会混入相邻组。
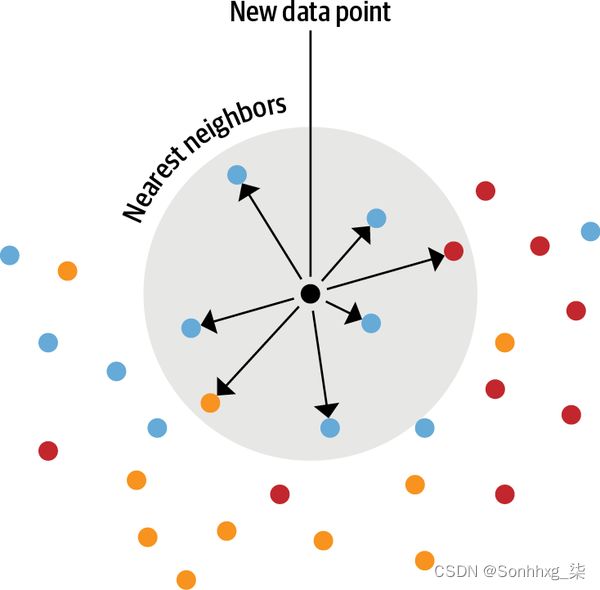
图 9-3。最近邻嵌入查找的图示
这种方法的优点在于不需要模型微调来利用少数可用的标记数据点。相反,使这种方法发挥作用的主要决定是选择一个合适的模型,该模型理想地在与您的数据集相似的域上进行了预训练。
由于 GPT-3 只能通过 OpenAI API 获得,我们将使用 GPT-2 来测试该技术。具体来说,我们将使用经过 Python 代码训练的 GPT-2 变体,它有望捕获我们 GitHub 问题中包含的一些上下文。
让我们编写一个辅助函数,它接受一个文本列表并使用模型为每个文本创建一个单向量表示。我们必须处理的一个问题是,像 GPT-2 这样的转换器模型实际上会为每个令牌返回一个嵌入向量。例如,给定句子“I take my dog for a walk”,我们可以期待多个嵌入向量,每个标记一个。但我们真正想要的是整个句子的单个嵌入向量(或我们应用程序中的 GitHub 问题)。为了解决这个问题,我们可以使用一种叫做 pooling的技术。最简单的池化方法之一是对令牌嵌入进行平均,这称为均值池化. 对于均值池,我们唯一需要注意的是我们不包括平均填充标记,因此我们可以使用注意掩码来处理它。
为了看看它是如何工作的,让我们加载一个 GPT-2 标记器和模型,定义平均池操作,并将整个过程包装在一个简单的embed_text()函数中:
import torch
from transformers import AutoTokenizer, AutoModel
model_ckpt = "miguelvictor/python-gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
def mean_pooling(model_output, attention_mask):
# Extract the token embeddings
token_embeddings = model_output[0]
# Compute the attention mask
input_mask_expanded = (attention_mask
.unsqueeze(-1)
.expand(token_embeddings.size())
.float())
# Sum the embeddings, but ignore masked tokens
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Return the average as a single vector
return sum_embeddings / sum_mask
def embed_text(examples):
inputs = tokenizer(examples["text"], padding=True, truncation=True,
max_length=128, return_tensors="pt")
with torch.no_grad():
model_output = model(**inputs)
pooled_embeds = mean_pooling(model_output, inputs["attention_mask"])
return {"embedding": pooled_embeds.cpu().numpy()}现在我们可以获得每个拆分的嵌入。请注意,GPT 样式的模型没有填充标记,因此我们需要添加一个,然后才能按照前面代码中实现的批处理方式获取嵌入。为此,我们将仅回收字符串结尾标记:
tokenizer.pad_token = tokenizer.eos_token
embs_train = ds["train"].map(embed_text, batched=True, batch_size=16)
embs_valid = ds["valid"].map(embed_text, batched=True, batch_size=16)
embs_test = ds["test"].map(embed_text, batched=True, batch_size=16)现在我们有了所有的嵌入,我们需要建立一个系统来搜索它们。我们可以编写一个函数来计算我们将要查询的新文本嵌入与训练集中现有嵌入之间的余弦相似度。或者,我们可以使用称为 FAISS 索引的内置数据集结构。5我们已经在第 7 章遇到过 FAISS 。您可以将其视为嵌入的搜索引擎,我们将在稍后详细了解它的工作原理。我们可以使用数据集的现有字段来创建 FAISS 索引 add_faiss_index(),也可以使用 将新嵌入加载到数据集中 add_faiss_index_from_external_arrays()。让我们使用前一个函数将我们的训练嵌入添加到数据集中, 如下所示:
embs_train.add_faiss_index("embedding")这创建了一个新的 FAISS 索引,称为embedding. 我们现在可以通过调用函数来执行最近邻查找 get_nearest_examples()。它返回最近的邻居以及每个邻居的匹配分数。我们需要指定查询嵌入以及要检索的最近邻居的数量。让我们试一试,看看最接近示例的文档:
i, k = 0, 3 # Select the first query and 3 nearest neighbors
rn, nl = "\r\n\r\n", "\n" # Used to remove newlines in text for compact display
query = np.array(embs_valid[i]["embedding"], dtype=np.float32)
scores, samples = embs_train.get_nearest_examples("embedding", query, k=k)
print(f"QUERY LABELS: {embs_valid[i]['labels']}")
print(f"QUERY TEXT:\n{embs_valid[i]['text'][:200].replace(rn, nl)} [...]\n")
print("="*50)
print(f"Retrieved documents:")
for score, label, text in zip(scores, samples["labels"], samples["text"]):
print("="*50)
print(f"TEXT:\n{text[:200].replace(rn, nl)} [...]")
print(f"SCORE: {score:.2f}")
print(f"LABELS: {label}")QUERY LABELS: ['new model']
QUERY TEXT:
Implementing efficient self attention in T5
# New model addition
My teammates and I (including @ice-americano) would like to use efficient self
attention methods such as Linformer, Performer and [...]
==================================================
Retrieved documents:
==================================================
TEXT:
Add Linformer model
# New model addition
## Model description
### Linformer: Self-Attention with Linear Complexity
Paper published June 9th on ArXiv: https://arxiv.org/abs/2006.04768
La [...]
SCORE: 54.92
LABELS: ['new model']
==================================================
TEXT:
Add FAVOR+ / Performer attention
# FAVOR+ / Performer attention addition
Are there any plans to add this new attention approximation block to
Transformers library?
## Model description
The n [...]
SCORE: 57.90
LABELS: ['new model']
==================================================
TEXT:
Implement DeLighT: Very Deep and Light-weight Transformers
# New model addition
## Model description
DeLight, that delivers similar or better performance than transformer-based
models with sign [...]
SCORE: 60.12
LABELS: ['new model']好的!这正是我们所希望的:我们通过嵌入查找获得的三个检索到的文档都具有相同的标签,我们已经可以从标题中看到它们都非常相似。查询以及检索到的文档都围绕着添加新的高效转换器模型。然而,问题仍然存在,k的最佳值是多少?同样,我们应该如何聚合检索到的文档的标签?例如,我们是否应该检索三个文档并分配至少出现两次的所有标签?还是我们应该使用 20 个并使用所有出现至少 5 次的标签?让我们系统地研究一下:我们将尝试几个k值,然后改变阈值 米<ķ用于带有辅助功能的标签分配。我们将记录每个设置的宏观和微观性能,以便我们稍后决定哪个运行表现最好。我们可以使用函数来代替循环验证集中的每个样本,该函数get_nearest_examples_batch()接受一批查询:
def get_sample_preds(sample, m):
return (np.sum(sample["label_ids"], axis=0) >= m).astype(int)
def find_best_k_m(ds_train, valid_queries, valid_labels, max_k=17):
max_k = min(len(ds_train), max_k)
perf_micro = np.zeros((max_k, max_k))
perf_macro = np.zeros((max_k, max_k))
for k in range(1, max_k):
for m in range(1, k + 1):
_, samples = ds_train.get_nearest_examples_batch("embedding",
valid_queries, k=k)
y_pred = np.array([get_sample_preds(s, m) for s in samples])
clf_report = classification_report(valid_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True)
perf_micro[k, m] = clf_report["micro avg"]["f1-score"]
perf_macro[k, m] = clf_report["macro avg"]["f1-score"]
return perf_micro, perf_macro让我们检查一下所有训练样本的最佳值是多少,并可视化所有k和 m配置的分数:
valid_labels = np.array(embs_valid["label_ids"])
valid_queries = np.array(embs_valid["embedding"], dtype=np.float32)
perf_micro, perf_macro = find_best_k_m(embs_train, valid_queries, valid_labels)fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 3.5), sharey=True)
ax0.imshow(perf_micro)
ax1.imshow(perf_macro)
ax0.set_title("micro scores")
ax0.set_ylabel("k")
ax1.set_title("macro scores")
for ax in [ax0, ax1]:
ax.set_xlim([0.5, 17 - 0.5])
ax.set_ylim([17 - 0.5, 0.5])
ax.set_xlabel("m")
plt.show()
从图中我们可以看到存在一种模式: 对于给定的k选择太大或太小的m会产生次优结果。选择大约的比率时,可以实现最佳性能米/ķ=1/3. 让我们看看哪个k和m总体上给出了最好的结果:
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
print(f"Best k: {k}, best m: {m}")Best k: 15, best m: 5
我们选择时性能最好ķ=15和 米=5,或者换句话说,当我们检索 15 个最近的邻居,然后分配至少出现 5 次的标签时。现在我们有了一个很好的方法来找到嵌入查找的最佳值,我们可以玩与朴素贝叶斯分类器相同的游戏,我们遍历训练集的切片并评估性能。在我们对数据集进行切片之前,我们需要删除索引,因为我们不能像数据集一样切片 FAISS 索引。其余循环保持完全相同,除了使用验证集来获得最佳k和m 值:
embs_train.drop_index("embedding")
test_labels = np.array(embs_test["label_ids"])
test_queries = np.array(embs_test["embedding"], dtype=np.float32)
for train_slice in train_slices:
# Create a Faiss index from training slice
embs_train_tmp = embs_train.select(train_slice)
embs_train_tmp.add_faiss_index("embedding")
# Get best k, m values with validation set
perf_micro, _ = find_best_k_m(embs_train_tmp, valid_queries, valid_labels)
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
# Get predictions on test set
_, samples = embs_train_tmp.get_nearest_examples_batch("embedding",
test_queries,
k=int(k))
y_pred = np.array([get_sample_preds(s, m) for s in samples])
# Evaluate predictions
clf_report = classification_report(test_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True,)
macro_scores["Embedding"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Embedding"].append(clf_report["micro avg"]["f1-score"])plot_metrics(micro_scores, macro_scores, train_samples, "Embedding")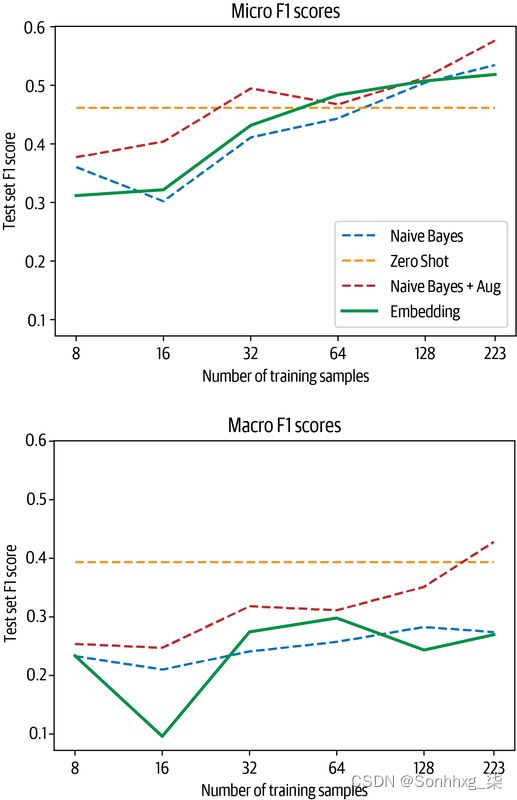
嵌入查找在微观分数上与之前的方法具有竞争力,同时只有两个“可学习”参数 k和m,但在宏观分数上表现稍差。
对这些结果持保留态度;哪种方法效果最好很大程度上取决于领域。零样本管道的训练数据与我们使用它的 GitHub 问题数据集完全不同,后者包含模型以前可能没有遇到过的大量代码。对于更常见的任务,例如评论的情绪分析,管道可能会更好地工作。同样,嵌入的质量取决于模型和训练它的数据。我们尝试了六种模型,例如sentence-transformers/stsb-roberta-large经过训练以提供高质量句子嵌入的模型,以及microsoft/codebert-base经过 dbernsohn/roberta-python代码和文档训练的模型。对于这个特定的用例,使用 Python 代码训练的 GPT-2 效果最好。
由于除了替换模型检查点名称来测试另一个模型之外,您实际上不需要更改代码中的任何内容,因此一旦设置了评估管道,您就可以快速尝试一些模型。
现在让我们将这个简单的嵌入技巧与简单地在我们拥有的有限数据上微调转换器进行比较。
使用 FAISS 进行高效的相似性搜索
我们在第 7 章第一次遇到 FAISS ,我们用它通过 DPR 嵌入检索文档。在这里,我们将简要解释 FAISS 库的工作原理以及为什么它是 ML 工具箱中的强大工具。
我们习惯于在大型数据集(例如 Wikipedia)或使用 Google 等搜索引擎的网络上执行快速文本查询。当我们从文本转向嵌入时,我们希望保持这种性能;但是,用于加速文本查询的方法不适用于嵌入。
为了加快文本搜索,我们通常创建一个将术语映射到文档的倒排索引。倒排索引就像一本书末尾的索引:每个单词都映射到它出现的页面(或者在我们的例子中,文档)。当我们稍后运行查询时,我们可以快速查找搜索词在哪些文档中出现。这适用于诸如单词之类的离散对象,但不适用于诸如向量之类的连续对象。每个文档可能都有一个唯一的向量,因此索引永远不会与新向量匹配。我们需要寻找接近或相似的匹配,而不是寻找精确匹配。
当我们想在数据库中找到与查询向量最相似的向量时,理论上我们需要将查询向量与数据库中的 n 个向量中的每一个进行比较。对于本章中的小型数据库,这没有问题,但是如果我们将其扩展到数千甚至数百万条目,我们将需要等待一段时间才能处理每个查询。
FAISS 通过几个技巧解决了这个问题。主要思想是对数据集进行分区。如果我们只需要将查询向量与数据库的一个子集进行比较,就可以显着加快处理速度。但是,如果我们只是随机划分数据集,我们如何决定要搜索哪个分区,以及找到最相似条目的保证是什么?显然,必须有更好的解决方案:将 k均值聚类应用于数据集!这通过相似性将嵌入聚类成组。此外,对于每个组,我们得到一个质心向量,它是该组所有成员的平均值(图 9-4)。

图 9-4。FAISS 索引的结构:灰色点表示添加到索引中的数据点,粗黑点是通过 k-means 聚类找到的聚类中心,彩色区域表示属于聚类中心的区域
给定这样的分组,在n 个向量中搜索要容易得多:我们首先在k个质心上搜索与我们的查询最相似的那个(k个比较),然后在组内搜索(k/n要比较的元素)。这将比较次数从n减少到 k+n/k. 所以问题是,什么是k的最佳选择?如果它太小,每组仍然包含许多我们需要在第二步中进行比较的样本,如果k太大,我们需要搜索很多质心。寻找函数的最小值 F(k)=k+n/k关于k,我们发现k=n. 事实上,我们可以用下图来形象化这一点n=220.
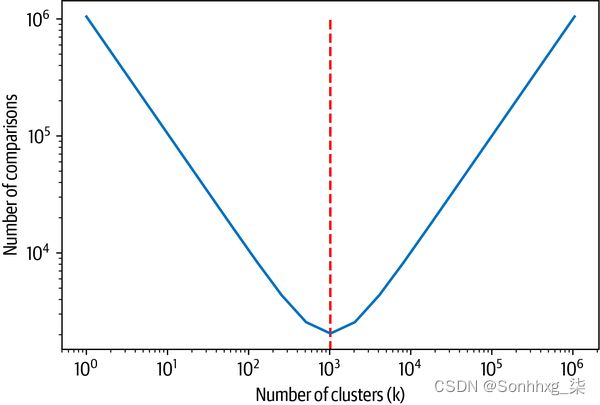
在图中,您可以看到比较次数与聚类数的函数关系。我们正在寻找这个函数的最小值,我们需要做最少的比较。我们可以看到最小值正是我们期望看到的地方,在 220=210=1,024.
除了通过分区加速查询之外,FAISS 还允许您利用 GPU 来进一步加速。如果内存成为一个问题,还有几个选项可以使用高级量化方案来压缩向量。如果您想将 FAISS 用于您的项目,存储库有一个简单的 指南 供您为您的用例选择正确的方法。
使用 FAISS 的最大项目之一是 Facebook创建 CCMatrix 语料库。作者使用多语言嵌入来查找不同语言的平行句子。这个庞大的语料库随后被用来训练 M2M100,这是一种能够直接在 100 种语言之间进行翻译的大型机器翻译模型。
微调Vanilla Transformer
如果我们可以访问标记数据,我们还可以尝试做一件显而易见的事情:简单地微调一个预训练的 Transformer 模型。在本节中,我们将使用标准 BERT 检查点作为起点。稍后,我们将看到微调语言模型对性能的影响。
小费
对于许多应用程序,从预训练的类 BERT 模型开始是一个好主意。但是,如果您的语料库的领域与预训练语料库(通常是 Wikipedia)有很大不同,您应该探索 Hugging Face Hub 上可用的许多模型。很可能有人已经在您的域上预训练了模型!
让我们首先加载预训练的分词器,对我们的数据集进行分词,并删除我们不需要进行训练和评估的列:
import torch
from transformers import (AutoTokenizer, AutoConfig,
AutoModelForSequenceClassification)
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
def tokenize(batch):
return tokenizer(batch["text"], truncation=True, max_length=128)
ds_enc = ds.map(tokenize, batched=True)
ds_enc = ds_enc.remove_columns(['labels', 'text'])多标签损失函数期望标签是浮点类型,因为它还允许类概率而不是离散标签。因此,我们需要更改列的类型label_ids。由于按元素更改列的格式与 Arrow 的类型格式不兼容,我们将做一些解决方法。首先,我们创建一个带有标签的新列。该列的格式是从第一个元素推断出来的。然后我们删除原始列并重命名新列以代替原始列:
ds_enc.set_format("torch")
ds_enc = ds_enc.map(lambda x: {"label_ids_f": x["label_ids"].to(torch.float)},
remove_columns=["label_ids"])
ds_enc = ds_enc.rename_column("label_ids_f", "label_ids")由于训练数据的大小有限,我们很可能很快过拟合,因此我们load_best_model_at_end=True根据 micro F 1 -score 设置和选择最佳模型:
from transformers import Trainer, TrainingArguments
training_args_fine_tune = TrainingArguments(
output_dir="./results", num_train_epochs=20, learning_rate=3e-5,
lr_scheduler_type='constant', per_device_train_batch_size=4,
per_device_eval_batch_size=32, weight_decay=0.0,
evaluation_strategy="epoch", save_strategy="epoch",logging_strategy="epoch",
load_best_model_at_end=True, metric_for_best_model='micro f1',
save_total_limit=1, log_level='error')我们需要F 1 -score 来选择最佳模型,因此我们需要确保在评估期间对其进行计算。因为模型返回 logits,我们首先需要使用 sigmoid 函数对预测进行归一化,然后可以使用简单的阈值对它们进行二值化。然后我们从分类报告中返回我们感兴趣的分数:
from scipy.special import expit as sigmoid
def compute_metrics(pred):
y_true = pred.label_ids
y_pred = sigmoid(pred.predictions)
y_pred = (y_pred>0.5).astype(float)
clf_dict = classification_report(y_true, y_pred, target_names=all_labels,
zero_division=0, output_dict=True)
return {"micro f1": clf_dict["micro avg"]["f1-score"],
"macro f1": clf_dict["macro avg"]["f1-score"]}现在我们准备隆隆声了!对于每个训练集切片,我们从头开始训练分类器,在训练循环结束时加载最佳模型,并将结果存储在测试集上:
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config)
trainer = Trainer(
model=model, tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"],)
trainer.train()
pred = trainer.predict(ds_enc["test"])
metrics = compute_metrics(pred)
macro_scores["Fine-tune (vanilla)"].append(metrics["macro f1"])
micro_scores["Fine-tune (vanilla)"].append(metrics["micro f1"])plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (vanilla)")
首先,我们看到,当我们可以访问大约 64 个示例时,只需对数据集上的普通 BERT 模型进行微调就会产生有竞争力的结果。我们还看到,在此之前,行为有点不稳定,这再次是由于在小样本上训练模型,其中一些标签可能会出现不利的不平衡。在我们使用数据集的未标记部分之前,让我们快速看一下在少样本领域使用语言模型的另一种有前途的方法。
带提示的上下文和小样本学习
我们在本章前面看到,我们可以使用像 BERT 或 GPT-2 这样的语言模型,并通过使用提示和解析模型的标记预测来使其适应监督任务。这与添加特定任务的头部和调整任务的模型参数的经典方法不同。从好的方面来说,这种方法不需要任何训练数据,但在消极方面,如果我们可以访问标记数据,我们似乎无法利用它。有时我们可以利用一种中间立场,称为 上下文学习或小样本学习。
为了说明这个概念,考虑一个英语到法语的翻译任务。在零样本范式中,我们将构建一个提示,如下所示:
prompt = """\
Translate English to French:
thanks =>
"""这有望促使模型预测单词“merci”的标记。我们在第 6 章中使用 GPT-2 进行摘要时已经看到,在 文本中添加“TL;DR”会促使模型生成摘要,而无需明确接受培训。GPT-3 论文的一个有趣发现是大型语言模型能够有效地从提示中提供的示例中学习——因此,之前的翻译示例可以增加几个英语到德语的示例,这将使模型表现更好在这个任务上。6
此外,作者发现模型规模越大,它们使用上下文示例的能力就越好,从而显着提高性能。尽管 GPT-3 大小的模型在生产中使用具有挑战性,但这是一个令人兴奋的新兴研究领域,人们已经构建了很酷的应用程序,例如自然语言 shell,其中以自然语言输入命令并由 GPT-3 解析为 shell 命令.
使用标记数据的另一种方法是创建提示和所需预测的示例,并继续在这些示例上训练语言模型。一种称为 ADAPET 的新方法使用了这种方法,并在各种任务上击败了 GPT-3,7 使用生成的提示调整模型。Hugging Face 研究人员最近的工作表明,这种方法比微调自定义头部的数据效率更高。8
在本节中,我们简要介绍了充分利用我们拥有的少数标记示例的各种方法。很多时候,除了标记的示例之外,我们还可以访问大量未标记的数据;在下一节中,我们将讨论如何充分利用它。
利用未标记的数据
尽管访问大量高质量标记数据是训练分类器的最佳情况,但这并不意味着未标记数据一文不值。想想我们使用过的大多数模型的预训练:即使它们是在互联网上大部分不相关的数据上训练的,我们也可以将预训练的权重用于各种文本的其他任务。这就是 NLP 中迁移学习的核心思想。自然,如果下游任务具有与预训练文本相似的文本结构,则迁移效果会更好,因此如果我们可以使预训练任务更接近下游目标,我们就有可能改善迁移。
让我们根据具体用例来考虑这一点:BERT 在 BookCorpus 和英语维基百科上进行了预训练,包含代码和 GitHub 问题的文本在这些数据集中绝对是一个小众市场。例如,如果我们从头开始预训练 BERT,我们可以在 GitHub 上的所有问题上进行爬网。但是,这会很昂贵,而且 BERT 学到的许多语言方面的知识仍然适用于 GitHub 问题。那么在从头开始重新训练和仅使用模型进行分类之间是否存在中间立场?有,它被称为域适应(我们在第 7 章中也看到了问题回答)。无需从头开始重新训练语言模型,我们可以继续使用我们领域中的数据对其进行训练。在这一步中,我们使用经典的语言模型目标来预测掩码单词,这意味着我们不需要任何标记数据。之后,我们可以将适应的模型加载为分类器并对其进行微调,从而利用未标记的数据。
领域适应的美妙之处在于,与标记的数据相比,未标记的数据通常是大量可用的。此外,调整后的模型可以在许多用例中重复使用。想象一下,您想构建一个电子邮件分类器并对所有历史电子邮件应用域适应。您可以稍后将相同的模型用于命名实体识别或其他分类任务(如情感分析),因为该方法与下游任务无关。
现在让我们看看我们需要采取哪些步骤来微调预训练的语言模型。
微调语言模型
在本节中,我们将在数据集的未标记部分上使用掩码语言建模对预训练的 BERT 模型进行微调。为此,我们只需要两个新概念:标记数据时的额外步骤和特殊的数据整理器。让我们从标记化开始。
除了来自文本的普通标记之外,标记器还会将特殊标记添加到序列中,例如用于分类和下一句预测的标记[CLS]。[SEP]当我们进行掩码语言建模时,我们希望确保我们不会训练模型来预测这些标记。出于这个原因,我们将它们从损失中屏蔽掉,并且我们可以在标记化时通过设置得到一个屏蔽 return_special_tokens_mask=True。让我们使用该设置重新标记文本:
def tokenize(batch):
return tokenizer(batch["text"], truncation=True,
max_length=128, return_special_tokens_mask=True)
ds_mlm = ds.map(tokenize, batched=True)
ds_mlm = ds_mlm.remove_columns(["labels", "text", "label_ids"])从掩码语言建模开始,缺少的是在输入序列中掩码标记并在输出中包含目标标记的机制。我们可以解决这个问题的一种方法是设置一个函数来屏蔽随机标记并为这些序列创建标签。但这会使数据集的大小翻倍,因为我们还将目标序列存储在数据集中,这意味着我们将在每个 epoch 使用相同的序列掩码。
一个更优雅的解决方案是使用数据整理器。请记住,数据整理器是在数据集和模型调用之间建立桥梁的函数。从数据集中抽取一个批次,数据整理者准备批次中的元素以将它们提供给模型。在我们遇到的最简单的情况下,它只是将每个元素的张量连接成一个张量。在我们的例子中,我们可以使用它来动态进行遮罩和标签生成。这样我们就不需要存储标签,并且每次采样时都会得到新的掩码。此任务的数据整理器称为 DataCollatorForLanguageModeling。我们使用模型的标记器和我们想要通过mlm_probability参数屏蔽的标记部分对其进行初始化。我们将使用这个整理器来屏蔽 15% 的令牌,这遵循 BERT 论文中的过程:
from transformers import DataCollatorForLanguageModeling, set_seed
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,
mlm_probability=0.15)让我们快速浏览一下数据整理器的实际作用。为了在 a 中快速显示结果DataFrame,我们将分词器和数据整理器的返回格式切换为 NumPy:
set_seed(3)
data_collator.return_tensors = "np"
inputs = tokenizer("Transformers are awesome!", return_tensors="np")
outputs = data_collator([{"input_ids": inputs["input_ids"][0]}])
pd.DataFrame({
"Original tokens": tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]),
"Masked tokens": tokenizer.convert_ids_to_tokens(outputs["input_ids"][0]),
"Original input_ids": original_input_ids,
"Masked input_ids": masked_input_ids,
"Labels": outputs["labels"][0]}).T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| Original tokens | [CLS] | transformers | are | awesome | ! | [SEP] |
| Masked tokens | [CLS] | transformers | are | awesome | [MASK] | [SEP] |
| Original input_ids | 101 | 19081 | 2024 | 12476 | 999 | 102 |
| Masked input_ids | 101 | 19081 | 2024 | 12476 | 103 | 102 |
| Labels | -100 | -100 | -100 | -100 | 999 | -100 |
我们看到感叹号对应的token已经被替换为mask token了。此外,数据整理器返回了一个标签数组,原始标记为 –100,掩码标记为标记 ID。正如我们之前看到的,在计算损失时忽略包含 –100 的条目。让我们将数据整理器的格式切换回 PyTorch:
data_collator.return_tensors = "pt"有了标记器和数据整理器,我们就可以微调掩码语言模型了。我们像往常一样设置TrainingArguments和 Trainer:
from transformers import AutoModelForMaskedLM
training_args = TrainingArguments(
output_dir = f"{model_ckpt}-issues-128", per_device_train_batch_size=32,
logging_strategy="epoch", evaluation_strategy="epoch", save_strategy="no",
num_train_epochs=16, push_to_hub=True, log_level="error", report_to="none")
trainer = Trainer(
model=AutoModelForMaskedLM.from_pretrained("bert-base-uncased"),
tokenizer=tokenizer, args=training_args, data_collator=data_collator,
train_dataset=ds_mlm["unsup"], eval_dataset=ds_mlm["train"])
trainer.train()trainer.push_to_hub("Training complete!")我们可以访问训练者的日志历史来查看模型的训练和验证损失。所有日志都存储 trainer.state.log_history为字典列表,我们可以轻松地将其加载到 PandasDataFrame中。由于训练和验证损失记录在不同的步骤中,因此数据框中存在缺失值。出于这个原因,我们在绘制指标之前删除了缺失值:
df_log = pd.DataFrame(trainer.state.log_history)
(df_log.dropna(subset=["eval_loss"]).reset_index()["eval_loss"]
.plot(label="Validation"))
df_log.dropna(subset=["loss"]).reset_index()["loss"].plot(label="Train")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(loc="upper right")
plt.show()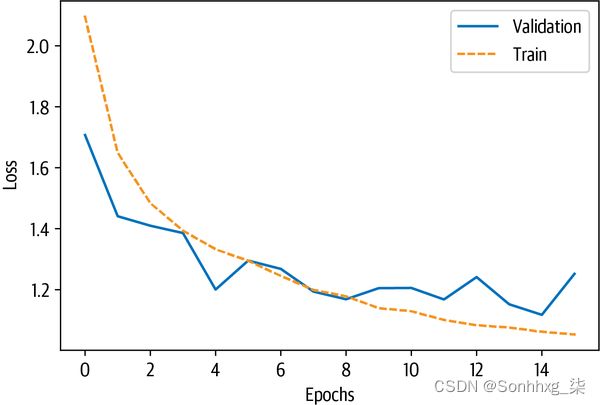
似乎训练和验证损失都大大下降了。因此,让我们检查一下,当我们基于此模型微调分类器时,是否也能看到改进。
微调分类器
现在我们将重复微调过程,但略有不同的是我们加载了我们自己的自定义检查点:
model_ckpt = f'{model_ckpt}-issues-128'
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"
for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"],
)
trainer.train()
pred = trainer.predict(ds_enc['test'])
metrics = compute_metrics(pred)
# DA refers to domain adaptation
macro_scores['Fine-tune (DA)'].append(metrics['macro f1'])
micro_scores['Fine-tune (DA)'].append(metrics['micro f1'])将结果与基于 vanilla BERT 的微调进行比较,我们发现我们获得了优势,尤其是在低数据领域。在有更多标记数据可用的情况下,我们还获得了几个百分点:
plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (DA)")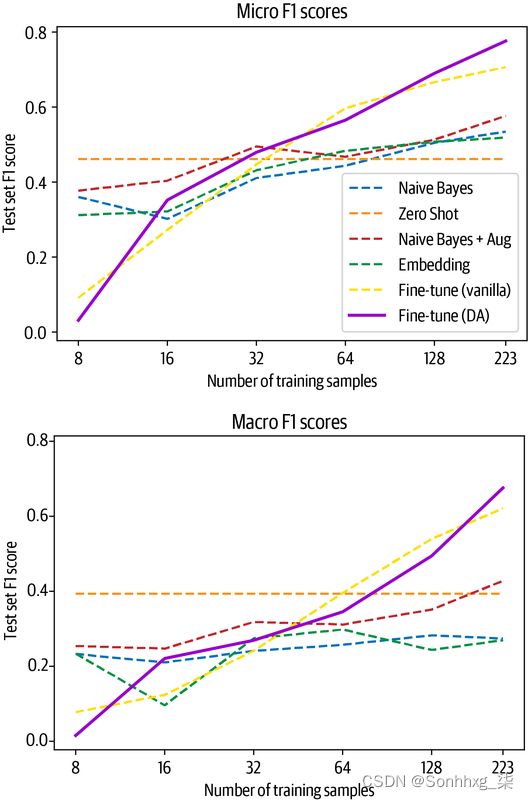
这突出表明,域适应可以通过未标记的数据和很少的努力稍微提高模型的性能。自然,您拥有的未标记数据越多和标记数据越少,您使用此方法获得的影响就越大。在结束本章之前,我们将向您展示更多利用未标记数据的技巧。
高级方法
在调整分类头之前微调语言模型是提高性能的一种简单而可靠的方法。然而,有一些复杂的方法可以进一步利用未标记的数据。我们在这里总结了其中一些方法,如果您需要更高的性能,它们应该提供一个很好的起点。
无监督数据增强
无监督数据增强 (UDA) 背后的关键思想是模型的预测对于未标记的示例和稍微失真的示例应该是一致的。这种失真是通过标准数据增强策略(例如令牌替换和反向翻译)引入的。然后通过最小化原始示例和扭曲示例的预测之间的 KL 散度来执行一致性。这个过程如图 9-5 所示,其中通过使用未标记示例中的附加项来增加交叉熵损失来合并一致性要求。这意味着人们使用标准监督方法在标记数据上训练模型,但限制模型对未标记数据做出一致的预测。

图 9-5。使用 UDA 训练模型 M(由谢启哲提供)
这种方法的性能令人印象深刻:使用少量标记示例,使用 UDA 训练的 BERT 模型与使用数千个示例训练的模型具有相似的性能。缺点是您需要一个数据增强管道,并且训练需要更长的时间,因为您需要多次前向传递来生成未标记和增强示例的预测分布。
不确定性自我训练
另一种利用未标记数据的有前途的方法是不确定性感知自我训练(UST)。这里的想法是在标记数据上训练一个教师模型,然后使用该模型在未标记数据上创建伪标签。然后一个学生在伪标记数据上接受训练,训练后成为下一次迭代的老师。
这种方法的一个有趣的方面是如何生成伪标签:为了获得模型预测的不确定性度量,相同的输入通过模型多次馈送,并打开 dropout。然后,预测中的方差代表了模型在特定样本上的确定性。通过这种不确定性测量,然后使用称为贝叶斯不一致主动学习 (BALD) 的方法对伪标签进行采样。完整的训练流水线如图 9-6 所示。
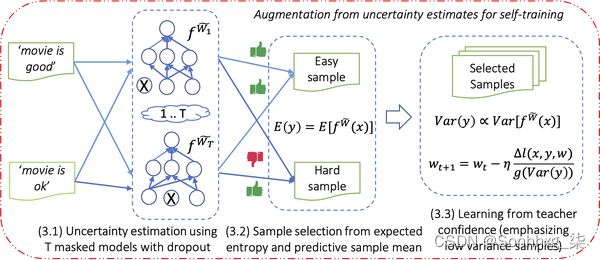
图 9-6。UST 方法由生成伪标签的教师和随后在这些标签上训练的学生组成;学生接受培训后成为老师并重复该步骤(由 Subhabrata Mukherjee 提供)9
通过这种迭代方案,教师在创建伪标签方面不断变得更好,从而提高了模型的性能。最后,这种方法在具有数千个样本的完整训练数据上训练的模型中只有百分之几,甚至在几个数据集上击败了 UDA。
现在我们已经看到了一些高级方法,让我们退后一步,总结一下我们在本章中学到的东西。
结论
在本章中,我们已经看到,即使我们只有几个标签,甚至没有标签,也不是所有的希望都消失了。我们可以利用已经在其他任务上预训练的模型,例如 BERT 语言模型或在 Python 代码上训练的 GPT-2,来对 GitHub 问题分类的新任务进行预测。此外,在使用普通分类头训练模型时,我们可以使用域适应来获得额外的提升。
哪种方法在特定用例上效果最好取决于多个方面:你有多少标记数据,它有多大噪声,数据与预训练语料库的接近程度等等。要找出最有效的方法,最好建立一个评估管道,然后快速迭代。 Transformers 的灵活 API允许您快速加载少量模型并进行比较,而无需更改任何代码。Hugging Face Hub 上有超过 10,000 个模型,过去很可能有人研究过类似的问题,您可以在此基础上进行构建。
超出本书范围的一个方面是在更复杂的方法(如 UDA 或 UST)与获取更多数据之间进行权衡。为了评估你的方法,至少尽早建立一个验证和测试集是有意义的。在每一步,您还可以收集更多标记数据。通常注释几百个示例只需要几个小时或几天的工作,并且有许多工具可以帮助您做到这一点。根据您要实现的目标,花一些时间来创建一个小的、高质量的数据集而不是设计一个非常复杂的方法来弥补它的不足是有意义的。使用本章介绍的方法,您可以确保从宝贵的标记数据中获得最大价值。
在这里,我们冒险进入了低数据机制,发现即使只有一百个例子,Transformer 模型仍然很强大。在下一章中,我们将研究完全相反的情况:当我们拥有数百 GB 的数据和大量计算时,我们将看到我们能做什么。我们将从头开始为我们训练一个大型变压器模型到自动完成代码。